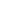The full report of the recent DCS/DCA Data Centre Transformation (DCT) conference can be found elsewhere in this issue, but I think it’s worthwhile using my editorial comment to re(emphasise) the key message from the event: transformation is happening and will continue to happen, at an ever increasing pace, and there is coming a time when many, if not all, of the traditional assumptions made around the data centre and the IT infrastructure it houses and enables are going to be replaced by new technologies and ideas.
For end users, the question is a relatively simple one: Do I want to embrace the change and shape the impact that it will have on my organisation, or do I want to carry on doing what I’ve always done and cross my fingers that everything will be okay?
The hyperscalers and the large-scale web disruptors might be viewed by many as ‘the enemy’ – destroying the high street and many long-standing household names as they leverage technology to undercut companies tied to physical premises and the paying of rent and rates – but their innovative use of existing technologies and their pioneering use of new ones show the way forward for virtually all other businesses, over time.
Of course, not everything will end up in the virtual world – no, we will have yet another hybrid to add to the list – hybrid Cloud, hybrid IT, hybrid data centres…and, now, hybrid business. Physical premises and shops will continue to exist. Some workforces will need to have an office or factory from which to work, but an increasing amount will not; some businesses will continue to need physical showrooms and shops, more and more will not. Towns and cities large enough to be ‘destinations’ when it comes to shopping, will survive, if not thrive; those that do not have a compelling draw to customers, will see more and more empty premises.
Add to this national and regional variations – loyalty to local suppliers and businesses seems to be much more prevalent on mainland Europe, as opposed to the UK and the US – and the world of work and leisure is going to become a real hybrid mixture of the physical and the virtual (and quite literally the virtual when technology will allow us to sight see, play golf and do many other things all over the world from the comfort of our own homes.
There’s no guide to how, when, where or what when it comes to digital transformation, but it’s already here, its momentum is accelerating, and the data centre of, say, 10 years’ time, could look nothing like that of today. More likely, we’ll have some data centres that do look the same from the outside at least – but look radically different when you look under the covers – and joining the current, large scale, consolidated data centres will be all manner of data centre shapes, sizes and locations that are optimised for the applications and data processing tasks which they are required to undertake.
Digital transformation – threat or opportunity? It’s up to each business to decide!
The recent Data Centre Transformation (DCT) conference may not have generated quite as much excitement as England’s victory over Columbia in the World Cup, but it’s safe to say that, if ignorance and uncertainty were the event’s opposition, then DCT played them off the park without a hint of extra time and penalties!
If there was one key take away from the highly successful DCT conference, it had to be the growing recognition that data centre transformation is happening, is here to stay and those who wish to deny its existence – both vendors and end users – would do well to learn the lesson of King Canute, who managed to demonstrate to his subjects that, king he may be, but there was nothing he could do to prevent the tide coming in.
The scene was set courtesy of the Simon Campbell-Whyte Lecture, presented by Rudi Nizinkiewicz. Cyber security was his topic, and Rudi managed to bring a fresh perspective to the world of hacking, phishing, malware and the daily reports of data breaches, as he suggested that, without proper risk assessment, any IT security strategy was doomed to failure. A company needs to understand its potential vulnerabilities – and not just the obvious ones related to outside attacks. No, equally important is the knowledge of how the data centre and its contents might be vulnerable from changes and mistakes, or malicious attacks, from within an organisation.
Rudi gave the recent example of the TSB IT meltdown, where it would seem that the company had not fully understood the inter-relation of its IT infrastructure, hence the problems that occurred when a planned migration took place. And here he touched on the major reason why cyber security and disaster recovery needs to be taken so seriously – the damage it causes to a company. Yes, there’s damage to the company’s day to day business as the mess needs to be sorted out, but there’s also damage to a company’s reputation. What is the true cost of this?
For the cyber security ‘world weary’, Rudi’s take on the subject was fresh and challenging, especially as he was reluctant to concede that the current received wisdom – security breaches will happen, it’s how you manage them that matters – is dangerous, as the focus really should be on preventing any such incidents from taking place. Yes, managing/minimising the impact of a breach is important, but no matter how well this is done, there will be some damage to an organisation, so it has to be better to prevent cyber attacks wherever possible.
And it was also refreshing to hear that, like it or not, bringing in a bank of consultants to advise on cyber security strategy is not the answer. After all, who knows your business best – you, or random third parties?! So, prepare to roll up your sleeves and get that risk assessment project under way.
So, fresh thinking required for cyber security.
And, if delegates were struggling to comprehend the message of Rudi’s lecture, well John Laban’s keynote presentation on open source left them in no doubt that change is coming, like it or not. Open software is a familiar part of the IT landscape, but open hardware has received less traction to date. However, the Open Compute Project (OCP) seeks to change this and promises major disruption to an industry already ‘reeling’ from the move to Cloud and managed services. That’s to say, many hardware vendors are already having to re-invent themselves in terms of how and where they obtain their revenues, becoming less and less reliant on selling expensive ‘boxes’ as more and more end users sign up to Cloud and managed services. The momentum behind the OCP project suggests that not only will the IT hardware folks continue to suffer, but that many of the data centre hardware vendors could be similarly disrupted.
The OCP server design promises to do away with much of the traditional data centre infrastructure required to support it. It’s early days, but when one saw John’s slide of a traditional data centre layout – crammed full of the power and cooling required to support the servers, storage and switches – and then the following slide of the almost empty data centre required to support OCP servers – well, a picture really did paint a thousand words. Perhaps most tangibly, John explained how, using OCP servers, a Scandinavian company was working on a modular data centre design which has two rows of servers – running along each side of the container, tight to the walls – doubling the capacity of the traditional one row design that exists now.
Of course, there’s so much legacy kit out there that open hardware may not make a major impact in the data centre just yet, but there’s no doubting that its benefits will prove hard to resist over time.
The trio of keynote presentations was completed by Jon Summers, who gave a brilliant insight into how the world of the edge computing and edge data centres was likely to develop over time. Jon spoke of the ‘pervasive impact’ of edge – all that remains is for organisations to obtain a proper understanding of where edge fits into their overall IT and data centre infrastructure. In other words, where data is created, is processed, is at rest, is retrieved, where it is re-processed, where it is stored – all this needs to be understood. Only then can an organisation hope to put together an edge strategy that provides the optimum experience for the customer and the most efficient use of IT and data centre resources for the organisation.
The rest of the DCT conference was given over to a mixture of technology and issue focused workshops - subjects discussed included digital business, automation, digital skills, energy and hybrid data centres – and selected vendor presentations.
Cyber security, open compute and edge might be seen as obvious business disruptors. However, as the day progressed, it became increasingly clear that few, if any, data centre ‘components’ are not experiencing something of a transformation as they have to evolve to address the requirements of the emerging information technologies that are underpinning the digital age.
Take just one example – cooling. Right now, air-cooled data centres are the norm. However, in the HPC space, liquid cooling is widely accepted, as it is seen to offer greater efficiency, greater potential for heat recovery and the ability to cool high density racks that are becoming a feature of more and more data centres. The hybrid data centre workshop debated the possibility that air cooling and liquid cooling could co-exist in the data centre well into the future, but is liquid cooling the only game in town in the longer term, when we’re led to believe that HPC-type applications will become the norm?
In summary, the Data Centre Transformation conference delivered a brilliant, balanced agenda that suggested how the industry is going to have to change over the coming years, always mindful that that great ‘enemy’ to progress – legacy infrastructure – is not going away any time soon.
For most organisations, the transformation challenge is knowing how and when to let go of traditional technologies and ideas, replacing them with faster, smarter, more efficient solutions. Doing nothing is not an option. Not only does every industry sector have one or more digital disruptor – a new company that is not hampered by the ‘shackles’ of legacy infrastructure – but there’s every chance that even rival organisations with the same transformation dilemmas as your own are starting to plan for a digital future.
The prospect of so much change might be daunting, but, if the England team can learn how to (finally) win a penalty shoot-out, there must be hope for us all, whatever the challenges. That was certainly the view of the DCT delegates who enjoyed watching the match at the evening buffet/dinner!

Worldwide spending on the technologies and services that enable the digital transformation (DX) of business practices, products, and organizations is forecast to be more than $1.1 trillion in 2018, an increase of 16.8% over the $958 billion spent in 2017.
DX spending will be led by the discrete and process manufacturing industries, which will not only spend the most on DX solutions but also set the agenda for many DX priorities, programs, and use cases. In the newly expanded Worldwide Semiannual Digital Transformation Spending Guide, International Data Corporation (IDC) examines current and future spending levels for more than 130 DX use cases across 19 industries in eight geographic regions. The results provide new insights into where DX funding is being spent as well as what DX priorities are being pursued.
Discrete manufacturing and process manufacturing are expected to spend more than $333 billion combined on DX solutions in 2018. This represents nearly 30% of all DX spending worldwide this year. From a technology perspective, the largest categories of spending will be applications, connectivity services, and IT services as manufacturers build out their digital platforms to compete in the digital economy. The main objective and top spending priority of DX in both industries is smart manufacturing, which includes programs that focus on material optimization, smart asset management, and autonomic operations. IDC expects the two industries to invest more than $115 billion in smart manufacturing initiatives this year. Both industries will also invest heavily in innovation acceleration ($33 billion) and digital supply chain optimization ($28 billion).
Driven in part by investments from the manufacturing industries, smart manufacturing ($161 billion) and digital supply chain optimization ($101 billion) are the DX strategic priorities that will see the most spending in 2018. Other strategic priorities that will receive significant funding this year include digital grid, omni-experience engagement, omnichannel commerce, and innovation acceleration. The strategic priorities that are forecast to see the fastest spending growth over the 2016-2021 forecast period are omni-experience engagement (38.1% compound annual growth rate (CAGR)), financial and clinical risk management (31.8% CAGR), and smart construction (25.4% CAGR).
"Some of the strategic priority areas with lower levels of spending this year include building cognitive capabilities, data-driven services and benefits, operationalizing data and information, and digital trust and stewardship," said Research Manager Craig Simpson, of IDC's Customer Insights & Analysis Group. "This suggests that many organizations are still in the early stages of their DX journey, internally focused on improving existing processes and efficiency. As they move into the later stages of development, we expect to see these priorities, and spending, shift toward the use of digital information to further improve operations and to create new products and services."
To achieve its DX strategic priorities, every business will develop programs that represent a long-term plan of action toward these goals. The DX programs that will receive the most funding in 2018 are digital supply chain and logistics automation ($93 billion) and smart asset management ($91 billion), followed by predictive grid and manufacturing operations (each more than $40 billion). The programs that IDC expects will see the most spending growth over the five-year forecast are construction operations (38.4% CAGR), connected automated vehicles (37.6% CAGR), and clinical outcomes management (30.7% CAGR).
Each strategic priority includes a number of programs which are then comprised of use cases. These use cases are discretely funded efforts that support a program objective, and the overall strategic goals of an organization.. Use cases can be thought of as specific projects that employ line-of-business and IT resources, including hardware, software, and IT services. The use cases that will receive the most funding this year include freight management ($56 billion), robotic manufacturing ($43 billion), asset instrumentation ($43 billion), and autonomic operations ($35 billion). The use cases that will see the fastest spending growth over the forecast period include robotic construction (38.4% CAGR), autonomous vehicles – mining (37.6% CAGR), and robotic process automation-based claims processing (35.5% CAGR) within the insurance industry.
"While the influence of the manufacturing industries is apparent in the program and use case spending, it's clear that other industries, such as retail and construction, will also be spending aggressively to meet their own DX objectives," said Eileen Smith, program director, Customer Insights & Analysis. "In the construction industry, DX spending is expected to grow at a compound annual rate of 31.4% while retail, the third largest industry overall, is forecast to grow its DX spending at a faster pace (20.2% CAGR) than overall DX spending (18.1% CAGR)."

