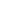In this issue of DCS you’ll find plenty of food for thought. Our Uptime Institute article gives a great insight into the thinking behind the Green Mountain data centre operation in Norway – where sustainability and energy efficiency are very much top of the agenda. Likewise, the Q and A with The Green Grid has a major focus on the same themes. Cynics might continue to suggest that no organisation will spend money on becoming green unless there’s a worthwhile financial payback, but the good news is that, broadly speaking, sustainability and energy efficiency are, more often than not, about improving the performance of some aspect of the data centre, hence there often is some kind of a monetary ‘reward’.
As I think I’ve written previously, for an industry that does consume significant amounts of energy, the data centre market has managed to remain pretty much ‘under the radar’ when it comes to attracting the attention of the environmental lobby. For as long as data centre owners, operators and industry organisations continue to focus on optimising the performance of the facilities that underpin almost every aspect of 21st century life – and certainly the rapidly developing digital age – then they can rest assured that they will be able to counter any criticism of their environmental performance with a degree of authority and pride.
Key to this successful future is understanding and adopting as appropriate the many new developments and innovations that are becoming such a hallmark of the IT and data centre landscape. The glass half-empty view sees far too many new ideas and products – how is anyone supposed to keep on top of all these developments, let alone decide if, how and when to deploy them? The glass half-full sees nothing but opportunity to continue improving performance, hence productivity and profitability. Our Q and A with Panduit provides a great insight into what’s going on in the world of fibre connectivity and networks – and I’m delighted to say that we’ll be running a series of articles on the future of this sector of the IT/data centre space over the coming months.
Not so long ago, 10G connectivity seemed a long way away for the average enterprise, but now companies like Panduit are already plotting a course towards 400G! Okay, so many end users might be bemused as to why they would ever need such speed. However, as the digital age evolves, who’s to say that, at some stage in the future, 400G will become just another stepping stone in the quest for ever faster feeds and speeds?
Advertisement: Server Technology
With tens of thousands of HDOT (High Density Outlet Technology) PDUs already installed, Server Technology has now completed its most popular and innovative product line ever with the addition of the HDOT Switched POPS® (Per Outlet Power Sensing) PDU. Now with device level monitoring, the most uniquely valuable rack PDU on the market provides the #1 solution for density, capacity planning, and remote power management for the modern data center.

Enterprise server rooms will be unable to meet the compute power and IT energy efficiencies required to meet the demands of fluctuating technology trends, pushing a higher uptake in hyperscale cloud and colocation facilities.
Citing the latest IDC research, which predicts a growing fall in the number of server rooms globally, Roel Castelein, Customer Services Director, at The Green Grid argues that legacy server rooms are failing to keep pace with new workload types and causing organisations to seek alternative solutions.
“It wasn’t too long ago that the main data exchanges going through a server room were email and file storing processes, where 2-5KW racks was often sufficient. But as technology has grown, so have the pressures and demands placed on the data centre. Now, we’re seeing data centres equipped with 10-12KW racks to better cater for modern-day requirements, with legacy data centres falling further behind.
“IoT, social media, and the number of personal devices now accessing data are just a handful of factors that are pushing the demands of compute power and energy consumption, which is causing further pressures on legacy server rooms used within the enterprise. As a result, more organisations are now shifting to cloud-based services, dominated by the likes of Google and Microsoft, and also colo facilities. This trend is not only reducing carbon footprints, but also guarantees that the environment organisations are buying into are both energy efficient and equipped for higher server processing.”
In IDC’s latest report, ‘Worldwide Datacenter Census and Construction 2014-2018 Forecast: Aging Enterprise Datacenters and the Accelerating Service Provider Buildout’, it claims that while the industry is at a record high of 8.6 million data centre facilities, after this year, there will be a significant reduction in server rooms. This is due to the growth and popularity of public cloud based services, occupied by the large hyperscalers including AWS, Azure and Google, which is expected to grow to 400 hyperscale data centres globally by the end of 2018. Roel continued:
“While server rooms are declining, this won’t affect the data centre industry as a whole. The research identified that data centre square footage is expected to grow to 1.94bn, up from 1.58bn in 2013. And with hyperscale and colo facilities offering new services in the form of high-performance compute (HPC) and Open Compute Project (OCP), more organisations will see the benefits in having more powerful, yet energy efficient IT solutions that meet modern technology requirements.”
The growth of cloud and industrialized services and the decline of traditional data center outsourcing (DCO) indicate a massive shift toward hybrid infrastructure services, according to Gartner, Inc.
In a report containing a series of predictions about IT infrastructure services, Gartner analysts said that by 2020, cloud, hosting and traditional infrastructure services will come in more or less at par in terms of spending.
"As the demand for agility and flexibility grows, organizations will shift toward more industrialized, less-tailored options," said DD Mishra, research director at Gartner. "Organizations that adopt hybrid infrastructure will optimize costs and increase efficiency. However, it increases the complexity of selecting the right toolset to deliver end-to-end services in a multisourced environment."
Gartner predicts that by 2020, 90 percent of organizations will adopt hybrid infrastructure management capabilities.
The traditional DCO market is shrinking, according to Gartner's forecast data. Worldwide traditional DCO spending is expected to decline from $55.1 billion in 2016 to $45.2 billion in 2020. Cloud compute services, on the other hand, are expected to grow from $23.3 billion in 2016 to reach $68.4 billion in 2020. Spending on colocation and hosting is also expected to increase, from $53.9 billion in 2016 to $74.5 billion in 2020. In addition, infrastructure utility services (IUS) will grow from $21.3 billion in 2016 to $37 billion in 2020 and storage as a service will increase from $1.7 billion in 2016 to 2.7 billion in 2020.
Advertisement: Vertiv

In 2016, traditional worldwide DCO and IUS together represented 49 percent of the $154 billion total data center services market worldwide, consisting of DCO/IUS, hosting and cloud infrastructure as a service (IaaS). This is expected to tilt further toward cloud IaaS and hosting, and by 2020, DCO/IUS will be approximately 35 percent of the expected $228 billion worldwide data center services market.
"This means that by 2020 traditional services will coexist with a minority share alongside the industrialized and digitalized services," said Mr. Mishra.
A 2016 Gartner survey of 303 DCO reference customers worldwide found that 20 percent use hybrid infrastructure services and 20 percent more intend to get them in the next 12 months.
Gartner also predicts that through 2020, data center and relevant "as a service" (aaS) pricing will continue to decline by at least 10 percent per year.
From 2008 through 2016, Gartner pricing analysis of data center service offerings shows prices have dropped yearly by 5 percent to 7 percent for large deals and by 9 percent to 12 percent for smaller deals.
More recently — from 2012 to the present — prices for the new aaS offerings, including IaaS and storage as a service, have dropped in similar to higher ranges.
Traditional DCO vendors will exit the DCO market due to price pressure, while others will develop solution capabilities and continue to compete. Buyers will have the ability to choose between many more vendors, choose traditional or new solutions and achieve price reductions year over year through 2020.
By 2019, 90 percent of native cloud IaaS providers will be forced out of this market by the Amazon Web Services (AWS)-Microsoft duopoly.
Over the last four years, the public cloud IaaS market has begun to develop two dominant leaders — AWS and Microsoft Azure — that are beginning to corner the market. In 2016, they both grew their cloud service businesses significantly while other players are sliding backward in comparison. Between them, they not only have many times the compute power of all other players, but they are also investing in innovative service and pricing offerings that others cannot match.
According to Gartner, it is only in new markets that the dominance of AWS and Microsoft will be challenged by businesses such as Aliyun, the cloud service arm of Alibaba, the top player in China.
"The competition between AWS and Azure in the IaaS market will benefit sourcing executives in the short to medium term but may be of concern in the longer term," said David Groombridge, research director at Gartner. "Lack of substantial competition for two key providers could lead to an uncompetitive market. This could see organizations locked into one platform by dependence on proprietary capabilities and potentially exposed to substantial price increases."
New data from Synergy Research Group shows that hyperscale operators are aggressively growing their share of key cloud service markets, which are themselves growing at impressive rates.
Synergy’s new research has identified 24 companies that meet its definition of hyperscale, and in 2016 those companies in aggregate accounted for 68% of the cloud infrastructure services market (IaaS, PaaS, private hosted cloud services) and 59% of the SaaS market. In 2012 those hyperscale operators accounted for just 47% of each of those markets. Hyperscale operators typically have hundreds of thousands of servers in their data center networks, while the largest, such as Amazon and Google, have millions of servers.
In aggregate those 24 hyperscale operators now have almost 320 large data centers in their networks, with many of them having substantial infrastructure in multiple countries. The companies with the broadest data center footprint are the leading cloud providers – Amazon, Microsoft and IBM. Each has 45 or more data center locations with at least two in each of the four regions (North America, APAC, EMEA and Latin America). The scale of infrastructure investment required to be a leading player in cloud services or cloud-enabled services means that few companies are able to keep pace with the hyperscale operators, and they continue to both increase their share of service markets and account for an ever-larger portion of spend on data center infrastructure equipment – servers, storage, networking, network security and associated software.
Advertisement: Geist

“Hyperscale operators are now dominating the IT landscape in so many different ways,” said John Dinsdale, a Chief Analyst and Research Director at Synergy Research Group. “They are reshaping the services market, radically changing IT spending patterns within enterprises, and causing major disruptions among infrastructure technology vendors. Our latest forecasts show these factors being accentuated over the next five years.”
Worldwide IT spending is projected to total $3.5 trillion in 2017, a 1.4 percent increase from 2016, according to Gartner, Inc. This growth rate is down from the previous quarter's forecast of 2.7 percent, due in part to the rising U.S. dollar (see Table 1.)
"The strong U.S. dollar has cut $67 billion out of our 2017 IT spending forecast," said John-David Lovelock, research vice president at Gartner. "We expect these currency headwinds to be a drag on earnings of U.S.-based multinational IT vendors through 2017."
The Gartner Worldwide IT Spending Forecast is the leading indicator of major technology trends across the hardware, software, IT services and telecom markets. For more than a decade, global IT and business executives have been using these highly anticipated quarterly reports to recognize market opportunities and challenges, and base their critical business decisions on proven methodologies rather than guesswork.
The data center system segment is expected to grow 0.3 percent in 2017. While this is up from negative growth in 2016, the segment is experiencing a slowdown in the server market. "We are seeing a shift in who is buying servers and who they are buying them from," said Mr. Lovelock. "Enterprises are moving away from buying servers from the traditional vendors and instead renting server power in the cloud from companies such as Amazon, Google and Microsoft. This has created a reduction in spending on servers which is impacting the overall data center system segment."
Table 1. Worldwide IT Spending Forecast (Billions of U.S. Dollars)
|
| 2016Spending | 2016 Growth (%) | 2017Spending | 2017 Growth (%) | 2018 Spending | 2018 Growth (%) |
| Data Center Systems | 171 | -0.1 | 171 | 0.3 | 173 | 1.2 |
| Enterprise Software | 332 | 5.9 | 351 | 5.5 | 376 | 7.1 |
| Devices | 634 | -2.6 | 645 | 1.7 | 656 | 1.7 |
| IT Services | 897 | 3.6 | 917 | 2.3 | 961 | 4.7 |
| Communications Services | 1,380 | -1.4 | 1,376 | -0.3 | 1,394 | 1.3 |
| Overall IT | 3,414 | 0.4 | 3,460 | 1.4 | 3,559 | 2.9 |
Source: Gartner (April 2017)
Advertisement: Sudlows

