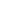Storage networking continues to be a crucial part of the overall ICT landscape, as there’s no escaping the fact that all the data that the digital world demands needs to be stored somewhere!
By far the most interesting storage networking development moving forward is how the continuing emergence of, and growth in, edge computing will, or will not, impact on the storage landscape. For so much of the IT industry, ‘consolidation’ has been the watchword of the past few years. So, distributed, local infrastructure has given away to huge, centralised and virtualised pools of storage. However, edge computing demands fast, local compute, networking and storage resources, so are we going to see the development and adoption of small, fast, local storage solutions, or will existing technologies and topologies simply be adapted to meet the demands of IoT and data analytics applications required to process data obtained, and retained, at a local level?
Linked to this, there’s no doubt that we’re seeing the emergence of a hybrid IT landscape, which includes hybrid storage infrastructure. So, there’ll be edge, regional and centralised storage – some of it owned by the end user and located in the end user’s facility, but more and more of it owned and/or hosted by Cloud and managed service providers. In simple terms, few enterprise organisations have the necessary resources to build, own and operate such a vast, complex storage infrastructure, so it makes perfect sense to use outside help. Working out where/when/how to create, use and manage the required storage components is the challenge that lies ahead.
Of course, I can’t end this brief look at the future, without reference to the impending GDPR! I’m very much of the view that the new regulation, although a significant departure from the existing data protection legislation, need not have a massive impact for companies who are already managing their data professionally. The major change seems to be the importance of being able to demonstrate ‘due diligence’ should anything go wrong. So, appointing a Data Protection Officer might be a good idea/is required for companies of a certain size, and having a reliable audit trail is essential for everyone. It would be wrong to down play the importance of the GDPR; equally, there’s been a massive amount of scaremongering and misinformation designed to panic end users into spending on GDPR ‘solutions’ – not very helpful or responsible.
Happy festive season, and here’s to an exciting and rewarding 2018.
By the end of 2019, DX spending will reach $1.7 trillion worldwide, a 42% increase from 2017
While International Data Corporation (IDC) continues to see tremendous momentum and influence of digital transformation (DX) on technology spending worldwide, across all geographies and industries, 59% of companies remain at either stage two or three of DX maturity, or what IDC calls a "digital impasse." To help CIOs and IT professionals successfully advance their organization's digital maturity, IDC has published IDC FutureScape: Worldwide Digital Transformation 2018 Predictions.
In launching the predictions, IDC analysts Robert Parker and Shawn Fitzgerald discussed the ten industry predictions that will impact CIOs and IT professionals in the worldwide digital transformation industry over the next one to three years and offered guidance for managing the implications these predictions harbor for their IT investment priorities and implementation strategies.
The 2018 DX predictions are primarily organized against the five pillars of IDC's digital transformation maturity model: Leadership, Omni-Experience, Information, Operating Model, and WorkSource. In addition, the new report includes a forecast on DX investments, which helps contextualize these predictions as part of direct DX investment of $6.3 trillion for 2018–2020. Most importantly, the latest DX predictions provide a set of planning assumptions to help IT executives consider how these prognoses would manifest themselves. That vision, combined with IDC's future road maps, will offer a framework for advancing digital maturity.
The predictions from the IDC FutureScape for Worldwide Digital Transformation are:
Prediction 1: By the End of 2019, DX Spending Will Reach $1.7 Trillion Worldwide, a 42% Increase from 2017
Prediction 2: By 2019, All Digitally Transformed Organizations Will Generate at Least 45% of Their Revenue from "Future of Commerce" Business Models
Prediction 3: By 2020, Investors Will View Digital Businesses Differently, with Specific Measures Based on Platform Participation, Data Value, and Customer Engagement Accounting for over 75% of Enterprise Valuations
Prediction 4: By the End of 2018, at Least 40% of Organizations Will Have a Fully Staffed Digital Leadership Team Versus a Single DX Executive Lead to Accelerate Enterprise-wide DX Initiatives
Prediction 5: By 2019, Personal Digital Assistants and Bots Will Execute Only 1% of Transactions, But They Will Influence 10% of Sales, Driving Growth Among the Organizations That Have Mastered Utilizing Them
Prediction 6: By 2020, in over Half of Global 2000 Firms, Revenue Growth from Information-Based Products and Services Will Be Twice the Growth Rate of the Balance of the Product/Service Portfolio
Prediction 7: By 2020, 85% of New Operation-Based Technical Position Hires Will Be Screened for Analytical and AI Skills, Enabling the Development of Data-Centric DX Projects Without Hiring New Data-Centric Talent
Prediction 8: By 2020, 25% of Global 2000 Companies Will Have Developed Digital Training Programs and Digital Cooperatives to Compete More Effectively in Talent Wars
Prediction 9: By 2019, 40% of Digital Transformation Initiatives Will Be Supported by Cognitive/AI Capabilities, Providing Timely Critical Insights for New Operating and Monetization Models
Prediction 10: By 2020, 60% of All Enterprises Will Have Fully Articulated an Organization-wide Digital Platform Strategy and Will Be in the Process of Implementing That Strategy
According to Shawn Fitzgerald, research director, Worldwide Digital Transformation Strategies, IDC, "This year's DX predictions represent the latest thinking on the key programs, technologies, and processes needed to achieve success in the digital economy as more companies are embracing and engaging their enterprise transformations. While we are seeing more companies becoming more digitally capable, there is a widening gap between leaders and laggards, with significant implications for those organizations that cannot make the transition to a digital-native organization."

IT spending in EMEA is projected to total $1 trillion in 2018, an increase of 4.9 percent from estimated spending of $974 billion in 2017, according to the latest forecast by Gartner, Inc.
In 2017, however, all categories of IT spending in EMEA underperformed global averages (see Table 1). Currency effects played a big part in the weakness in 2017, and will also contribute to the strength forecast in 2018.
Table 1. EMEA IT Spending Forecast (Millions of U.S. Dollars)
| 2017 Spending | 2017 Growth (%) | 2018 Spending | 2018 Growth (%) | |
| Data Center Systems | 44,497 | 1.1 | 45,890 | 3.1 |
| Enterprise Software | 96,091 | 7.6 | 106,212 | 10.5 |
| Devices | 167,579 | 2.6 | 174,246 | 4.0 |
| IT Services | 269,059 | 2.5 | 286,162 | 6.4 |
| Communications Services | 396,419 | -0.6 | 409,158 | 3.2 |
| Overall IT | 973,645 | 1.6 | 1,021,668 | 4.9 |
Source: Gartner (November 2017)
"The U.K. has EMEA’s largest IT market and its decline of 3.1 percent in 2017 impacts the forecast heavily," said John-David Lovelock, research vice president at Gartner. "Weak Sterling and political uncertainty since Brexit are reducing U.K. IT spending in 2017, while other major IT markets in EMEA grew steadily."
Another significant currency effect is the rapid appreciation of the Euro against the U.S. Dollar— it provides an incentive for Eurozone countries to defer IT spending to 2018 where possible, in anticipation of even lower prices in U.S. Dollars.
"However, there is more to the recovery in 2018 than just currency effects," added Mr. Lovelock. "Strong demand in the enterprise software and IT services categories across EMEA hint at significant shifts in IT spending patterns."
"The forecast highlights that businesses are broadly reducing spending on owning IT hardware, and increasing spending on consuming IT as-a-service," said Mr. Lovelock. "In the total IT forecast the business trends are masked somewhat by consumer spending, but when we look at enterprise-only spending the new dynamics between the categories are much clearer."
Significant Shifts in Enterprise IT Spending
EMEA enterprise IT spending* in 2017 was weaker than the overall IT spending forecast, declining 1.4 percent. The only category predicted to show enterprise spending growth in 2017 is the enterprise software market at 3.2 percent.
"In 2017, we’re seeing a pause in EMEA enterprise spending due to the switch to as-a-service offerings gaining momentum," said Mr. Lovelock. "Among the spending rebounds in 2018, however, we expect lagging markets. The data center, devices and communication services categories are all on pace to decline 3 percent or more in 2017. Despite improvements in 2018, spending on servers, storage, network equipment, printers, PCs, mobile devices — and even hardware support — won’t recover to 2016 levels."
In 2018, total enterprise spending in EMEA is on pace to grow 2.8 percent. All categories of enterprise IT spending will return to growth in 2018, but only IT services and software will grow strongly at 4 percent and 7.6 percent, respectively. Enterprise spending on devices and communications services continue to fall behind in 2018, growing at 2 percent or lower, thus failing to recoup the losses of 2017.
Gartner’s recent public cloud forecast further underlines this change in spending as businesses increasingly adopt cloud models for efficiency and agility. In doing so, they also shift their IT spending toward operational expenditure (opex) service-based models.
"The move to cloud services and opex spending on IT should serve to stabilize the growth in overall IT spending in EMEA in 2018 and beyond. We expect spending will spread out more evenly with fewer spikes of capital investment on hardware," said Mr. Lovelock. "In both enterprise and overall IT spending forecasts, worldwide and in EMEA, we forecast IT spending from 2019 through 2021 will remain close to a 3 percent growth rate each year."
70% of storage buyers in Tintri’s study admit miscalculating storage needs when planning new capacity.
According to research conducted by Tintri at IPExpo in London in October 2017, nearly a quarter (24%) of storage capacity planning decisions are made by IT leaders on the basis of a ‘best guess’ or no planning at all. In addition, three quarters of the respondents in the study operate with up to 20% of their storage capacity unused, keeping it in place as a buffer to maintain predictable performance.
When planning storage capacity needs, 42% of the respondents rely on previous experience, but only 12% run a simulation project to help accurately guide decisions. Just under 10% of the respondents carry out no planning at all for future needs, and only one fifth (22%) rely on input from technology vendors or partners.
The research also revealed that accurate storage capacity planning is a challenge for most buyers, with 70% of the respondents reporting that they have underestimated (43%) or overestimated (27%) their needs. In addition, 77% of the respondents reported that up to a fifth of their storage capacity is unused, except as acting as a buffer to maintain performance. At the extremes, 37% revealed that more than a fifth of their storage capacity is unused, with only 10% able to report that they operate with 5% unused storage capacity or less.
“While previous experience and knowledge are valuable methods to help predict future storage needs, many environments are becoming too complex to rely on that approach anymore,” commented Scott Buchanan, Chief Marketing Officer at Tintri. “Guesswork leads to performance issues or overprovisioning—and with the analytics tools available today, it’s simply unnecessary.”
“Our customers understand the importance of precise planning. It saves them anguish and it saves them money. And in our experience, the most accurate planning is only possible when you’re working with granular analytics,” said John N. Brescia, CTO at Virtix IT. “That’s part of Tintri’s value—its analytics are based on the actual behavior of each individual virtual machine. By using up to three years of historical data to forecast future resource needs, Tintri helps our customers reduce guessing.”
Research from business continuity and disaster recovery provider, Databarracks, has revealed organisations are failing to get to grips with the true cost of IT downtime, with a third of organisations (35 per cent), unsure what an IT outage would end up costing their business.
The results were identified in Databarracks annual Data Health Check survey, with other notable findings including:
From a sample of over 400 IT decision makers, 46 per cent experienced more than four hours of IT related downtime over the past 12 months
Critically, of those organisations able to quantity what the cost of IT downtime would mean for their business, 23 per cent said that they incurred costs ranging from £10,000 up to more than £1million, per hourSplunk has published the results of new research in a report titled “Damage Control—The Impact of Critical IT Incidents”, from analyst firm Quocirca.
Findings show that the average organization suffers five critical IT incidents a month, with each one costing the IT department on average USD $36,326 and a further $105,302 to the rest of the business. This is forcing IT departments to take resources away from the development of new services to maintain existing infrastructure.
“It’s clear that organizations are finding it challenging to maintain end-to-end visibility with the growing volume of data being generated by their IT systems and infrastructure,” said Bob Tarzey, analyst, Quocirca. “This is holding IT teams back from being able to drill down and pinpoint the root cause of issues that are causing frequent and recurring problems. This often results in reputational damage and poor customer experience, impacting a company’s bottom line. Organizations need to be able to collect and analyze data across all their IT infrastructure more effectively to reduce the time spent in damage control mode and increase time spent on pro-active digital innovation.”
Other findings from the report include:
Critical IT incidents are negatively impacting businesses. 70% say a past critical incident has caused reputational damage to their organization, underlining the importance of timely detection to minimize impact.The volume of IT incidents is hampering the ability to improve IT delivery. 96% of organizations are failing to learn from previous incidents. 13.3% of all incidents are repeats caused by an inability to properly determine the root cause of issues.Incident detection and investigation is taking too long. 80% admitted they could improve the mean-time-to-detect incidents. Incidents on average take 5.81 hours to repair.Organizations are failing to effectively monitor their entire IT estate. 80% have operational blind spots, particularly across next-generation technology stacks, hindering their ability to respond to IT incidents quickly. Only 2.5% have full visibility across all relevant infrastructure.
“Today’s IT environments are more complex than ever, spanning data centres, cloud services and on-the-edge devices such as mobile and IoT. Because systems are often siloed, IT can struggle to collect and correlate information, making it difficult to monitor infrastructure and rapidly troubleshoot problems,” said Rick Fitz, senior vice president of IT Markets, Splunk. “Splunk software enables customers to gain real-time, end-to-end visibility across the entire IT environment. By collecting and correlating machine data across all technology tiers and devices as well as delivering it in the form of real-time analytics, customers can quickly troubleshoot issues and outages, monitor end-to-end service levels and detect anomalies. Reducing costs from IT incidents allow IT leaders to focus their funding and resources on developing the new digital services essential for remaining competitive.”
The SVC Awards reward the products, projects and services as well as honour companies and teams operating in the cloud, storage and digitalisation sectors. The SVC Awards recognise the achievements of end-users, channel partners and vendors alike and have become established as one of the most prestigious events that recognise the innovation and dynamism of the IT sector.
Paddington’s Hilton Hotel was the venue for a highly successful and enjoyable evening – one senses that the Isambard Kingdom Brunel, founder of the Great Western Railway and the founder and first managing director of the awards venue, would have approved of the engineering achievements being celebrated at the SVC Awards.
A drinks reception, sponsored by Touchdown PR, was followed by an excellent three course dinner and comedy, courtesy of Edinburgh Festival regular, Jimmy McGhie.