Cloud migration remains a ‘critical’ or ‘high priority’ business initiative for most business leaders.
Businesses have big ambitions for the cloud to transform their agility and reduce overall business expenditure, but unrealistic cost estimates and unforeseen complexities are still dramatically increasing the time-to-value of cloud migration programmes. Only 28 percent of businesses say the cloud has been comprehensively embedded across their organisation.
A June 2018 study, Maintaining Momentum: Cloud Migration Learnings, commissioned by Rackspace and conducted by Forrester Consulting, describes the ongoing organisational focus on moving applications and data to the cloud. 71 percent of business and IT decision makers across the UK, France, Germany and the U.S. report that they are now more than two years into their cloud journey, with the migration of existing workloads into a public or private cloud environment remaining a ‘critical’ or ‘high priority’ business initiative for 81 percent of business leaders over the next 12 months.
Predicting cost
Half of business and IT decision makers (50 percent) identify significant cost reduction as their main driver for cloud adoption. However, several years in, 40 percent of businesses stated that their cloud migration costs were still higher than expected.
The biggest disparity uncovered was around upgrading, rationalising and/or replacing legacy business apps and systems, with 60 percent of respondents identifying costs as higher than expected.
Execution complexity
The survey also found that businesses massively underestimated the greater task at hand, encountering a number of both technical and non-technical internal barriers.
During the planning and executing stages, data issues around capture, cleaning, and governance; workload management in the cloud; and vision and strategy for the transformation were the most commonly cited challenges (40 percent, 34 percent and 31 percent respectively).
Post-migration, respondents highlighted a lack of adequate user training; cultural resistance to cloud migration; and inadequate change management programmes as their greatest challenges (44 percent, 37 percent and 36 percent respectively).
Delivering on the vision
Companies need a clear strategy that connects both business and IT to minimise cloud migration challenges and accelerate the realisation of benefits, with a lack of a strategic vision cited as an issue before and during migration to cloud by 58 percent of respondents.
‘Going it alone’ also increases the scale of the challenge. 78 percent of businesses already recognise the role of service partners in helping them reshape operating models to support their cloud adoption strategy. And when considering what they’d do differently, half (51 percent) of respondents said they would hire experienced cloud experts to help with migration projects, with 41 percent recognising the need to increase the assistance they get from advisory and consulting services.
Commenting on the findings Adam Evans, director of Professional Services at Rackspace said: “Cloud is the engine of digital transformation and a critical enablement factor for innovation, cost reduction and CX initiatives. But while most organisations we meet have started on their cloud journey, I would say the majority did not expect the scale of the ongoing challenge.”
“As a business generation, we are getting faster at new technology adoption, but we still seem to stumble when it comes to understanding the requirements (and limitations) of the business consuming it. Introducing new cloud-based operating practices across an entire organisation is rarely straightforward, as with anything involving people, processes and their relationship with technology. Managing the gap between expectation and reality plays a huge role in programme success, so it’s imperative that organisations start with an accurate perspective on their maturity, capability and mindset. Only then can we start to forecast cost and complexity reliably.”
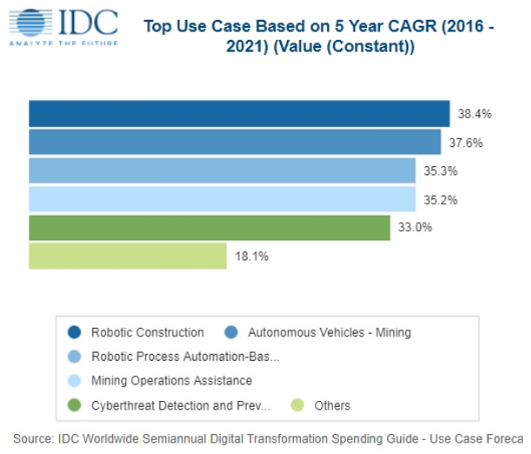
The total EMEA external storage systems value increased almost by 24% in dollars in the first quarter of 2018 (+7.4% in euros), according to International Data Corporation's (IDC) EMEA Quarterly Disk Storage Systems Tracker, 1Q18.
The all-flash-array (AFA) market value recorded high double-digit growth in dollars (58.7%), accounting for 32.7% of overall external storage sales in the region, with most gains recorded in the CEMA subregion. Hybrid arrays, in turn, came close to representing half of total external storage shipments (49.1%). The growth in flash-powered arrays came at the expense of HDD-only systems, which recorded yet another double-digit decline (-24.9%).
"The EMEA external storage market showed remarkable growth in 1Q18, aided by a favorable exchange rate and returning growth for some major players," said Silvia Cosso, research manager, European Storage and Datacenter Research, IDC. "Digital transformation (DX), alongside infrastructure optimization, is the main driver pushing investments in the region. As AFA penetration in the average EMEA datacenter is still low, and end-users have just started dipping their toes into IoT and AI-related projects, we expect further growth in the emerging segments of the datacenter infrastructure market, although with an increasing share of this being captured by public cloud deployments."
(For further research into the workload evolution in the Enterprise Storage market, please refer to IDC's Worldwide Semiannual Enterprise Storage Systems Tracker: Workload).
Western Europe
The Western European market grew 23.9% in U.S. dollar terms, and by 7.4% in euro terms. All flash arrays remained stable at a third of total shipments, with a year-on-year increase well exceeding 50%
The big news of this quarter was a U.K. market returning to growth after 14 consecutive quarters of decline or zero growth in U.S. dollar terms. An unfavorable exchange rate and difficult macroeconomic conditions reflected in stalling investments have been affecting the U.K. market, but DX is finally bringing some investment back.
Meanwhile, the German and French markets continued to show strong growth on the back of higher business confidence at the beginning of the year.
Central and Eastern Europe, the Middle East, and Africa
Alongside Western Europe, the external storage market in Central and Eastern Europe, Middle East and Africa (CEMA) reached 24.1% YoY growth ($423.2 million) triggered by a solid double-digit value boost in both subregions, CEE and MEA.
Both flash-based storage arrays (flash and hybrid) recorded sizeable growth. However, AFA gained 8% share increase compared to a year ago, to account for 30% of total market value, thanks to investments shifting from HFA to AFA, especially in the CEE region. Datacenter upgrades to AFA solutions were a major focus of most storage vendors.
As predicted by IDC, CEMA's positive performance was visible across most big countries, resulting from major verticals investing in datacenter preparation for 3rd platform workloads and technologies. Although emerging, projects related to digital transformation were increasingly present on end users' agendas. As a result, the high-end segment exploded with three-digit YoY growth and the midrange segment stabilized to reclaim 60% of the market.
"As long as the macroeconomic framework does not endure any major changes, the external storage market potential in the region will continue to be visible in the near future," said Marina Kostova, research manager, Storage Systems, IDC CEMA. "Vendors leveraging a regional strategy to address digital transformation efforts and changing consumption models of the market with initial datacenter investments from a growing number of smaller companies, are poised to be more successful."
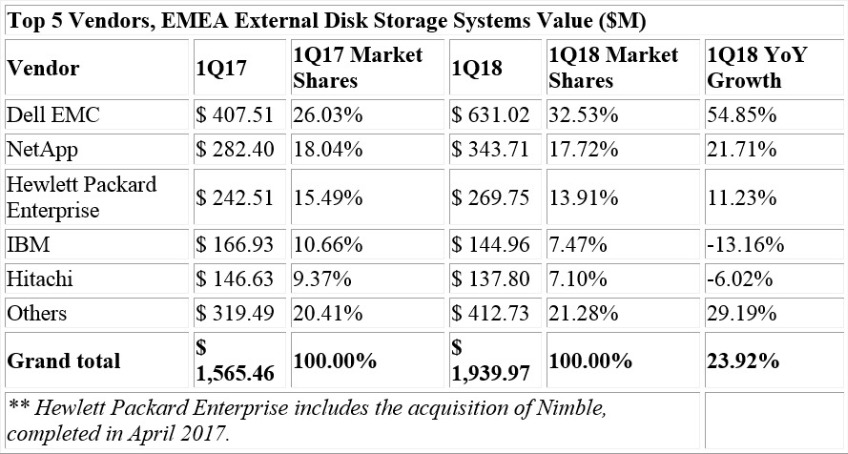


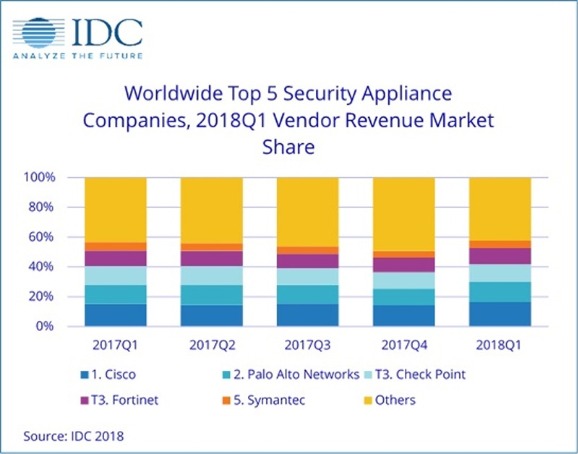
According to the International Data Corporation (IDC) Worldwide Quarterly Security Appliance Tracker, the total security appliance market saw positive growth in both vendor revenue and unit shipments for the first quarter of 2018 (1Q18). Worldwide vendor revenues in the first quarter increased 14.3% year over year to $3.3 billion and shipments grew 18.9% year over year to 838,098 units.
The trend for growth in the worldwide market driven by the Unified Threat Management (UTM) sub-market continues, with UTM reaching record-high revenues of $2.1 billion in 1Q18 and year-over-year growth of 16.1%, the highest growth among all sub-markets. The UTM market now represents more than 53% of worldwide revenues in the security appliance market. The Firewall and Content Management sub-markets also had positive year-over-year revenue growth in 1Q18 with gains of 17.4% and 7.5%, respectively. The Intrusion Detection and Prevention and Virtual Private Network (VPN) sub-markets experienced weakening revenues in the quarter with year-over-year declines of 13.0% and 3.0%, respectively.
Regional Highlights
The United States delivered 42.3% of the worldwide security appliance market revenue and was the major driver for spending in Q1 2018 with 16.7% year-over-year growth. Asia/Pacific (excluding Japan) (APeJ) had the strongest year-over-year revenue growth in 1Q18 at 15.9% and captured 21.0% revenue market share. The more mature regions of the world – the United States and Europe, the Middle East and Africa (EMEA) – combined to provide nearly two thirds of the global security appliance market revenue. Both regions had positive growth in the single-digit range. EMEA saw an annual increase of 11.6%.
Asia/Pacific (including Japan)(APJ) and the Americas (Canada, Latin America, and the U.S.) experienced year-over-year growth of 13.1% and 16.3%, respectively.
"The first quarter of 2018 exhibited strong growth for network security due to consistent double-digit growth across nearly every region and continued momentum from UTM as vendors reported $240.6 million more in revenue for 1Q18 than in 1Q17. Firewall and UTM are the strongest areas of growth as network refreshes drive perimeter security refreshes and as vendors add new features and improve performance across all product lines," said Robert Ayoub, program director, Security Products.

The growth at the end of 2017 continued for the worldwide server market in the first quarter of 2018 as worldwide server revenue increased 33.4 percent and shipments grew 17.3 percent year over year, according to Gartner, Inc.
"The server market was driven by increases in spending by hyperscale as well as enterprise and midsize data centers. Enterprises and midsize businesses are in the process of investing in their on-premises and colocation infrastructure to support server replacements and growth requirements even as they continue to invest in public cloud solutions," said Jeffrey Hewitt, research vice president at Gartner. "Additionally, when it came to server average selling prices (ASP) increases for the quarter, one driver was the fact that DRAM prices increased due to constrained supplies."
Regional results were mixed. North America and Asia/Pacific experienced particularly strong growth double-digit growth in revenue (34 percent and 47.8 percent, respectively). In terms of shipments, North America grew 24.3 percent and Asia/Pacific grew 21.9 percent. EMEA posted strong yearly revenue growth of 32.1 percent while shipments increased 2.7 percent. Japan experienced a decline in both shipments and revenue (-5.0 percent and -7.3 percent, respectively). Latin America experienced a decline in shipments (-1.8 percent), but growth in revenue (19.2 percent).
Dell EMC experienced 51.4 growth in the worldwide server market based on revenue in the first quarter of 2018 (see Table 1). This growth helped widen the gap a bit between Dell EMC and Hewlett Packard Enterprise (HPE) as Dell EMC ended the quarter in the No. 1 spot with 21.5 percent market share, followed closely by HPE with 19.9 percent of the market. Inspur Electronics experienced the strongest growth in the first quarter of 2018 with 120.4 percent growth.
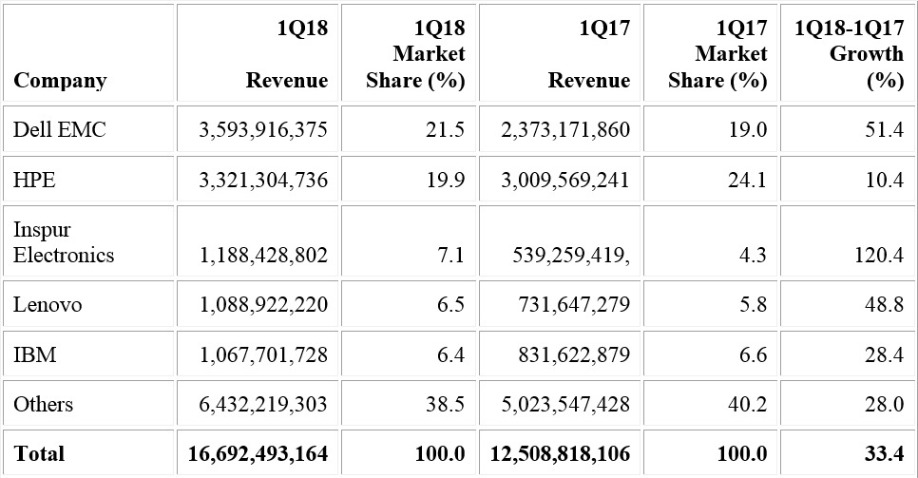
Table 1 - Worldwide: Server Vendor Revenue Estimates, 1Q18 (U.S. Dollars) - Source: Gartner (June 2018)
In server shipments, Dell EMC maintained the No. 1 position in the first quarter of 2018 with 18.2 percent market share (see Table 2). Despite a decline of 8.5 percent in server shipments, HPE secured the second spot with 13.1 percent of the market.
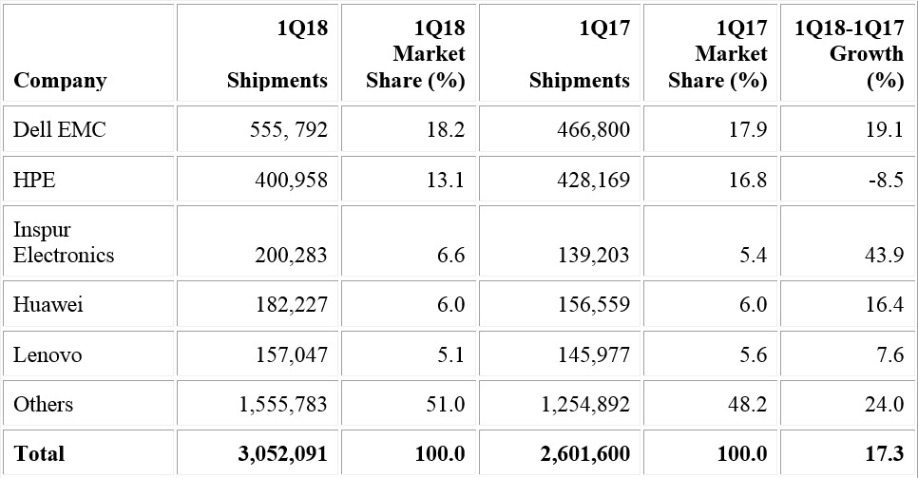
Table 2 - Worldwide: Server Vendor Shipments Estimates, 1Q18 (Units) - Source: Gartner (June 2018)
The x86 server market increased in revenue by 35.7 percent, and shipments were up 17.5 percent in the first quarter of 2018. The RISC/Itanium UNIX market continued to struggle with shipments down 52.8 percent, while revenue declined 46.7 percent.

The total worldwide enterprise storage systems factory revenue grew 34.4% year over year during the first quarter of 2018 (1Q18) to $13.0 billion, according to the International Data Corporation (IDC) Worldwide Quarterly Enterprise Storage Systems Tracker. Total capacity shipments were up 79.1% year over year to 98.8 exabytes during the quarter.
Revenue generated by the group of original design manufacturers (ODMs) selling directly to hyperscale datacenters increased 80.4% year over year in 1Q18 to $3.1 billion. This represented 23.9% of total enterprise storage investments during the quarter. Sales of server-based storage increased 34.2% year over year, to $3.6 billion in revenue. This represented 28.0% of total enterprise storage investments. The external storage systems market was worth $6.3 billion during the quarter, up 19.3% from 1Q17.
"This was a quarter of exceptional growth that can be attributed to multiple factors," said Eric Sheppard, research vice president, Server and Storage Infrastructure. "Demand for public cloud resources and a global enterprise infrastructure refresh were two important drivers of new enterprise storage investments around the world. Solutions most commonly sought after in today's enterprise storage systems are those that help drive new levels of datacenter efficiency, operational simplicity, and comprehensive support for next generation workloads."
1Q18 Total Enterprise Storage Systems Market Results, by Company
Dell Inc was the largest supplier for the quarter, accounting for 21.6% of total worldwide enterprise storage systems revenue and growing 43.0% over 1Q17. HPE/New H3C Group was the second largest supplier with 17.7% share of revenue. This represented 18.3% growth over 1Q17. NetApp generated 6.8% of total revenue, making it the third largest vendor during the quarter. This represented 21.7% growth over 1Q17. Hitachi and IBM were statistically tied* as the fourth largest suppliers with 3.6% and 3.0% respective share of revenue during the quarter. As a single group, storage systems sales by original design manufacturers (ODMs) directly to hyperscale datacenter customers accounted for 23.9% of global spending during the quarter, up 80.4% over 1Q17.
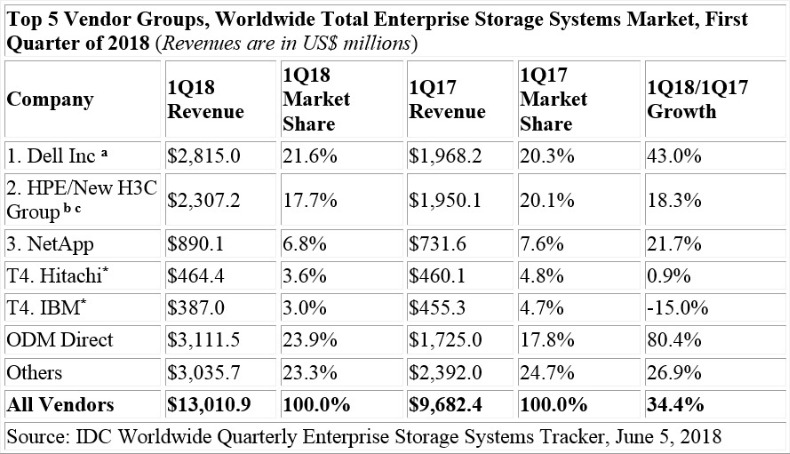
Notes:
a – Dell Inc represents the combined revenues for Dell and EMC.
b – Due to the existing joint venture between HPE and the New H3C Group, IDC will be reporting market share on a global level for HPE as "HPE/New H3C Group" starting from 2Q 2016 and going forward.
c – HPE/New H3C Group includes the acquisition of Nimble, completed in April 2017.
* – IDC declares a statistical tie in the worldwide enterprise storage systems market when there is one percent difference or less in the revenue share of two or more vendors.
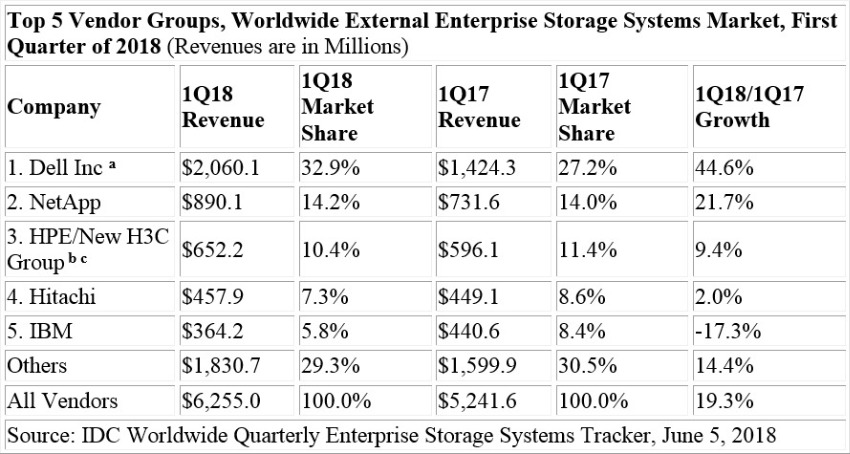
1Q18 External Enterprise Storage Systems Results, by Company
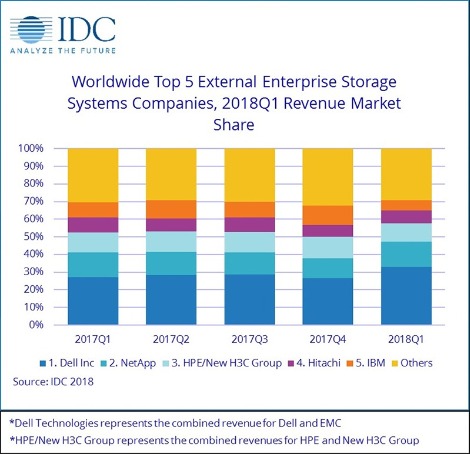
Dell Inc was the largest external enterprise storage systems supplier during the quarter, accounting for 32.9% of worldwide revenues. NetApp finished in the number 2 position with 14.2% share of revenue during the quarter. HPE/New H3C Group was the third largest with 10.4% share of revenue. Hitachi and IBM rounded out the top 5 with 7.3% and 5.8% market share, respectively.
Notes:
a – Dell Inc represents the combined revenues for Dell and EMC.
b – Due to the existing joint venture between HPE and the New H3C Group, IDC will be reporting external market share on a global level for HPE as "HPE/New H3C Group" starting from 2Q 2016 and going forward.
c – HPE/New H3C Group includes the acquisition of Nimble, completed in April 2017
Flash-Based Storage Systems Highlights
The total All Flash Array (AFA) market generated $2.1 billion in revenue during the quarter, up 54.7% year over year. The Hybrid Flash Array (HFA) market was worth $2.5 billion in revenue, up 23.8% from 1Q17.