Driven by strength in mobile phone sales and smaller improvements in sales of printers, PCs and tablets, worldwide spending on devices (PCs, tablets, ultramobiles and mobile phones) is projected to grow 1.7 percent in 2017, to reach $645 billion. This is up from negative 2.6 percent growth in 2016. Mobile phone growth in 2017 will be driven by increased average selling prices (ASPs) for phones in emerging Asia/Pacific and China, together with iPhone replacements and the 10th anniversary of the iPhone. The tablet market continues to decline significantly, as replacement cycles remain extended and both sales and ownership of desktop PCs and laptops are negative throughout the forecast. Through 2017, business Windows 10 upgrades should provide underlying growth, although increased component costs will see PC prices increase.
The 2017 worldwide IT services market is forecast to grow 2.3 percent in 2017, down from 3.6 percent growth in 2016. The modest changes to the IT services forecast this quarter can be characterized as adjustments to particular geographies as a result of potential changes of direction anticipated regarding U.S. policy — both foreign and domestic. The business-friendly policies of the new U.S. administration are expected to have a slightly positive impact on the U.S. implementation service market as the U.S. government is expected to significantly increase its infrastructure spending during the next few years.
Green Mountain operates two unique colo facilities in Norway, having a total potential capacity of several hundred megawatts. Though each facility has its own strengths, both embody the company’s commitment to providing secure, high-quality service in an energy efficient and sustainable manner. CEO Knut Molaug and Chief Sales Officer Petter Tømmeraas recently took time to explain to the Uptime Institute how Green Mountain views the relationship between cost, quality, and sustainability.


Tell our readers about Green Mountain.
KM: Green Mountain focuses on the high-end data center market, including banking/finance, oil and gas, and other industries requiring high availability and high quality services.
PT: IT and cloud are also very big customer segments. We think the US and European markets are the biggest for us, but we also see some Asian companies moving into Europe that are really keen on having high-quality data centers in the area.
KM: Green Mountain Data Centers operates two data centers in Norway. Data Center 1 in Stavanger began operation in 2013 and is located in a former underground NATO ammunition storage facility inside a mountain on the west coast. Data Center 2, a more traditional facility, is located in Telemark, which is in the middle of Norway.
Today DC1-Stavanger is a high security colocation data center housing 13,600 square meter facility (m2) of customer space. The infrastructure can support up to 26 megawatts of IT load today. The main data center comprises three two-story concrete buildings built inside the mountain, with power densities ranging from 2-6 kW/m2, but the facility can support up to 20 kW/m2. NATO put a lot of money into creating their facilities inside the mountain, which probably saved us 1 billion Kroners ($US 150 million).
DC2-Telemark is located in a historic region of Norway and was built on a brownfield site with a 10-MW supply initially available. The first phase is a fully operationa1 10-MW Tier lll Certified Facility, with four new buildings and up to 25 MW total capacity planned. This site could support even larger facilities if the need arises.
Green Mountain focuses a lot on being green and environmentally friendly, so we use 100% renewable energy in both data centers.
How do the unique features of the data centers affect their performance?
KM: Besides being located in a mountain, DC1 has a unique cooling system. We use the fjords for cooling year-round, which gives us 8°C (46 °F) water for cooling. The cooling solution (including cooling station, chilled water pipework and pumps) is fully duplicated, providing an N+N solution. Because there are few moving parts (circulating pumps) the solution is extremely robust and reliable. In-row cooling is installed to client specification using Hot Aisle technology.
We use only 1 kilowatt of power to produce 100 kilowatts of cooling. So the data center is extremely energy efficient. In addition, we are connected to three independent power supplies, so DC1 has extremely robust power.
DC2 probably has the most robust power supply in Europe. We have five independent hydropower plants within a few kilometers of the site, and the two closest are just a few hundred meters away.
Advertisement: Schneider Electric
How do you define high quality?
PT: High quality means Uptime Institute Tier Certification. We are not only saying we have very good data centers. We’ve gone through a lot of testing so we are able to back it up, and the Uptime Institute Tier Standard is the only standard worldwide that certifies data center infrastructure to a certain quality. We’re really strong on certifications because we don’t only want to tell our customers that we have good quality, we want to prove it. Plus we want the kinds of customers who demand proof. As a result, both our facilities are Tier III Certified.
Please talk about the factors that went into deciding to obtain Tier Certification.
KM: We have focused on high-end clients that require 100% uptime and are running high-availability solutions. Operations for this type of company generally require documented infrastructure.
The Tier III term is used a lot, but most companies can’t back it up. Having been through testing ourselves, we know that most companies that haven’t been certified don’t have a Tier III facility, no matter what they claim. When we talk to important clients, they see that as well.
What was the on-site experience like?
PT: When the Uptime Institute team was on site, we could tell that Certification was a quality process with quality people who knew what they were doing. Certification also helped us document our processes because of all the testing routines and scenarios. As a result, we know we have processes and procedures for all the thinkable and unthinkable scenarios and that would have been hard to do without this process.
Why do you call these data centers green?
KM: First of all we use only renewable energy. Of course that is easy in Norway because all the power is renewable. In addition we use very little of it, with the fjords as a cooling media. We also built the data centers using the most efficient equipment, even though we often paid more for it.
PT: Green Mountain is committed to operate in a sustainable way and this reflects in everything we do. The good thing about operating in such a way is that our customers benefit from this financially. As we bill power cost based on consumption of power, the more energy efficient we operate the smaller the bill to our customer. When we tell these companies that they can even save money going for our sustainable solutions this makes their decision easier.
More and more customers require that their new data center solutions are sustainable, but we still see that price is a key driver for most major customers. The combination of having very sustainable solutions and being very competitive on price is the best way of driving sustainability further into the mind of our customers.
All our clients reduce their carbon footprint when they move into our data centers and stop using their old and inefficient data centers.
We have a few major financial customers that have put forward very strict targets with regards to sustainability and that have found us to be the supplier that best meets these requirements.
KM: And, of course, making use of an already built facility was also part of the green strategy.
How does your cost structure help you win clients?
PT: It’s important, but it’s not the only important factor. Security and the quality we can offer are just as important, and that we can offer them with competitive pricing is very important.
Were there clients who were attracted to your green strategy?
PT: Several of them, but the decisive factor for customers is rarely only one factor. We offer a combination between a really, really competitive offering and a high quality level. We are a really, really sustainable and green solution. To be able to offer that at competitive price is quite unique because often people think they have to pay more to get a sustainable green solution.
Are any of your targeted segments more attracted to sustainability solutions?
PT: Several of the international system integrators really like the combination. They want a sustainable solution, but they want the competitive offering. When they get both, it’s a no-brainer for them.
How does your sustainability/energy efficiency program affect your reliability? Do potential clients have any concerns about this? Do any require sustainability?
PT: Our programs do not affect our reliability in any way. We have chosen only to implement solutions that do not harm our ability to deliver the quality we promise to our customers. We have never experienced one second of SLA breakage on any customer in any of our data centers. In fact, some of our most sustainable solutions, like the cooling system based on cold sea water, increase our reliability as it takes down the risk of failure considerably compared to regular cooling systems. We have not experienced any concerns about these solutions.
Has Tier Certification proven critical in any of your client’s decisions?
PT: Tier certification has proved critical in many of our client`s decision to move to Green Mountain. We see a shift in the market to require Tier certification, whereas it used to be more in the form of asking for Tier compliance, that anyone could claim without having to prove it. We think the future of quality data center providers will be to certify all their data centers.
Any customer with mission critical data should require their supplier/s to be Tier certified. At the moment this is the only way for a customer to secure that their data center is built and operated in the way it should in order to secure the quality that the customer needs.
Are there other factors that set you apart?
PT: Operational excellence. We have an operational team that excels every time. They deliver to the customers a lot more than expected every time, and we have customers that are extremely happy with their deliveries from us. I hear that from customers all the time, and that’s mainly because our operations team do a phenomenal job.
Uptime Institute testing criteria were very comprehensive and helped us develop our operational procedures to an even higher level as some of the scenarios created during the certification testing were used as a basis for new operational procedures and new tests that we now perform as part of our normal operating procedures.
Green Mountain definitely benefitted from the Tier process in a number of other ways, including training gave us useful input to improve our own management and operational procedures.
What did you do to develop this team?
KM: When we decided to focus on high-end clients, we knew that we needed high-end experience and expertise and knowledge on the ops side, so we focused on that when recruiting as well as building a culture inside the company that focused on delivering high quality the first time every time.
We recruited people with knowledge of how to operate critical environments, and we tasked them with developing those procedures and operational elements as a part of their efforts, and they have successfully done so.
PT: And the owners made the resources available so that they could spend the resources—both financial and staff-hour wise to create the quality we wanted. We also have a very good management system, so management has good knowledge of what’s happening, so if we have an issue it will be very visible.
KM: We also have high-end equipment and tools to measure and monitor everything inside the data center as well as operational tools to make sure we can handle any issue and deliver on our promises.
How the Cloud changes storage.
By John Kim, Chair, SNIA Ethernet Storage Forum.
Everyone knows cloud is growing. According to analysts, cloud and service providers consumed between 35-40% of servers in 2016 while enterprise data centers consumed 60-65%. By 2018, cloud will deploy more servers each year than enterprise.