STORAGE PROJECT OF THE YEAR
Sponsored by: IGEL
Award presented by: Iris Hatzenbichler-Durchschlag, Director Marketing
Runner up: Mavin Global supporting The Weetabix Food Company
WINNER: DataCore Software supporting Grundon Waste Management
Collecting: Brett Denly, Regional Director

CLOUD/INFRASTRUCTURE PROJECT OF THE YEAR
Award presented by: Jason Holloway, Director of IT Publishing @ Angel
Runner up: Axess Systems supporting Nottingham Community Housing Association
WINNER: Navisite supporting Safeline
Collecting: Elizabeth Redpath, Marketing Director

HYPER-CONVERGENCE PROJECT OF THE YEAR
Award presented by: Peter Davies, Senior Sales Executive on the IT Portfolio of Angel title and events
Runner up: HyperGrid supporting Tearfund
WINNER: Pivot3 supporting Bone Consult
Collecting: Chris Deacon of Pivot 3 and Ole Nielsen of Bone Consult

UK MANAGED SERVICES PROVIDER OF THE YEAR
Presented by: Philip Alsop, Editor Digitalisation World stable of publications
Runner up: Storm Internet
WINNER: EBC GROUP
Collecting: Richard Lane, Group Managing Director

VENDOR CHANNEL PROGRAM OF THE YEAR
Sponsored by: Touchdown PR
Presenting: James Carter, CEO
Runner up: Veeam
WINNER: NetApp
Collecting: Irene Marin, Sales Manager & sales representative Kayleigh Bull

INTERNATIONAL MANAGED SERVICES PROVIDER OF THE YEAR
Presented by: Jason Holloway
Runner-up: Claranet
WINNER: Datapipe
Collecting: Tony Connor - Marketing Director, EMEA

BACKUP & RECOVERY / ARCHIVE PRODUCT OF THE YEAR
Sponsored by IMPARTNER
Award presented by: Pierre Poggi, Impartner EMEA Sales Director
Runner up: NetApp
WINNER: Altaro Software
Collecting: Colin Wright, VP EMEA Sales

CLOUD-SPECIFIC BACKUP & RECOVERY PRODUCT OF THE YEAR
Sponsored by: EBC Group
Award presented by: Richard Lane, Group Managing Director
Runner up: Acronis
WINNER: Veeam Software
Collecting: Jason Holloway on Veeam’s behalf

STORAGE MANAGEMENT PRODUCT OF THE YEAR
Award presented by: PETER DAVIES
Runner up: SUSE
WINNER: Virtual Instruments
Collecting: Sean O’Donnell, Managing Director EMEA

SOFTWARE-DEFINED/OBJECT STORAGE PRODUCT OF THE YEAR
Award presented by: Phil Alsop
Runner up: DDN Storage
WINNER: Cloudian
Collecting: Regional Sales Managers, Dan Chester & Arian Everett

SOFTWARE DEFINED INFRASTRUCTURE – PRODUCT OF THE YEAR
Award presented by JASON HOLLOWAY
Runner up: Runecast Solutions
WINNER: SUSE
Collecting: Jeff Kirkpatrick, UK Alliances Manager

HYPER-CONVERGENCE SOLUTION OF THE YEAR
Award presented by: PETER DAVIES
Runner up: Pivot 3
WINNER: Scale Computing
Collecting: Regional Channel Manager Doug Williams & EMEA Systems Engineer, Leonard Powers

HYPER-CONVERGENCE BACKUP AND RECOVERY PRODUCT OF THE YEAR
Award presented by: PHIL ALSOP
Runner up: Cohesity
WINNER: Exagrid
Collecting: Graham Woods, VP International Sales Engineering

PLATFORM AS A SERVICE (PAAS) SOLUTION OF THE YEAR
Sponsored by: NetApp
The award will be presented by: Kayleigh Bull, NetApp
Runner up: SnapLogic
WINNER: Cast Highlight
Collecting: Pierre Poggi of Impartner collected the award on behalf of Cast Highlight

SOFTWARE AS A SERVICE (SaaS) SOLUTION OF THE YEAR
Award presented by: Jason Holloway
Runner up: Impartner
WINNER: Adaptive Insights
Collecting: Rob Douglas, VP UKI & Nordics

IT SECURITY AS A SERVICE SOLUTION OF THE YEAR
Award presented by: Peter Davies
Runner up: Alert Logic
WINNER: Barracuda MSP
Collecting: Jason Howells, Director of EMEA MSP Business

CLOUD MANAGEMENT PRODUCT OF THE YEAR
The award is presented by: Phil Alsop
Runner up: ZERTO
WINNER: Hypergrid
Collecting: Doug Rich, VP EMEA

STORAGE COMPANY OF THE YEAR
Sponsored by: SUSE
Presented by: David Winter, Data Centre Sales
Runner up: NetApp
WINNER: Data Direct Networks / DDN
Collecting: Ed Browne - UK&I and Nordics Sales Director, Chris Kenny - VP Gen Manager Europe and International Sales, Mark Rothwell - Sales Manager UK.

CLOUD COMPANY OF THE YEAR
Award presented by: Jason Holloway
Runner up: Databarracks
WINNER: Six Degrees Group
Collecting: James Hall, Sales Director

HYPER-CONVERGENCE COMPANY OF THE YEAR
Award presented by: Peter Davies
Runner up: Pivot3
WINNER: Cohesity

THE STORAGE INNOVATION OF THE YEAR
Presenting the award: Phil Alsop
Runner up: Nexsan
WINNER: Excelero
Collecting: Axel Rosenberg, Sr Technical Director

THE CLOUD INNOVATION OF THE YEAR
Presenting the award: Peter Davies
Runner up: StaffConnect
WINNER: Zerto
Collecting: Peter Godden, VP EMEA

HYPER-CONVERGENCE INNOVATION OF THE YEAR
Presenting the award: Jason Holloway
Runner up: Syneto
WINNER: Schnieder Electric
Collecting: Yakov Danilevskij, Head of Strategic Marketing

DIGITALISATION INNOVATION
Sponsored by Touchdown PR
Presenting the award: James Carter, CEO
Runner up: MapR
WINNER: IGEL
Collecting: Iris Hatzenbichler-Durchschlag, Director Marketing

SVC INDUSTRY AWARD
Each year Angel likes to recognise a significant contribution to or outstanding achievement in the industry – this award is not voted for by the readers but based on the publisher’s and editorial staff’s opinions.
Presented by: Jason Holloway, Director of IT Publishing at Angel Business Communications.
SVC Industry Award – Zerto
Collecting: Peter Godden, VP of EMEA


