By 2020, 92 percent of European companies will have deployed Robotic Process Automation (RPA) to streamline business processes.
Advanced business use of Robotic Process Automation (RPA) is expected to double in Europe by 2020, as companies seek to improve customer experience and streamline their finance operations, according to new research from Information Services Group (ISG), a leading global technology research and advisory firm.
ISG, in partnership with RPA software provider Automation Anywhere, surveyed more than 500 European business leaders to assess their adoption of RPA technology and services. The research reveals the percentage of European companies expecting to be at the advanced stage of RPA use will double by 2020, while fewer than 10 percent will not yet have started their RPA journey.
While Europe has been slower to adopt technologies like automation than other markets, RPA is moving into the mainstream, with 92 percent of respondents saying they anticipate using RPA by 2020, and 54 percent saying they will reach the advanced stage of adoption by then, up from 27 percent currently.
ISG’s research reveals RPA budgets in Europe increased on average by 9 percent in the last year, significantly ahead of the average increase for general IT spending. Of those companies that posted an increase, 25 percent saw a double-digit increase. Third parties, such as consultants and service providers, make up more than half of this budget.
Increasingly, improving the quality, speed and efficiency of client-facing and finance functions are becoming top priorities for corporate automation buyers. Over the next 24 months, respondents say RPA is expected to have the greatest impact on customer service and order-processing functions (43 percent), closely followed by finance, treasury and audit (42 percent); procurement, logistics and supply chain (40 percent), and sales and marketing (38 percent).
Adoption of RPA is in its initial stages in Europe, with three-quarters of respondents saying they are in either the early phase (up to pilot testing) or intermediate phase (automating fewer than 10 business processes). By 2020, however, nearly three-quarters expect to be in the intermediate to advanced phase (automating 10 or more processes).
Among Europe’s largest markets, 60 percent of German companies expect to be in the advanced stage of deployment by 2020 (versus 32 percent today), following by 50 percent in France (up from 22 percent) and 46 percent in the UK (up from 23 percent).
However, barriers to adoption remain. Security is a key concern, with 42 percent of businesses citing this as an obstacle to expanding their RPA use. Lack of budget and resistance to change were both cited by 33 percent, followed by concerns over governance and compliance (29 percent), lack of IT support (28 percent) and lack of executive commitment (27 percent).
Commenting on the findings, Andreas Lueth, partner at ISG, said: “Robotic Process Automation is delivering improved outcomes for enterprises across Europe and our research shows many more businesses will be taking advantage of the technology by 2020 as adoption accelerates. The increasing prominence of RPA in organizations is borne out in the fact that many businesses are now choosing to appoint Heads of Automation – a role that has appeared only in the past two years.
“This technology has the potential to revolutionize customer service and back-office functions alike, but organizations should be wary of falling into the RPA trap. The decision to deploy RPA should be treated as a strategic business initiative, with defined objectives and measures. Without this, the chance of failure is high.”
James Dening, vice president, Europe at Automation Anywhere adds: “European enterprises are at an exciting juncture with respect to RPA. If implemented properly, over the next few years RPA technologies will help deliver significant value for businesses across a range of European enterprises and industries, ensuring growth in productivity, efficiency and output, and helping these firms and industries stay competitive at a local, regional and global level.”

European Union legislation requires the phased reduction of refrigerants that have considerable greenhouse effects by 2030. Such refrigerants are widely used in water chillers and direct expansion (DX) air-conditioning systems used across industries, including datacenters. The current legislation took effect in 2015, but it wasn't until 2018 that the total available supply saw a great cut, by about one-third, according to the phaseout plan. By Daniel Bizo, Senior Analyst, Datacenters and Critical Infrastructure, 451 Group.
As a direct result of this, refrigerant prices have been rising rapidly since 2017, and now resellers are increasing quotes by 10-20% every month on already high prices as the market races to find a new equilibrium. Costs are being passed on to end users and becoming material to datacenter design and equipment sourcing decisions. The next phase takes effect in 2021, when another 30% of the supply will be cut. The HVAC-industry (heating, ventilation and air-conditioning) has started rolling out new chillers and developed new refrigerants in response. Those that build datacenters optimized for free-cooling and use mechanical refrigeration for trimming peaks are less affected, while those with more traditional cooling regimes, particularly around computer room air-conditioners, might reconsider their equipment choices.
The 451 Take
Investigating refrigerant options and how it might affect cooling design is an unlikely item on the task lists of datacenter engineers and managers. The last time such a change took place was over 20 years ago, when the production of ozone-depleting refrigerants was banned. But the picture today couldn't be more different – datacenter facilities have spread in numbers, and grown in size and importance. In reflection of all this, datacenters have become a major expenditure. On top of all that, environmental charities and pressure groups closely scrutinize major datacenter operators. Skyrocketing costs and looming hard shortages are inescapable and will demand the attention of datacenter owners for prudent reasons, but they also present an opportunity to speed up the shift toward more environmentally sustainable operations.
Some refrigerants are just not cool anymore Having eliminated virtually all sales of ozone-depleting gases (and equipment that makes use of them) ahead of its commitments made under the Montreal Protocol, the European Union turned its attention to leading the charge against substances with strong greenhouse effects, or global warming potential (GWP) in climate research and regulatory parlance. These are hydrofluorocarbons (HFC) – generally referred to as F-gases. European regulation of F-gases has been in place since 2007, but the EU adopted a new and much more stringent regulation in 2014 to limit emissions. Ambitiously, the new legislation has set out a plan that will reduce the sale of F-gases in the EU to one-fifth of the baseline (Fgas sales are measured by their carbon dioxide equivalence) by 2030, set at the average from 2009-2012. Only chemical processing, military applications and semiconductor manufacturing are exempt from the phase-down.
As a result, F-gas emissions in the European Union will be cut to one-third of 2014 levels by the end of the next decade. The EU, the world's largest trading bloc, adopted its accelerated HFC phase-down legislation ahead of the Kigali Amendment to the Montreal Protocol, a global agreement to cut HFC consumption by 80% in 30 years, which comes into force in 2019.
The first phase of cuts in the EU came into effect in 2016, yet at 7% (of total supply) it had marginal effect on the overall supply-demand picture. Come 2018, however, the total available supply was cut to 63% of the baseline. The next cut, due in 2021 will see it reduced to 45% of baseline, and 31% by 2024. Anyone producing or importing F-gases needs to apply for quota. Prices have been escalating quickly, with double-digit monthly adjustments by resellers as hard shortages of key refrigerants, such as R134a, which is the predominant choice for datacenter cooling systems, hit the market – supplies are going to the highest bidder. Another contributing factor may have been increases in production costs of key F-gases driven by price surges of key ingredients in 2017. The net effect today is a tenfold jump compared with just a couple of years ago (1,000%).
Vendors say the shortage-driven price of R134a is already becoming material to end users. In cases where large amounts of refrigerant are needed to charge the system, datacenter customers will see as much as a 5% cost increase on capital costs for cooling, up from a negligible amount. This is only the start. Even if markets find a new equilibrium, it will be short-lived with new phases coming into effect every three years. Anticipation of shortages, much like in 2017, will also likely bring demand ahead as many participants will attempt to build stockpiles, making shortages and price increases even more pronounced elsewhere. Vendors expect the issue of refrigerants (both the cost and environmental sustainability) to speed up the shift toward extended temperature ranges in the data hall, as well as systems that are optimized for maximized free cooling hours (time during which no mechanical refrigeration is employed) and rely on mechanical refrigeration for only part of the load. Prime examples are indirect evaporative air handlers and economized free cooling chillers.
Ultimately, the HVAC industry (heating, ventilation and air-conditioning) will shift away from F-gases to substances with much lower GWP – it has no other choice. There are multiple options being explored, some of which are ready for commercial application. Still, questions remain about their cost performance and, more importantly, long-term sustainability. While some alternative refrigerants offer low GWP, which makes them ideal for environmental sustainability, either cooling performance or safety properties make them less than ideal for application in existing cooling systems. Ammonia, for example, is a high-performance refrigerant that also occurs naturally and has a zero GWP. Yet, unlike R134a, which is an inert gas, it is flammable, toxic and (with moisture present) corrosive to some metals (such as copper). This makes it unattractive for many applications, such as computer room air-conditioning (CRAC), where it puts both people and potentially mission-critical IT infrastructure at risk.
Count to four, a new compound is at the door Fortunately, there are much more suitable compounds available. The most promising one for datacenter-type applications is R1234ze, a so-called fourth-generation refrigerant with zero ozone depletion and negligible global warming potential. As a hydrofluoroolefin (HFO) compound, however, it is classified as mildly flammable by climatic industry body ASHRAE (American Society of Heating, Refrigerating and Air-Conditioning Engineers). Even though it is difficult to ignite (lots of energy required), this will require some changes to the design of cooling and fire-suppression systems, as well as to the operational procedures around storing it and maintaining equipment that uses the gas, particularly in a closed environment such as a computer room.
Another issue is performance: R1234ze has lower cooling capacity relative to R134a, which means it can absorb less thermal energy for a given volume. This means it is not ideal as a drop-in replacement in existing cooling systems unless a drop-in cooling capacity is acceptable, alongside marginal fire risks, for the operator – for example, enterprise sites with low utilization. But changes required to support R1234ze are relatively minor, and chiller-manufacturers have already started rolling out new products that accept this environmentally sustainable refrigerant with a new compressor option. The cost of adoption is not negligible: peak cooling capacity is about 10-25% lower for a similar configuration (same frame size, number of compressors, number of fans, etc.). This means more expensively configured and possibly larger (or more) chiller units for a given IT load where R1234ze is used.
An intermediate option is to blend the currently established R134a and one of the new refrigerants in various mixes. Such cocktails (e.g., R450A, R513A) offer very similar performance to R134a in datacenter applications and lower greenhouse effects by about 50-70%, depending on the mix. Loss of cooling capacity and efficiency is marginal, so it should not be of concern unless the datacenter site is already running at design capacity.
It is for these features that the industry widely considers such blends as drop-in replacements to R134a to be a cost-effective measure to increase environmental sustainability while addressing the supply issues of pure R134a. These blends will give datacenter operators more time to weigh their options and plan for upgrading equipment. Long term, 451 Research expects these blends to give way to R1234ze and other substances with very low GWP.