This trend has challenged traditional storage vendors because more storage has also moved to the cloud each year, following the servers and applications. But it’s also challenging storage customers—the IT departments who buy and manage storage—as well, because they are expected to offer the same benefits as cloud storage at the same price.
The appeal of cloud storage is four-fold:
1) Price: Cloud storage might be cheaper than on-premises storage, as public cloud providers leverage economies of scale and frequently lower prices.
2) Rapid deployment: Application users can rent cloud storage capacity in a few hours, using a credit card, whereas traditional enterprise storage often requires weeks to acquire, provision and deploy.
3) Flexibility and automation: Cloud allows rapid increases or decreases in the amount and performance of storage, with no concerns about hardware management or refreshes, while changes and monitoring can be automated with scripts or management tools.
4) Cost structure: Cloud storage is billed as a monthly operating expense (OpEx) instead of an upfront capital expense (CapEx) that turns into a depreciating asset. You only pay for what you use and it’s typically easy to charge storage costs to the application or department using it.
Despite this appeal, many enterprise users are against moving all their storage to the public cloud for various reasons. Security: they might not trust their data will be sufficiently private or secure in the cloud. Regulations: government regulations might prevent them from using shared cloud infrastructure. Or from a performance standpoint, they might have locally-run applications that cannot get sufficient performance from remote cloud storage. (This can be resolved by moving applications to run in the same cloud as the storage.)
Other times, hardware is already purchased and the IT team strives to prove they can deliver on-premises storage solutions at a lower price than the public cloud. Either way, in the face of public cloud storage that is easy to consume and always falling in price, enterprise IT departments need to make storage cheaper and more flexible, either with a private cloud deployment or more efficient enterprise storage.
One way to “cloudify” the enterprise is software-defined storage (SDS). This separates the storage hardware from the software, and in some cases separates the storage control plane from the data plane. The immediate benefit is the ability to use commodity servers and drives to reduce storage hardware costs by 50%. Other benefits include increased agility and more deployment flexibility. You can choose different types and amounts of CPU, RAM, drives (spinning and/or solid-state), and networking for different projects and refresh or upgrade the hardware when you want instead of the storage vendor’s schedule. If you buy some of the fastest servers and SSDs, they can be your fast block/database storage today with one SDS solution then converted to archive/object storage three years from now using a different SDS solution.
Some SDS solutions let you choose between scale-up vs. scale-out and even hyper-converged deployments, and you can deploy different SDS products for different workloads. For example it’s easy to deploy one SDS product for fast block storage, a second one for cheap object storage, and a 3rd one for hyper-converged infrastructure. Compared to traditional arrays, SDS products are more likely to be scale-out and based on Ethernet (rather than on Fibre Channel or InfiniBand), but there are SDS products that support nearly every kind of storage architecture, access protocol, and connectivity option.
Other SDS vendors include more automation, orchestration, monitoring and charge-back/show-back (granular billing) features. These make on-premises storage seem more like public cloud storage, though it’s important to note that many enterprise storage arrays have also been adding these types of management features to make their products more cloud-like.
The benefits of SDS are appealing but not “free” because it requires integration and testing work. Achieving the 5 or 6-nines (99.999 % or 99.9999% availability) desired for enterprise storage typically requires careful qualification and testing of many aspects including server BIOS, drive firmware, RAID controllers, network cards, and of course the storage software. Enterprise storage vendors do all this in advance with rigorous qualification cycles and develop detailed plans for each model that covers support, upgrades, parts replacement, etc.
This integration work makes the storage more reliable and easier to support and service, but it takes a significant effort for an enterprise to do all this. It could easily require a few months of testing for the first rollout, followed by more months of testing every time the server model, software, drive model, or network speed changes. Cloud providers—and very large enterprises—can easily invest in hardware and software integration work then amortize the cost of their thousands of servers and customers. The larger ones customize the hardware and software while the huge Hyperscalers typically design their own hardware, software, and management tools from scratch. Enterprises need to determine if the savings of SDS are worth the cost of integrating it themselves.
Customers who want the cost savings and flexibility of SDS without the testing and integration requirements often turn to SDS appliances or bundles created by server vendors and system integrators who do all the testing and certification work. These appliances may cost more to buy and be less open to hardware choices than a “raw” SDS solution that is 100% integrated by the end user. But they still cost less and offer more frequent hardware refreshes than a traditional enterprise storage array. For these reasons the SDS appliances offers a good solution to customers who want the benefits of SDS but don’t want to do their own testing and integration work.
In the end choosing between SDS and traditional enterprise arrays usually comes down to a tradeoff between time and money. SDS lets you save money on hardware by investing a lot of time up-front for qualification and testing, while traditional arrays cost more to buy but don’t require the upfront time investment. Generally speaking, larger customers find SDS more appealing than smaller customers, but choosing a pre-integrated SDS appliance—which can include hyper-converged or hypervisor-based solutions—can make SDS accessible and affordable to customers of any size.
For more perspective on how the cloud changes storage, see the following SNIA resources on Hyperscaler Storage at www.snia.org/hyperscaler

By Steve Hone, CEO, DCA Data Centre Trade Association
Making predictions about the future is never easy, especially when it comes to technological advances or the impact these might have on the data centre sector as it attempts to keep up with demand and change.

We live in a fast moving world whose insatiable appetite for digital services is both rapidly growing and evolving at an alarming rate leaving Moore’s Law in its wake. In this month’s edition of the DCA Journal Dr Jon Summers article titled “standing on the shoulders of giants” touches on this very point. Additional contributions from Ian Bitterlin, David Hogg from ABM (formally 8 Solutions) and Laurens Van Reijen from LCL all provide additional insight into what might lie ahead and the impact this could have both positively and negatively on the data centre sector.
You would be wise not to ignore the past when peering into our crystal ball to predict what’s likely to be round the next corner. It’s also healthy to review some of the previous forecasts and predictions to see if they were proved correct or were widely over or under estimated, as Robert Kiyosaki (American Author) said “if you want to predict the future, study the past”.
There is no denying that we are using far more digital services than we ever predicted, to put this into perspective in 2012 an IDC's Digital Universe Study*1, sponsored by EMC, calculated that based on historical data collected since 2010 the worlds data usage would rise from a modest 10,000 Exabyte’s to 40,000 Exabyte’s by 2020. Well, a Cisco white paper*2 confirmed that we had reached and exceeded that forecast by January 1st 2016 in mobile data alone, so it’s anyone’s guess where we go from here! Up and on a very steep curve would be a very safe prediction! Remember the concept of ‘Smart Cities’ and the ‘Internet of Everything’ is only just warming up.
Now I’m not suggesting for one minute that this explosion in demand for digital services is something to be frowned upon or that we should try in some way to slow it down, as quite frankly any attempt to do so would be utterly futile, now the genie is out of the bottle it’s simply unstoppable.
I was still in a highchair throwing food at my parents in 1969 when an American flag was first planted on the moon; that was nearly 50 years ago, today it is reported that the same amount of computing power it took to put man on the moon can now be found in my sons Xbox 360! If you need even more statistics take a look at the info graphic below produced in 2015 – 2M Google searches and 204M emails sent every 60 seconds together with over 4300 Hours of You Tube videos uploaded every 60 minutes. These figures are staggering and remember these numbers are now two years old and were compiled before the likes of On Demand TV, Netflix and Now TV streaming services kicked off.
It is only when you take these sorts of statistics into consideration that you realise how far we have travelled in such a short amount of time and why predicting the future is proving so hard to predict! As uncomfortable as it may be, the undeniable fact is we are now completely reliant and if you take my kids as a good (or bad) example, utterly dependant on the IT based technology and online digital services we use every day without thinking twice about them.
We have also become completely intolerant when it fails us, you would have thought the world was about to end if you can’t get 3G or Wi-Fi. We expect access to these services 24x7xforever[SH1] and to make that happen an unbelievable amount of work goes on behind the scenes at an infrastructure level to ensure you are not let down.
The Data Centre Industry, represents the beating heart of any digital infrastructure and is arguably now just as important to the health of our nation as Water, Gas and Electricity - ironically the supply of which are all controlled by servers located in data centres.

If the revised statistics coming out are to be believed, the demands on the Data Centre Operators and the import role they play in supporting our digital world is probably going to increase five times quicker than originally predicted. Like the Enterprise in Star Trek, life is now moving at warp speed and we need to find the right solutions to keep up with this voyage into the unknown.
The DCA plays a vital role as the Trade Association for the Data Centre Sector in ensuring the industry remains on the ball and fit for purpose. It was created with the express purpose of both supporting existing business leaders attempting to address the many challenges faced today and to collaborate with suppliers on R&D, training and skills development programmes to ensure we meet future demand. This is a team effort and we are here to help.
Next month’s DCA Journal theme is focused on Energy Efficiency, deadline for copy is the 16th May this is followed by Education, Skill and Training with a copy deadline of 13th June. If you would like to submit articles for either one of these editions please contact info@datacentrealliance.org, full details are on the DCA website http://data-central.site-ym.com/page/DCAjournal.

By David Hogg, Managing Director, ABM Critical Solutions
With the advent of the UK’s forthcoming departure from the European Union, much has been made of the ‘uncertainty’ that threatens to dog future trading relations.

But of all the challenges the data centre industry faces over the next few years, Brexit is, perhaps surprisingly, the least of our concerns. British firms and the UK Government are hopefully leaning towards pragmatism and avoiding unnecessary complexity. It is highly likely, therefore, that the UK will adopt the same data control laws as exist in the EU currently, meaning that there will be no difference for the major US tech players in where their data is stored.
It is true to say, of course, that restrictions on the free movement of labour may drive up the cost (and reduce the availability) of labour, but this tends to impact the lower skilled ‘commodity’ roles (e.g. within the hospitality sector) and will therefore have little or no impact on data centres.
Indeed, for all of our predictions for the future, most are likely to have a positive impact on the data centre industry of tomorrow. Consolidation of data centres, for example, continues at a pace, and this will include more pan-European deals as the maturity of the market and expansion of clients continues. This in turn will add to an increased focus on achieving best practice.
Whilst there is yet to be a ‘one-size fits all’ set of standards, best practice levels have risen markedly across the UK in the past few years. Bodies such as the Data Centre Alliance have been key to promoting the need for best practice, complemented by the commercial imperatives of the co-location data sector segment looking for a differentiator in order to attract new clients. The updated European standard for data centres (EN50600 – Information Technology – data centre facilities and infrastructures) will also drive an increase in best practice adoption rates.
Leading on from this, the increasing density of IT equipment is similarly prompting closer attention on performance against best practice. As a case in point, ABM Critical Solutions recently upgraded one of its client’s data centres (the customer is a major high street retailer) following the client’s investment in new IT. The retailer is now able to generate the same IT computing power using only 25% of their previous space occupied by the ageing IT infrastructure.
Best practice is similarly enabling a focus on insurance, and driving down the cost of premiums. There is already evidence that insurance companies recognise that data centres that adopt best practice inherently contain less risk, and therefore adjust premiums directly. Allianz, for example, appears to be taking the lead in this area, and we predict that others are likely to follow once the idea fully takes hold.
From a technology perspective, ‘Edge’ data centres will become increasingly important as high-speed networks such as 5G are rolled out (5G is currently expected in 2020). We predict a real growth opportunity in this type of facility, especially where the big data centre players don’t have a presence, or there is demand from a specific market niche. The Internet of Things (IoT), Virtual Reality (VR) and 5G will lead to a massive growth in the world’s data centre volume, and a key opportunity for data centre providers and service companies alike.
We also predict a period of evolution in the way services to data centres will be delivered. There is already an increased demand for companies to provide a full complement of services based around a core expertise or skilled workforce. This is being driven, in part, by a desire by data centre operators to manage a smaller number of external suppliers, wherever possible, to reduce costs.
By way of example, ABM Critical Solutions is now using the same teams that complete its technical cleans to also undertake simple, additional tasks such as cleaning CRAC units and changing filters. AC engineers are expensive, and this allows their time on site to be more productively utilised in areas where their skills can be better deployed. In this way, service providers will be able to deliver greater value, while supporting their clients’ need for greater operational efficiency.
By Ian Bitterlin, Consulting Engineer & Visiting Professor, Leeds University
Most of us like a bit of speculation and making lists, so this month, when asked for ‘predictions’, I have decided to make a list of my top three.