NetApp has been chosen by City of Glasgow College to revolutionise how technology functions within the institution. The installation places flexibility at the heart of the College’s infrastructure, using VDI technology to make classrooms multipurpose – adapting to be either a Computer Aided Design (CAD) classroom, a business studies classroom, or anything in between, without the need for additional technology resources.
The City of Glasgow College educates over 40,000 students across a range of full time and part time courses. To support this number of students, the college recently completed the building of two new campuses, as part of a £228 million project supported by Glasgow City Council and the Scottish Funding Council.
As the largest tertiary education establishment in Scotland, it was vital for the City of Glasgow College to be able to share resources and data across a huge, robust and scalable data landscape. The environment needed to be capable of supporting its students across any of the campus locations, as well as allowing students of evening classes or off-site courses to use the college’s software and learning resources from any location.
Working with NetApp has enabled the City of Glasgow College to offer shared services, technology rich learning environments, and pave the way for exciting new innovations such as VR learning technology. In the coming months and years, technology will increasingly be used throughout the entire education process. For example getting students to design using CAD software, visualise their designs in 3D using VR, and then 3D print their prototype.
Craig Dowling, Head of Infrastructure, City of Glasgow College, said: “We have a duty to our students to look at where technology in education is going and make sure we are able to adapt our courses to the studies and technologies of the future. Working with NetApp has allowed us to make sure our data management infrastructure is ready for this challenge. Having the ability to work closely with NetApp and tap into the technical expertise available in our region has been a huge advantage for us. As a result, we are hoping to expand our IT services to other education establishments in the area, offering our datacentre as a service, as well as exploring the potential for centralised student timetabling systems, library databases and financial systems across the region. This could lead to cost savings and continuity for local colleges.”
Nick Thurlow, Managing Director for UK & Ireland, NetApp, concluded: “Flexible data management will continue to grow in importance when it comes to driving education forward as tighter budgets and emerging technologies increase the pressure on learning establishments to do more with less. We are pleased to have supported the City of Glasgow College as it continues to transforms the delivery of college education for students in Scotland.”
Paris-based Dailymotion has expanded the Scality RING object storage back-end to its massive video repository across its global network of data centres. Scality now supplies more than 30 petabytes of useable capacity to the video sharing behemoth. Dailymotion’s move to Scality RING was impelled by its requirements for high performance, boundless scalability, assured uptime, and intuitive administration controls.
“Scality was the obvious choice. Performance, stability, and reliability is what impresses us most about Scality RING, which altogether meets our storage and business requirements,” said Christophe Simon, system architect at Dailymotion. “We could not find any other object storage solution to be as mature as Scality RING. It is well-developed, broadly deployed, and receives timely evolutionary enhancements to keep it cutting-edged.”
Alan Martins, VP of Infrastructure at Dailymotion, added: "With Scality we went to the next level and we can continue scaling more smoothly."
Scality RING replaced EMC Isilon after demonstrating a more straightforward architecture and delivering significant performance improvement over that legacy system. Dailymotion now relies on Scality RING as its primary storage. The company recently added several petabytes for backup, as well as nine petabytes across its New York, Singapore, and Sunnyvale data centres, strengthening video distribution capabilities in those regions and enhancing user experience with local caching/points of presence.
“The requirement for uninterrupted content uploading and sharing, and seamless system expansion makes Scality RING indispensable to Dailymotion’s fast-growing business,” said Erwan Menard, president and COO at Scality. “Expanding Scality storage to more than 30 petabytes without system interruption is testament to the value of Scality RING for video sharing environments that demand zero downtime.”
The University of Tennessee, Chattanooga (UTC) has selected DDN’s GS14KX® parallel file system appliance with 1.1PB of storage to replace its aging big data storage system and to support a diversifying range of data-intensive research projects.
The Center of Excellence in Applied Computational Science and Engineering (SimCenter) at UTC needed a big data storage solution that could scale easily to support growing research programs focused on computational fluid dynamics (CFD), machine learning, data analytics, smart cities and molecular biology. The DDN GS14KX is purpose built to address the comprehensive needs of HPC environments and manage huge data growth, enabling organisations, such as SimCenter, to scale their environments and take advantage of new, data-intensive research disciplines such as machine learning.
The SimCenter is a research incubator with both an inward-facing role to support the growth of innovative research at UTC and an outward-facing role to support and collaborate in making Chattanooga a world-class smart city. “The real-time data coming from smart cities is huge; every street will have data sets coming in about everything from small Bluetooth devices to autonomous vehicles,” said Anthony Skjellum, Director of SimCenter at UTC. “The scalability and quality of integration from DDN will allow us to implement a number of smart city test beds connecting into the new storage solution, with machine learning algorithms taking advantage of the near real-time data. We have a torrent of data so the ability to scale up capacity or performance was vital, and DDN was able to provide a clear path for growth.”
Since the start of the SimCenter in 2002, it has served as a hub in modeling, simulation, and high-performance computing for all colleges at UTC and is a research incubator that helps UTC build its innovative doctoral programs in computational science and computational engineering. Traditionally focused on CFD projects such as hypersonic flows, which typically have very large data sets, the SimCenter also supports research into energy and environment, manufacturing, urban systems and smart cities, and health and biological systems.
A number of users are taking advantage of GPU hardware in the SimCenter’s newest Dell EMC HPC cluster to speed up research. "DDN’s powerful big data storage platform will give us the ability to easily meet the diverse and dynamic demands of our current research programs and enable us to scale performance or capacity as we look to expand our research capabilities,” said Ethan Hereth, High Performance Computing Specialist at UTC. “The integration of DDN’s solution into our existing Dell EMC HPC infrastructure has been fabulous. As well as being larger than our previous storage system, the density is far better. We are only using a quarter of the rack space as before for the same capacity, which we could easily double with DDN by only adding new hard drives.”
The SimCenter needed to modernise and future-proof its storage to support the expanding research focus and enable researchers to access data quicker, meet the demands of applications with larger I/O bandwidth requirements, and support the collaborative smart city project. With DDN’s highly scalable storage solution, SimCenter is prepared to meet the growing demands of data-intensive applications and research, providing superior performance. As well as providing 8x better density than before, the solution will be filled entirely with self-encrypting hard drives (SEDs), which will enable UTC to access research grants, initiatives and projects that have requirements around encryption.
“DDN has a proven track record and has a very good reputation. They met the challenge and delivered a really good solution, providing everything that we required. We wanted a solution that was easily scalable and that would seamlessly integrate into our existing environment. The collaboration between Dell EMC and DDN provides an end-to-end HPC storage solution that fits into our infrastructure and adds tremendous value,” added Skjellum.
Burst buffer application at Canada’s largest supercomputer centre uses NVMesh® to achieve
unheard-of bandwidth and cost efficiency via pooled NVMe within the GPFS shared parallel file system.
Excelero customer SciNet has deployed Excelero’s NVMesh™ server SAN for the highly efficient, cost-effective storage behind a new supercomputer at the University of Toronto. By using NVMesh for burst buffer – a storage architecture that helps ensure high availability and high ROI, SciNet created a unified pool of distributed high-performance NVMe flash that retains the speeds and latency of directly attached storage media, while meeting the demanding service level agreements (SLAs) for the new supercomputer.
“For SciNet, NVMesh is an extremely cost-effective method of achieving unheard-of burst buffer bandwidth,” said Dr. Daniel Gruner, chief technical officer, SciNet High Performance Computing Consortium. “By adding commodity flash drives and NVMesh software to compute nodes, and to a low-latency network fabric that was already provided for the supercomputer itself, NVMesh provides redundancy without impacting target CPUs. This enables standard servers to go beyond their usual role in acting as block targets – the servers now can also act as file servers.”
Based in Toronto, SciNet, Canada’s largest supercomputer centre, serves thousands of researchers in biomedical, aerospace, climate sciences, and more. Their large-scale modelling, simulation, analysis and visualisation applications sometimes run for weeks, and interruptions can sometimes destroy the result of an entire job. To avoid interruption SciNet implemented a burst buffer - a fast intermediate layer between the non-persistent memory of the compute nodes and the storage - to enable fast checkpointing, so that computing jobs can be easily restarted. SciNet had deployed the Spectrum Scale (GPFS) shared parallel file system on their spinning disk system, but at scale, as individual jobs become larger, checkpointing may take too long to complete, making the calculation difficult, or even impossible to carry out.
Using Excelero’s NVMesh in a burst buffer implementation, SciNet created a peta-scale storage system that leverages the full performance of NVMe SSDs at scale, over the network – easily meeting SLA requirements for completing checkpoints in 15 minutes, without needing costly proprietary arrays. With NVMesh, SciNet created a unified, distributed pool of NVMe flash storage comprised of 80 NVMe devices in just 10 NSD protocol-supporting servers. This provided approximately 148 GB/s of write burst (device limited) and 230GB /s of read throughput (network limited) – in addition to well over 20M random 4K iOPS.
Emulating the “shared nothing” architectures of the Tech Giants, SciNet’s NVMesh deployment allows them to use hardware from any storage, server and networking vendor, eliminating vendor lock-in. Integration with SciNet’s parallel file system is straightforward, and the system enables SciNet to scale both capacity and performance linearly as its research load grows.
“Mellanox interconnect solutions include smart and scalable NVMe accelerations that enable users to maximise their storage performance and efficiency,” said Gilad Shainer, vice president of marketing at Mellanox Technologies. “Leveraging the advantages of InfiniBand, Excelero delivers world leading NVMe platforms, accelerating the next generations of supercomputers.”
“In supercomputing any unavailability wastes time, reduces the availability score of the system and impedes the progress of scientific exploration. We’re delighted to provide SciNet and its researchers with important storage functionality that achieves the highest performance available in the industry at a significantly reduced price – while assuring vital scientific research can progress swiftly,” said Lior Gal, CEO and co-founder at Excelero.
Syneto has consolidated the IT infrastructure of LG Electronics Italia, part of worldwide brand and leading provider of flat panel TVs, mobile devices, air conditioners, washing machines and refrigerators LG Electronics.
The IT deployment, consisting of a HYPER Series 3100 all-in-one hyperconverged platform with built-in Disaster Recovery (DR) capabilities, has reduced admin time by five hours per week from 21 hours, and lowered recovery time objective (RTO) from 21 hours to just under 15 minutes.
Gianni Velardi, Senior IT Manager at LG Electronics Italy, and his team were looking for an affordable solution that would provide ease of use as well as disaster recovery capabilities. The team needed to have control of and insight into applications, files and video surveillance data. After researching the market, Velardi’s team was underwhelmed with the available products, and found that none satisfied all of their criteria, also including a user-friendly and easy to manage built-in disaster recovery function, complete 24/7 data protection and the lowest possible DR RTO possible.
After identifying Syneto’s HYPER Series 3100 all-in-one array, LG Electronics Italy approached Syneto to find out more about the company and its hyperconverged technology. It found that the HYPER Series 3100 met its strict criteria, being able to host all applications and store all the company’s files simultaneously at a highly competitive price. Furthermore, while LG Electronics Italy’s previous IT infrastructure, composed of three obsolete traditional servers without DR capabilities, was unable to generate detailed reports, Syneto’s system offered a user-friendly integrated analytics feature, which the team found highly appealing.
“Syneto’s hyperconverged platform has helped cut the time we spend managing our IT infrastructure by five hours a week while providing complete data protection with granular data recovery policies. An RTO of 15 minutes is now also possible, and it is a fantastic improvement, given that our previous RTO was over 21 hours,” said Gianni Velardi, Senior IT Manager at LG Electronics Italy.
Since the Syneto deployment, the LG Electronics Italy IT team has been able to optimise its infrastructure by carrying out detailed performance analysis to determine how additional workloads would impact performance. The team now spends far less time on IT administration, and instead is able to focus on innovating and delivering value to the business.
“LG Electronics Italy, like many companies of different sizes, was looking for an all-in-one hyperconverged solution with built-in and highly reliable disaster recovery capabilities at an affordable price. Added to that, the ease of use we are able to offer our ROBO and SMB customers is unmatched in the storage market today.” said Vadim Comanescu, CEO Syneto.
Solution delivers automated QoS, alongside data reduction and more efficient backups.
SEGA Games Co., Ltd., one of the world’s most famous interactive games companies, has significantly improved the stability, availability and manageability of its IT infrastructure by implementing enterprise cloud technology from Tintri, Inc. Tintri has enabled SEGA Games to cure a persistent conventional storage problem that left Sega Games’ IT team unable to monitor and control resources consumed by Virtual Machines (VMs). In addition, the time spent by the SEGA Games infrastructure team on storage operations has been reduced significantly.
With more than half of SEGA Games’ physical servers used to host virtualisation environments, where 2,000-3,000 VMs are running, Quality of Service (QoS) is vital to infrastructure stability. Previously, VMs consuming lots of storage I/O resources – or ‘Monster VMs’ – were affecting overall performance of other VMs using the same storage.
SEGA has purchased Tintri enterprise cloud technology for its primary and Disaster Recovery sites, with each unit taking only 30 minutes to configure. By moving to Tintri, SEGA Games was able to implement its auto-QoS function to automatically monitor storage I/O for each VM, greatly reducing the impact of ‘Monster VMs’ and simplifying management across the entire environment.
Additionally, SEGA Games has reported an approximate 2.2x data reduction in its storage environment, with each Tintri unit hosting up to 800VMs, with minimal impact on performance. The solution has also enabled more efficient data protection: snapshot and replication can be done every hour instead of the previous six hours, and the data replicated is reduced by dedupe and compression.
“Tintri’s ability to deliver auto-QoS has proved very effective in enabling us to improve the stability and availability of our infrastructure,” explained Kyohei Aso, who works in Infrastructure & DB Section at SEGA Games. “Some of the other companies’ storage also had auto-QoS functionality, but when we actually tested them, I/O was only mildly suppressed and the performance of other VMs was impacted. On the other hand, Tintri QoS greatly reduced the impact on other VMs.”
“The stability and availability of the IT infrastructure is of utmost importance to any organisation operating at the leading edge of their industry,” commented Yohei Yagishita, Tintri Japan. “By implementing Tintri enterprise cloud, SEGA Games’ infrastructure team have addressed both business and technical challenges giving them greater confidence in overall performance, and allowing their team to focus on more important challenges while Tintri automates.”
Research reveals the reality of hybrid computing.
By Tony Lock, Director of Engagement and Distinguished Analyst, Freeform Dynamics Ltd.

At the beginning of the ‘Cloud’ movement, vendors, evangelists, visionaries and forecasters were often heard proclaiming that eventually all IT services would end up running in the public cloud, not in the data centres owned and operated by enterprises themselves. Our research at the time, along with that of several others, showed that the reality was somewhat different: the majority of organisations said they expected to continue operating IT services from their own data centres and from those of dedicated partners and hosters, even as they put certain workloads into the public cloud.
More recent research by Freeform Dynamics (link: http://www.freeformdynamics.com/fullarticle.asp?aid=1964) illustrates that this expectation – running IT services both from in-house operated data centres, and from public cloud sites – is now very much an accepted mode of operation. Indeed, it is what we conveniently term “hybrid cloud” (Figure 1).
The chart illustrates very clearly that over the course of the last five years almost three-quarters of organisations have already deployed, at least to some degree, internal systems that operate with characteristics similar to those found in public cloud services, i.e. they have deployed private clouds. Over the same period, just under two-thirds of those taking part in the survey stated that they already use public cloud systems. It is interesting to note that both private and public cloud usage has grown steadily rather than explosively, but this is not surprising given the pressures under which IT works, and that the adoption of any “new” offering takes time. Especially if the systems will be expected to support business applications rather than those requiring lower levels of quality or resilience (Figure 2).
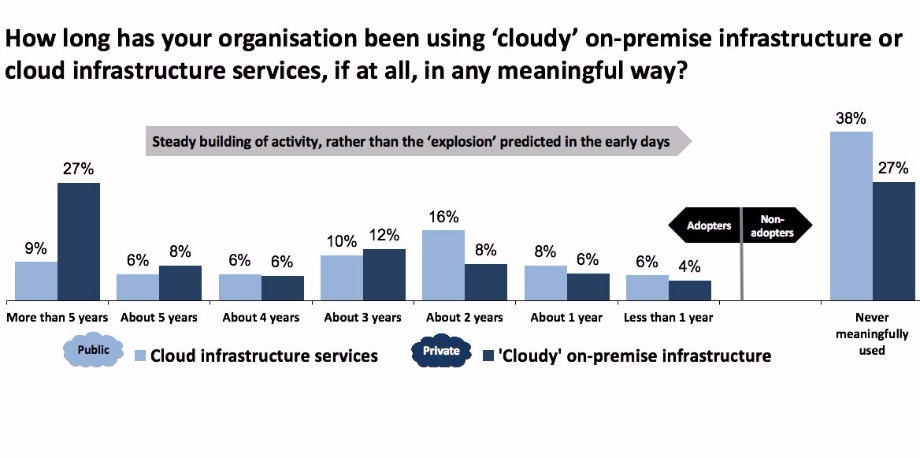
The second chart shows that for a majority of organisations, private cloud is already in use or will be supporting production business workloads in the near future. The adoption of public cloud to run such workloads clearly lags behind, but its eventual usage is only out of the question for around a quarter of respondents. When combined with the results for test/dev and the production hosting of applications and services developed specifically for the web, the picture of a hybrid cloud future for IT is unmistakable.
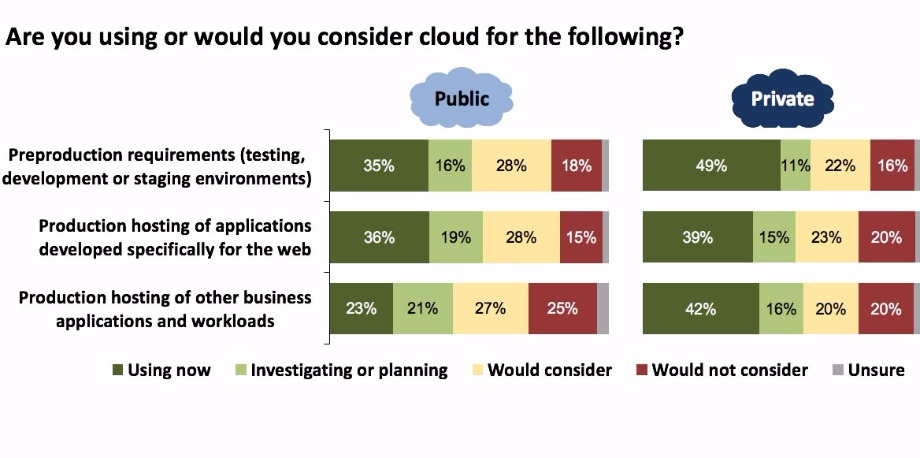
But if ‘hybrid IT’ is to become more than just a case of independently operating some services on internally owned and operated data centre equipment and others on public cloud infrastructure, the survey points out some key characteristics that must form part of the management picture. (Figure 3.)

The results in this figure highlight several key requirements that must be met around the movement of workloads if ‘hybrid cloud’ is to become more than a marketing buzzword. Given that private clouds are today used more extensively to support business applications than public clouds, there should be little surprise that smoothing the movement of workloads between different private clouds is ranked as important, or at least useful, by around four out of five respondents.
But the chart also indicates a recognition of the need to move workloads smoothly between private clouds running in the organisation’s own data centres and those of public cloud providers. And almost as many answered similarly about the need to be able to migrate workloads between different public clouds. The importance of these integration and interoperation capabilities is easy to understand: they are essential if we want to achieve the promise of cloud, in particular the ability to rapidly and easily provision and deprovision services, and the ability to dynamically support changing workloads coupled with hyper scalability to ease peak resource challenges and enhance service quality.
How quickly such capabilities can be delivered depends on a number of factors (Figure 4.)
The need for the industry to adopt common standards is clear and, to its credit, things are beginning to move in this direction although there is still much work to be done. The same can be said for integrating cloud services with the existing management tools with which organisations keep things running, although, once again, things do need to improve especially in terms of visibility and monitoring.
The days of vendors building gated citadels to keep out the competition and keep hold of customers should be coming to an end, as many – though alas not all – are under pressure to supply better interoperability. In truth, while interoperability does make it easier for organisations to move away, such capabilities are also attractive and can act as an incentive to use a service.
After all, no one likes the idea of vendor lock-in, and anything that removes or at least minimises such fear can help smooth the entire sales cycle. In addition, if a supplier makes interoperability simple via adopting standards, being open and making workload migration straightforward, they then have an excellent incentive to keep service quality up and prices competitive.