By Steve Hone, CEO The DCA
Ever tried fishing and wondered why the guy next to you always seemed to catch not only more but catches the biggest fish, while your net remains woefully empty? Rather than struggling on alone, if you took the time to ask you would probably find it was a simple case of having a better strategy, better position and / or better bait.
Speak to any business owner irrespective of the sector and you will quickly discover you are not alone when it comes to the challenge of identifying the right people needed to help drive your businesses forward. Finding the right skills, at the right time and at the right price can be a real uphill battle. This is even more evident when you are working at the leading edge of technology such as those relating to the resources needed within the data centre sector.
Workshops and other events I have recently attended had an increased focus on the issue of gender diversity within the data centre space. There is no doubt that our sector is currently very male dominated, and the data centre trade association is working with its fellow strategic partners to address this issue.
For the DCA, the issue of gender diversity forms part of a far larger ͞Sustainability Initiative͟ which is equally addressing both the challenges we face with a looming labour shortage and the challenges of ensuring that this new labour force has the skill set required to hit the ground running.
With such growth forecasts and career opportunities on offer you may well be lulled into thinking this should be an easy task to solve. If only it were that simple!As previously mentioned we are not alone in this challenge, and the competition we face is fierce. Almost every sector is reporting the same challenges and concerns and there lies the issue. We face far stiffer competition from other industries who are all equally looking for the same sort of skill sets as us, and quite frankly they are doing a far better job at attracting the attention of those we desperately need in the DC Sector.
To attract the right people the DC Sector needs to not only do a better job promoting the data centre sector from an awareness perspective but also to ensure that students studying Mechanical Engineering, Electrical Engineering, Computer Science etc., are able to accessspecialist modules that specifically focus on the Data Centre sector.
Awareness and accessibility to qualifications go hand in hand if we are to stand any chance of fixing this growing issue. The data centre sector continues to flourish creating opportunities not just within the data centre itself but also the supply chain of manufacturers, installers and consultants which under pin it. This in turn creates job opportunities not just for graduates but equally students studying for A Levels, BTEC’s, and similar technical qualifications at UTC’s, Technical Colleges etc.
All of these students need to be made aware of the fantastic opportunities which exist within the Data Centre sector and to be given the tools to enable them to select our industry as their chosen career path. The Data Centre Trade Association continues to work with Industry leaders such as CNet Training, the Academic Community and Policy Makers to raise the profile of the Data Centre Sector and we would welcome your collaborative support.
In summary, it is vital that as a sector we work closely together to ensure we have the right strategy, the right story and the right bait to increase our chances of attracting the prize of new talent into our net rather than into everyone else’s.
Many thanks to those supporting members who summitted articles for this months Journal edition. Upcoming themes include Research & Development in September with a deadline of 14th August 2018 and Smartcities, Big Data, Cloud, IoT and AI coming up in October with a deadline of 12th September 2018. If you would like to submit content, please contact Amanda McFarlane –amandam@dca-global.org / 0845 873 4587.
By Steve Hone, CEO The DCA

By Dr Terri Simpkin Higher and Further Education Principal at CNet Training
Skills and labour shortages are an often cited and lamented data centre sector issue. The topic is examined, dissected and argued at events, workshops and meetings all over the globe. More often than not the usual suggested responses are trotted out and people nod in agreement and the lack of advancement of the topic is bemoaned.
Getting into schools, raising the profile as an employer and getting universities on board with specific education programs are all repeated "go-to" resolutions. And while these are clearly common sense suggestions there are some fundamental platform issues that make it more difficult than it appears at face value. If it were less complex, we (and many other sectors facing the same issues) would have the problem resolved by now.
One of the most obvious responses to lack of talent, too, is the lack of women in the data centre sector. It really is an obvious resolution to a highly observable and problematic lack of diversity. However, as with the other fundamental capability and talent concerns being faced by our sector, getting more women into our organisations is not quite as straightforward as putting out the welcome mat and inviting them to participate.
Why diversity matters
The business case for more inclusive workplaces has been made for decades. Organisations such as the World Bank, The World Trade Organisation and the United Nations1 for example, have all published robust arguments as to why getting more women into the workforce, to meet their potential for economic contribution, is good business. The World Economic Forum suggests that at current rates of improvement (using that word in a very loose fashion!) the gender gap in regard to parity of access to privileges such as pay and rewards, access to economic participation, political participation and education, will take 217 years to achieve2.
A raft of research, both empirical and industry based tells a story of greater innovation, better decision-making, greater efficiency and improved profitability where a diverse workforce and board representation is present3. As a business case, it's a bit of a "no-brainer" and one that is intuitively self-evident.
Despite the compelling arguments put forth, getting women into science, technology, engineering and mathematics (STEM) occupations, particularly at the leadership and senior management levels, is a key challenge. Organisations such as WISE, WES and POWERful Women are charged with raising the profile of women in STEM sectors and lobbying for greater representation in the STEM workforce.
Research recently delivered by WISE suggests that women make up 24 per cent of the STEM workforce in the UK. In terms of professional engineers, women represent 11 per cent with 27 per cent of the science and engineering technician roles occupied by women. In professional ICT the number has dropped by 1 per cent to 17 per cent and 19 per cent of the ICT technician population is women. In management roles in science, engineering and technology women represent 15 per cent. Looking at the audience at any data centre event and you'll find far fewer women than that.
So, what’s going on?
The reasons for a general lack of women in STEM are complex. Social and organisational barriers have long existed and are difficult to shift. The work of Angela Saini, for example, paints a picture of long held, but erroneous, assumptions about the capabilities of men and women. In her book Inferior4, she recounts a raft of scientific studies that have set up the "nature" over "nurture" argument for women being less capable in the sciences for example.
Take this comment from Charles Darwin who wrote in correspondence that states "I certainly think that women though generally superior to men [in] moral qualities are inferior intellectually... and there seems to me to be great difficulty... in their becoming the intellectual equals of man" (Saini, 2017:18).
Fast forward to more recent times and Saini tells of a raft of research that misinterprets social conditioning for "natural" ability in terms of the capacities of men and women. Essentially, we've been conditioned to believe that men are better at sciences and women are better at humanities. While this is still a strongly held belief, neuroscience is now debunking the myth. Social and workplace attitudes are a long way from being brought up to date, however. Even our schools still actively, if implicitly, push girls into social sciences, creative and humanities subjects rather than routinely offering a broader range of science based learning to all students. My own research into women in STEM illustrated a shocking statistic that 89 per cent of respondents experienced the impostor phenomenon; the unfounded feeling of being a fake in their own STEM occupation.
We know that girls are underrepresented in science at senior levels of secondary education, but do better in assessments. Girls represent about 35 per cent of all students enrolled in STEM related studies with some of the lowest representation in ICT and engineering. A disproportionate attrition of women from higher education STEM courses continues into early career and even in later career5. It's not so much a leaky pipeline as a leaky funnel.
Career decision making starts early
We know that when considering occupations, the first decision children unconsciously make in divesting options is made on the basis of gender. If girls see no women around them in engineering, IT or broader STEM occupations they'll consider them "men's" jobs and fail to consider them as suitable.This happens at early infant school age and the tragedy is, it's unlikely that they'll reconsider those options later in life. The data centre sector then, is well and truly off the agenda.
The dearth of visible women in the sector is perpetuating a lack of awareness and failing to paint the sector as an option for girls who will go on to consider other options more consistent with the gender roles they are aware of from their parental, social and educational contexts.
So, the upshot of all this is that there are fewer women to choose from, but suggesting that there are no women to hire is an easy out. Employers that want to find women will. And here's how...
Get critical
Organisations that actively examine their processes and procedures for implicit bias are likely to be more successful at attracting women. This includes recruitment and selection, reward and recognition and succession planning for example. It's known that a broader pool of talent can be tapped into by changing language, broadening out the "wish list" often used by hiring managers and creating more inclusive role descriptions.
This is not just to attract women.
If a critical view is taken in an attempt to rebuild traditionally oriented workplace structures to reflect a more diverse workforce, then it naturally expands the talent pool to those from different socio-economic and social backgrounds as well as women. This is far from being a process of "feminising" structures and processes, but of "humanising" them. It is not a zero sum proposition where the focus is on women at the expense of men, but a recognition that the workplace and demands of workers has changed irreversibly, but our workplace structures have not. The second machine age workplace is still running with industrial age structures. It's like trying to run a data centre with ENIAC.
The traditional mechanisms we use to manage organisations have been built for men by men6. This is not a criticism but a historical fact. It's known too, that hiring managers often hire in their own image. Challenge that and diversity is more likely. We also know that culturally embedded practices such as networking within a narrow social circle (read the traditional "boy's club" moniker here), excludes women and men who lie outside of that circle. Expand that out and the talent pool will open up.
But I’ve done some unconscious bias training, won’t that do?
In three words? No, no and a resounding no. Unconscious bias training is a good start to raise awareness but it won't change the culture. It may stop people from telling "blonde" jokes but it's known that in isolation it does not work7. Indeed, research suggests that it's more likely to infuriate men and fail women. Recall the Google diversity email manifesto scandal8 and the backlash against the "me too" movement.
Organisations that actively examine the "back of house" processes, policies, values and procedures in alignment with unconscious bias training over the long term are more likely to reap rewards.
Start now
Theres a broad ranging sector imperative at risk here if organisations continue to drag their feet on critically reviewing workplace practices. With a sectoral disadvantage associated with a lack of visibility in comparison to other sectors such as manufacturing and construction, the war for talent has never been so intense. It makes sense for data centre organisations to get wise about the reconstruction of outmoded structures and attitudes that are not serving the talent attraction agenda. The skills and labour shortage will not be resolved unless the recruitment, retention and advancement of women is actively advanced and perpetuated.
To inform a better approach to inclusion, as part of my role within CNet Training, I'm revising my global work on the experience of women in STEM to focus on women in data centres. This empirical research aims to better understand the structural barriers to entry, retention and advancement of women in the sector. Work such as this will provide a clearly articulated suite of evidence that the sector can use to formulate an evidence-based response to an all-pervasive and entrenched issue of lack of workforce diversity.
Dr Terri Simpkin
Higher and Further Education Principal
CNet Training
1 https://en.unesco.org/sites/default/files/usr15_is_the_gender_gap_narrowing_in_science_and_engineering.pdf
https://www.wto.org/english/tratop_e/womenandtrade_e/gendersdg_e.htm
http://www.worldbank.org/en/topic/gender
2 https://www.weforum.org/agenda/2017/11/women-leaders-key-to-workplace-equality
3 https://www.mckinsey.com/business-functions/organization/our-insights/delivering-through-diversity
4 Saini, A. 2017. Inferior. How Science Got Women Wrong... and the New Research That’s Rewriting the Story.London. 4th Estate.
5 http://unesdoc.unesco.org/images/0025/002534/253479e.pdf
6 https://theconversation.com/what-the-google-gender-manifesto-really-says-about-silicon-valley-82236
7 http://time.com/5118035/diversity-training-infuriates-men-fails-women/

By Dr Umaima Haider, Research Fellow at the University of East London

Over 800 stakeholders were trained globally through various events organised by the EURECA project
The EURECA Project
EURECA was a three-year (March 2015 – February 2018) project funded by the European Commission’s Horizon 2020 Research and Innovation programme. It was aimed at providing tailored solutions to help identify the cost saving opportunities represented by innovation procurement choices, as related to the environmental impact of these choices, for public sector data centres. One of the main objectives of the EURECA project was to:
"Provide tailored procurement practical training and awareness programmes covering environmental, legal, social, economic and technological aspect".
The main purpose of this objective was to bridge the knowledge gap between non-technical officers and technical stakeholders to improve solution viability and engagement in environmentally sound products and services.
For further information, please visit the EURECA project website at www.dceureca.eu
The EURECA Training Kit
During the project’s lifetime, a training curriculum (called the "EURECA Training Kit") was designed to help stakeholders identify opportunities for energy savings in data centres.
In relation to the EURECA objectives, the training kit has 9 modules divided into two categories, "Procurement" and "Technical". The procurement courses (6 courses) cover various different aspects of innovation procurement such as policy, strategy, tendering and business case development. The technical courses (3 courses) cover best practices, standards and frameworks related to data centre energy efficiency.
All the EURECA training modules are available electronically and accessible freely, and the majority of the modules come with video recordings. The modules can be accessed via this link: https://www.dceureca.eu/?page_id=2064
Training Approach
The EURECA training modules enable stakeholders to play a crucial role in delivering an effective efficiency and cost control strategy for their data centres. 815 stakeholders were trained across the world through various events organised by the EURECA project. More specifically, 10 EURECA face-to-face training events were held across Europe (UK, Netherland, Dublin and Paris, to name just a few). Two webinars and two bespoke training events were delivered at stakeholder premises. One of the webinars was dedicated to European cities while the two bespoke training sessions were tailored for senior stakeholders from the Irish and UK Governments.
Training Outcome
Overall, 46% of the EURECA training attendees came from the public sector, as compared to 54% from the private sector. 71% of the participants attended face-to-face events, whereas 29% joined the webinars. Finally, the vast majority of attendees (80%) came from EU member states. This is illustrated in Figure 1 below. There was a diverse set of stakeholders attending the EURECA training events. The following groups were represented: C level IT executives, ICT/Data Centre/Energy managers, policy makers at EU level, procurement experts and academic researchers.

Figure 1: EURECA Trainee Analysis
Finally, these numbers (and consequently, the analysis) do not include stakeholders whose capacities were increased via other modes of knowledge sharing. Similarly, these figures do not include the number of people who attended/downloaded the online training curriculum available on the EURECA website. This number is regularly increasing; However, given that we cannot be sure whether the people who download the files actually go through them, or how many unique users downloaded the files, we decided to leave this number out of our analysis. Yet the contribution of this online platform towards building the capacities and skills of stakeholders should not be underestimated.
Going Forward ...
Based on the lessons learned from the EURECA pilots and from other project activities, the bespoke training kit designed under EURECA can be considered a world first. It captures the knowledge hotspots identified as crucial for successfully implementing energy efficiency projects in the data centre industry (targeting the European public sector). Thus, it has helped to build a substantial pool of capacities and skills in the field of data centre energy efficiency.
Going forward, we anticipate the online platform playing a key role in the continued dissemination of knowledge. The training programme will be maintained by the EURECA partners to ensure its currency and alignment with the various developments in standardisation, legislation, and best practices. Additionally, EURECA members continue to deliver face-to-face training and awareness sessions, such as the ones done recently at Data Centre World London in March 2018, Uptime Institute Network EMEA Conference, Vienna, in April 2018 and Datacentres North, Manchester, in May 2018.
AUTHOR: Dr Umaima Haider
JOB TITLE: Research Fellow
ORGANISATION: University of East London
BIO: Dr Umaima Haider is a Research Fellow at the University of East London within the EC Lab (https://www.eclab.uel.ac.uk). She held a visiting research scholar position at Clemson University, South Carolina, USA. Her main research interest is in the design and implementation of energy efficient systems, especially in a data centre environment.
CONTACT: uhaider@clemson.edu

By Julie Chenadec, Project Manager, Green IT Amsterdam
The month of May marks the 4 years anniversary of my arrival in the Netherlands when I started my first internship at Green IT Amsterdam.
Upon my arrival, I discovered a, new for me, booming industry: Information and Technology. Digging into that world, I discovered new concepts and technologies such as distributed data centres, smart grids, cloud technology, server virtualisation and so on and so forth. Just like every layman, I knew how to use the Internet on my phone and laptop, but I knew nothing about what is behind the curtain. As my work evolved, I also came across another related industry challenge: the sense of urgency. Data grows so fast nowadays that sustainability is a necessity. Not only to scale-up but also as an enabler towards sustained IT critical infrastructures.
Take for example IT on its own: as data centres are the backbone of our digital economy, our use of digital services generates huge amount of data traffic every year and its rising every year. In Europe, data centres energy consumption is expected to reach 104 TWh by 2020, despite the use of more virtualisation and cloudification, (or even perhaps because of it?). Therefore, we need to think how to turn data centres into flexible multi-energy hubs, which can sustain investments in renewable energy sources and energy efficiency, which is the primary goal of the CATALYST project.
"Data centres can and should offer energy flexibility services to their smart grid and district heating networks", CATALYST project.
As a young professional woman at age 23, showing up in a world traditionally dominated by men was quite a stepping stone for me. Nevertheless, I’ve never doubted my choice to pursue a career on this sector. On the contrary it gave me the opportunity to bring in a fresh, and perhaps in some cases much needed, viewpoint.
4 years later, I can proudly say that "I work in green IT"! Although most of the people outside of this sector barely know it, my colleagues and I have a lot of ambition and vision because we all think that a need for cooperation and knowledge building is by far the most important element to support innovation and breakthrough technologies.
When it comes to Green IT, all stakeholders need to be innovative, technology-savvy, coming up with novel business model, and always find a revolutionary solution (take Asperitas who are in a quest to disrupt the data centre industry with their cleantech solution). IT is a sector that can adapt really fast and actually has the power to change and disrupt itself at its core.
In 4 years, the knowledge and responsibility I gathered is impressive. From analysing the transfer of IT good practices from different European regions, to now being the project leader of a European project, EV ENERGY where we aim to combine clean energy & electric mobility in cities, providing analysis to a number of regional and EU wide projects and launching with 3 other organisations a European multi-country alliance for Green IT (GRIG), I have accumulated both skills and experience.
One that I'm particularly proud of is sustainable leadership and awareness raising. I am confident enough to say I'm a positive and optimistic person in general, while always keen on sharing my vision, explaining the reasons of necessary changes in our society: I solely believe sustainable leadership is the key. It is not enough that we are working towards more energy efficiency with less greenhouse gases emissions, if we cannot reach the society, share our thoughts and take action, we won't succeed in tackling climate change. Ask yourself: "Is my activity providing a positive impact for the society?"
"No smart future without green clouds" Anwar Osseyran
Nevertheless, I envision myself only working in IT. Why? The impact with IT is tremendous. We have the opportunity to work on many different aspects of IT: electric vehicles, smart grids, data centres, energy flexibility, policy-making, etc. as well as working with a lot of different stakeholders. Something that I learned over the past 4 years, is that we need to engage with everyone. Everyone is of importance when we green the IT sector, collaboration is key.
For all these reasons, I particularly want to thank Jaak Vlasveld, Esther van Bergen, Vasiliki Georgiadou and Maikel Bouricious who gave me the opportunity in the first place and trusted me along this wonderful journey. But also to every single person I came across and still meet today, thank you too!
Green IT Amsterdam is a non-profit organization that supports the wider Amsterdam region in realizing its energy transition goals. Our mission is to scout, test and showcase innovative IT solutions for increasing energy efficiency and decreasing carbon emissions. We share knowledge, expertise and ambitions, for achieving these sustainability targets with our public and private Green IT Leaders. Follow us on twitter @GreenItAms; visit our website http://www.greenitamsterdam.nl/.
Article provided by STEM Learning
UK STEM businesses have warned of a growing skills shortage as they struggle to recruit qualified workers in science, technology, engineering and mathematical fields.
According to new findings from STEM Learning, the largest provider of STEM education and careers support in the UK, the shortage is costing businesses £1.5 billion a year in recruitment, temporary staffing, inflated salaries and additional training costs.