The first in my list, ‘in no particular order’, concerns ASHRAE and their Thermal Guidelines for microprocessor based hardware. We, the data centre industry in Europe, are very lucky to have ASHRAE. OK, they are a purely North American based trade association that serves its members but they are the sole global source for the limits of temperature, humidity and air-quality for ICT devices and have proven themselves to be far more progressive for the environmental good than anyone could have expected. If you follow their guidelines from the first to the latest you could be saving more than 50% of your data centre power consumption since the members of TC9.9, who include all the ICT hardware OEMs, have consistently and regularly updated their Thermal Guidelines, widening the temperature/humidity window to enable drastic improvements in cooling energy. So, what is my prediction? Well it certainly is not that they will make the same improvements in the future that they have made in the past, since the latest iteration leaves server inlet temperature warmer than most ambient climates where people want to build data centres and requiring almost zero humidity control. My prediction is, in fact, that the conservative nature of our data centre users will keep the constant lag in ASHRAE adoption at a lackadaisical and slightly unhealthy five years. What I mean by that is simple – the 2011 ‘Recommended’ Guidelines are, in 2017, just about accepted by the mainstream users as ‘risk free’ whilst many users still regard the 2011 ‘Allowable’ limits as avant-garde. So, I predict that ‘no humidity control’ and inlet temperatures of 28-30°C will be mainstream by 2022….
The second prediction in my trio concerns the long-forecasted, but now clearly closer, demise of Moore’s Law. When Gordon Moore, chemical engineer and founder of Intel, wrote his Law it was clear to him that the photo-etching of transistors and circuitry into silicon wafer strata doubled in density every two years. That was soon revised by his own company to a doubling of capacity every 18 months to consider the increasing clock-speed and, more recently by Raymond Kurzweil (sometime nominated as the successor to Edison), to 15 months when considering software improvements. It lost its simple ‘transistor count per square mm’ basis long ago but Koomey’s Law took up the baton and converted the 18 months’ capacity doubling to computations per Watt. Effectively that explains why it is so beneficial to refresh your ICT hardware every 30 months (or less) and more than halve your power consumption for the same ICT load. To make a little visualisation experiment in ‘halving’ take a piece of paper of any size and fold it in half, and again, and again... You will not get to seven folds since you will have reached the physical limit.
So why have data centres been growing if Moore’s Law and its derivatives have been providing a >40% capacity compound annual growth rate (CAGR)? The explanation is simple – our insatiable hunger for IT data services (notably including social networking, search, gaming, gambling, dating and any entertainment based on HD video such as YouTube and Netflix et al) has been growing at 4% per month CAGR (near to 60% per year) for the past 15 years. The delta between Moore’s Laws’ 40-45% and the data traffic rise at 60% gives us the 15-20% growth rate in data centre power. The problem comes when Moore’s Law runs out, which it surely will with a silicon base material, as then we will have to manage the 60% traffic per year without any assistance from the technology curve. Moore’s Law probably has 5 years left without a paradigm shift away from silicon (to something like graphene) but that is unlikely to happen ‘in bulk’ within the 5-year time frame. Looking at one of the major internet exchanges in Europe shows that peak traffic is running at 5.5TB/s with reported capacity at 12TB/s – but if we consider even a slight slowing down of the annual growth rate to 50% then it will be less than 2 years before the peak traffic will be pushing the present capacity limits. I predict a couple of years of problems during the dual-event of a paradigm shift away from silicon and a sea-change in network photonics capacity.
The last of my trio of predictions concerns the reuse of waste heat from data centres and is simply stated as: By 2027 waste heat will not be ‘wasted’ from a huge array of ‘edge’ facilities and they will become close to net-zero energy consumers. From my perspective, there is a gathering ‘perfect storm’ of drivers that will converge to drive infrastructure designers to liquid based cooling:
The solution is simple and within our grasp today – liquid cooling of the heat generating components, particularly the microprocessors. With liquid immersed or encapsulated hardware and heat-exchangers pushing out 75-80°C into a local hot-water circuit with 94% efficiency the data centre will have a net power draw of just 6%. Just five cabinets (a micro-data centre by todays definition), equivalent to 80x todays ICT capacity, will be able to offer to the building 100kW of continuous hot-water. Consider embedded 100kW micro-facilities in offices, hotels, sports centres, hospitals and apartment buildings. Indeed, could this be the ‘major’ future? Could giant, remote, air-cooled facilities become obsolete? Probably not for twenty years, but then…
By Dr Jon Summers, University of Leeds
How much do you trust the weather predictions for tomorrow? If you are observant you may have noticed that such predictions have improved over time. This is in fact a direct consequence of Moore’s law, which I am sure you have heard much about, but suffice it to say it has been a self-fulfilling prophecy for successful growth of the ICT industry for nearly 50 years. Weather predictions become more accurate with faster supercomputers, which can then provide predictions in time for the broadcast weather forecast.

Talking about Moore’s law and making predictions and forecasts, it is interesting to ask the question if there are physical limits that restrict Moore’s law from continuing as it has done for many decades. Recently the academic and technical literature abounds with indications that manufacturing transistors with gate lengths of only a couple of atoms is limited due to two main reasons, namely fabrication cost and quantum effects. The former is likely to be the main limitation as indicated in the 2016 Nature News article called the chips are down for Moore’s law, which included the quote “I bet we run out of money before we run out of physics”.
In 1961, IBM employee Rolf Landauer published a paper that highlighted a relationship between energy and information that amongst other things reinforced the point that digital information is not ethereal. What the paper implied was that there was an ultimate minimum amount of energy dissipated (as heat) in a transistor (switch) at room temperature of 3 zeptoJoules (0.000000000000000000003 Joules), which is due to the erasure of information as part of the logical steps in the digital processes, which lead to the notion of the “physics of forgetting”. This minimum energy became known as the Landauer limit, but if information is never erased it would be theoretically possible to build switches that do not adhere to this limit. In fact this was discussed by a colleague of Landauer, Charles Bennett, in 1973 where it was suggested that if the computer logic was made reversible so that information could flow both ways without digital erasure, then it would be possible to compute with far less energy. This was in fact recently achieved in the laboratory using what is called an adiabatically clocked microprocessor.
The question you may be asking yourself now is how the demise of Moore’s law impacts on data centres. The answer is probably not much since the heat removal and power requirements will continue to be an issue for facility management, but it is worth trying to understand how ICT may change as we march into the next decade. Analysing the literature there are a number of interesting developments in building a replacement for Field Effect Transistors (FETs), the switch that creates the logic necessary for processing digital information. The immediate idea with today’s technology is to keep heat dissipation down but continue to increase transistor count by lower voltages, introducing three dimensional features, switching at lower speeds and making use of new materials. There are also a range of activities that are being pursued in the laboratory, namely computers that use reversible logic, superconducting switches, quantum processes, approximation and neuromorphic processes, which are not ready for the mainstream data centres. However, the issue of dark silicon, i.e. part of the “silicon chip” that cannot use power simultaneously with other parts, is likely to grow. This in effect has already happened when multicore microprocessors were introduced in 2005, but rather than having more “general purpose” processing cores they will be specific for certain functions, such as encoding, encryption, compression, etc., a development that is already occurring in the smartphone. ICT hardware is likely to become heterogeneous and application software development will then become the main focus for energy efficiency.
Our ability to make prediction based on scientific theory has only been possible with the developments of calculating machines, but predicting how ICT will develop in the future may be a question that we really need to ask the machines themselves.
“If I have seen further, it is by standing on the shoulders of giants” was the phrase that Isaac Newton used in a letter to his rival, Robert Hooke, in 1675.
LCL Survey of Belgian Companies By Laurens van Reijen, Managing Director of LCL Belgium
Belgium's listed companies have a false sense of security when it comes to data storage. 97% do not test power back-up systems and 50% plan to outsource activities. CIOs and IT managers of listed companies incorrectly assume that their corporate data is stored safely and securely. According to a survey of Belgian listed companies carried out by LCL Data Centers, they underestimate risks such as power cuts and fire, they fail to test their protective systems and they do not invest sufficiently in redundancy.