The continued rapid rise of data creation will provide immeasurable opportunities for companies to gain advantage in the market, but they must take proactive actions in order to be a step ahead of others. Business leaders need to increase their focus on the computing trends driving data growth over the next several years and revisit policies to assess the value of data throughout its lifecycle from creation, collection, utilization to its long-term management.
By Wayne M. Adams, SNIA Board of Directors and Chair of the SNIA Green Storage Initiative.

International Data Corporation (IDC)1 has predicted that data creation will continue to grow year over year to a total of 163 zettabytes (ZB) by 2025. IDC also states that the industry will transition from a trend of consumers being the largest creators of the world’s data, to where enterprises will become the larger creator again, creating 60% of the world’s data in 2025. Computing trends like IoT, machine learning, and other types of Artificial Intelligence (AI) based data analysis/decision making and many others are behind these data growth trends

Within IT though the era of greenwashing has long passed, there remains the need to be energy efficient and to further optimize limited resources as the ongoing top priority to have increased computational resources and pools of data are required to drive a business. IT users continue to look for effective approaches to select technologies and products. For data center storage, there is a collection of standard energy efficiency metrics that enable IT decision makers to objectively compare a range of possible solutions and to manage a solution once deployed.
The SNIA Emerald™ Program provides a standardized way of reporting vendor-performed test results that characterize the several aspects of storage system energy usage and efficiency. For procurement metrics, SNIA’s Emerald™ program and specification defines energy usage metrics for Block IO and the recently released File IO metrics that provides an energy usage profile on how a storage system will work in configurations optimized for transaction performance capacity or streaming.
The USA EPA Energy Star® Data Center Storage Program references the use of SNIA’s Emerald™ Energy Efficiency Measurement Specification Metrics for Block IO storage system configurations. The EPA maintains a public repository of vendor tested products since 2014, where many many vendors are listed with a range of products.

The SNIA Emerald Block IO metrics are:
With the release of SNIA Emerald V3 specification in September 2017, the File IO metrics are based on the following application workloads:
Additional considerations during the procurement phase to select a solution for your IT requirements includes a systems Reliability, Availability, Serviceability (RAS) features, capacity optimization features, and type of physical media being selected. All of these factor into a system’s energy efficiency profile, so when contrasting solutions, keep these in mind.
The more RAS features will increase additional controller functionality and or systems to be running additional logic, which can add to the system energy usage. Capacity optimization technologies enable a system to store a data set size in a smaller physical storage size, which can reduce energy usage. Disk storage types from Hard Disk Drive (HDD) to Solid State Drives (SSD) have different energy usage profiles. Within HDD, there are rotational speeds and data placement considerations.
The SNIA Emerald specification recommends that these attributes be part of a system test report so the reader understands why there can be variations in metrics when looking at two systems configured with the same base hardware. RAS and capacity optimization technologies, each feature by themselves may be uneventful, but when combined there can be positive, additive improvements for reduced energy usage. Capacity optimization refers to a set of techniques which collectively reduce the amount of storage necessary to meet storage objectives. Reduced use of storage (or increased utilization of raw storage) will result in less energy usage for a given task or objective. Each of these techniques is known as a Capacity Optimizing Method (COM).
COMs are largely, though not completely, independent. They provide benefit in any combination, though their combined effect does not precisely equal the sum of their individual impacts. Nonetheless, since data sets vary greatly, a hybrid approach using as many techniques as possible is more likely to minimize the capacity requirements of any given data set, and therefore is also likely to achieve the best results over the universe of data sets. In addition, the space savings achievable through the different COMs are sufficiently close to one another that they are roughly equivalent in storage capacity impact.
A commonl assumption is that certain space consuming practices are essential to the storage of data at a data center class service level.
In the SNIA Emerald™ Energy Measurement Specification, tests for the presence of the following COMs are defined as:
SNIA and the Green Grid organization collaborated on a whitepaper titled, “The Green Grid Data Center Storage Productivity Metrics: Application of Storage System Productivity Operational Metrics”.
DCsP represents a set of operational phase metrics that observe storage system productivity while the data center runs normal or “real-world” workloads. These metrics are conceptually the same as those defined for the acquisition phase including aspects of capacity and performance. All are needed to completely characterize storage systems.
Although similar to the procurement metrics, these DCsP operational metrics differ in their measurement and usage aspects. The majority of “real-world” workloads represent actual data center information produced by at least one or more applications. Most of IT equipment, among other requirements, are required to run 24/7. This last-mentioned availability aspect is particularly important for storage systems as it makes the real time gathering of the operational metrics essential for good analysis.
The metrics to be calculated, based upon a storage systems operational information to be collected, polled, or stored in a Data Center Information Management (CIM) tool, based on the storage configuration for the applications it is supporting are as follows:
For more information on SNIA resources and programs for data storage energy efficiency, including the SNIA Emerald program, IT planning resources, and education materials, please visit https://www.snia.org/energy or email emerald@snia.org.
1 SDC reference: http://www.seagate.com/www-content/our-story/trends/files/Seagate-WP-DataAge2025-March-2017.pdf

Solid State Disks (SSDs) are a popular option for IT professionals looking to boost performance in their data center, but the question of how to best implement SSD storage often arises. Automated caching and tiering can provide the solution. But while both caching and tiering provide a layer of application acceleration that result in a cost-effective way to improve performance and get more out of your applications, they differ in a number of ways. They are not interchangeable and it is essential for IT administrators to understand the purpose and difference of each.
By Cameron Brett, STA Board Member, Toshiba America Electronic Components, Inc.


PCIe/NVMe is a high-performance option, but when provided in add-in card form factor, the drive is not very serviceable. 2.5”/U.2 and M.2 form factors are growing in availability, but PCIe drive slots are still rare, until the ecosystem becomes more established. And while vendors are creating controllers that take advantage of the PCIe bus's extra performance and reduced latency, the lack of a mature process for managing storage over PCIe will likely limit adoption in the near term.
Both caching and tiering provide a tier 0 layer of high-performance storage, making it easy to improve performance from 2x to 10x or greater. But there are differences. Caching provides a seamless layer of flash that the application does not need to be aware of everything just goes faster in most applications. This makes it the most common method of using SAS SSDs for performance improvement. Since data changes regularly on a front-end cache, a drive with high endurance would the best fit, such as a SAS SSD with x10 drive writes per day (DWPD), also referred to as “write intensive.”
In some cases, tiering also provides a seamless layer, but the additional storage in the tiered layer is part of primary data storage. It acts as a super-fast layer where the added capacity is a part of the data storage pool. Since caching is not counted towards data storage, you get more capacity with tiered storage that you do with caching. A mixed use (x3 DWPD) or read intensive (x1 DWPD) would typically be a good fit for a data drive.
When storing important data, you should have redundancy with a tiered layer. This is most commonly done with RAID 1 or mirroring, or multiple copies are available in scale-out and cloud environments. With caching, since it is not part of primary storage and it is not the only copy of data, it doesn’t have to be redundant or backed up (assuming “writes” are confirmed to permanent storage).
SSDs excel when the system requirements are more skewed toward performance, reliability and low power. The list of applications which could benefit from faster storage is vast and adoption of SAS SSDs is growing rapidly, and will continue as SSD prices fall and increased densities make it more cost-effective.
Transactional applications require the speed of the storage system and I/O performance (IOPs) to be as high as possible. 12Gb/s SAS SSDs provide the enterprise proven reliability and performance that is needed. Virtualized environments also do well with SAS SSDs due to their small block sizes and highly randomized workloads. Media streaming takes advantage of higher throughput rates that SAS SSDs provide over SATA SSDs and HDDs.
Applications such as online analytic processing (OLAP) that enables a user to easily and selectively extract and view data from different points of view and virtual desktop infrastructure (VDI), where a desktop operating system is hosted within a virtual machine running on a centralized server, also benefits from the higher enterprise-class system performance, connectivity and scalability of 12Gb/s SAS storage interfaces.
The cost analysis, or metrics of caching vs. tiering vary depending on how you measure your datacenter. These could include performance, dollars, power, application transactions or datacenter real estate.
Some common metrics are to compare one solution to another, depending on your application.
SAS SSDs are available through well-established suppliers such as Toshiba, Western Digital/SanDisk and Samsung. Software solutions are also available.
A few examples of solutions as of March 2017:
Tiering and caching are both used to accelerate datacenter and enterprise applications, but take different approaches. Caching is temporary in nature and typically can better utilize a minimal amount of SSDs. Tiering is more permanent, but requires a higher capacity investment in flash to be effectively utilized. Both offer a cost-effective way to improve performance and get more out of your application. For data center applications that require higher IOPs and faster throughput than hard disk drives, 12Gb/s SAS SSDs are especially well-suited for caching or tiering configurations.
DW talks to Kurt Kuckein, Director of Marketing at DDN, about data lifecycle management, with particular reference to the benefits of Object Storage.