The STEM Skills Indicator1 reveals that nine in 10 (89%) STEM businesses have found it difficult to hire staff with the required skills in the last 12 months, leading to a current shortfall of over 173,000 workers - an average of 10 unfilled roles per business.
The findings come as the UK is entering the "Fourth Industrial Revolution"2, a time of significant technological, economic and societal change, along with a Brexit outcome that remains uncertain, and severe funding challenges in schools.
As a result, the recruitment process is taking much longer for the majority (89%) of STEM employers – an average of 31 days more than expected – forcing many to turn to expensive temporary staffing solutions (74%), hire at lower levels (65%) and train staff in-house (83%) or inflate salaries (76%) by as much as £8,500 in larger companies to attract the right talent.
Almost half (48%) of STEM businesses are looking abroad to find the right skills, while seven in 10 (70%) are hiring candidates without a STEM background or simply leaving positions empty (60%).
Businesses are concerned about the outlook too. Over half (56%) expect the shortage to worsen over the next 10 years, with expansion in the sector set to nearly double the number of new STEM roles required.
Employers are concerned that the UK could fall behind other countries in terms of technological advancement (54%) or lose its research and development credentials (43%), while others warn a lack of talent could put off foreign investment in the sector (50%).
Building the future pipeline of skills will therefore be key to maintaining the UK's standing in the STEM sector. Low awareness of the jobs available (31%) and a lack of meaningful work experience opportunities (35%) are identified by businesses facing recruitment challenges as key barriers to young people considering STEM careers.
In a rapidly changing technological environment, the UK government is planning to invest over £400 million in mathematics, digital and technical education3, but businesses will also need to start investing in a sustainable pipeline of talent now.
Nearly one in five STEM businesses (18%) that are finding it difficult to recruit admit that employers need to do more to attract talent to the sector. STEM Learning is therefore calling for businesses to join its efforts to inspire young people in local schools and colleges and help grow the future workforce.
Yvonne Baker, Chief Executive, STEM Learning said: ͞We are heading towards a perfect storm for STEM businesses in the UK - a very real skills crisis at a time of uncertainty for the economy and as schools are facing unprecedented challenges.
"The shortage is a problem for employers, society and the economy, and in this age of technological advancement the UK has to keep apace. We need to be in a better position to home grow our talent but it cannot be left to government or schools alone – businesses have a crucial role to play too.
"STEM Learning bridges the gap between businesses and schools. By working with us to invest in teachers in local schools and colleges, employers can help deliver a world-leading STEM education, inspiring young people and building the pipeline of talent in their area, making it a win-win for everyone."
The DCA are in discussion with STEM Learning regarding the introduction of the STEM Ambassadors Programme from the Data Centre Industry.
For further information contact info@dca-global.org
It was made clear in the presentation from Gartner at April’s European Managed Services Summit that customers were finding it hard to differentiate individual managed services providers and their services. Research director Mark Paine from Gartner told a packed event that while MSP Services were growing at over 35%, it might not last, and certainly the pace of competition was not going to let up. Even so, at the latest estimate, the global managed services market is expected to grow from €150bn last year to €250bn by 2022.
“The key to a successful and differentiated business is to give customers what they want by helping the customer buy,” he told the Amsterdam audience.
In a business where 65% of the buying process is over before the buyer contacts the seller, because of all the information gathered beforehand, the MSP is even less in charge of what happens than in the old VAR model. Without differentiation, the customer is more likely to buy from their usual sources, or at the least, ignore an MSP who does not offer anything different, he says.
But the rewards are waiting for those MSPs who can prove what problems they solve and what makes them special, particularly when the MSP can show how the deal will work and how customers get value, he says. Research shows that product success and aggressive selling carry no weight with the customer, compared to laying out a vision for the customer’s own growth and success.
So a major part of the message in the Amsterdam event, and in the forthcoming London summit on September 29th will be on marketing issues with the aim of getting MSPs up to speed on the current best techniques in building sales pipelines, leveraging available marketing resources, and best practice using social media.
Among the issues challenging the MSP marketing teams is that fact that buying teams are large and extended, containing a variety of influencers, with decision-making spread throughout the organisation. Getting a consistent message through in this environment is a problem which MSPs themselves will be discussing at the London event, which will have speakers who have successfully promoted their message at the highest levels.
One secret about which more will be revealed is that MSPs need to align their businesses with their customers, so that a win for either is a win for the other. Being able to demonstrate this is a good deal-closer. Being able to lay out a convincing vision to improve the customer’s business and to offer this as a unique and critical perspective will win business, says Gartner.
Now in its eighth year, the UK Managed Services & Hosting Summit event will bring leading hardware and software vendors, hosting providers, telecommunications companies, mobile operators and web services providers involved in managed services and hosting together with Managed Service Providers (MSPs) and resellers, integrators and service providers migrating to, or developing their own managed services portfolio and sales of hosted solutions.
It is a management-level event designed to help channel organisations identify opportunities arising from the increasing demand for managed and hosted services and to develop and strengthen partnerships aimed at supporting sales. Building on the success of previous managed services and hosting events, the summit will feature a high-level conference programme exploring the impact of new business models and the changing role of information technology within modern businesses.
The UK Managed Services and Hosting Summit 2018 on 19 September 2018 will offer a unique snapshot of this fast-moving industry. MSPs, resellers and integrators wishing to attend the convention and vendors, distributors or service providers interested in sponsorship opportunities can find further information at: www.mshsummit.com

It’s become a fact of life that hackers might lock down your computer, blocking access to your most valuable data, and vowing to free it only if you pay up. Ransomware is nothing new, but it’s profitable, and hackers are deploying it left and right. By Sandra Bell, Head of Resilience, Sungard Availability Services.
Mitigating ransomware is actually fairly straightforward. If you have backups, if your network is segmented, really all you have to do is wipe the infected computers, and reimage them from backups. If you’re prepared, the recovery takes maybe 20 minutes.
But if it’s so easy to recover from ransomware, why is it still such a problem?
It comes down to human psychology. If we truly want to stop ransomware in its tracks, it takes an understanding of the real problems that this malware preys on.
Here are four things you need to know about ransomware if we’re ever going to stop it.
1. The real target of ransomware (might not be what you think)
If you think your IT systems are the target of ransomware, you’re not alone. But you’re also not correct.
Your IT systems are just the delivery mechanism. The real target is your employees.
Ransoms rely on psychological manipulation that IT systems aren’t susceptible to (AI isn’t there just yet). The systems are the prisoner being held for money.
The psychology of ransomware is complex, and the two main types — locker and crypto — use different tactics and are successful within different populations of people (more on this later).
It’s not just a case of getting your workforce to abide by security rules and keep their eyes open for dodgy ransom notes (this just helps prevent the data and system from becoming prisoners).
You must recognize their unique psychological susceptibilities and design work practices that prevent individuals within your workforce from becoming attractive targets.
2. Who is more likely to fall for ransomware and how to stop them
As mentioned above, ransomware uses complex psychological tactics to get their targets to pay. The two main types of ransomware play off different psychological vulnerabilities.
Crypto finds and encrypts valuable data and typically asks for a fee to unencrypt the files, often creating a time pressure for paying. Crypto plays on the “endowment effect” in the victim, taking advantage of the value people place in what they own versus what they don’t.
It also makes use of the Ellsberg Paradox by making it look like there is a certain, and positive, outcome if the target complies with the ransom demand (e.g., they get their data back), as opposed to an uncertain, and potentially negative, outcome if they don’t (e.g., their boss will be mad and they may or may not lose their job).
By contrast, locker ransomware typically locks a system, preventing the target from using it and imposes a fine for release. It often works by deception, with the perpetrator posing as an authority figure who has supposedly identified a misdemeanor and uses the dishonesty principle — the conviction that anything you have done wrong will be used against you — to get you to comply with their wishes.
The effects of both these tactics are greatly amplified if the target is physically isolated from their colleagues and their organisational support network, or even if they perceive themselves to be.
When you look at the victims of ransomware, they’re often remote workers or people who associate themselves primarily with their profession rather than their employer (e.g., doctors, nurses, policemen, and so on).
If you’re in an open-plan office and a ransomware screen pops up, you’re likely to point it out to your colleagues before acting yourself. However, if you are in your home office or feel only loosely affiliated with your employer, you’re more likely to take matters into your own hands.
The risk of ransomware can be reduced by fostering a corporate culture that reduces the feelings of real or perceived isolation.
3. How to short-circuit the entire value prop behind ransomware
If you’re hit with ransomware, your data and IT systems are the ransom prisoners, held hostage until the perpetrators receive payment. But there’s a crucial difference between your data and the traditional prisoner in a ransom scheme, like a person or an object of monetary value.
Data, unlike a person, is easily copied or cloned. When you think about it logically, hackers shouldn’t be able to hold data for ransom by withholding access to it. If you always have a copy (or the ability to create a copy), there’s no point in paying a ransom to have the original released.
Likewise, it’s now the norm to access our data through multiple devices, which means that locking one access route has limited impact.
While the only option for goods and people is to deploy security measures to protect them, data and IT systems can be protected by duplication. It’s not only cheaper, but also more practical.
The perpetrators could of course threaten to publicise sensitive data they hold to ransom, but this is technically “extortionware” rather than “ransomware.”
4. How companies avoid becoming ransomware victims
Ransomware attacks aren’t over when your systems get infected and locked down. When you launch your response and recovery, the attack is almost always still taking place, and you might have to shift strategies on the fly.
As any military commander will tell you, “plans rarely survive first contact with the enemy.” This means that if you only have a single response plan, without the means to deviate from it, your opponent will quickly learn what it is and overcome it. In short, you will become a victim.
Obviously, it’s essential to have a solid backup strategy and business continuity and disaster recovery arrangements in place. But your response won’t succeed unless you also have the crisis leadership skills and knowledge to adapt your response in real time. You must lead your organisation through the complex, uncertain, and unstable environment that’s created by a large-scale ransomware attack.
How do you stop ransomware?
There’s no single solution to the ransomware problem. However, organisations that are most successful at managing the associated risks have taken advantage of features that data and IT systems offer to back up and protect their data, while recognizing that much can be done to safeguard their people from becoming targets.
By understanding the psychology behind ransomware and how it affects your employees, you can sidestep the risk of ransomware and avoid becoming the next victim.


As any IT professional knows, running large and resource intensive workloads in the cloud is extremely difficult. The cloud is often billed as a panacea, but the truth is that for most organisations, architecting large workloads in the cloud is a heroic endeavour – one that must be executed with exact precision. There is no margin for error, and one small misstep can result in nightmares for CIOs. By Jake Echanove, Director of Systems Engineering, Virtustream.
According to the Forrester study, "Cloud Migration: Critical Drivers For Success", 89% of early migrators have experienced performance challenges after migrating their mission-critical applications. Running mission-critical applications in the cloud is difficult. Alleviating risk, limiting business disruption and ensuring the target architecture will satisfy the most stringent SLAs and performance requirements requires extensive experience and a special skillset that is rare in the industry.
A few months ago, I was speaking with a prospective customer about his organisation’s current infrastructure situation. They were in a tough spot: to stay competitive, his company needed to push its SAP workloads to the cloud. However, in his view, this wasn’t going to happen anytime soon. With a 50+ terabyte database and over two million transactions daily, shifting to cloud wasn’t a real possibility - not even a remote one.
He told me, “There’s no way you can do that.” and his general thinking is actually correct. Most cloud services providers can’t handle what he was looking for. However, with the right experience, technology, and approach, it can be done; I’ve solved my fair share of difficult engineering problems, including some like this. Here are four recommended features to look for in a cloud provider that will enable your organisation to successfully move extreme workloads to the cloud:
1. Purpose-built Hardware
Firstly, it is vitally important that your cloud infrastructure is powered by hardware that is purpose-built to support mission-critical workloads. Purpose-built hardware provides better performance and control as it is specifically designed to suit the needs of your organisation. Your reference architecture should capitalise on enterprise-grade infrastructure to provide the necessary storage, compute, and networking equipment to handle even the most aggressive workload requirements.
2. Connected Infrastructure-as-a-Service
One of the most powerful features for mission-critical cloud migration is Connected IaaS, a dedicated kit that supports the most resource intensive workloads. The environment connects to a general, multi-tenanted infrastructure so that organisations are able to run workloads such as the 50TB, multi-million transaction beast mentioned above alongside more general purpose workloads. Additionally, Connected IaaS helps to meet the most stringent compliance and security requirements, and is capable of connecting with other cloud services.
3. Cloud Management Platform
A cloud management platform is essential for providing a unified, cloud-agnostic control pane that can bring together infrastructure orchestration, enterprise application automation, business intelligence (BI) and service delivery into one single convenient tool. A cloud management platform can allow organisations to run mission-critical enterprise applications in the cloud, with the performance and scalability needed to be competitive.
4. Cloud Resource Technology
Another highly valuable feature is MicroVM, a unique cloud resource technology that ensures cost efficiency, no matter how demanding or complicated the workloads. Research has shown the importance of cost efficient for organisations, with 52% embarking on their cloud migration journeys to achieve cost savings. As part of the xStream Cloud Management Platform, the MicroVM construct is able to dynamically tailor resource allocation to meet the exact workload demands and then, like a utility provider, only bills for the resources used.
So, it is clear that migrating and managing mission critical applications in the cloud can be a challenging process. Choosing an experienced cloud provider that is able to accommodate your mission-critical cloud needs is essential; feature enterprise-grade infrastructure, Connected Iaas, a cloud management platform and cost-saving resource technology are all essential in maintaining a smooth transition.
Most importantly, enterprises should partner with a provider whose expertise is in running SAP in the cloud whereby experts have extensive experience working directly with SAP and other mission-critical applications. Whether like the client I mentioned, you have a 50TB database, or have the data of millions of customers to uphold, there are excellent solutions to ensure the performance and security of your business is not compromised. Given the clear advantage to enterprises, it is unsurprising that the migration of mission critical applications continues to grow. By 2019, 62% of organisations engaged in active cloud projects are expected to migrate and with the correct cloud provider, your organisation could be one of them.