The survey of Belgian, quoted companies that LCL ordered, shows that data security is not seen as essential within IT governance, not even with quoted companies. For instance: with only one data center, in case of a disaster, you risk losing absolutely all your data. After your power shuts down, your company does too. If you really want to be safe, at least 30k’s should separate both data centers. Moreover, best practices dictate that one should separate the development environment from the production systems.
The CIOs and IT managers of 168 Belgian quoted companies took part in the survey. Of these companies, 87.5% felt they were protected from disasters such as fire or lengthy power cuts. Surprisingly, these respondents said that this was ‘because power cuts rarely happen’. The fact that they also have a disaster recovery service also added to their sense of security. Just 5% of respondents indicated that their organization was ‘reasonably protected', while 7.5% said that their organization had inadequate protection. This final group stated that in the event of a disaster it would not be possible to guarantee the continuity of the organization.
However, when asked whether their systems are also tested by switching off the electricity supply, only 3% of respondents answered yes. This means that a full 97% of respondents will effectively ‘test’ their backup systems for the first time when a disaster occurs.
“Our conclusion is that Belgian listed companies have a false sense of security,” Laurens van Reijen, LCL's Managing Director, said. “Many of the smaller listed companies, and some of the larger organizations, are not adequately equipped to deal with power cuts or other risks. They don't even know how well-protected their systems are, as they don't test their power backup systems. All organizations, and quoted companies in particular (in the context of corporate governance), should have all the protective systems they need to guarantee that the servers are dependable 24 hours a day, 7 days a week and they should actually test these systems on a regular basis.”
More than half of the listed companies store their data internally at the head office. One tenth of them rely on their own server room or a data center at another location owned by the company. A total of 44% of the respondents have a server room that is less than 5 m² in area. In this kind of set-up it is clearly impossible to include appropriate protective measures or specialized staff.
That said, most of the respondents do not have a second data center: 53%. That means, they have no backup in case of fire or theft of the servers. At the same time, half of the listed companies included in the survey have plans to outsource activities. At one third of the quoted companies that have a second data center, the second data center is located less than 25 km from the company's first data center. A major power cut is therefore likely to affect both data centers, which means the back-up plan will not be very effective.
“And yet business continuity is a must for virtually every business today,” Laurens van Reijen added. “The rise of digital technology has led to more and more business processes being digitized. Digital technology is being adopted in new, disruptive business models more than ever before, and these business models are thus dependent on the availability of the IT infrastructure. Shutting down servers in order to carry out maintenance work is no longer an option, as customers also need to be able to visit the website at night to submit orders. And as we have seen recently in Belgium at Delta Airlines, Belgocontrol and the National Register, a server breakdown can cause serious problems.”
“What are the odds that the current mentality – we all trust that all will go well - will change in the short term? Only a minority of companies interviewed said they were planning to set up a second data center. If we really want change, it will have to be directed by the Belgian stock exchange control body: FSMA. So in the best interest of our Belgian quoted companies, for the sake of their business continuity and employment - not to mention the shareholders who want return on their investment; data loss will almost certainly cause share devaluation - we call upon FSMA to issue a new guideline for quoted companies. A guideline pushing quoted companies to have a second data center, and to either thoroughly test all back-up systems, including power backup, or to confide in a party that does just that for them. It’s a pain in the lower back part, but people will not move unless they have to”, Laurens van Reijen concluded.
LCL has many years' experience and know-how in data centers and colocation. The company has three independent data centers: in Brussels East, Brussels West and Antwerp. The Belgian IDC-G member is ideally located in the center of Europe. At 4 miliseconds from Amsterdam and 5 miliseconds from London and Paris in terms of round trip latency, LCL is a vital link in IDC-G’s international data center network.
LCL has clients in a wide range of sectors. Multinationals and small and medium-sized enterprises, government bodies, internet companies and telecom operators all call upon the services of LCL. The company is ISO 27001 and Tier 3 certified. LCL also opts resolutely in favor of sustainability and is 14001 certified.
Laurens van Reijen, LCL’s CEO, is a seasoned data center professional. He was a founder and Operations Director at Eurofiber before founding data center company LCL in 2002.
For more information:
http://www.lcl.be
A key revelation to some at the first European Managed Services and Hosting
Summit in Amsterdam on 25th April was that, outside of the managed services
industry, no-one is calling it that. With a strong focus on customers and how
they engage with managed services, the event discussed how the model had become
mainstream in the last year, and was now the assumed way of working for many
industries.
Over 150 attendees from nineteen different European countries met to review the state of the market and the ways to take the industry forward. Bianca Granetto, Research Director at Gartner, set the scene with a keynote on how Digital Business redefines the Buyer-Seller relationship. In this she showed how customers are using more and more diverse IT suppliers, while still looking for a trust relationship with those suppliers, and that this process will continue in coming years. “The future managed services company will look very different from today’s,” she concluded.
This was reinforced by TOPdesk’s CEO Wolter Smit who, in a discussion on the new services model, said that MSPs were actually in the driving seat as the larger IT companies could not reach their level of specialisation. Dave Sobel, SolarWinds MSP’s partner community director also pointed out that many of the existing IT services companies were decades old and, with management due for replacement, new thinking among the providers was inevitable.
The top trends affecting the market were outlined by several speakers, with IoT, user experience and smart machines within the list – and IoT will be profitable for suppliers, according to Dave Sobel, with the MSPs top of the list as beneficiaries.
IT Europa’s editor John Garratt highlighted the differences between the US and European managed services markets, with the US more focused on financial returns. Price was apparently less important to European customers, who were more focused on gaining control of their IT resources. Autotask’s Matthe Smit said that price indeed mattered less than a good supportive relationship. But, he said, less than half of providers actually measured customer satisfaction, and this would have to change.
If anyone was in any doubt of the impact of the new model, Robinder Koura, RingCentral’s European channel head, showed how cloud-based communications had pushed Avaya into bankruptcy, and the new force was cloud-based and more flexible.
Security was never going to be far from the discussions, and Datto’s Business Development Director Chris Tate shook up the meeting with some of the latest statistics on ransomware. MSPs are in the firing line in the event of an attack like this, and he gave some sound advice on responses and precautionary measures. Local MSP Xcellent Automatisering’s MD Mark Schoonderbeek also revealed how he launched new services using a four-layered security offering: “First we'll search for vendors through our existing partnerships. When we find a good product - we'll R&D it from a technical standpoint. If the product meets our quality standards we will roll out within our own production environment. Then we'll go to one of our best customers in a very early stage, we tell them it's a test-phase and we'll implement the service for free, but in return we want the customers feedback (what went well, what went not so well and what is the perceived value of the service that is offered). Then we'll make a cost calculation and ask the customer what the service is worth. We'll put a price on the product and deliver it fixed price. Next step is to sell the product to all existing customers.”

The impact of the new EU General Data Protection Regulation (GDPR) was starting, but there were many unknowns, not least how various regulators across Europe would react to the provisions, warned legal expert and partner at Fieldfisher, Renzo Marchini, while the opportunities and general strong confidence in the European IT market were illustrated by Peter van den Berg, European General Manager for the Global Technology Distribution Council (GTDC).
Finally, a well-received analysis of what was going on in the tech M&A sector showed attendees where to make their fortunes and how to do so quickly. Perhaps unsurprisingly the key to creating value within a company turns out to be generating highly repeatable revenues – which is what managed services is all about.
For further information on the European Managed Services and Hosting Summit visit www.mshsummit.com/amsterdam.
Many of the issues debated during the European Managed Services event will be further discussed at the UK Managed Services and Hosting Summit, which will be staged in London in September – www.mshsummit.com
The server industry is becoming more and more automated. Robots are helping to deploy servers and clouds that are moving away from large racks of blades and hardware managed by teams of administrators to machines that are deployed and managed with minimal human interaction. The way information is delivered as well as improvements in automation technologies are fundamentally changing the central role of IT.
By Mark Baker, OpenStack Product Manager, Canonical.

Data centres are becoming smaller, distributed across many environments, and workloads are becoming more consolidated. CIOs realize there are less dependencies on traditional servers and costly infrastructure; however, hardware is not going anywhere. For IT executives, servers will be part of a bigger solution that creates new efficiencies that will make cloud environments quicker and more affordable to deploy.
CIOs wishing to run either cloud on premises (private cloud) or as a hybrid with public cloud, need to master both bare metal servers and networking. This has caused a major transition in the data centre. Big Software, IoT (Internet of Things), and Big Data are changing how operators must architect, deploy, and manage servers and networks. The traditional Enterprise scale-up models of delivering monolithic software on a limited number of big machines are being replaced by scale-out solutions that are deployed across many environments on many servers. This shift has forced data centre operators to look for alternative methods of operation that can deliver huge scale while reducing costs.
As the pendulum swings, scale-out represents a major shift in how data centres are deployed today. This approach presents administrators with a more agile and flexible way to drive value to cloud deployments while reducing overhead and operational costs. Scale-out is driven by a new era of software (web, Hadoop, Mongodb, ELK, NoSQL, etc.) that enables organisations to take advantage of hardware efficiencies whilst leveraging existing or new infrastructure to automate and scale machines and cloud-based workloads across distributed, heterogeneous environments.
For CIOs, one of the most often overlooked components to scale-out are the tools and techniques for leveraging bare metal servers within the environment. What happens in the next 3-5 years will determine how end-to-end solutions are architected for the next several decades. OpenStack has provided an alternative to public cloud. Containers have brought new efficiencies and functionality over traditional Virtual Machine (VM) models, and service modelling brings new flexibility and agility to both enterprises and service providers, while leveraging existing hardware infrastructure investments to deliver application functionality more effectively.
Because each software application has different server demands and resource utilization, many IT Organizations tend to over-build to compensate for peak-load, or they will over-provision VMs to ensure enough capacity years out. The next generation of hardware uses automated server provisioning to ensure today’s IT Pros no longer have to perform capacity planning five-years out.
With the right provisioning tools, they can develop strategies for creating differently configured hardware and cloud archetypes to cover all classes of applications within their current environment and existing IT investments. Effectively making it possible for administrators to make the most of their hardware by having the ability to re-provision systems for the needs of the data centre. For example, a server used for transcoding video 20-minutes ago is now a Kubernetes worker node, later a Hadoop Mapreduce node, and tomorrow something else entirely.
These next generation solutions bring new automation and deployment tools, efficiencies, and methods for deploying distributed systems in the cloud. The IT industry is at a pivotal period, transitioning from traditional scale-up models of the past to scale-out architecture of the future where solutions are delivered on disparate clouds, servers, and environments simultaneously. CIOs need to have the flexibility of not ripping and replacing their entire infrastructure to take advantage of the opportunities the cloud offers. This is why new architectures and business models are emerging that will streamline the relationship between servers, software, and the cloud.
Advertisement: DT Manchester

Employees are demanding a different experience and require new ways of working. At the centre of this shift is the mobile and IoT device; but European businesses are failing to place this at the heart of their technology strategies. The compelling evidence speaks for itself: Gartner predicts a $2.5m spend per minute on IoT and one million new IoT devices sold every hour by 2021.
By Nassar Hussain, Managing Director, Europe, Middle East & Africa at SOTI.

So what is the main barrier holding businesses back from getting a competitive edge from mobility?
Mobility is an essential enabler of digital transformation. Yet, when it comes to Enterprise Mobility Management (EMM) and Unified Endpoint Management (UEM), there is a lack of strategic planning among European businesses. In terms of implementing and utilising EMM solutions much of the enterprise focus has centred around how to manage and secure mobile devices at a basic level.
Recent research discovered 61 per cent of European businesses are making little to no progress towards mobility objectives, with a further 26 per cent yet to realise any value from mobility. This lack of recognition and appropriate response to changing user demands will impact an organisation’s productivity, dynamism, experience and competitiveness.
Furthermore, half of European businesses are failing to impose basic mobile device management to administer their smartphones, tablets and laptops. This raises concerns about the ability to combine people, processes and technology in an EMM solution.
To address this, businesses must ensure they not only have a vision, but the strategy and fundamentals in place to meet their employees’ expectations. This is a major cause for concern if enterprises are to create competitive advantages from mobility as it gives employees freedom, while also encouraging mobile working.
A lack of vision is very much with Europe business leaders, who are failing to understand the strategic benefits of managing their mobile strategies and investment. The leaders in question have cited budgetary, security and privacy concerns as the main obstacle to their organisation realising value from EMM and UEM.
However, with better understanding of mobility at a top level, a business can implement the correct mobility strategy to combat these concerns and ensure its data and information is safe no matter what type of device and its location.
Traditionally IT departments worked in silos. However with the rise in BYOD, they are now working with a varied range of devices not owned by the organisation. Therefore to see a mobility strategy put in place across an organisation, business leaders must have the vision to allow IT departments to take the lead.
IT departments must be involved at a closer level, supporting employees’ broad use of technology. In parallel, they must extricate themselves from old corporate silos and help to design systems with mobility at their core. In the fast pace of today’s digital revolution, business leaders should engage IT managers and mobility specialists to take charge, making sense of the chaos.Starting with a clear vision will not inform the strategy, but allow organisations to benefit from business critical mobility, enhancing their customer experience and place mobility at the heart of their digital transformation plans.
DCS kicks of a series on fibre connectivity and optical networks by talking with Panduit’s President and CEO, Tom Donovan.