1. Please can you provide some background on DDN – when/why formed, key personnel and key milestones to date?
DDN Storage was founded by Paul Bloch and Alex Bouzari; both highly successful IT leaders with 25+ years in founding and managing profitable, high growth technology companies. For almost 20 years now, DDN has committed to delivering the highest levels of customer satisfaction through extensive knowledge and deep experience with hardware, file systems, and applications to accelerate and scale business. Data-intense, global enterprises are leveraging the power of DDN technology and the deep technical expertise of our team to capture, store, process, analyse, collaborate and distribute data at the largest scale and in the most efficient, reliable and cost-effective manner.
In 2017, DDN delivered its first 100+ petabyte storage system. Large scale deployments such as these are becoming more commonplace, not just in the traditional High Performance Computing (HPC) market, but in web and cloud, AI and machine learning types of environments, and mobile applications.
DDN now has over four exabytes in production globally. Measurements used to be based on the capacity attribute of systems but that is now shifting to performance. DDN now has customers with massive performance attributes in their environments, which is spread over thousands of locations and tens of millions of users. That’s a sliver of performance per user or per location, but multiplied together, these new distributed systems are much larger than large HPC environments.
Other notable achievements in 2017 were the opening of a brand new business unit focused entirely on our Infinite Memory Engine (IME) technology; a scale-out, flash-native, software-defined, storage cache headed up by Jessica Popp as General Manager, and the venerated Eric Barton as Chief Technology Officer. We’ve also seen our Non-Volatile Memory (NVM) revenue grow to be a quarter of our business – up from 5% just a few years ago.
2. Please can you outline the DDN product/technology portfolio – you cover block, Flash, file and object storage?
That’s right; DDN delivers a comprehensive and seamless portfolio of storage technologies that provide an extremely flexible set of data lifecycle management tools that can be applied anywhere and at any scale. Our various pillars of technology can be connected together to solve end-to-end data lifecycle management challenges, enabling organisations to achieve peak efficiency and extract maximum value throughout the entire lifecycle of data.
DDN’s Infinite Memory Engine (IME) is designed from the ground up to be a scale-out flash-native, software-defined storage cache that streamlines the data path for application IO. Several key factors, both technological and commercial are creating demand for a new approach to high performance I/O. New non-volatile memory (NVM) device technologies are proliferating and media capacities are increasing rapidly.
A new generation of high-business-value markets are taking advantage of analytics and machine learning and further stressing performance boundaries. Parallel file systems only crudely manage Flash, and HDD performance degrades as concurrency increases making them the bottleneck as performance requirements grow. IME manages data differently, transforming tough workloads into NVMe optimised IO, accelerating a variety workloads to offer wirespeed performance, RDMA support, and linear scaling
Alongside this we have our Scaler file storage systems, which offer best-in-class analytics, parallel file system and NAS for the most data intensive and performance demanding requirements. And we have the world’s most scalable object storage-based technology, WOS, that enables secure, global multi-site collaboration, worldwide distribution of content, active archive and deep archive, real time replication, intelligent tiering, and bridges into public clouds.
3. Of these technologies, Object Storage is a major focus for DDN?
Yes, Object Storage is and will continue to be an area of focus from DDN. Through WOS, we have been able to address customers that require massive volumes of storage for Web/Clolud type applications and archive with all the characteristics that make Object Storage advantageous for those requirements. We are beginning to see requirements for even greater performance in the Object Storage market as applications taking advantage of REST-based interfaces continue to emerge and this will be part of DDN’s direction going forward.
4. Can you outline the key attributes/benefits of DDN’s WOS Object Storage, starting with scalability?
WOS was purpose built to scale much further than traditional data stores like scale-out NAS. DDN’s WOS presents a single scalable storage pool that seamlessly scales to trillions of stored objects and Exabytes of capacity.
However, achieving high scalability is much more than simply measuring object counts and data volume. Considerations such as object size, capacity limits, tiering and caching, metadata management and, as the object store grows, object access times all need to be addressed.
The last point is particularly important for building out object stores that will deliver access to many object store/retrieve requests in parallel, such as systems serving as the backend of a Content Delivery Network (CDN).
Of course, we shouldn’t forget that object stores may need to start small and not be required to have an initial footprint in the hundreds of Terabytes or Petabyte range. DDN provides the capability to have a small entry-level capability, which helps reduce the barriers to entry for object storage adoption, with the added requirement to be able to scale linearly from small to large with minimal operational impact.
5. And flexibility?
Object storage has been at the forefront of the move towards software-defined storage or SDS. The nature of large scale-out deployments has meant object stores work well with the cost model of commodity hardware and vendor-supplied software. As a result, we see many object storage implementations based on software only. As such, WOS is available for software-only deployments on pre-approved third-party systems.
The use of commodity hardware, of course, doesn’t suit all requirements. Many potential customers may be unwilling or unable to manage the process of sourcing and building a bespoke object storage solution, preferring instead to take a combined hardware and software solution from us.
As either software or delivered as a density optimised appliance, WOS provides full flexibility to build the right storage infrastructure for any mix of applications. Customers can tune their infrastructure to meet the requirements for their data and application needs
DDN also offers choice in terms of data protection. DDN is unique in the market in that it offers many different policies so that data protection can be tuned to application requirements. With whole object replication over multiple sites, local erasure coding and multi-site erasure coding, WOS is able to tune policies to the exact profile a customer demands.
6. And simplicity?
Object Storage was designed as a more scalable alternative to file storage solutions for simplified storage needs. File storage was designed for files that need to be modified or changed frequently. As such, file storage is complex to scale because of file system hierarchies and locking mechanisms, which were created to enable file modifications. This overhead drives up the management cost exponentially.
The simplicity of the WOS architecture allows organisations to start as small as a single WOS appliance in four standard rack units and scale in single-node increments. WOS can deliver up to a quarter-million drives in a solitary, shared namespace and provide a single view of files and objects, thus allowing it to provide high-performance storage for active archive and collaboration environments seamlessly.
7. Moving on to the open architecture?
Initial object stores were based on the HTTP(S) protocol, using REST-based API calls to store and retrieve data. The use of HTTP is flexible in that data can be accessed from anywhere on the network (either local or wide-area), however, applications have to be coded to use object stores, compared to accessing data stored in scale-out file systems. Extending protocol support means existing applications can be easily ported or amended to use object stores for their data.
WOS simplifies deployment including support for a broad set of plug-and-play data access protocols including S3, Swift, NFS, SMB, Spectrum Scale and Lustre using an embedded or highly scalable gateways. A REST API is also included for custom app integration.
8. And the ability to access 3rd party applications?
WOS integrates with 3rd party applications either via the S3 interface, or via the native REST. With S3 rapidly becoming the defacto standard interface for Object Storage, this has made it much easier to rapidly qualify and deploy 3rd party applications. DDN has been working for many years with 3rd party developers, and in the past, some chose to integrate directly with the native REST API as well.
9. Not forgetting security?
As with any data store, security is a key feature. In object stores, security features cover a number of aspects.
With the volume of data likely to be retained in an object store, multi-tenancy becomes very important. Business users (either separate departments in an organisation or separate organisations) want to know that their data is isolated from access by others. This means having separate security credentials and offering encryption keys per customer or object within a customer.
WOS is the only object storage platform that offers full flexibility in data protection schemes and enables performance optimisation to comply with data, application or SLA requirements.
WOS also encrypts all communication for the client into WOS and between WOS nodes.
10. And NOFS – what is this, and why is it important?!
WOS delivers up to 20 percent better disk efficiency and density over its closest competitor, and is 1.25x faster thanks to a No File System (NoFS) architecture. While most competitors have built their solution on top of a file system, the unique NoFS architecture of DDN’s WOS solutions level up the management and scalability TCO gains of object storage and offers hard cost savings versus competitive solutions, up to 99 percent efficiency, and significant operational cost savings in space, heating, cooling and administration.
WOS is a true object storage solution, enabled through DDN’s underlying NoFS architecture, which minimises disk operations with as little as a single-disk operation for reads, and two for writes (sharply contrasting the 8-10 I/O operations that POSIX file systems require which result in additional performance and network overhead).
11. And, finally, lower TCO?
WOS was designed as a single storage solution for all unstructured data needs, to easily and reliably store Petabytes of information at the lowest cost. DDN maximises storage efficiency through the NoFS architecture, which keeps the solution easy to manage at scale (one infrastructure). It is not unusual to find customers who manage 10s of PB with just one full-time employee. The TCO can be further optimised by leveraging the WOS Capacity nodes and ObjectAssure, which provides the highest durability, with the lowest overhead of any object storage solution on the market.
12. And how would you characterise DDN’s Object Storage solution when compared to other offerings in the market?
While other Object Storage companies have chased Enterprise storage requirements, which often don’t require quite the scale or aggregate performance, DDN has focused WOS on the needs of the most scalable customers. With individual customers managing more than 500 billion objects on a WOS cluster, DDN has developed the experience and technology to manage the most scalable requirements with ease. That includes making the Object Store very easy to consume, as well as seamless and near effortless to expand as required over time.
13. Let’s move on to the applications for which Object Storage is well suited, starting with enterprise collaboration?
WOS is the only platform that enables integration with (and federation of) parallel file systems, which allows organisations to store assets in a globally distributed storage cloud to enable collaboration between distributed teams and integrate with workflow suites or file sync and share clients. Enterprises, leading research institutions and universities around the world are leveraging WOS to build global collaboration libraries, enabling more efficient workflows and quicker times to results/discovery.
Additionally, there are more and more web based applications that require the scale and ease of management of Object Storage. Because these applications might start as a small test suite or POC and then need to grow into the multi-PB range, they need a storage system that can scale along with them
Finally, there are customers that really need a private cloud, for which Object Storage is very well suited. This cloud could house a variety of applications and have a diverse set of data protection or replication requirements for which something like WOS would be a strong match. Customers want to be able to put primary applications, archive and backup all on one type of flexible scalable space with minimal management overhead for allocation and provisioning.
14. And then there’s Private and Hybrid Cloud?
WOS has been deployed in Private, Hybrid and Public cloud use cases. DDN will continue to explore WOS to make public cloud more accessible to customers as we see that use case expanding over the next 3-5 years.
15. And active archive?
Many providers have been promoting disk storage solutions as an alternative to tape to build “Active” Archives, but few are able to provide the cost-efficiency that is required to build Petabyte-scale repositories. WOS enables organisations to monetise their data and build highly reliable, scale-out archive infrastructures, at the lowest TCO.
WOS provides instant access to all archived assets and integrates with popular archival platforms, such as: ASG® and iRODS®. DDN is a member of the Active Archive Alliance to continue thought leadership and integration points with object storage to the modern archive applications.
16. As well as global content distribution?
The unique latency-aware technology in WOS, combined with the flexibility to optimise for small and large file performance, make WOS the perfect CDN storage origin. DDN has engaged with several partners to build CDN architectures that scale to as many as 60 origin storage sites.
You can enable Video on Demand, Cloud DVR and other video streaming services for residential or corporate end users. WOS provides high-throughput, low latency video delivery streaming for geographically distributed viewers. WOS Video Streaming can be deployed as a custom solution (integrated with API’s or file system gateways) or as a pre-integrated solution using the technology from partners like Arris®, a global innovator in cable, video and broadband technology
17. And ‘good old’ BC/DR?
WOS was originally designed with business continuity in mind, and can easily fit into any IT organisations BC/DR plans. Even within the flexible policies for data a protection, customers can apply to right level of protection to meet their requirements, whether it is simple continuous access to data in the case of a single lost site via Global Object Assure erasure coding, or high performance BC/DR through the use of replication to ensure that applications can always seamlessly transition in the case of data unavailability, with the lowest possible latency.
18. Ending with file sync and share?
Automated Sync & Share applications enable users to securely upload documents to the cloud, synchronise files and mobile devices, and easily share information with others. This is one of the more popular applications that utilise WOS, leveraging the latency-aware and data placement capabilities that are unique to the platform. WOS Sync & Share comes as a pre-integrated partner solution, from companies like CTERA® and OwnCloud®.
19. Can you provide a customer success story?
Deluxe Entertainment Services Group is a leading provider of state-of-the-art services and technologies for the global digital media and entertainment industry. Deluxe provides the technology, talent and high-quality processes to assist a broad range of customers including major motion picture studios, television networks, cable companies, advertising agencies, production companies, independent distributors and content owners.
To better manage feature-film workflow across its global footprint, Deluxe Creative Services sought an improved architecture that would enable selectively replicating data globally for easy and fast access by remote users. Numerous challenges surfaced in meeting this objective, including varied filmmaking process needs and the massive amounts of data generated.
Typically, workflow data is ingested and stored on tier-one disk storage while proxies are created and archived on tape-based storage to be passed out to directors, producers, visual effects teams, marketing and a host of stakeholders for review and editing. As data doesn’t always come in the same way, Deluxe demands great flexibility in how it’s stored, accessed, shared and retained. Additionally, projects moving through post-production create massive storage requirements. Typical feature films produce 300-to-500TB of raw camera masters, with up to 50MB per frame, depending on format. The amount of content doubles with 3D shows and ongoing demand for ultra high-definition resolution means that data sizes continue to grow exponentially.
In evaluating its high-performance archiving requirements, Deluxe Creative Services saw object storage as a potential fit for handling all creative assets generated during post production. By design, object storage boasts a simpler architecture than its SAN and NAS counterparts, making it well suited for building scale-out platforms to support large volumes of this kind of unstructured data.
Following a successful proof of concept validating WOS, Deluxe began deploying the complementary solutions. In rolling out its integrated content repository system, Deluxe is finding it easier to keep production workflows on track, shorten production time, and avoid pitfalls in the filmmaking process. The integrated platform also delivers short-term storage with backup capacity and long-term archiving capabilities that support the preservation of data with its associated user metadata.
Additionally, WOS provides Deluxe with high-reliability storage as the platform offers a choice of data protection capabilities, including ObjectAssure™, which provides local, replicated and globally distributed erasure coding to safeguard data at multiple locations from site failures.
20. What one piece of advice would you give to someone looking at Object Storage for the first time?
Generally, we would advise customers to look at the exact requirements of the Object Storage initiative. We still encounter plenty of customers that say “I have an Object Storage initiative, but I still don’t know how I’m going to use it….”, or perhaps, “I’m looking to Object Storage to replace a small piece of my Enterprise IT.” For those customers, WOS might not be a good fit.
For customers that are looking to off-load vast amounts of data from their primary storage infrastructure, know that they have new applications that may be starting small today but have a growth path into the 10s or 100s of PBs, or are looking at ways to optimise the storage costs of the Data Intensive applications, WOS is going to be a much more likely fit. So for customers, it is important to consider which applications they will be using and how those applications will scale over time.

Data is redefining the business world, giving organisations the ability to find new competencies, acquire customer insights as never before, and tap into new markets. But the propagation of data, as transformational as it is, creates a whole new set of storage management challenges.
By Jon Toor, CMO, Cloudian.
Conventional storage systems can no longer cope with the sheer volume and workload of collecting, storing, managing and protecting information. As storage management increases in importance, are there solutions that can tick the boxes and keep a business viable?
What do the stats say?
A report published at the end of 2016 by Market Research Company IDC estimated that the total capacity of data created or replicated globally in 2012 would equate to 2.8 zettabytes (ZB). Fast forward to 2025, and IDC experts project an increase to 163 ZB in worldwide data creation.
What’s a business to do?
It’s not just about storing more data – companies are also accessing it more frequently and keeping it longer. Add to that new, tighter legislation around data protection, and businesses are under pressure from multiple directions. Unfortunately conventional storage systems weren’t designed with the scalability or flexibility needed to accommodate these new behaviours and are falling woefully short, both on functionality and cost.
To manage data storage capacity, IT planners need a strategy that considers the right storage tier to store and manage the right data, securely, at the appropriate cost.
Object storage as a solution
One storage technology that offers limitless capacity for information and allows companies to consolidate very large amounts of information to a single storage system is object storage. The key differentiator is that an object storage system can grow to any size, making it an ideal solution for organisations needing to manage explosive data growth. Here’s why:
1) Object storage capacity is effectively limitless and can scale as data needs expand.
A company that uses video files, for example, may quickly reach its storage limits after just a few hundred hours of media, especially with emerging 4K/8K, VR and 360-degree formats. In the past, this would have been handled by building extra capacity in advance and ensuring sufficient IT resources were in place to manage changes to the storage system, as they were needed. The scalability of object storage renders this a non-issue. IT planners can quickly and efficiently add more capacity on-demand, with little or no downtime.
2) Object storage is more cost-effective than its traditional enterprise storage counterparts. It uses a flat file structure that makes it easy to manage, and runs on industry-standard commodity servers that cost a lot less than proprietary hardware from traditional storage providers.
Compliance is simplified with object storage
To ensure compliance with government regulations, search is becoming a mission-critical task. Object storage helps by enhancing real-time search capability. It uses metadata to label assets, making it easy to find data using Google-like search tools. Not only that, the metadata can be updated in real time to help organise the archive.
Furthermore, the unlimited capacity of object storage makes it feasible to consolidate data in a single, searchable pool, making it faster and simpler to search and check for duplicate records.
GDPR compliance, in particular, can be aided with enhanced metadata usage. To ensure compliance, organisations must be able to find information. In the flat file structure of object storage, each object has a unique identifier, a tag that can be later used to find information. With these tags - plus a user-defined labelling taxonomy - data requests will be quick and painless, an important point when that inevitable discovery request arrives.
Where data is physically located also matters. Many governments require that certain data types either stay on premises or within geographic boundaries. Here, object storage offers a unique solution. A single storage system can span multiple locations, but data can be held at a specific location within that system. This is important because all data is searchable within that single system, and local compliance requirements can still be met.
Simpler, lower-cost data protection
Most object storage solutions have configurable data protection that lets organisations select the data durability they need. For example, customers may choose from on-site protection, or replicate across sites for disaster recovery purposes. These capabilities are both built into the object storage architecture, making them cost effective and easy to manage.
You can also back-up other storage devices, using object storage as a backup target. Most popular backup solutions work with object storage. That fact, combined with the limitless scalability of object storage, means it’s possible to back up all servers and storage to a single, searchable pool.
Because object storage is cost-effective – with 70 percent lower total cost of ownership (TCO) than traditional storage – it can often cost less than tape.
Future proofing
Migrating data from traditional storage solutions can be time consuming, but the consequences of simply staying and ‘going with the flow’ are dire. Object storage gives businesses the flexibility to run their operations more efficiently and profitably at a time when competition is increasing and customer expectations are rising.
Every industry is feeling the drive to digitally transform. Research from analysts IDC found two thirds of CEOs in large organisations will place digital transformation at the heart of their corporate strategies by the end of 2017. However, simply moving digital transformation ‘up the agenda’ is easy, delivering it is another matter entirely.
By Maarten van Montfoort, Vice President Northwest Europe, COMPAREX.