According to Cisco, there will be 50bn network attached communications/computing devices in operation by 2020 and expects some 20.8bn items to comprise the Internet of Things (IoT). As a result, the growth in digital traffic is predicted to treble during the next five years.
Inevitably, data centre infrastructure vendors are responding to this demand by creating solutions using a range of prefabricated, standardised and modular architectures. This pre-configured and pre-tested approach is not only practical, but with a variety of form factors and configurations available in the market today, they provide maximum flexibility to businesses with need to deploy a new data centre resources, or expand capacity, fast.
Regardless of deployment, one size does not fit all in the data centre world. Expansion requirements differ from customer to customer and in some situations, an operator may want to deploy an entirely new, integrated solution containing all of the power, cooling and IT infrastructure in a single prefabricated system.
In another, the customer may need only to upgrade just one of the three functional blocks—power, cooling and IT equipment. This could be required to add capacity to equipment inside an existing building, but should space be a limitation, it would be delivered in a weatherproof or ruggedised enclosure to be positioned in a location adjoining an existing structure.
Nevertheless, all prefabricated modules are built to established industry standards—essential to ensure interoperability and speed of deployment between equipment and tested prior to leaving the factory. This leaves a minimum amount of integration work to be carried out on- site, providing a system that is as close to “plug and play” as is possible for mission-critical infrastructure.
Functional Blocks
Prefabricated modules are available in a variety of functional blocks, form factors and configurations and can be broken down into three major categories: power plant, cooling plant and the IT space.
Frequently, an existing data centre may only require enhancements in one of these areas: extra resource may be needed to exploit stranded capacity, or conversely additional IT capacity may need to be added quickly to meet increasing customer demands.
A prefabricated IT space houses all of the IT equipment and the accompanying support infrastructure. Typically, such a module includes racks, power distribution units (PDUs); air distribution systems, fire detection and suppression systems, security systems, lighting and cabling.
Power modules can provide resiliency for both modular and traditional IT spaces. A typical power subsystem comprises switchgear and switchboards, UPSs (uninterruptible power supply systems), batteries, transformers and power distribution to the IT racks. Standby generators, if required, are usually delivered as a separate module.
Cooling requirements for data centres depend on a number of factors, including the prevailing climate of the region in which the data centre is located. There are also important trade-offs to be made in terms of cost, performance, reliability and efficiency. Therefore a wide variety of cooling infrastructure equipment is now available in modular form including: chiller plant modules, direct exchange and indirect air modules.
Form Factors
The size and shape—or form factor—of prefabricated system also varies dependent on the exact requirements of the customer.
In some cases, modules will need to be deployed outside an existing building or indeed comprise the entire data centre system. In such cases they may be supplied in an ISO container, a standardised reusable steel shipping enclosure, which is weather proof and can be deployed outdoors at any location, regardless of space constraints.
ISO containers are also designed to fit standard shipping systems used by rail, sea and road transport operators. In this way they can be delivered quickly and cost-effectively to customer sites. They generally have a practical capacity limit of around 500kW for power or cooling plants and between 200 and 250kW for an IT space and are therefore best suited for “drop-in” capacity upgrades in smaller data centres.
Customised enclosures sacrifice some of the ease of transport of ISO containers to enable greater flexibility, both in terms of the IT capacity they can support and in the layout of the equipment. In some cases they will not meet the specific dimensions of ISO containers, therefore transport and handling costs will be greater and more onsite work may be necessary to complete the integration.
Such enclosures are often rated for outdoor use and can be exposed to a variety of weather conditions. A key driver for choosing an enclosed or customised form factor is capacity and the need for the data centre to be protected from the elements in hazardous or ruggedised environments.
The third form factor is the skid-mounted module in which the equipment at point of manufacture is permanently mounted on a frame, rails or a metal pallet. As such, it can be easily transported and installed as a unit.
Skid-mounted modules are generally not designed for outdoor use and are most commonly used for power modules, as items like switchgear, UPS and transformers do not have to be outdoors, unlike many cooling modules. Equipment in skid-mounted modules are open to the space and therefore not conducive to separating hot and cold air flows, which makes them inappropriate for housing IT spaces.
There are also fewer capacity constraints due to footprint limitations with skid-mounted power modules, when compared with ISO containers or non-standard enclosures. As such, they can support larger data centres, and as power requirement increase, the skid-mounted approach becomes more attractive.
Configurations
When it comes to implementing functional blocks, there are generally three categories: semi-prefabricated; fully prefabricated and micro data centres.
The semi-prefabricated approach sees prefab modules deployed alongside existing systems in a traditional or purpose-built data centre. This typically happens in cases where capacity is constrained or in need of upgrade. For example, additional power and cooling modules could be deployed alongside the traditional IT space within a building, or extra IT space could be added outside a facility already adequately supplied by power and cooling. The specific combination will of course depend on the needs of the customer.
In the case of fully prefabricated data centres, modules are implemented for all three functional blocks—power, cooling and IT. This approach is generally used in cases where scalability is a key business driver and operators may wish to deploy equipment in a pay-as-you-grow manner. A colocation or multi-tenant data centre (MTDC) may also use them to separate physical equipment belonging to different customers.
Micro data centres are a subset of the fully prefabricated category but house all the functional elements in a single enclosure. Such modules are usually limited in terms of size to power ratings of about 150kW. Nevertheless, they provide great flexibility of deployment and are very well suited to Edge Computing environments, especially those requiring high resiliency and security. They can be used for factory or industrial automation applications; in temporary situations such as major sporting or cultural events; or, with a suitably rugged enclosure, in harsh remote environments such as oil or gas extraction.
Conclusion
With many applications sharing a common need for rapid deployment of new data-centre resources, there is a clear need for IT equipment and its attendant infrastructure components to be made available in modular prefabricated format.
As the requirements of different applications vary, so too must the choice of prefabricated modules available in the market. As such, there are now numerous options in terms of functional blocks, form factors and configurations now available to meet customer needs.
Schneider Electric White Paper #165, ‘Types of Prefabricated Modular Data Centers’, describes many of these options in more detail and can be downloaded by clicking here, or visiting http://www.apc.com/salestools/WTOL-97GLP9/WTOL-97GLP9_R2_EN.pdf

Service providers are increasingly required to deploy a mix of wired and wireless services in their networks in a bid to meet the growing demands of ever-evolving broadband services and 5G wireless technology. With this evolution driving the need for service delivery to be brought closer to the network edge, many operators are also having to incorporate data centre functionality into their central offices alongside more traditional telecommunications services and, as these data centre and telecommunication services converge, different service provider groups will need to work together. By Craig Doyle, Director, CommScope.
Supporting low-latency data applications and standard telco services in the same facility will require operators to develop two separate mind-sets, however. Not only will operators need to support the “rip and replace” data centre approach, they will also need to support the developing needs of the traditional central office infrastructure over a long lifetime. Of course, as with any shift in approach, the planning and management of converged services in central offices will bring its own challenges and best practices.
Different architecture, standards and operating models
Edge data centre functionality, catering to those applications that require the lowest latency, such as those related to the 5G network, multi-player gaming or connected cars, is most likely to be hosted in an operator’s central office, alongside its more traditional services, such as FTTH, voice and video. Other applications, such as email servers, SMS servers and less popular video programmes, in which minor delays aren’t critical, will tend to be housed in an operator’s regional data centres.
The architecture, standards and methods of operating edge data centres are very different from that of a central office, however. While central offices tend to work on an equipment lifecycle of between 10 and 20 years, for example, data centres typically work on a three-to-five year “rip and replace” cycle.
When bringing their data centres into the central office, operators will be confronted by a huge fibre network which they’ll need to terminate in a high-density fibre distribution frame for easy access, flexibility, and reliability over a 20-year lifespan, while supporting multiple network evolutions. Accessibility and network density may be critical to this convergence, but so too is long term reliability. To serve an edge data centre in particular, operators must ensure the equipment uses multimode fibre, at a reasonable price on a replacement cycle of three to five years.
It’s clear, therefore, that housing an edge data centre will change a central office beyond recognition.
Developing greater expertise
Traditionally telco-oriented central offices tend to have considerable experience of singlemode connectivity and management. However, as the addition of data centre functionality will require more multimode connections, these particular operators will need to develop greater expertise of multimode fibre management and connectivity.
A knowledge of virtualisation will be an asset too. Long gone are the days of using various different individual network elements to perform a single network function. Operators are now maximising their equipment spend by virtualising network functions, using technologies such as network function virtualisation (NFV) and software-defined networking (SDN) to spread applications across software on servers. Not only is virtualisation more cost-effective, it uses far less space. By enabling operators to put servers and switches on to their networks, for example, these technologies mean that functions and services which might once have required 10 racks of dedicated physical network function equipment can now be handled with just three or four cabinets.
Key to evolution
We may not know what the future holds for network operators, but we do know that flexibility, density and accessibility are key to their evolution.
The use of multifibre push-on (MPO) connectors for fibre cables and patch cords, for example, makes it much easier and more cost-effective to change configurations when needed. While the multimode optics used in data centre services and switches continue to evolve, operators should use panels that include modules which easily enable changes to be made from Lucent connectors (LC) to MPO and vice versa, all while using the same backbone cable.
Fibre platforms and switching equipment should be of the highest density to allow for future growth in connectivity for service delivery. Operators should also give consideration to the use of wavelength division multiplexing equipment to scale capacity in their existing fibre networks. And operators should use fibre panels and frames that will maximise access to fibre connections now and in the future.
Flexible and adaptable infrastructure
Operators may be treading new ground when it comes to the evolution of their central office architecture. It would, therefore, benefit them to work with equipment providers with many decades’ worth of experience of offering both traditional telco and data centre solutions, that will have both the background and the expertise to advise on how they may be best deployed.
Forecasting demand will always be a challenge, especially when relatively unknown quantities, such as next-generation technologies like 5G are thrown into the mix. Operators must, therefore, adopt a flexible and adaptable infrastructure that will allow them to quickly tailor their offerings to meet customer demands. As they do so, we’ll see new the emergence of new, converged infrastructure models, the success of which requires the deployment of new technologies and, most importantly a new way of thinking about the network.


The SCSI protocol has been the bed rock foundation of all storage for more than three decades and it has served, and will continue to serve, customers admirably. SCSI protocol stacks are ubiquitous across all host operating systems, storage arrays, devices, test tools, etc. It’s not hard to understand why: SCSI is a high performance, reliable protocol with a comprehensive error and recovery management mechanisms built in. By Rupin Mohan, Board Member, Fibre Channel Industry Association and Director, R&D, Chief Technologist (SAN), HPE.
Even so, in recent years Flash and SSDs have challenged the performance limits of SCSI as they have eliminated the moving parts: they do not have to rotate media and move disk heads. Hence, what you find is that traditional max I/O queue depth of 32 or 64 outstanding SCSI READ or WRITE commands are now proving to be insufficient, as SSDs are capable of servicing a much higher number of READ or WRITE commands in parallel. In addition, host operating systems manage queues differently, adding more complexity to fine-tuning and potentially increasing performance in the SCSI stack.
To address this, a consortium of industry vendors created the Non Volatile Memory Express (NVM Express®, or NVMe) protocol. The key benefit of this protocol is that a storage subsystem or storage stack will be able to issue and service thousands of disk READ or WRITE commands in parallel, with greater scalability than traditional SCSI implementations. The effects are greatly reduced latency as well as dramatically increased IOPs and MB/sec metrics.
Shared Storage with NVMe over Fabrics
The next hurdle facing the storage industry is how to deliver this level of storage performance, given the new metrics, over a storage area network (SAN). While there are a number of pundits forecasting the demise of the SAN, sharing storage over a network has a number of benefits that many enterprise storage customers enjoy and are reluctant to give up. These are:
The challenge facing the storage industry is to develop a really low-latency SAN that can potentially deliver improved I/O performance.
NVMe over Fabrics is essentially an extension of the Non-Volatile Memory (NVMe) standard, which was originally designed for PCIe-based architectures. However, given that PCIe is a bus architecture, and not well-suited for Fabric architectures, accessing large-scale NVMe devices needed special attention: hence, NVMe over Fabrics (NVMe-oF).
The goal and design of NVMe over Fabrics is straightforward: the key NVMe command structure should be able to be transport agnostic. That is, the ability to communicate NVMe should not be transport-dependent.
The following are standardized methods by which NVMe-oF can be achieved:
So, how would you compare these two options? Here are some thoughts:
|
RDMA-Based NVMe-oF |
NVMe over Fibre Channel |
|
|
Completely new fabric protocol |
Uses Fibre Channel as a base, existing fabric protocol, shipping, standardized by T11 |
|
|
Standards group dealing with same type of challenges, shipping I/O commands/status, data over distance. |
Fibre Channel solved these problems when FCP protocol was developed to ship SCSI commands/status over distance over a FC network |
|
|
RDMA is available as per protocol |
RDMA is not available, uses FCP |
|
|
Zero-copy capability |
Zero-copy capability |
|
|
Transport options are iWARP, RoCE (v1 or v2) and even considering TCP/IP |
Transport is Fibre Channel. No changes to switching infrastructure / ASICs required to support NVMe over Fibre Channel |
|
|
Complex integrated fabric configuration |
Fibre Channel fabrics are well understood |
|
|
Could be lower cost if onboard NIC’s on servers and cheap non-DCB switches are used |
Higher cost, especially the newer generations of Fibre Channel are expensive |
|
|
New I/O protocol, New transport |
New I/O protocol, Existing reliable transport |
|
|
Lower latency if RDMA is enabled |
Latency improvements with hardware assists on Adapters. No RDMA option. |
The Fibre Channel protocol provides a solid foundation to extending NVMe over Fabrics as it already accomplished extended SCSI over fabrics almost two decades ago. From a practical technical development perspective, the T11 group was able to quickly develop FC-NVMe because the Fibre Channel protocol was designed from the beginning with the end-to-end ecosystem in mind. Most mission-critical storage systems run on Fibre Channel today, and NVMe is poised to boost those mission-critical capabilities and requirements even further.
Using an 80/20% example, Fibre channel protocols solve 80% of this FC-NVMe over fabrics problem with existing protocol constructs, and the T11 group has drafted a protocol mapping standard and is actively working on solving the remaining 20% of this problem.
In terms of engineering work completed, the Fibre Channel solution solves more than just the connectivity problems; it’s laser focused on ensuring administrators and end-users of NVMe over Fabrics are guaranteed the level of quality they’ve come to expect from a dominant storage networking protocol for SAN connectivity.
NVMe will increase storage performance by orders of magnitude as the protocol and products come to life and mature with product lifecycles.
There is more to Data Center storage solutions than speeds and connectivity. There is reliability, high-availability, and end-to-end resiliency. There is the assurance that all the pieces of the puzzle will fit together, the solution can be qualified, and customers can be confident that adopting a new technology such as NVMe can come with some well-understood, battle-hardened, rock-solid technology.
With more than 20 years of a time-tested, tried-and-true track record, there is no better bet than Fibre Channel.
Operational efficiency is a high priority for most enterprise IT organizations and service providers, and virtualization is being used in the data centre to meet this goal. By Nadeem Zahid, Sr. Director Strategy & Cloud, Savvius.
Just as service providers have gravitated toward virtualization to cope with the increasing pressures of megabit costs, so too are enterprises following suit. Focus is now shifting toward network virtualization, from the compute and storage virtualization waves. A big trend in this area that can dramatically reduce costs and drive operational efficiency, is replacing traditional proprietary hardware-centric network services with more cost-effective Network Function Virtualization (NFV), which puts those functions into software that runs on commoditized hardware machines.
NFV makes IT infrastructure more flexible, scalable and cost-effective, but the complexity of these new networks makes network visibility, such as Network Performance Monitoring (NPM), a real challenge. Traditional network visibility methods incorporate techniques such as tapping the wire, gathering wireless data, or using traffic mirroring (SPAN) functionality that feeds the data into visibility solutions such as NPM tools. But, when NFV comes into play, it creates a new set of challenges that can create new blind spots. Let’s look at some.
First, following NFV migration an organization is left without physical network devices, which means there’s no wire data to tap into. This means if they are trying to monitor network transactions or trying to capture network data-in-motion, they can only do that where it hits the physical wire. NFV employs multiple Virtual Network Functions (VNF) that run on top of the server’s compute function, rather than within traditional network nodes such as routers, switches or firewalls. Heavily virtualized networks have much more east-west traffic that travels between multiple VNFs and associated data-bases. This is important to note because each VNF is responsible for some specialized function in a ‘service chain’ and if you can’t see that traffic between two VNFs, you can’t ensure a service when it breaks. For example, you cannot capture and analyse the network packets or flows that you would normally use to quickly identify and isolate issues on a traditional network. This can result in war-room finger-pointing, because no one can pinpoint where the issue resides.
Second, it is highly inefficient to backhaul NFV traffic to a physical network or packet broker without multiplying the traffic, wasting expensive network bandwidth and inducing latency (although some use this approach as a “band-aid” solution). And, backhauling east-west traffic in the north-south direction – and simply feeding it into visibility tools – is not only inefficient, it raises business risk because it competes with the actual mission-critical traffic traversing the same network. If mission critical data can’t get through, business continuity will suffer.
Finally, as mentioned earlier, a service (such as eBanking or making a cell-phone call) in an NFV environment might include several VNFs in a chain that is distributed across different machines, compounding the visibility problem. Not only do you need to probe the data at multiple points, but it needs to be correlated and visualized centrally through a single-pane-of-glass and linked to the service in question. If those resources are provisioned close to an existing saturation point, you can create additional bottlenecks. For example, if bandwidth, CPU and memory resources associated with a virtual-switch on a machine are choking, and that machine is already critical to the NFV service chain, it could create unpredictable performance and a poor user-experience (in the form of dropped calls).
All of this requires some creative NPM-based visibility solutions to help eliminate network blind spots. Without the capabilities and insights these solutions can provide, NFV can quickly turn into “non-functional-virtualization” and the business can start losing revenue and customers due to bad user experience.
What’s the solution? While every deployment will have its own unique set of challenges and requirements, here are some tips to consider if you’re already running NFV or considering a rollout:
When deploying NFV, it is vital to have complete north-south and east-west coverage visibility to confidently maintain ‘service-assurance’ levels (or standards). NFV creates a new set of visibility challenges in the distributed enterprise and within service provider networks. If you want to eliminate network blind spots and create a high-performance NFV environment, be sure to have a well-planned visibility strategy in place. You won’t regret it.