Panduit was born from innovation. In 1955 we launched our first product, Panduct Wiring Duct, a new invention that uniquely organised control panel wiring and allowed new wires to be added quickly and neatly. Since that time Panduit has introduced thousands of problem solving new products and remained committed to providing innovative electrical and network infrastructure solutions.
Today, customers look to Panduit as a trusted advisor who works with them to address their most critical business challenges within their Data Centre, Enterprise, and Industrial environments. Our proven reputation for quality and technology leadership coupled with a robust ecosystem of partners across the world enables Panduit to deliver comprehensive solutions that unify the physical infrastructure to help our customers achieve operational and financial goals.
Our mission is to leverage the full portfolio and capabilities of Panduit, and our partner ecosystem, in order to support our customers in the design, development and deployment of infrastructure solutions that enable the achievement of superior results.
1955 Jack Caveney invents wiring duct, 1955
1959 First patent awarded for PanDuct®
1960 LOK-Strap cable tie is developed
1970 – 1979 Period led by international expansion
1980 Formal Research and Development facility established
1989 Network Connectivity Group established
1989 Panduit is the network infrastructure provider for the largest fibre communication network (150 mB ATM) in an enterprise (Sprint Campus in Kansas, City, MO USA)
1990 – 1999 Network Connectivity Group expands with Data Communications suite of products: copper and fibre connectivity, patch panels, racks, cabinets and cable management products
1990 Six Sigma implemented
1994 Fibre connectors and accessories launched to address longer length and high data transmission rates in the data centre
1999 Telecommunications Racks are introduced
1999 Cisco Systems selects Panduit as their infrastructure provider of choice and collaborates in designing new infrastructure solutions. Cisco is now a key Global Alliance Partner for Panduit.
2005 OptiCam® fibre optic connector is introduced
2006 High Speed Data Transport solutions is introduced to deliver reliable 10Gb/s performance
2007 EMC partnership established
2007 Fibre laboratory capabilities are UL certified
2008 Launches intelligent infrastructure management solutions
2009 Panduit, Cisco and Intel join forces to promote 10G over Ethernet
2009 Panduit partners with VCE to develop optimised cloud solutions
2011 Signature Core™ Fibre introduced
2012 Introduces new Energy Efficient Cabinet system for the Data Centre
2012 Panduit and Rockwell Automation expand longstanding relationship and form a strategic alliance to drive Ethernet to the factory floor.
2012 & 2013 For two years in a row, Panduit is awarded InformationWeek’s 500 Masters of Technology
2013 PanMPO™ connector is introduced to provide easy migration from 10G to 40G in the data centre
2013 Panduit introduces SmartZone™ Solutions for physical infrastructure management
2014 Panduit acquires SynapSense® to provide wireless monitoring and cooling control solutions for data centres
Advertisement: Server Technology
Both HDOT and Alternating Phase are available through Server Technology's “Build Your Own PDU” configurator. Build Your Own PDU takes a Switched, Smart or Metered 42-outlet High Density Outlet Technology (HDOT) PDU and allows you to build an HDOT PDU your way in Four Simple Steps. Choose a configuration. Download a spec sheet and request a quote in four simple steps.
This is an overview of our Data Centre products and services portfolio:
At Panduit, we find that our customers don’t just have to worry about designing, procuring and implementing the right IT and facilities. They must also focus more than ever on controlling costs and conserving energy usage. The bottom line is they’re struggling to deploy a data center—whether that means reconfiguring their existing one or creating a new one—that addresses every need.
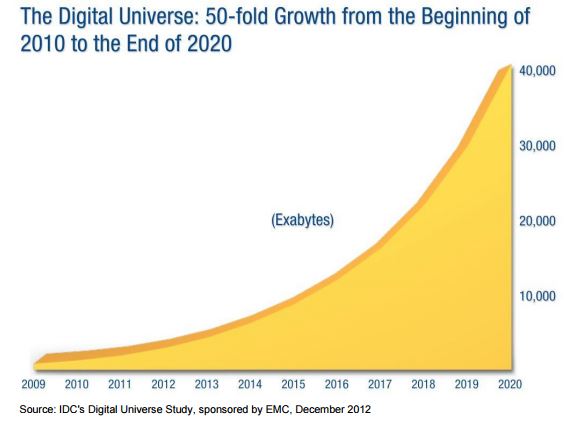
Converged Infrastructure: Panduit’s Converged Infrastructure solution offers unique value to the market by delivering a comprehensive and reliable infrastructure framework that bridges the gap between the traditional Facility and IT stacks to ensure a seamless physical to logical convergence. Given the enormous expense of operating data centres, organisations must design and deploy an architecture that is built to meet future needs, requiring scalability to meet changing business demands and optimisation of IT investments – delivering value throughout the data centre lifecycle. Panduit accelerates the design cycle, simplifies implementation, optimises operations and improves total cost of ownership.
Fibre Solution Set: Panduit High Density Fibre Solutions help customers maximize and transform their data centre space to accommodate NextGen technologies and evolve within IoT and beyond to IoE. Creating the most agile, scalable, high performance system in the market. As a cohesive set, HD Flex™ 2.0, PanMPO™ and Signature Core™ solve in tandem: network performance, system reliability, energy efficiencies, seamless integration, space and savings, installation and uptime, data transfer speed and migration to future demands.
Cooling Optimisation and Thermal Solutions: The one-size-fits-all approach of just maintaining a constant temperature to keep data centres cool is no longer a relevant solution with energy prices rising and capacity concerns become more prevalent. Panduit’s energy efficient cabinets and SynapSense® cooling optimisation solution allow higher data center set points and reduce cooling system energy consumption by up to 40%. From controlling small leaks, maintaining hot/cold air separation and deploying real-time monitoring and mapping of the data centre environment, ensures optimal energy efficiency and cooling energy savings across the operations.
The major pain points that Panduit has encountered at the data centres we visit are downtime and saving money via energy savings. Especially in colocation facilities, these two issues are top of mind and flow directly to the business’ bottom line. By far, the largest amount of operations budgets spent in the data centre are around cooling. Energy efficiency being the greatest opportunity for cost savings, Panduit often leads with SynapSense® Cooling Optimisation solutions. SynapSense is a turn-key wireless monitoring and cooling control solution that uses intelligent software, leading edge wireless nodes, and professional services to gain real-time visibility into current data centre operating conditions.
Frequently our customers tell us that they want to save energy, and they site many reasons for that – being green, good corporate citizen, operations leadership in their industry. However, it boils down to saving money without putting your data centre at risk. That being the case, one can’t manage what one doesn’t measure. With Panduit’s SynapSense product the customer participates in our simple process: Assess, Instrument, Optimise, and Control. This product enables the customer to address various pain points across energy savings and risk management.
Customers have more choice and more demands placed upon them than ever before. These choices span desires to retain or expand their on-premise data centre foot print with a traditional, converged or hyper converged design; To move to a Hybird cloud deployment to providing flexibility for dynamic IT loads; Finally to move to the hyperscale public cloud to reduce capital investment. We can help navigate these choices and ensure our customers are able to meet their business objectives with a scalable, stable and efficient physical infrastructure for all these design options.
Virtualisation has been reliably deployed in the data centre for several years now and has migrated across the various platforms (compute, network and storage). Panduit has provided infrastructure solutions that allow customers to avoid shortened refresh cycles and retain their layer one investment for longer periods of time so they can better migrate their applications and maintain high performance levels for future applications. In regards to SDN, which has become another stable and beneficial data centre technology, Panduit offers a compelling solution that naturally complements the software side of SDN deployments. Specifically, the Panduit offering helps enable SDN solutions such as Cisco’s Application Centric Infrastructure or ACI.
Via our long standing relationship with Cisco, Panduit has created best practice reference documents and product solutions that enable customers to confidentially deploy their SDN architectures. This approach is different to some common SDN methodologies because this approach takes into consideration not just the software and management tools to architect applications, but it also includes the hardware and physical infrastructure that really provide an optimised operating environment since all of the necessary elements are designed, implemented and orchestrated comprehensively.
Panduit’s SmartZone™ DCIM software product enables our customers to better manage their data centre infrastructure. Panduit uses a consultative approach to help the customer select the modules of the SmartZone solution that are right for them. We do not require the customer to purchase the whole system. We often see that customers are at different levels of readiness in their ability to take advantage of a DCIM system.
We divide the system into modules: asset, connectivity, cabinet access, power, and environmental. Many customers are prepared to implement only one of two of these modules, and return later to implement others. Our professional services team and certified partners work with the customer to determine which modules relieve the greatest pain points for the customer.
The SmartZone DCIM system combined with our other Panduit products lead to solutions for customers that not only help them save money, but enable them to better manage their data centres. For example, SmartZone DCIM connectivity combined with active PViQ fibre/copper patch panels helps customers manage their physical network without deploying someone to inventory capacity or troubleshoot changes. The SmartZone system notifies the user of any changes to or issues with physical connections on their network. With SmartZone asset management, this extends all the way to the IT equipment level, and enables moves, adds, and changes to be tracked automatically.
There is an increasing focus on the architecture of the network and that is due to the increase speed of the network. When the speed of the network increases, for example from 10G Ethernet to 50G Ethernet, the distance that one can span with the links is reduced. Additionally, one needs to consider the number of connectors in the link the faster the speed of the network. One needs to consider what the impact of these faster network speeds will have on their network architecture today, in order to have the architecture support several generations.
Interoperability and speed of deployment are part and parcel to successful data centre deployment. When physical infrastructure components are brought together from numerous manufacturers, elements such as long lead time components and system inconsistency can quickly extend the time needed for live system functionality. Provision of a preconfigured solution mitigates this potential obstacle by assuring that elements ranging from base enclosures to intelligent monitoring systems arrive complete and are 100% tested prior to deployment.
Security and access control is another challenge that aligns well with integrated infrastructure. By taking that same preconfigured model and utilising HID card or keypad access control as part of the solution, traditionally less secure colocation deployments are immediately protected right out of the box.
The mobility movement is certainly having an impact on enterprise networks. As an example, faster Wi-Fi access points require faster links to those wireless access points (WAP) from the telecom closet. This is driving the development of 2.5GBASE-T and 5GNASE-T which can be deployed over existing Cat 5e cabling infrastructure. Using 10GBASE-T links to support WAPs would require using CAT6A, which most existing enterprises have not deployed. The trend with new enterprise deployments is to deploy cabling that can accommodate the needs of faster WAPs.
The impact that Big Data and IoT is having on networks, both in the enterprise and data centres, is essentially the same impact that the mobility movement is making. However, the difference with IoT is that data is being generated at the edge of the network. This is pushing the requirement for higher bandwidth out to the edge to accommodate IoT. Aggregating all of this data from IoT devices then drives up the need for faster networks in the data centre.
The new breed of applications, from our perspective, have no impact on the design of the data centre. Big Data, IoT and wireless is having a greater impact on data centre design.
We think that the average data centre manager is aware of the expectations, but may not be confident in their ability to meet them. For example, most average data centres are moving from 1G Ethernet to 10G. They have not had the experience with some of the issues and problems that occurs when moving to faster speeds and more complex architectures. That is why Panduit has been very proactive with educating our customers on what they could expect when they do move into the future.
Panduit offers a wide array of tools for data centre managers to help them work through all the options and avoid pitfalls. These range from whitepapers, case studies, best practices, etc. We also offer products that help data centre managers such as preconfigured cabinets. Finally, we have a services team that consults with data centre managers to help them.
The Impact the immense growth in data transmission required for Big Data and IoT (internet of things/everything) is having on the enterprise and data centres is unquestionable.
The rate of change in terms of data centre networks evolution is unprecedented – reflecting a rapidly changing world, where disruptive technologies and exponential data centre traffic growth is undeniably the new normal.
In terms of high speed data transport, as more data aggregates on each network circuit that circuit becomes more mission critical. Increasing value of data to its users is intensifying pressure on the data centre to reduce costly unplanned downtime and better prepare migration strategies to higher bandwidth infrastructure to cope with exponential growth.
Annual global IP traffic has passed a zettabyte (ZB) (1000 exabytes (EB)) and will reach 2.3 ZB per year by 2020*2. The number of internet connected devices will be more than 200 billion by 2020*1, whilst IP traffic in Western Europe will reach 28 EB per month by 2020*2. The most telling metric is machine to machine (East to West) data traffic – simply put, data transactions contained within the DC itself - forecast for growth at 44% CAGR 2015-2020*2
The cost of unplanned outages has massively increased over the past few years, the maximum cost per outage has more than doubled over six years from $1 million to $2.4 million*3, see Bar Chart 1. And 91-percent of data centres will experience unplanned down time during their first two years of operation*4. With 59-percent of downtime attributed to the physical layer*5, operators and owners can mitigate the risk of expensive outages through the right physical layer infrastructure choice.
Four fundamental aspects for data centre owners and operators to consider within this ever-increasing volume of data are:
1. improving up-time
2. beating the ‘bandwidth bottleneck’ - with a strong network migration strategy
3. reducing network latency
4. improving operational efficiency
Prepare for change or prepare to fail…
Evolution has taught us that those more able and agile towards adapting to ‘change’ will succeed - the data centre is no exception.
As DC networks evolve and become more mission critical there has never been a better time to invest in a quality physical layer solution that is reliable, scaleable and migratable.
A solution that promotes performance certainty, headroom and uptime and one that can be easily adapted to address the next generation of high speed data transport needs holds the key to improving ROI and beating bandwidth bottlenecks.
*1 Intel Corp forecast 200bN connected devises. Unclear if this was also a Cisco forecast/quote/reference. I will let you (Simon) check and confirm information source.
*2 – Cisco Visual Network Index 2015-2020 – Executive Summary
*3 – Ponemon Institute – Cost of Data Centre Outages Jan 2016
*4 - Ponemon Institute
*5 - Gartner
Following on from the success of the 400G at Light Speed event, DCS is delighted that Panduit is contributing a series of articles focusing on the technologies and ideas that are being developed to address the challenges facing the digital data centre.
Data Centre Infrastructure Management (DCIM) has been around for years, helping data centre managers navigate the challenges presented by everything from physical infrastructure to network management. With its monitoring ability, DCIM plays a critical role in providing a detailed overview of data centre activity including the varying loads being processed, which can greatly improve efficiency and bring costs down. The inherent value of DCIM is easily demonstrated by the fact that some of the world’s biggest companies, such as eBay, Facebook and Google, have turned to the solution to manage data.
By Richard Whomes, director sales engineering, Rocket Software.