CIOs, often in charge of already over-burdened IT departments, must lead the digital revolution – but this a considerable challenge. There is little surprise then, that a significant 84% of digital transformation projects fail. These failures are typically a combination of the following three factors.
1. Digital transformation seen as ‘too complex’
There are no discrete start and end-points to digital transformation. As an ongoing, changeable process, it is daunting to many CIOs. This means that all too often, digital transformation is perceived as too complex, and a project doesn’t even get started in the first place. Take cloud as an example; a business makes the decision it will move some workloads to the cloud. So far, so good. The CIO investigates the cloud services available, and how this will change their infrastructure. Slowly, the picture starts to look more complicated – worries emerge over how to integrate legacy IT applications, or how to control costs, and very often, over data security and sovereignty. Eventually, the migration to cloud is shelved.
While there is no doubt organisations’ IT infrastructures have become more complex in recent years, this complexity is not a valid excuse for delaying the adoption of new digital technologies. With robust planning and clear, expert guidance – no complexity is insurmountable. A mix of the right skills and knowledge will enable CIOs to plot an achievable roadmap whatever the level of maturity in the business. The central tenet should be that everything is within ‘the square of possibility’.
2. ‘Legacy thinking’ is holding transformation back
One of the greatest barriers to digital transformation is ‘old-fashioned’ thinking, which means that grassroots ideas are often killed in the weeds. Often, this results in businesses approaching digital initiatives from the IT department’s perspective, rather than that of end-users. A shift in attitude is needed. The organisation must understand that better digital services are fundamental to engaging with users – whether internal employees or external customers – so projects must keep their needs front of mind. In addition, this shift must embrace innovative thinking, and become less concerned with getting everything ‘right’ first time.
In any sector, the companies riding the technology ‘wave’ are the most successful. These are the organisations able to create and launch new products or services in short timeframes, thanks to their agility. By embracing speed – for example, employing quick testing and quick feedback phases – ideas that don’t work can be quickly discarded, and those with promise can be rapidly rolled out.
A conscious choice to be creative, be prepared to take a risk, and to water the seeds of grassroots ideas, will empower true digital transformation.
3. Ill-defined and misaligned projects
Technology is an intrinsic part of any organisation – think of how critical IT departments are to everyday operations. Every organisational and business process is now driven by, or supported by technology. What this should mean in practice, is that there is no divide between the business and the IT department – but often, this is not the case. There are some fundamental questions that any digital transformation undertaking must begin with – what are we trying to achieve, what is our strategy, and how does technology help us achieve this? Frequently, however, organisations begin projects before they have answers to these questions; resulting in ill-defined projects that fail to deliver tangible benefits.
Digital transformation has huge potential for improving the way that businesses interact with stakeholders, how their operations are run, and ultimately, on their bottom line. But to make this digital future a reality, these barriers must be overcome, and CIOs can make this happen. Firstly, by challenging the legacy mind-set that continues to hold enterprises back. Secondly, satisfying boardroom demands by improving the link between the goals of the business and the goals of IT. Thirdly, CIOs must be prepared to take risks – focusing on the digital destination, rather than becoming fixated on the journey of transformation.
How organisations can replace manual processes, free the IT-team from mundane tasks and improve efficiency by building enterprise cloud environments and self-service portals
By Brandon Salmon, Director of Technical Strategy at Tintri

In the past, provisioning IT resources was a manual, time-consuming and tedious process. A developer or business manager requesting resources had to wait days or weeks while the requests got passed around between server and network admins or whatever department was responsible for signing off the additional resource.
However, this approach is coming under increasing pressure. Users are asking why obtaining additional resources to support their latest project from their IT department is not as easy as using their private Amazon, Dropbox or Apple cloud accounts.
Building self-service portals to provision resources can help organisations replace manual processes, free their busy IT teams from mundane and complex tasks and improve overall organisational efficiency. However, adding a self-service portal to an organisation’s IT is only possible if the underlying infrastructure can support it. Before investing in building a self-service portal, it’s vital that an organisation evaluates its underlying infrastructure.
At a consumer level, self-service has already become commonplace. Public cloud providers have added convenient portals to their offerings, making it possible to buy services in seconds. Organisations are looking to replicate this model with self-service portals that can make the internal provisioning of IT resources as easy as one, two, click.
One of the benefits of a self-service portal is that users who are not IT experts can provision IT services without any knowledge of managing complex IT infrastructure. That’s a good thing because, in a self-service environment, it’s hard to know what types of applications users will deploy. For instance, a user can simply provision a VM, set Quality of Service (QoS) for that VM, and specify a snapshot and replication schedule, all in a very intuitive fashion – without being an expert.
DevOps environments can also benefit hugely from self-service. Provisioning and refreshing development environments are common tasks that should be automated to streamline and accelerate the process. Automation, with the right tools, allows DevOps teams to refresh data in development and test environments within minutes. This accelerates continuous integration and the deployment of new software features. The right features for developers can be made available through a self-service portal to create and update development and test environments with current code and data whenever needed.
The platform should be built with a web-services approach that offers important core features and high levels of granularity and abstraction. Clean REST APIs are also needed for all enterprise cloud capabilities to ensure all functions can be automated no matter what self-service platform is used at the front-end.
Another important element of self-service is integration with higher-level tools and platforms. In addition to REST APIs, the right platform should integrate with OpenStack, vRealize Operations and Orchestration, Python SDK and PowerShell. This provides the fundamental building blocks for integration, satisfies any automation requirements and makes enterprise cloud easier to automate and consume in a wide variety of situations.
Traditional infrastructures are unfit to serve as a foundation for a self-service portal, as they simply cannot meet the requirements for granularity and abstraction. On the other hand, it is hard to find classic features, including space-efficient snapshots, replication and other value-added capabilities, in public cloud environments as they usually do not operate at the right level of granularity. To get the best of both worlds, organisations should build their own cloud, based on an enterprise cloud platform, that runs in their own data centre, allowing for both the control of private cloud and the agility of public cloud.
The adoption of an enterprise cloud platform is a solid solution to the problem. The platform fully satisfies the requirements for features, abstraction and granularity – allowing it to be easily incorporated into a self-service portal. This level of granularity enables self-service users to provision each VM with the exact services required. Administrators who have to guarantee performance for all business applications at all times, would have the ability to see performance problems and eliminate them.
The infrastructure an organisation chooses has a direct impact on the functionality of its self-service portal. A modern enterprise cloud platform built from scratch for virtualisation and cloud-native workloads overcomes the limitations of conventional infrastructures by providing the right set of core features operating at the right granularity. This makes it simple for IT teams to expose a rich set of IT services through self-service. Higher-level integrations simplify the automation process to address needs across a range of operating environments. With the right platform in place, organisations can even automate advanced IT functions and make them available through self-service in ways that traditional platforms can’t.
(1)-miq0hs.jpg)
A well-designed and, crucially, well-tested backup and disaster recovery plan is critical to surviving a cyber attack and multi-layered backup should be core to that plan.
By Gareth Griffiths, Chief Technology Officer, BridgeHead Software.
NHS England recently released its 2017/2018 Data Security and Protection Requirements, which sets out ten data security standards. This follows a National Audit Office (NAO) report criticising the NHS for its handling of the WannaCry attack earlier this year. While there is much to commend in this report we do not think this goes far enough.
One of those data security standards states that “a comprehensive business continuity plan must be in place to respond to data and cyber security incidents”. We think there should be more emphasis on the robustness of protection. Having a comprehensive plan is no use if the backups themselves are not secure.
When backup isn’t enough
Just as disaster recovery is an essential component of business continuity in the battle against cyber crime, in the case of ransomware attempts, backup is critical. But, increasingly, we’re seeing that having a single backup strategy is not sufficient and, depending on the storage media, potentially even part of the problem.
Historically, there was little risk to backups themselves, yet ransomware adds a new dimension that threatens and attacks not just the data, but also the backups, as was the case with the WannaCry attack.
Because the risks to NHS systems have evolved, the precautions to protect against new threats are evolving too. Similarly, as the drivers for backing up data changes, the way backups are performed should too.
When backup is part of the problem
Today, many Trusts use online de-duplication devices as their primary backup media. These devices can store many generations of backup in a small footprint at a reasonable cost and they are convenient to use and quick to restore from, i.e. no fetching tapes from offsite storage. BUT, they may actually be more vulnerable to malicious or malware attack, as demonstrated by WannaCry’s proficiency at encrypting files. And, on their own, they present a single point of failure.
While you can protect the single failure point by replicating the device to another location, that does not protect against deliberate corruption. Resilience features like replication are great if one piece of hardware fails, but no defence against deliberate corruption; they simply ensure that the data is perfectly corrupted in multiple locations.
Typically, de-duplication devices look just like any other file server (they typically present an SMB share). Unfortunately, that is just the sort of thing that ransomware looks for. Network file servers are where most sites keep their data so the ransomware looks for these and encrypts them.
In effect, you may have made your backups convenient and easy to use, but also easy to damage and vulnerable to malware like WannaCry. What better way for a cyber criminal to incentivise an organisation to pay up than by corrupting their backups as well as the data?
Lessons from history
· Ten years ago we backed up to tape
o Safe but slow and inconvenient to restore
· Five years ago we changed to backup to online deduplication
o Quick, convenient but vulnerable
Today we need both
Traditionally, data backups were written to tape and stored offsite. While there were, and still are of course, physical threats to backups, such as damage to hardware and disasters such as fires and flood, they were not vulnerable to cyber attack.
An offsite tape in a fire-safe with the write-protect switch set remains the safest form of backup from any threats, cyber or otherwise. Backups are best protected when they are maintained offline from production environments to avoid ransomware viruses corrupting backup copies. We refer to this as the “gold standard”.
While having an offline or tape backup is a good secure media, it is more challenging to use. Tapes have to be located, loaded and positioned and can only be used by one process at a time. For this reason, many Trusts have a desire to move away from tape, but they haven’t always considered the potential vulnerability of disk-based backups.
Rather than moving away from tape completely, at BridgeHead, we believe that offline media must supplement online backups and provide the second layer of protection. So how can you get the best of both worlds - convenient quick access and secure offsite protection?
We recommend an easy to restore from, but less secure first stage backup with a “cascade” on to tape or similar offline removable media. Because the “cascade” copying the data is all on backup servers it does not impact production systems. This is commonly called Disk to Disk to Tape (D2D2T). The final copy doesn’t have to be tape, but it must be safe against malware, secure and offsite. Tape is arguably still the simplest media, although some strongly authenticated cloud storage could be considered.
The disk copy, most likely de-duplication, is used for quick convenient restores, while tape is used for site disasters or if the de-dupe device itself gets damaged physically or corrupted. The first layer might be a backup to a de-duplication store or a storage array snapshot that is then cascaded onto tape, or similar offline media, for long term and more robust backup.
Insurance policy
Much like any other sector, NHS Trusts need to make sure they have robust data backup. There is no one single best practice for backup. But considering, planning and testing disaster recovery and business continuity strategies regularly is an essential part of keeping up with evolving threats and minimising impact on patient care through downtime.
Even with the best firewalls and protection in place, we need to accept that cyber attacks can and will still happen. It isn’t so much if you catch malware as when. What is crucial is that healthcare organisations recover quickly with as little impact on patients as possible.
As the data security standard recommends, Trusts should have a written continuity plan. A well-designed and, crucially, well-tested backup and disaster recovery plan is critical to surviving a cyber attack and we believe that multi-layered backup should be core to that plan.
Law firm Hill Dickinson has transformed the way it stores data.
Founded in 1810, with its UK headquarters in Liverpool, Hill Dickinson is an international commercial law firm with more than 1050 people across its offices in the UK, mainland Europe and Asia. Servicing a wide range of clients including multinational companies, major corporations and UK plcs, the firm delivers strategic advice and guidance spanning the full legal spectrum.
Given the nature of Hill Dickinson’s client base, it has the responsibility to manage and store a significant amount of highly confidential data, therefore having an extremely secure and reliable backup solution is critical to the running of the organisation.
The Challenge: An aging, time-intensive backup solution
Prior to the implementation of Redstor’s cloud backup solution, Hill Dickinson was operating an aging tape-based backup system for longer retention items, alongside a short-term local disk-based backup solution. Although this solution had been adequate in the past, it was quickly becoming unmanageable due to the rapid growth of data. In addition, the physical hardware was nearing end of life, prompting Hill Dickinson to evaluate other solutions available on the market that better aligned with its strategic move to cloud technologies.
Whilst using the existing service and associated tape-based backup, the IT team were spending ever more time managing and maintaining the backup process. The internal time required to manage the estate and move physical tapes had grown to over half-a-day in man hours on a weekly basis.
Due to the large volume of data managed by Hill Dickinson, there was a library of over 4,500 physical tapes in the existing backup process and these had to be indexed and stored as well as securely transported between sites. An ever-increasing amount of physical storage space was required by the tapes themselves and more physical, secure storage space would have to have been arranged to cater for future data growth.
A further issue associated with the ever increasing data growth was the ability of the existing solution to take a full backup within an acceptable business window. Full backups to tape were taking ever longer to complete such that it was starting to encroach on the business day and degrade the performance of the services they provided to the business.
Charlie Muir, Head of IT at Hill Dickinson explains: “The backup solution we were previously using had served us well but had clearly reached its end of useful life. If we had persisted with the physical solution, we were looking at the need for a full expanded hardware refresh and given we were finding more areas that the product didn’t interface with our modernised suite of services effectively we knew we needed to find the next solution that would take us through the next strategic cycle. In addition we had begun to find the physical ownership of the process becoming more costly, complicated and time consuming, with the sheer number of physical tapes being created overwhelming. It was the right time to align our backups with the firm’s wider cloud strategy, and partner with the right provider to take as many of the daily operational burdens as possible while assuring the control and service levels we expect of our critical services.”
Adding to the complexity was that the tape drives themselves were beginning to fail on a more regular basis. Each time a drive failed, engineers had to come out to site and the drive was out of action; which meant backups were unable to complete and time consuming remedial action had to be taken to cover the business risk.
He adds: “The operational end of Backup just isn’t glamorous or an area our staff are naturally drawn to owning. The legacy solution was demanding more and more effort but we found it difficult to persuade anyone in the team to volunteer to spend more of their time managing the process to ensure that we maintained a 100% backup record. It became ‘that job’ that no one wanted to do and it was at this point that we knew enough was enough and that we should look at the problem differently to reduce our risk and release our staff to provide more value elsewhere.”
The Solution: Moving to the cloud with Redstor
Hill Dickinson initially started looking at cloud backup alternatives in February of 2016 with a set of key criteria in place. Firstly, the firm needed a solution that would support multiple sites, would be infinitely scalable to accommodate the business’ increasing data and eliminate the need for tape-based media altogether. In addition, due to the sensitivity of much of the data held, it needed to ensure that its data remained extremely secure to minimise the risk of data breaches or leaks. Finally, the firm wanted to minimise downtime to the systems to avoid disruption to the IT team and the business.
Charlie first met with Redstor in March of 2016 following the recommendation of one of his industry peers and an existing Redstor customer.
Charlie comments: “We had aspired to cloud backup for a while as part of our ongoing cloud adoption strategy and this need to update our existing backup solution was just the catalyst we needed to progress this element. We wanted to work with a provider who would work on a partner level with us and be able to drive the analysis, design, implementation and migration to the end solution, before providing a fully managed service to support our use of it going forward.
“As ever we were ambitious in our timescales for delivery so decided to prioritise those suppliers that came recommended by peers at similar firms. Thankfully Redstor’s products and services came highly recommended and allowed us to filter solutions quickly and save time.
“The best part of the experience for us was the ownership and responsibility that Redstor’s team took to deliver against the tight timescales we had set ourselves, we could not have done it without them and their positive engagement validated our choice!”
During an initial trial of Redstor’s cloud backup, it was determined that Hill Dickinson would need to back up around 100TB of data to Redstor. Due to the volume of data involved and the firm’s stipulation that there was zero negative impact to the operation of the business, the supporting network, and that old and new backups should run in parallel for a number of months; the process of transferring to the cloud and deploying the backup solution across the estate was more complex than originally anticipated. However, all of the targets were met and there was no system downtime or service impact during the transition. In addition, the ability to recover from the legacy solution was not lost as Redstor’s cloud solution was run in conjunction with the older system until the teams had aligned and the service cut across to Redstor.
Charlie says: “Despite the complexity of the migration process, Redstor’s team were able to hold our hands throughout and ensured there was no downtime. It was incredibly important for us to not disrupt the day-to-day running of the business and we managed this to the credit of the two teams involved.”
Measurable improvements
Following a smooth implementation process, Hill Dickinson is now successfully backing up well over the initial 100TB of data estimated, which is stored locally at Hill Dickinson for ease of access, with an additional two backups held securely at Redstor’s UK-based datacentres to ensure maximum continuity.
Redstor’s cloud backup solution provides Hill Dickinson with fast, cost-effective, secure offsite backup; allowing them to rapidly recover data anytime and anywhere. Redstor’s service guarantees security by ensuring that data is encrypted at source, in transit and at rest in Redstor’s dedicated data centres using either 256-bit AES encryption. Only Charlie’s team at Hill Dickinson has access to the encryption key used to encrypt data and thus only they can decrypt and recover their data, making their data that much more secure.
Importantly the Redstor service is incredibly low touch. Fully automated, the service provides Hill Dickinson with automated reports detailing backup success and failure, enabling true management by exception.
With Redstor’s ISO certified disaster recovery solution, Charlie can remain reassured that in the event of a critical issue, involving anything from a ransomware attack to a natural disaster, downtime is kept to a minimum.
In addition to being able to securely backup the law firm’s large amount of data, Redstor’s cloud backup scales effortlessly to accommodate the rapid and unpredictable growth of confidential data stored by Hill Dickinson.
Charlie comments: “Since working with Redstor, there has been a huge transformation to the way Hill Dickinson stores data. Not only do we now have a sustainable and scalable solution, but we no longer need to dedicate a highly skilled team member’s time to maintain the backup process, meaning we can dedicate the team’s time to driving value for the firm.”
He concludes: “At a recent internal supplier review meeting, we were proud to place Redstor in our top supplier quadrant. We do not consider Redstor to be a supplier but a trusted partner providing a technology and service view that underpins much of what the team here does.”
On May 25th, 2018, the EU’s General Data Protection Regulation (GDPR) comes into force. It will shake up the unacceptably slack standards that have been applied to the privacy of citizens’ data to date and is very likely to provide a decisive push towards the widespread adoption of strong encryption among businesses worldwide.
By Shaun Orpen, Commercial Director at Scentrics.