In the wake of the Cambridge Analytica scandal - where a British research company has allegedly influenced the US election with the help of illegally-acquired Facebook data - it’s likely that Zuckerberg regrets his teenage bravado. But in many ways, that the throwaway comment is so shocking today is reflective of our changing relationship with data. Now, fuelled by scandals and high profile data breaches, there is a much documented sense of wariness towards big data applications and the commercial use of personal data by private companies.
When asked about trust issues around data, consumers often point to issues of security and opportunistic commercialisation of information. In an interview with The Guardian, one UK consumer pointed out that “too many in Silicon Valley analyse, share, and sell this data with whoever they want.” The public too often feels it doesn’t know what data companies have, whether it’s used properly, and importantly, whether it’s secure.
Whatever the trust issues, the big data revolution is here to stay. It’s too intrinsically woven into the fabric of society to go away. It powers healthcare, travel, shopping and even the way we meet and fall in love. Simply, data makes the world go around. Now the onus is now firmly on the companies who deal with data to work to rebuild trust. They must demonstrate that the data they rely on to execute their business is stored, processed and used properly - and importantly that it’s working, and powering applications we want and will use. Only then will consumers realise that the good outweighs the bad.
How to get big data right
So how do firms throw off the shackles of the scandals and ensure that they’re meeting the public demands for transparency, responsibility and security when it comes to big data?
Many would agree that the companies hit by data breaches or scandals have a big PR job to do to mend tarnished reputations. Apologies must be open and chief execs held accountable. One of the biggest jobs to do is far more fundamental than messaging and PR - and is firmly under the hood of a company. Making sure that big data doesn’t become synonymous with big danger is an operation which starts in the data centre.
Data volumes are growing very quickly. IBM reports that around 90 per cent of all data has been created in the last two years - and that it’s growing at a rate of around 50 per cent annually. Domo, an American computer software company specialising in business intelligence tools and data visualisation, recently released its fourth-annual “Data Never Sleeps” report, which highlights the fact that data is now more ubiquitous than ever – and revealed that more than 1 million megabytes of data being generated by mobile connections every single minute of every single day.
That’s a lot of data. And what companies want to do with it is increasingly complex too. Many applications demand real-time or near real-time responses, and information from big data is increasingly used to make vital business decisions. All this means intense pressure on the security, servers, storage and network of any organisation - and the impact of these demands is being felt across the entire technological supply chain. IT departments need to deploy more forward-looking capacity management to be able to proactively meet the demands that come with processing, storing and analysing machine generated data. Indeed, it's no exaggeration to say that the data centre strategy could be crucial to big data’s ultimate success or failure.
For even the biggest organisations, the cost of having (and maintaining) a wholly owned data centre can be prohibitively high. By choosing colocation, companies are effectively achieving the best of both worlds; renting a small slice of the best uninterruptible power and grid supply, with backup generators, super-efficient cooling, 24/7 security and resilient path multi-fibre connectivity that money can buy that has direct access to public cloud platforms to provide the full array of IT infrastructure - all for a fraction of the cost of buying and implementing them themselves.
It’s maybe obvious that the more data stored, the more difficult it is to ensure its security. In the eyes of the consumer at least, data security is of paramount importance. In September last year, Yahoo announced that they managed to not secure the real names, date of birth and telephone numbers for 500 million people. This is data loss on an unimaginable scale, and of course, for the public, that’s scary stuff.
For many, these concerns mean that a wholesale move to standard cloud – where security may not be as advanced – isn’t an option. Again, looking to colocation options for data storage needs, organisations are quickly recognising that deploying a hybrid cloud strategy, within a shared environment means that IT can more easily expand and grow, without compromising security or performance.
-------
Now is a crucial point in the history of big data. We are actually only just at the very beginning of this data revolution, and the cat is firmly out of the bag. We need data in our business and personal lives. Consumer demand drives everything and big data is no different. As the internet browsing public grows more wary of data breaches, the pressure will (and already has) come to bear on the business community to pay more attention to securing, storing and using data in the right way.
Countermeasures that used to be optional are in the process of becoming standard and increased pressure is being put on company’s IT systems and processes. Proper infrastructure and good data management can only help to control the bad and make the good better.
So, whilst we’ll continue to see big data scandals making waves, the savviest companies will be focusing on what happens under the hood, not in the media limelight. IT infrastructure will make or break the big data revolution. Consumers are no longer - as Zuckerberg would once have had it - ‘dumb’ - and will demand that companies have optimal security and governance procedures and are above reproach in the way they store, process and use data.

Today we live in a world of data — so much so that there’s often too much information available to make clear decisions in a timely fashion.
By Scot Schultz, SNIA Ethernet Storage Forum.
Since data analytics has become an essential function within today’s high-performance enterprise datacenters, clouds and hyperscale platforms, solutions are necessary to better enable and more accurately gauge decisions based on analyzing tremendous amounts of data. With the right data analysis technologies, what was once an overwhelming volume of disparate information can be turned into a simplified, clear decision point. This encompasses a wide range of applications, ranging from security, financial, image and voice recognition, to autonomous cars and smart cities. The technology building blocks include better compute elements, graphics processing units (GPUs) and quite possibly the most important element of technology today - very fast intelligent network pipes to transfer all the data.
Improving the Network with Smart Offload Engines
In legacy architectures of days past, data could only be processed by a compute element such as a CPU or GPU and is commonly referred to as a CPU-Centric architecture. Having to wait for the data to reach the CPU before it can be analyzed created a delay or a potential performance bottleneck. Because of the increasing amount of data today, a CPU-Centric architecture can limit overall data processing, where as a data-centric architecture can be used to overcome unnecessary latency. The fundamental concept behind this new architecture addresses the need to move computing to the data, instead of moving data to the computing, and results in a more modern approach for the datacenter to execute data analytics-everywhere data exists.
We are witnessing the introduction of several advanced capabilities and acceleration engines to address the challenges of the modern-day datacenter by delivering an intelligent network to act as a “co-processor”, which shares the responsibility for computation. By placing the computation for data-related algorithms on an intelligent network, it is possible to dramatically improve both application performance and scalability. The first In-Network Compute capabilities include aggregation and reduction functions that perform integer and floating-point operations on data flows at wire speed, enabling the most efficient data-parallel reduction operations, which is extremely important for both high performance computing (HPC) and artificial intelligence (AI) workloads. In-Networking Computing technologies enable in-network aggregations to minimize the overall latency of reduction operations by reducing the bandwidth they require and their calculation time – thanks to the network devices performing the calculation on the fly.

GPUDirect Technology is one example of In-Network Computing to enable a Data-Centric Architecture
The rapid increase in the performance of graphics hardware, coupled with recent improvements in its programmability, have made graphic accelerators a compelling platform for computationally-demanding tasks in a wide variety of application domains. GPU-based clusters are used to perform compute-intensive tasks. Since GPUs provide high core count and floating point operations capabilities, high-speed networking is required to connect between the platforms in order to provide high throughput and the lowest latency for GPU-network-GPU communications.
The main performance issue with deploying platforms consisting of multiple GPU nodes has involved the interaction between the GPUs, or the GPU-network-GPU communication model. Prior to GPUDirect technology, any communication between GPUs had to involve the host processor and required buffer copies of data via the system memory.

GPUDirect enables direct communications between GPUs over the network
GPUDirect is a technology implemented within both remote direct memory access (RDMA) adapters and GPUs that enable a direct path for data exchange between the GPU and the high-speed interconnect using standard features of PCI Express. GPUDirect provides significant improvement of an order of magnitude, for both communication bandwidth and communication latency between GPU devices of different cluster nodes, and completely offloads the CPU from involvement, making network communication very efficient between GPUs.
GPUDirect technology has moved through several enhancements since introduced, and the recent GPUDirect version 3.0, is also called GPUDirect RDMA. GPUDirect 4.0 or GPUDirect ASYNC is planned to be introduced in the near future, and will further enhance the connectivity between the GPU and the network. Beyond the data path offloads of GPUDirect RDMA, GPUDirect ASYNC will also offload the control path between the GPU and the network, further reducing latency operations at an average of 25%.
Remote Direct Memory Access (RDMA) Doubles AI Performance
RDMA usually refers to three features: Remote direct memory access (Remote DMA), asynchronous work queues, and kernel bypass. Remote DMA is the ability of the network adapter to place data directly to the application memory. RDMA is also known as a “one-sided” operation in the sense that the incoming data messages are processed by the adapter without involving the host CPU. Kernel bypass allows user space processes to do fast-path operations directly with the network hardware without involving the kernel. Saving system call overhead is a big advantage, especially for high-performance, latency-sensitive applications, such as machine learning workloads.


RDMA enables 2X higher performance for Tensorflow, PaddlePaddle and others.
While at the early stages, most of the AI software frameworks were designed to use the TCP communication protocol; now most, if not all (TensorFlow, Caffe-2, Paddle PaddlePaddle and others), include native RDMA communications due to the performance and scalability advantages of the latter.
The capabilities of In-Network Computing are set to continue and further increase performance with the future ‘Smart’ interconnect generations. Today In-Network Computing includes network operations, data reduction and aggregation algorithms, and storage operations. Future capabilities may include tighter integration of the middleware functionality, communications libraries and various elements of the machine learning frameworks themselves.
Looking Further Out
The amount of data being parsed for data analytics, and the amount of data leveraged to make real-time decisions will only continue to increase. Therefore we will see greater demand on the interconnect itself to provide faster data movement and more importantly, to execute data algorithms on the data while it is being transferred. It will not be practical to move the data to the compute elements; as previous, it will be mandatory to perform computational operations on the data where it resides.
As for the interconnect speeds and feeds, 2018 will usher in 200 gigabit per second speeds, and by 2019/2020 the capability to move data at 400 gigabit per second will be available. By 2022 we’ll approach moving data at nearly one terabit per second. We should expect the world to undergo an amazing transformation in how we interact with computers in just four short years due to In-Network Computing and higher transfer speeds. Autonomous self-driving vehicles, humanitarian research, personalized medicine, homeland security and even seamlessly interacting as a global society regardless of language or location are just a few of the exciting elements we will experience within our lifetime; and this is just the tip of the proverbial iceberg that will advance our knowledge and understanding of our place in the universe for generation to come.
About the SNIA Ethernet Storage Forum
The SNIA Ethernet Storage Forum (ESF) is committed to providing vendor-neutral education on the advantages and adoption of Ethernet storage networking technologies. Learn more at http://www.snia.org/esf.

It has been estimated that by 2025, data centres could be using 20% of all available electricity in the world due to the increasingly large amounts of data being created and collected. As a direct result, experts also believe that by 2040, the ICT industry will be responsible for 14% of global emissions. By Janne Paananen, Technology Manager, Eaton EMEA.
Many data centres are already recognising the need to reduce their energy usage and put energy efficiency front of mind, balancing both the need to keep costs to a minimum and consider environmental impact. Many data centres are exploring the possibilities that electric vehicle (EV) batteries can bring to help store electricity in an energy-efficient way. Furthermore, other data centres are trialling the process by which waste heat from data centres are reused – this is being pioneered in the Nordics especially.
However, renewable energy is volatile and if the move to a low carbon economy is going to be achieved, the data centre industry needs to use renewable energy whilst at the same time maintaining a steady power supply. It’s extremely encouraging that more and more energy providers are moving towards renewable energy sources. Last year, 24% of electricity demand globally was produced by renewables such as solar, wind and hydro-power. But – there is a catch here. Intermittency and renewable energy generation go hand in hand.
So – what is the solution?
As the energy market progresses to a fuel-free future, the production of renewable energy sources could itself become more volatile and harder to accurately predict and balance electrical supply. Moreover, the natural frequency stabilisation mechanism of the grid and the amount of inertia is decreasing and this creates greater, faster frequency transients, especially during notable faults.
The instability of a volatile electricity supply is not optimum for data centres, as they depend on a reliable and steady source of energy. With the spike of renewable energy sources and an ever rising demand for electricity, we predict to see more of a fluctuation in the power quality in the grid.
So, what does this mean for the future of data centres? It means that they have the power to play a critical part in helping the energy providers to maintain power quality by balancing power generation with consumption.
Companies within the energy sector need to help other organisations immediately respond to grid-level power demands to keep frequencies within confined boundaries. This will reduce the possibility of grid-wider power outages. So, data centres can be paid back either for not drawing power, or for supplying electricity back to the national grid.
More companies need to consider UPS-as-a-Reserve (UPSaaR) data centre solutions that facilitate earnings from the initial UPS investment. This works well because it places data centres firmly in control of their energy, choosing how much capacity to offer at a specific time and set price. The typical returns can be up to 50,000 euros per MW power allocated to the grid per year.
How to make it work?
A UPSaaR service allows data centre operators to put the UPS to work as part of a virtual power plant that allows them to take part in the demand-side market and in high-value FCR. The UPS can be used to support the grid by replacing demand with the power taken from batteries.
The power that is released, is then seamlessly regulated in parallel with the UPS rectifier to provide an accurate response, which is independent of the load level. Data centre operators can subsequently support the grid in regulating frequency, thus creating extra revenue to offset the total cost of ownership of the UPS, or as part of making the data centre far more competitive from a pricing perspective.
Eaton is an example of an organisation that has demonstrated that UPS systems and batteries can be efficiently and safely deployed to carry out demand-side response operations with minimal risk to the UPS’s primary purpose.
A data centre could work with the likes of a commercial energy aggregator to offer its capacity to a Transmission System Operator or the national grid. A range of service providers can install the functionality and ensure the right communication interface to the aggregator’s systems are in place.
Data centres can truly act as a system for change, helping the UK in its mission to become a low carbon economy. By helping energy providers balance consumption with the generation of power, and by selling electricity back to the grid, they can make a true positive impact on reducing the UK’s overall carbon footprint. It’s time to see more data centres across the country adopt a greener and smarter approach to energy usage.