However, the difficulties within data centre management are evolving, thanks to the rapid growth of disruptive technologies. Looking back just a few years, mobile solutions and the cloud were bringing a long list of changes to the data centre environment. Fast forward to today, and IoT and cognitive technology are the key drivers of reasons behind increased complexity for network managers.
The rise of IT modernisation has seen workloads shifting and growing at an alarming rate, while on the other hand, some data centres have completely disappeared overnight. Thanks to this, capacity planning is harder than ever before. So, it’s no surprise that businesses are struggling to justify spending, should the workload fall, or never expand to begin with.
What’s more, as technology evolution outpaces the ability of data centres to process requests, it is inevitable that they will bear the brunt of complexity overload, before this is passed on to SaaS providers. To put things into perspective, as a result of increasing complexity, traditional data centre traffic is predicted to reach 1.3 zettabytes (ZB) per year by 2020. And considering that a zettabyte represents one trillion gigabytes, this is an enormous increase from the relatively small 827 exabytes (EB) of traffic in 2015. But it is cloud data centre traffic that will see the most significant growth, set to reach 14.1ZB in 2020, up from 3.9ZB per year in 2015.
There are many factors driving companies to adopt DCIM, but a notable one is the growth of disruptive technology such as Internet of Things (IoT). Gartner has estimated that by 2020, there will be more than 20.4 billion devices connected to the internet. And figures show that global data generated by IoT will reach a staggering 600ZB by 2020. This growth means that capacity planning is particularly important, to ensure that there is enough storage space for data, and, more importantly, that this space is used efficiently.
Advertisement: Sudlows
Considering the vast amount of data just on the horizon, we need to be asking whether the traditional approach to DCIM is still adequate in the long term. Without the ability to leverage analytics and other business solutions, DCIM as we know it is likely to be written out of the picture by application developers, who will aim to design more modern solutions to collect and analyse data. So, what solutions should data centre managers be taking advantage of, to broaden the capacity of their DCIM?
On a real-world level and taking into consideration rapid technology modernisation, experts have advocated for DCIM to be used mainly for physical infrastructure-related issues, such as power and cooling. It can then be combined with additional tools including software-defined networking (SDN) and network virtualisation to extend the capabilities of DCIM to deal with increasing demand.
These two solutions add a level of sophistication to traditional DCIM, drastically improving the speed and flexibility of the network. Network virtualisation in particular is incredibly valuable, as it can help support dashboard tools, which makes data monitoring a far more straightforward task. By consolidating KPIs and data across multiple vendors and technologies, dashboards offer an easily-comprehendible and visually-engaging way of understanding the numbers at the heart of data centre activity. Essentially, integrating these solutions into DCIM is key to streamlining data centre operations and managing networks more efficiently.
In order to modernise data centre operations, businesses need to recognise the current skills gap within data centre management. And this is where tools such as SDN and network virtualisation also come into their own. By implementing solutions such as these, the success of the data centres won’t rely on a pool of talent that is being quickly depleted as people retire and move out of the workforce. Rather, you will be able to employ a new breed of data centre manager, and ensure that they can handle the complexity of the technology.
Ultimately, DCIM as we know it still provides a well-functioning solution to some of the issues facing data centre managers. And we can’t overlook the inherent value in DCIM, as it goes a long way in covering the bulk of the processes. But, as complexity increases, it is wise to supplement this with more specific and high-performing programs. As the need to modernise IT systems grows, data centres must evolve to keep pace with new demands.
As the demand to do more with less continues, data centres are under increasing pressure to deliver new levels of efficiency, while reducing operating expenses. Here Cindy Monstream at Legrand talks through each of the core areas, ripe for cost savings.

1. Performance
With the rapid movement toward virtualisation and cloud infrastructure, downtime reduction is a necessity.
a. Structured cabling – consider your options. There are systems, for example, that can substantially cut insertion losses for fibre systems and offer copper cabling systems with the performance headroom to provide for future growth.
b. Improve cable management to support appropriate bend radius and cable connections to remove performance inhibitors.
2. Time – as data centre staff numbers shrink, efficiency is a must. Consider:
a. Flexibility and scalability – select systems that provide flexibility for multiple cabling types and scalability.
b. Device changes and the resultant cabling modifications for moves and additions are constantly changing, so specify systems that are quick to install.
c. Improve cable infrastructure – simplify how cables are routed and managed to save installation time. Consider vertical managers to support more cable without adding new management.
d. Flexible cable infrastructure – will support all cabling approaches without having to change cable management.
3. Space – focus on increasing rack density and “going vertical” offers new ways to gain space. Potential options include:
a. Taller racks – a 9’ rack will have up to 38% more RU space than a comparable 7’ rack.
b. Support for improved Air Flow and Cooling – Rack-based cooling, passive cooling and other methods can increase rack density with more active devices within the same space.
c. Cabling solutions for higher port density – increasing port density, opens up space for active devices e.g. Ortronics, can support 144LC connectors in one rack unit, reducing the number of RU’s dedicated to connections.
d. Fibre and copper combined in one rack unit – mixed-media offerings save space, thanks to a single rack unit.
e. Smaller outside diameter cable – Smaller OD cable can increase space available in the cable runs or in a raised floor.
Advertisement: Vertiv
4. Experience – improving customer-vendor experience is often overlooked in terms of efficiencies, yet one of the biggest frustrations, is when products don’t work together as expected.
a. Simplify relationships – demand a single point of contact - helping coordinate solutions, delivery schedules and work with contractors.
b. Project-specific expertise – every project has unique demands, but experience pays. Tapping into your partners knowledge and experience, can help shorten a project timeline and enabling greater efficiencies.
5. Sustainability – energy use and the topic of sustainability are hot topics and a focal point for reducing costs. Look out for products with:
a. Minimal hazardous materials
b. Feature increased recycled materials and waste reduction
c. Next generation air flow and cooling improvements
Connected infrastructure goes beyond power and cooling and through the five core elements outline for data centres and operations it demonstrates that a more holistic approach can deliver a more effective data centre that is also more efficient.
The upcoming General Data Protection Regulation (GDPR) is about to have a large impact on businesses across Europe. To ensure compliance by the time GDPR enters into application in May 2018, organisations need to take action now to ensure they are sufficiently capturing, integrating, certifying, monitoring and of course, protecting their data.
By Patrick Booth, VP UK & Ireland, Talend.