Unlike the directives that form most the EU’s legal output, and which can be interpreted somewhat differently by member states, GDPR is a regulation and, in eight months, becomes a binding, uniform law in each nation. That’s part of the point: historically, different nations in the Union had different requirements, complicating the practice of doing business with the EU. Uniform regulation on data privacy makes it simpler to do business across the Union, both for its members and the rest of the world.
The UK government announced it would follow the legislation, Brexit notwithstanding, in the Queen’s speech in June. And even if the Government changes its mind, UK companies hoping to trade with EU member states, still comprising the world's largest single market, will need to comply and accept the terms of the regulation, whatever local laws might be introduced as an alternative.
GDPR is something of a victory for consumers. It aims to give protection to EU citizens over the privacy of their personal data. The level and depth of privacy breaches from private companies in possession of people’s personal information has been deemed far too high, and fierce punishments will be visited upon organisations that continue to fail to exercise proper vigilance. The penalties for non-compliance or infringement are 4% of previous year annual turnover, and/or €20 million.
It's high time that some action was taken to try to make people’s information safer on the Internet: online fraud is now the most common crime in the UK, with one in ten of the nation’s citizens having fallen victim already.
It's not quite the consumer revolution many might have hoped for, though. The larger internet giants - the likes of Facebook and Google - have already immunised themselves against the colossal fines introduced through the directive by amending the terms of service we all blithely click through, to guard themselves against prosecution.
For many other businesses, though, particularly mid-sized and smaller organisations, these potentially fatal penalties create considerable cause for alarm.
GDPR affects both what it describes as the “controllers” and the “processors” of personal data. “Controllers” determine how and why data is processed, and largely comprise the brands and businesses most people will be used to doing business with on the Internet. “Processors” handle data on the controllers’ behalf and include the likes of fulfilment and logistics companies, all sorts of agencies, advertising networks and more. Typically, mid-sized companies or smaller.
The administrative load and technical expertise required is extremely heavy for these smaller organisations.
Alongside guarding against the continuing threat from hackers and malware, the Regulation requires processors to notify the authorities of any breach, however small it may be, within 72 hours.
More types of digital information, such as IP addresses, now fall under the definition of personal data.
Consent must be given by parents for the retention of children’s data, for the specific purposes for which it will be used, and controllers must be able to prove that such consent has been obtained. This measure alone must be giving CIOs sleepless nights on a regular basis.
GDPR will also codify the regulations around people’s “right to be forgotten” on the Internet, give them a right to know if their data has been compromised, a right to transfer their data, the ability to access their data and understand how it is processed.
So, there are a substantial number of new legal responsibilities, and massive penalties should organisations be found lacking in their commitment to these responsibilities. While it doesn’t seem as though data security could be described as a key priority for many internet-based companies heretofore, from now on, it must be.
At this point, encryption technology should seem like a very sensible piece of insurance for any company with personal information about its users and computers connected to the Internet. If the last 30 years of Internet history has shown us anything, then it's that technology will be hacked. Even the best experts in the field agree that "security is a journey", constantly moving forwards to evade the grasp of bad actors who are always only inches behind the most vigilant and best-resourced companies and organisations on the Net.
For many small and medium-sized companies, the continual upgrades, testing and on-site expertise required to meet secure standards will be a difficult and expensive path to follow. So, they will, very understandably, outsource, at the very least, the finer details of security to third-parties and take out insurance policies to limit their exposure. Both of those things cost money, but nothing in the region of the penalties that falling foul of the GDPR police would attract.
Modern, strong encryption - applied as a transparent service to files, communications and other identifiable data - provides an extra layer of safety. One that will be both less expensive and more powerful than either third-party warranties or insurance policies.
Your server might be hacked, your regular security measures foiled - these things happen every day. But if the files that fall into hackers' hands are also securely encrypted, then those criminals are left with nothing that could compromise your customers or - under GDPR - your entire business. You might think of encryption-as-a-service as being analogous to a bank safe in pre-electronic times. There's a lock on the front door of the bank, various other security measures, but for peace of mind, the money and other sensitive documents sit inside a safe overnight.
Would you trust your money with a bank that didn't have a safe? That's precisely the argument for businesses to adopt wholesale encryption immediately.

With super-fast quantum computers and data stored on DNA are we about to witness a seismic shift in storage?
By Nick Powling, General Manager, Components, Hammer.
Earlier this year, scientists revealed they had built the world's first quantum computer. It could be the first of many. Google said it anticipates the first commercial quantum computers in five years. IBM, for example, already has plans to build a commercially available universal quantum computer for business and science.
Significantly, these quantum machines will leave current supercomputers looking more like the early clunking mainframes, such are the processing speeds.
This is significant on many levels; speed and adaptability are essential for two of the latest disruptors; the Internet of Things (IoT) and artificial intelligence (AI).
IoT is where machines ‘talk’ to each other via the internet. These are the wearable and mobile devices we are currently familiar with but also, increasingly, many household goods. According to Business Insider by 2020 there will be 193m such devices shipped in 2020 ranging from washers, dryers and refrigerators to sensors, monitors, cameras, alarm systems and thermostats.
These internet-connected machines will take decisions and carry out actions without the need for human involvement. For example, to regulate a nation’s energy demand washing machines and dishwashers would know to activate when energy demand was low and freezers would decide to switch off for a harmless couple of hours when demand was high. They would take such decisions based on real-time data being fed from the National Grid’s IoT-linked monitors.
This is all entry-level IoT. As the concept matures, machine actions will require a level of awareness normally associated with human judgment such as visual perception and speech recognition. This is artificial intelligence.
None of this is breaking news, so what’s it all got to do with quantum computing? The connection is data. Both the IoT and AI are, at their core, based on data generation and analysis. The volumes of data we see today – which we already are calling a deluge – will seem small fry once IoT and AI become mainstream. Big Data is morphing into Mega Data.
Being able to manipulate and process this data is of paramount importance, which is where the added factor of quantum computing comes in.
Traditionally, computers code information as bits – either a 1 or a 0. Quantum computing is far more flexible. Data can be coded as either a 1 or 0, or both, or somewhere in between. The industry has termed these as ‘qubits’. It means many calculations can be performed significantly faster and simultaneously rather than sequentially. To meet the challenge, Microsoft is planning the first quantum programming language.
This ability to cope with growing data volumes is imperative when you consider the importance placed on it. According to The Economist, this dependency makes data the most valuable commodity of our age. More data has been created in the past two years than in all time preceding it. Inside Big Data estimates this digital universe will double every two years at least, that’s a 50-fold growth from 2010 to 2020 with machine data increasing even more rapidly at 50x the growth rate.
That’s a lot of data; where will it be stored? True, today’s drive vendors are creating ever larger capacity drives - both HDD and SSDs. HGST is offering a 14TB HDD, WD a 12TB HDD and Toshiba is also planning a 14TB drive. Seagate is marketing a 60TB SSD. Stacks are becoming higher with the multiplier effect allowing datacentres to store greater volumes.
Clearly, however, the demand is there for far greater storage capacities, hence the research into new storage methods such as Heated Dot Magnetic Recording (HDMR) and Microwave-Assisted Magnetic Recording (MAMR), as this Hammer thought-leader article explores.
One pioneering project is looking at DNA as a data storage medium. DNA - deoxyribonucleic acid - is a self-replicating material which is present in nearly all living organisms. It is the carrier of genetic information and was discovered in the 1950s.
Scientists have been storing digital data in DNA since 2012 and, as this report states, Microsoft is hoping to take the technology commercial. The company told the MIT Technology Review that it plans to have an operational storage system based on DNA up and running inside a datacentre by the end of the decade.
Unlike conventional hard drive materials, which only store data on a two-dimensional surface, DNA is a three-dimensional molecule. That extra vertical dimension lets DNA store much more data per unit area: 215 million gigabytes (that’s 215 petabytes) in a single gram of DNA. What’s more, DNA won’t degrade or become obsolete and lasts for hundreds of thousands of years, says Science Magazine.
So, with IoT and AI we have the demand for data storage and with DNA we will have the capacity. What quantum computing does is enable that data to be properly scrutinised and analysed. Quantum computers will power all of our AI systems, acting as the brains of these super-human machines, according to Forbes.
Whether it’s data storage, servers or networks, Hammer, with its 25-plus years’ experience and backed by 40 world-class vendors, can provide the expertise and insight to help channel partners meet the varying and demanding IT needs of their customers.