Anyone considering installing a LAN for long-term usage needs to take two important factors into account: the continuously increasing bandwidth requirement of the active components and the possibility to power devices remotely via data cable (PoE). By Matthias Gerber, Market Manager Office Cabling Reichle & De Massari.
The new cabling standard for Cat. 8.1 could be the solution for both challenges.
Current trends are putting pressure on the LAN and challenging planners and installers. 10-, 25- and 40GBase-T are increasing data throughput in copper cables, but makes them more susceptible to internal and external electromagnetic influences. Installers have to work with the utmost precision as there is no concealed headroom left in LAN cabling.
A little technical background
Transmission performance in the twisted-pair copper cabling is increasing from 10 to 25 and 40 Gigabit/s. Standardization committees have agreed on a quantum leap in transmission frequency, which is increased from 500MHz to 2000 MHz. To handle the resulting increase in attenuation, permanent links will need to be shorter. In the case of 40GBase-T, this distance is limited to 24 m. Recent research indicates, that a distance of 50 m may be feasible with 25GBase-T. For 10GBase-T the distance remains at the known 90 m. Use cases and possible applications need take these shorter distances into consideration.
To date, 40GBase-T was primarily intended for short distance applications in data centers. But an extended reach for 25GBase-T, could make it interesting for the LAN sector. Possible applications for 25 Gbit/s in structured office and building cabling are already becoming apparent. For example, WLAN access points of coming generations will require bandwidths higher than 10 Gbit/s. 25GBase-T with a 50m permanent link range could cover two-thirds of all typical LAN networks. This makes Cat. 8.1 systems potentially interesting for LAN usage. A Cat. 8.1 installation would result in a LAN design in which achievable transmission speeds are directly related to length. With a well-thought-out utilization planning, the most challenging transmission requirements can be met.
Since Cat.8.1 cabling usually uses AWG22 cables, heating issues with PoE applications are not a problem. In normal installation environments, the bigger copper diameter and shielded cable construction of Cat.8.1 will prevent problems resulting from over-heating.
Some practical considerations
RJ45 format connectors of Cat. 8.1 systems offer a tried and tested solution. Alternative Cat. 8.2 connector systems don’t bring any advantages in the area of transmission speed and require relatively costly and cumbersome adapter cables.
When evaluating products, planners should make sure that Cat. 8.1 components are backward-compatible. Therefore, if the user would like to keep using Cat. 6A patch cords, at least 10GBase-T transmission should be possible. However: this is not the case with some products currently on the market! Two measurements for formal acceptance should take place after installation, one for Cat. 8.1 and one for Cat. 6A.
Of course, no matter how well technical specifications are documented or how excellent the quality of the used materials is, a copper installation might still end in failure because a number of essentially simple procedures and considerations have been overlooked. To make sure copper networks deliver on the promised performance, cabling supplier, planner and installer have to work very closely together. Knowing the intended use and smart planning for future bandwidth requirements are crucial. This allows the planner to calculate requirements and give guidance for implementation lengths depending on environments. Essential when making the most of the different length/speed options that are now possible with Cat. 8.1 in the LAN environment.
Variable speed zones in the LAN

As cloud workloads continue to increase, many enterprises are favouring a hybrid cloud model, which as the name implies is the combined use of both public and private resources as part of an overall cloud strategy. By Peter Coppens, VP Product Portfolio, Colt Technology Services.
In such an environment, some of an enterprise’s cloud computing resources are managed in house on legacy server infrastructure adapted for the purpose, while some are handled by an external public cloud service provider.
The reasons for keeping some cloud resources private can be complex, driven often by regulatory demands, or just plain discomfort with placing confidential data in a shared environment, however inaccessible that data may in reality be to others. But private cloud servers do not cope with unexpected peaks and troughs of usage in the same way that a public cloud service such as Microsoft Azure or Amazon Web Services does. Thus when a major scaling of resources is needed, it is helpful to have private cloud resources that are harmonised with a public cloud service. By this means cloudbursting, or sudden spikes of demand, can be handled easily while certain functions remain entirely on-site.
Some enterprises go beyond a simple hybrid cloud model and deploy a mix of different public cloud services from different providers alongside their own infrastructure, perhaps so as to be prepared for a spectrum of possible events.
But whichever hybrid cloud or multi-cloud model an enterprise chooses, it is clear that the connectivity it relies on is more central than ever. What then to look for in a connectivity partner? What properties should a network have if it is to support the connecting of legacy IT hosted in a private data centre with assets sited in a public cloud or multiple public clouds?
The first thing to look for is a connectivity proposition with reach and density. This means a network that has the ability not only to connect branch offices to each other over a very wide area, but one that also boasts the kind of availability and reliability that can support an enterprise’s strategy and growth ambitions. That alone is not enough. The network must additionally connect directly with the data centres where the leading public cloud services reside, providing low latency links into the mission critical digital ecosystem that lives in the cloud.
This issue of latency matters more now than ever, particularly for those enterprises running a multi-cloud strategy. There is every chance that the point of usage for a cloud service could be located some distance from where the workload is housed. For many applications, a lag between these points would render it effectively useless.
The perfect network partner will already have a network that interconnects many different data centres worldwide. To be successful as a hybrid cloud partner, a fibre network has to have an extensive number of data centres connected on its network in all the key regional gateways that data is travelling through to minimise the number of nodes that data must traverse. It is also useful if that network has a reach that extends into major enterprise buildings in the world’s key metropolitan hubs of commerce.
Through ownership of its own assets, combined with a portfolio of partnerships, the network partner will offer the ability to get data from the world’s major aggregation points, to the location where that data is most useful, wherever that is.
Lastly, the best sort of connectivity partner will be one that can show clearly that it has invested to modernise, automate and optimise its network so as to create the best possible fit with the always-on, anywhere-to-anywhere demands of today’s enterprise cloud ecosystem. All the world’s major networks are currently on a journey of transformation, moving towards a future where all functions and controlled by software, and virtualised for ease of management. Not all networks are at the same point on that journey, with some having demonstrably invested to get ahead of the pack while others are playing a longer, slower game of catch up.
The potential for self-service and real time control that enterprises want from a network, managed by themselves through an appropriate portal, is something they should expect today, and not be part of a network provider’s plan for the future. This can only be enabled by a network that is a long way down the path to software-defined networking (SDN).
If you can’t get the on-demand network power you need, combined with a flexible commercial model, you are not going to get the best from your hybrid cloud strategy. Not every enterprise has the same requirements, so feel free to ask your prospective network partner to demonstrate what choices they can offer you. Among their choices should be the building blocks that you require to build the hybrid cloud solution that your business needs. A good network will fit your requirements, not expect you to adapt to fit what it does offer.

Peter Coppens
VP Product Portfolio
Having joined Colt Technology Services in 2000, Peter Coppens currently holds the role of VP Product Portfolio.
He is responsible for the management, marketing and pricing of Colt’s product portfolio globally. His remit encompasses a range of networking services such as Ethernet, Wave, Dark Fibre, Internet Access, IP VPN, SD WAN and its SDN/NFV enablement, as well as Voice services (IN, SIP and UC).
Peter has also held several senior roles at Colt as Global Director Product Management and Marketing, Director Product Management and Marketing for Ethernet and IP services in Europe and Business Development Manager, Benelux.
Prior to joining Colt, he worked at Global One and Alcatel-Lucent.
Peter holds a Masters in Electronics, Civil Engineering and Telecommunications from the VUB Vrije University in Brussels, Belgium.
About Colt
Colt aims to be the leader in enabling customers’ digital transformation through agile and on-demand, high bandwidth solutions. The Colt IQ Network connects over 800 data centres across Europe, Asia and North America’s largest business hubs, with over 26,000 on net buildings and growing.
Colt has built its reputation on putting customers first. Customers include data intensive organisations spanning over 200 cities in nearly 30 countries. Colt is a recognised innovator and pioneer in Software Defined Networks (SDN) and Network Function Virtualisation (NFV). Privately owned, Colt is one of the most financially sound companies in its industry and able to provide the best customer experience at a competitive price. For more information, please visit www.colt.net.

Data centres are complex animals. They are comprised of millions of both tangible and intangible components. Managing complex data relationships and inventory data requires more than a spreadsheet, as the modern data centre manager knows – though that is sometimes all they get... By Mark Gaydos, Chief Marketing Officer for Nlyte Software.
Inaccurate column input and failure to keep sheets updated make for an unreliable way of ensuring that data is correct and that assets are correctly accounted for, monitored, and utilised. Managing the complexity of growing and optimisable data centres ideally requires a Data Centre Infrastructure Management (DCIM) suite. DCIM solutions tie together IT service management (ITSM) tools with a comprehensive suite of data centre asset management and data centre management software. It’s used when data centre decision-makers need to know exactly how to fix, improve, and plan ahead to deliver the service they want to, rather than the service they offer now.
Managing the lifecycle of a planned change in a data centre can be a formidable task. A planned change can include the subtasks of adding, moving, decommissioning, upgrading, or maintaining tangible and intangible assets. These include various categories of physical assets, virtual devices, cable plant, operating systems, applications, services, and mechanical, electrical and plumbing (MEP) systems. Unravelling an organically grown (or ‘chaotic’!) situation can be more than complex, it could threaten customer service levels.
Effective delivery of data centre services and resources demands maintaining uptime while upgrading new technology – seamlessly, with no interruption for the end user. There’s no way around this. The change management process within data centres is complex and one slip might take down a service with immediate repercussions. One component is establishing and making the most of a service window. A service window (sometimes referred to as a maintenance window) is a period of time, designated in advance, during which maintenance activities that could cause disruption of service may be performed with the customers’ blessing (or at least, their acceptance).
However, the planning and execution of a service window is complex, and time consuming. Maintenance windows help to identify what components will be affected by planned activity, with each data centre service associated to each component included in a consolidated impact analysis. They provide a safety net for data centre staff, ensuring that business owners support teams with the correct information, and provide a complete chain of accurate interdependencies. Without visibility into the current state of the asset landscape, there’s no way that unintended consequences are minimised to acceptable levels to business heads – either for data centre operators, or service providers.
The identification of all interested parties is an important aspect of the process. This procedure allows notifications to business owners, support teams, and relevant individuals of the planned event and potential service outages. Their participation is crucial in the planning and remediation process in an interdependent service offering.
Larger organisations, naturally have longer service window life cycles – which means more time spent executing. The bigger the organisation the greater number of changes occur within the year – with the cumulative costs associated to these surpassing millions of dollars for many data centres. The long timeframe can potentially create unintended consequences, missing critical services that were added after a service window planning process was initiated, and delays in implementing new projects. Concurrent and overlapping service windows can cause additional problems and unintentional disruptions due to the disassociation of multiple concurrent processes. It’s a knotty problem…
DCIM orchestrates with ITSM tools, and can create a single gateway to the data required to accurately and quickly identify all “things”: The applications, and services that could be impacted by the planned data centre activity. Additionally, the relevant business owners, support teams, interested individuals, and their contact information, can be quickly identified. DCIM solutions help to manage this complexity. They help to acquire information needed for a successful service window process, automating the orchestration of disparate data locations, including ITSM systems, CMDBs and data centre energy management software. DCIM solutions bring together the aforementioned tangible and intangible components, as well as external and internal workflow engines to ensure every element complies with the procedure.
DCIM software reduces management to ‘clicks’, instead of a labour-intensive process:
The right solution shortens the timeframe, reduces the required man-hours, and minimises errors, resulting in significant cost savings. Not to mention returning sanity to a frazzled data centre management service team, simply looking to deliver a great service to their users.

The traditional load balancer has a long and proud history. As datacentres in the client/server era became more complex, it acted as the traffic cop for workloads, apportioning them equally across available resources to maintain the equilibrium of performance and availability. By David Moss, Regional Director, Western Europe at Avi Networks.
But times have changed and today, work to virtualise, automate and repackage physical infrastructure and build agile, software-defined, datacentres is being hampered by the use of legacy load balancers. Once the way to avoid bottlenecks, they have instead become the bottleneck.
Enterprise IT is going through a lot of transformations. Many CIOs today have mandated that their organisations are ‘cloud-first’; that is, they are going to go with cloud applications, cloud services, and cloud infrastructure unless there’s a compelling reason not to do so. But the changes go deeper. Having already made the big switch from ‘bare metal’ deployments to VMware and other virtualisation approaches, progressive IT leaders are now looking to containers to provide yet more flexibility and value.
That deployment and packaging metamorphosis is a welcome advance, but it also has the effect of ushering in new IT architectures. This is another landscape change: we have moved from monolithic applications and workloads to service-oriented architecture (SOA), where coarsely-ground componentised services are delivered, and now to microservices, where every feature and function acts as an independent service. Look at the big social networks, for example, which are made up of many features, each composed of individual elements, from its marketplace to games, messaging and other elements. Because these services within services are standalone constituents, they can be updated without bringing the specific service, or the entire social network, down.
The legacy load balancer was designed to handle a world that looked very different, specifically monolithic applications deployed on hardware infrastructure. The load balancers really weren’t coded to deal with an enterprise that might be run on thousands of containers across multiple environments.
The other big change is on the infrastructure side. Cloud introduces changes in automation and provisioning where services and platforms are dealt out in real time. Look! No procurement, no tickets and none of the waiting around that the on-premises world with its individual servers, software licences and application software required before projects could start.
Faced with this fork in the road, the legacy load balancer folks had some stark choices, familiar to other companies caught up in the tornadoes of change that IT constantly summons. Legacy vendors could target customers for services revenue (F5 Networks recently began recognising more revenue from services than from products), start over and build something brand-new (hugely expensive, time consuming and a tough sell to shareholders), or they could fudge it (one of the more popular strategies). We see lots of load balancing appliances getting a software wrapper. They may sound nice, but it is still the same old legacy appliance designed for legacy applications and environments—a round peg for a square hole.
Whether you want to call them software load balancers or smart application delivery controllers or something else entirely, the new generation of load balancers has been built bottom-up for today’s containerised applications and modern architectures. And they are designed to deliver elasticity and intelligence across any cloud.
Don’t just ask us: IDC recently found that Avi delivers 47 per cent operating cost savings and 97 per cent faster to scale capacity compared to the traditional load balancers and provided an overall ROI of 573 per cent over three years.
The old load balancers might still be a decent fit for companies running old-generation apps, but even the big monolithic applications are being refashioned for the new age as elastic, cloud-based resources that can be relatively quickly reconfigured and are accessible from any device with a browser. That leaves legacy load balancers fit only for zombie environments.
In technology, change can creep up on you, and if you haven’t adapted, the impact can be catastrophic. As companies from Control Data, Digital and Wang to Siebel Systems, Lotus and Baan and have discovered, time waits for no man. Fine wine ages well, but technology? Not so much. The history of IT is replete with stories of companies that built a better mousetrap and saw the world beat a path to their door, leaving the legacy players in the dust. If you’re struggling on with an old load balancer, it’s time to move.