Addressing the challenges posed by video data storage – consolidation, data synchronisation, network latency and the like.
By David Trossell, CEO and CTO of Bridgeworks.
An International media company wants to consolidate its video editing operations in New York and London. This will split their video data between their offices in the two cities. Sixty terabytes will be stored in London, and the same amount of data will be stored in New York. Yet the company needs to have the capacity to move this data in between its two datacentres in these locations.
It’s not just a consolidation exercise, but a data synchronisation one, and the challenge is to mitigate the impact of data and network latency, which usually increases the further apart datacentres are located from each other. The response has traditionally been to place the datacentres in close proximity to each other. Such a strategy for reducing latency is risky, because if a natural disaster were to occur, the two datacentres could be affected, putting your organisation’s ability to operate in jeopardy. Not only that, but it could also damage your reputation and lead to downtime and financial losses.
So, if your company or its products are reliant on video data, then there is a need to seek an approach that permits both datacentres to be placed outside of their respective circles of disruption – at a distance from each other. The answer is not to use WAN optimisation, as this cannot deal with data compression efficiently. Instead, data acceleration tools such as PORTrockIT should be deployed to allow encrypted and compressed video data to flow without being hindered by data and network latency, and reduce jitter that can spoil the viewing experience.
Engaging with video
Research by Tubular Insights finds that Facebook users consider video 5 times more engaging than images. Facebook and Kantar found in their joint study that participants are 1.20x more likely to watch video at least once a day on a smartphone than on a computer. They also found that the study’s participants prefer to watch videos of no more than 10 minutes, with millennials being 1.36x more likely to watch it on a mobile device than on a PC.
Tubular Insights also says: “There were 3.1 trillion Facebook video views between November 2015 and November 2016; that’s a staggering increase of 94% year-on-year! With Facebook users spending an average of 50 minutes per day on the site, and over 100 million hours of daily video watch time being generated, the reach and influence of Facebook video content is only set to increase.” The significant year-on-year growth of Facebook video viewings clearly shows that video data is set to increase to many zettabytes over the next decade as video will be increasingly used in social media, digital broadcasting, marketing and advertising, as well as by autonomous vehicles by 2025.
5G: Video demand to increase
In June 2017, Total Telecom wrote: “With 5G likely to become commercially available in 2020, operators have three years to lay the foundations of a network that will change the way people interact forever. The sheer volume of devices and data that will be created by 5G – some 25 billion, creating two zettabytes of data by 2025 according to Machina Research – means the network build-out will need to be of a scope unlike anything that has been done before.”
To meet the challenge of managing, streaming, back-up and restoring ever larger amounts of data, large vendors such as Intel will no doubt tell you that there is a need to upgrade your existing infrastructure – particularly when 5G mobile networks are just around the corner. “Find out what it takes to envision, plan, and deploy critical service, performance, and IT management upgrades,” says Intel’s website. It suggests that network transformations are required to manage rich media, provide high-speed wireless connectivity, manage hybrid cloud, offer a 5G communications cloud, and offer a Virtualized IP Multimedia Subsystem.
This may be excellent technology, but the question should be about whether you really need to upgrade your network to cope with the challenges that big data and increasing video data volumes pose. With data acceleration, there may be no need or you could delay that upgrade to allow your network infrastructure to cope with the demands of video data. It is possible to consolidate it and to synchronise it with a data acceleration tool.
What’s also important to remember is that the data quite often may need to travel across a fixed line connection at some point. The fact that the speed of light has its limitations is often hidden too, and so buying more bandwidth doesn’t necessarily mean that you’ll be able to deliver more and faster streaming video data. However, it is important from a viewer’s user experience perspective to find ways to reduce latency.
Grab attention
People won’t stay around long if it affects their ability to view some video footage – whether it is used in broadcasting, advertising, video conferencing or on social media. They want access now, and if that capability is not provided, they will quite happily jump to one of your competitors. The opportunity to capture their attention, and in the case of advertising, the chance to sell to them, will have been lost for good. In scientific circles, video and still images are being used to further medical research, and if the devil of latency arises, their ability to use analytical engines or to retrieve the data they need to further their studies might negatively be affected too.
Support collaboration
In broadcasting, there is another requirement: Footage may be taken for a digital TV programme in one country, but it may need to be edited in another country or location far from its original source. Some of it may be uploaded to some form of database to allow people to work collaboratively on a filming project without being delayed by latency, and without files being corrupted by packet loss. The video they are creating is very data heavy, and so data acceleration is needed to ensure that it can be accessed instantaneously by a multitude of people in many widespread locations.
Time to intelligent
Netflix, for example, knows that this is important, too, but the ability to view a film does not just depend on having a subscription. Much also depends on the network speed being used by each viewer’s broadband. However, this does not mean that companies should not invest in data acceleration. Companies should certainly have the right network infrastructure solutions in place, because latency can begin at any point along a local area or wide area network.
By investing in their network infrastructure, they are investing in customer experience and customer loyalty – as well as in the potential present and future profitability of the firm. They can also use artificial intelligence and machine learning to present movies and TV programmes to their subscribers that they may want to watch. So time to intelligence must be built into this capability, allowing fast, timely and real-time big data analysis. All of this can be achieved with data acceleration tools.

Data deletion is reversible and insecure, whereas data
erasure is permanent and ensures the information can never be retrieved. Yet,
the two terms are widely confused. Richard, Stiennon, Chief Strategy Officer of
Blancco Technology Group and Director
of IDSC, outlines why this could present major issues under
the terms of the EU GDPR, which goes into effect in less than a year on May 25,
2018.
According to a recent IBM study, 90 percent of the data in the world today has been created in the last two years alone. This equates to a current data output of roughly 2.5 quintillion bytes a day. If you consider how many networks, hard drives, virtual machines, computers/laptops, smartphones, tablets, flash media drives and cloud drives exist today, to say there’s a lot of information out there would be an understatement.
What’s more, current worldwide data centre storage capacity is estimated to be 770 exabytes with forecasters expecting it to increase to nearly 2000 exabytes by 2020.
An abundance of data can create enormous benefits, such as increased productivity, enriched data, efficient processes and improved quality of life. As promising as this sounds, we must remember that with such benefits also comes great responsibility, and even liability. Although this might sound dramatic, when you think about the personal usernames and passwords, financial and bank account information, credit cards and debit cards linked directly to mobile devices, health records, social security numbers and other sensitive information sitting in all of these environments, the need to be vigilant is even greater.
Each time a retailer, healthcare provider or financial institution fails to erase the data they are holding permanently, they are putting themselves and their millions of customers at risk of cyber attacks, data breaches, fraud and even identity theft. As of May 2018, they will also be at risk of failing to comply with the EU General Data Protection Regulation. EU GDPR will require organisations to have a much better idea of what data is stored and where it’s stored, as well as what processes they have in place to remove it when required by data retention rules or if requested by customers. What’s more, due to the new regulations, customers will be taking a greater interest in the contract terms around data erasure, many of which are currently not fit for purpose.
Now is the time for organisations to take a close look at exactly what data is being stored in the cloud, how much of it is really needed and what happens to it when it reaches end of life. Failing to do so will not only result in large fines, but also loss of business and damage to its reputation.
EU GDPR and the right to be forgotten
The arrival of EU GDPR will serve to both strengthen and unify data protection for individuals by forcing organisations to align their data management policies and practices with its stringent rules. An important part of the incoming EU GDPR legislation means that anyone will have the right to request the erasure of their personal data “without undue delay” under a number of circumstances, such as by removing their consent for its processing – a bit like lending someone a book and asking for it back. At the end of the day, it belongs to you and you have every right to ask them to return it to you.
Whether or not you believe this to be a difficult task, in order to be compliant, any organisation needs to be able to remove each and every record relating to that particular person as soon as they make the request. The directive also introduces huge fines for companies that fail to protect the data they collect from consumers. With so much at stake, do businesses know the steps they need to take in order to ensure a user’s data is erased securely, safely and irreversibly? And will consumers enforce their right to ask for proof that all of their data has been successfully destroyed?
Deletion of data is not enough
There continues to be major confusion around the terms used for permanently erasing personal data. Worryingly, many people still don’t fully comprehend data sanitization. This is the process of deliberately and irreversibly removing or destroying data in order to ensure it is fully irrecoverable. Some organisations believe that factory reset, reformatting, data wiping and data clearing are capable methods of achieving data sanitization, when they are far from it. This is the case for all traditional IT equipment and data storage, as well as mobile devices and any internet-connected devices.
The confusion stems from the definition and the varying methods of achieving it, which results in organisations failing to employ the necessary steps to implement data sanitization and therefore continuing to leave themselves vulnerable to data theft. If security processes are not up to scratch, an organisation cannot guarantee that it is able to adequately protect customers’ sensitive information. If they are requested to erase a particular person’s personal data they will not be doing so adequately. What’s more, consumers are not enforcing their right to ask for proof that all their data has been successfully destroyed – ultimately because they are unaware of their rights to do so.
When taking a closer look at the language and terminology used within legal contracts by software as a service vendors and cloud infrastructure providers, it’s clear that confusion around the difference between data deletion and data erasure isn’t confined just to everyday users. More specifically, their contracts don’t always include the necessary terminology to specify if and when data is permanently erased when customers end their services/relationship with the providers. And when they do, they often use incorrect terminology such as ‘data deletion’ or ‘data wiping’ to indicate that a customer’s records are being removed. But as we know, data deletion and data wiping do not meet the criteria for data sanitization and therefore, could leave data accessible or exposed.
Below are some examples we have seen specified in contracts.
Salesforce: “After such 30-day period, we will have no obligation to maintain or provide any copies of your data, and as provided in the documentation we will thereafter delete or destroy all copies of your data in our systems or otherwise in our possession or control, unless legally prohibited.”
Microsoft Azure: “If you do not fully address the reasons for the suspension within 60 days after we suspend, we may terminate your Subscription and delete your customer Data without any retention period.”
Dropbox: “After a commercially reasonable period of time, Dropbox may delete any Stored Data relating to Customer’s account.”
The solution here is to properly educate organisations on the correct definitions and terminology and to ensure that improper methods that aren’t capable of achieving data sanitization are no longer used, and no longer referred to in legal contracts. If they continue to use such terminology, it could put them at serious legal and financial risks. Furthermore, a company should provide assurances and proof (this is an area that most fall short in) that when a request for data removal has been made, the data has been permanently and verifiably erased so that it can never be recovered.
Routinely sanitize your data
Organisations should be encouraged to make it a priority to conduct data protection audits on a regular basis in order to identify existing gaps and problems within their IT infrastructure and security posture. This will allow them to both correct such problems, as well as implement the necessary correction actions so they can be in regulatory compliance in the future.
The more often audits take place, the more certain an organisation can be in terms of knowing exactly how much data it is responsible for. After all, the more data you hold, the higher the chance you have of forgetting that some of it exists. If you’re unsure of the types of data you hold, you have a lower chance of being able to understand how to properly prioritise actions to protect that data and prevent it from being accessed or exposed to a data breach. If you’re unsure of the volume and type of data you’re working with, how can you properly manage it, mitigate the risks and prevent unnecessary data theft? Without a comprehensive picture of your data landscape, and if your organisation were to fall victim to a data breach, it would become all but impossible to fully comprehend the scale of the issue and how many people it would have affected.
According to Gartner, companies spend an average of $1,593 per raw terabyte of capacity on data storage costs each year. These costs include annual operational expense, lease, depreciation, maintenance, installation and taxes, as well as hardware, software, connectivity, disaster recovery, occupancy and personnel. However, only 15 per cent of the average company’s data is business-critical, which leaves 85 per cent that can be classified as ROT (redundant, obsolete or trivial) and dark data that could be erased. When the data stored by companies is deemed unnecessary and there is no data erasure process in place, the cost of storing data compound over time. However, if a data erasure process is in place, their storage costs will decrease significantly over time. On top of these cost savings, data erasure reduces the quantity of data that could potentially be exposed to data loss or theft in the event of a data breach.
Consider this, if your corporation is hosting servers at a data centre and the data centre operator files for bankruptcy, what happens to all of their equipment with your data on it? It goes to the bankruptcy court. The bankruptcy court is highly unlikely to fully sanitise and erase your data. They will more likely resell the hard drives, the equipment, the servers and your data along with it without first sanitizing the data – and all of that sensitive information could very well be passed to who knows where.
The threat to our data is increasing with data continuously being exfiltrated and security breaches continuing to dominate headlines around the world. However, organisations are still not changing how they handle things. With so much important and oftentimes confidential data running through any corporation, it’s hard to believe that security risks such as these, for which there are such simple preventative measures, continue to be overlooked.
If organisations continue along this path, not only will they be risking their reputation, they will incur huge fines that ultimately could force them to shut their doors. EU GDPR is coming in May 2018 so it’s not a matter of if, but when each and every organisation will be scrutinised in terms of their data protection policies.