There is a lot to do. Many organisations across both public and private sectors have not yet given due consideration to the problem, let alone taken proactive action to prepare themselves for full compliance with the new ruling, which was introduced by the European Commission on May 4, 2016.
They will not be able to put this problem on the backburner for much longer, however. A failure to comply with the new regulations could be costly. Breaches of some provisions could lead to data watchdogs levying fines of up to €20 million or 4% of global annual turnover for the preceding financial year, whichever is the greater.
When GDPR comes into force, businesses will need to track and trace each and every piece of potentially sensitive data, and determine how it is processed across their entire information supply chain - from their CRM and HR systems to their Hadoop data lakes. This same careful data management will be required to comply with “privacy by design” principles, which means that each new digital service that makes use of personal data must take the protection of such data into consideration, for example, by considering data anonymization or pseudonymization.
Compliance with GDPR is also dependent on the organisation’s data agility, as it mandates to communicate transparently with data subjects on their personal data and grants them rights for data access, as well as rectification and erasure at any time, free of charge. This can be a particular challenge for large, complex or geographically dispersed organisations where data is often siloed, duplicated and distributed across many different sites and likely stored in multiple places. Any delays to answer requests can be a major problem for businesses if they don’t have a clear process and widely accessible system to compile the requested information.
Businesses today are faced with the proliferation of data together with multiple new cloud and digital applications. It is therefore becoming increasingly difficult for IT departments to take total ownership of the protection of personal data without engaging their counterparts in HR, Sales, Marketing, and other customer-centric business units.
However, for most companies, GDPR mandates the appointment of a Data Protection Officer (DPO). Their role is to educate, advise internally on the obligations under the regulation, monitor compliance, and cooperate with the supervisory authority. But, more importantly, their main challenge in the data-driven era where data is everywhere is to delegate the organization’s accountability for privacy across all the activities and stakeholders that access and process that sensitive data.
Advertisement: Flash Forward

So what’s the solution to this complex challenge? Ensuring proper data protection, data integrity, security and ultimate compliance requires businesses to first establish a collaborative approach for delegating accountability and responsibilities.
Data governance should be a collective responsibility. Based on a data-centric shared platform, IT needs to turn everyone in the company who has to deal with sensitive customer or employee data into an agent for better data protection.
There’s also the opportunity to set up an information hub where all the data that needs to be monitored can be captured, discovered, documented, harmonised, reconciled and shared. And this is the concept of the data lake that many companies are implementing today to get a 360-degree views of their data subjects, their customers, employees. The beauty of the approach is that regardless of whether the lake is housed on premises, or in the cloud, it provides a centralised repository that the business can use to store significantly more information at a lower cost, and a collective resource that employees can work on together to extract insight from.
That’s where modern data integration platforms can be key in helping achieve GDPR compliance. They allow organisations to quickly gather all the data that relates to a subject – a customer, an employee – in the data lake. Then, they draw the relationships between the disparate data points into a reconciled view where data is harmonised and can be tracked and traced across the information supply chain. And finally, a data governance layer can be established on top, facilitating new data policies required by regulations such as GDPR, such as anonymising sensitive data whenever needed, and, through data stewardship, delegating accountability to the people that know the data best.
Good data stewardship and governance are not just about keeping in line with the strict letter of the regulatory law, though, it’s also about unleashing access to trustworthy data across individual business units, thereby helping to drive productivity and ultimately competitive advantage. What we’ve described in the above might sound familiar: it is all about building the 360-degree view that many consider as the ‘nirvana’ of our digital age. The bad news, now with GDPR, is that it is no longer a ‘nirvana’ but rather a mandate that’s worth a fine that, once the regulation goes live, could equate to as much as 4% of your global revenue if you fail to comply. The good news is that platforms have evolved to empower your organisation to meet this goal while helping you to reap all the benefits of this new goldmine: namely, the precious data that you can leverage to transform your customer experiences and your business.
High-quality connectors ensure optimum transmission rates and network uptime in all areas, from WAN to metropolitan area and campus networks, to backbone networks and subscriber connections. As a result of the ongoing increase in data rates, transmission quality is becoming increasingly sensitive to dirty connections – even with multimode. Only clean connections achieve the values guaranteed by standards and manufacturers. Studies show that up to 85% of local faults are caused by connectors that have not been cleaned carefully or even cleaned at all.
By Daniel Eigenmann, Product Manager, R&M.

Fibre optic system performance depends heavily on the condition of the interfaces. Dirt particles, grease, dust and other unwanted elements could negatively impact transmission characteristics. They can even destroy a fibre optic connection in some circumstances. If a connector is plugged in without first being inspected, it could well be too late. Particles are immediately pressed into the fibre and this causes irreversible damage.
By not observing certain practices, you not only risk signal and performance loss. Under certain circumstances, the connection may even be destroyed completely.
Cables, adapters, and above all the fibres themselves, must be handled gently, kept clean and tested before mating. This even applies to new products that are taken directly out of their packaging. New connectors should also be tested and, if necessary, cleaned. However, cleaning is only required after inspection. Although the manufacturer will conduct a test using an interferometer and high resolution microscope, it is still necessary to perform a visual inspection on site using a microscope or another suitable tool. Here, the surfaces of the fibre ends are checked for scratches, cavities, adhesive residue and dirt.
Most connectors arrive at their place of deployment in the pristine state in which they left the production facility. In such cases, the installer can actually only make the quality worse by cleaning the connector. A microscope or a similar test tool should always be available when carrying out installation work. Always check first, then clean if necessary, then connect. If cleaning is required, both sides of a connection including the guide sleeve should be cleaned, as recommended in IEC 62627-01/TR. This applies to devices and test cables, as well as for network components. This is the best guarantee for a reliable optical network.
Two areas in which dirt can have performance-degrading effects are return loss and insertion loss. Any kind of impurity can lead to significant impairment of the return loss. Dirt, along with damage such as scratches and cavities, are among the main causes of problems. Dirt can result in a change in the refractive index, a pathway to air and therefore backscattering of the modes or photons. The effects of dirt on the insertion loss are slightly less serious. Water residue, dust or other residues are typically pushed outward by the convex shape of the connector end face. It is therefore unlikely that larger particles will remain in the core area. At the edges, they can only deflect a small portion of the light. Even slightly deflected modes can still be coupled into the next fibre. Dirty surfaces have an impact on the insertion loss, although the level of contamination needs to be fairly high before measurable changes in loss occur.
• Award Winning
• Easy seamless integration
• Monitor and plan your growth and capacity
• Reports and alerts that you need
• Most Affordable Power Management Solution on the market
• Get Ahead with SPM
DCS talks to Lance Ruetimann, VP (answers in red), and Simon Brady, Chairman EMEA Liason Work Group (answers in blue), both of The Green Grid (TGG), about the organisation’s successes to date and plans for the future.


For those not familiar with the Green Grid, please can you provide some background on the organisation – when and why it was formed, what are its aims and objectives?
The Green Grid’s mission is to drive accountable, effective and resource efficient end-to-end ICT ecosystems, which is achieved by establishing a suite of relevant metrics, driving an understanding of risk, proactively engaging governments to influence effective policy, and providing frameworks for organisations to realise operational efficiency and maturity across the ICT infrastructure.
The association was formed a decade ago, in 2007. The initiator was the 2007 United States Environmental Protection Agency (EPA), Report to Congress on Server and Data Center Efficiency. Based on estimations from Prof. Jonathan Koomey on electricity consumption by servers and associated infrastructure, EPA projected a 100 per cent increase between 2006 and 2011 in the US, with additional impacts on the environment such as CO2 emissions. Against this backdrop, a number of reputable companies (vendors and data centre owners/operators) decided to do something and formed The Green Grid. Its first KPI was the widely spread, Power Usage Effectiveness (PUE) metric, which today is part of the EN 50600 standard series as well as ISO/IEC level (30134 Part 2).
And what have been some of the key milestones achieved by the Green Grid to date?
This is best explained by breaking it into organisational and deliverable content.
Already in 2007 after the founding of the association, interest grew in other parts of the world. In late 2007, the TGG EMEA region was formed and the efforts began to take the mission to the European market. In early 2008, TGG Japan was formed and since then has been very active and successful. In 2011, The Green Grid began with activities in China leading to the formation of TGG China in 2015. In addition, we have an active group in Singapore and are looking for people to help us expand further.Moving on to specifics, can you talk us through the recent Greenpeace report that commented on sustainable data centres and drew a response from the Green Grid?
The Greenpeace Report is a good indicator that while there are definite movements towards a more sustainable data centre industry, many organisations have sought individual goals, rather than working together to share best practice and find the best ways to a sustainable future.
Google, Facebook and Apple are constantly pushing the barriers of green innovation, while also working closely with energy suppliers to help achieve sustainable company targets. Their ability to advocate such measures is beginning to influence the rest of the sector, yet more transparency will aid collaboration to tackle rising carbon emissions in the industry, and speed up change.
The need for data centre providers and end users to collaborate to ensure our use of data is sustainable has never been greater. We are providing the space for this to happen and are developing a range of tools to make sure that our growing dependency on technology is sustainable.
And the Green Grid is also promoting innovative approaches to using renewable energy power in the data centre – especially focusing on smaller data centre providers?
Similar to the case above, the hyperscalers have set a precedent for their use of renewable energies – and while more are growing alert to alternative energy sources to power their IT infrastructure, renewable sources may not be completely attainable for all data centres. This is due to a lack of direct contact with renewable suppliers, unpredictable weather conditions and limited budgets.
Rather than seeing renewable energy as a primary source of power, some facilities may find it more beneficial to use renewable energy as a secondary source to help power some data centre operations, while helping keeping costs to a minimum, and most importantly, limiting the amount of fossil fuels used throughout the industry.
Governments could serve as a support arm for facilitating the adoption of renewable energy by bringing together energy suppliers with data centre operators. Combining this with fiscal incentives would help guarantee that organisations incorporate some form of renewable energy and in the process, push for long-term contracts with energy suppliers. In turn, this would have the potential to create a portfolio of partners and help lead to more progressive goals towards a sustainable and green data centre industry.
On top of this, we have also recently published the Open Standard for Data Centre Availability (OSDA) approach, which will add to the search for solutions towards implementing renewables, but more on this later.
The Green Grid has a range of projects on the go, can you give us an update on these, starting with Liquid Cooling?
With the release of the Liquid Cooling Technology Update (White Paper #70), we have provided tools and best practices that enable data centre owners/operators to realise efficiency gains at the IT and infrastructure levels from the implementation of liquid cooling technologies. This white paper is intended to serve somewhat as foundation for the team to publish their findings and recommendations on this form of cooling.
On a broader scale, this area of cooling will continue to develop. With it, we will see new opportunities for The Green Grid’s Liquid Cooling standing working group to develop and publish its knowledge achievements on how to apply this technology.
Moving on to the Open Standard for data centre availability tool?
The Open Standard for Data Centre Availability (OSDA) aims to modernise data centre availability classification and rating, similar to how PUE modernised data centre power usage. This new approach, which will be applicable to new designs and retrofits, will allow data centre designers and operators to increase resource efficiency and sustainability by integrating renewable energy sources into the overall availability considerations.
The OSDA working group has published the initial whitepaper, which is available to The Green Grid members to explain the objectives and scope. Currently, the group is working on the details on how to assess availability within the OSDA framework. The first draft of the evaluation tool looks good and the authors have taken great care in making a complex topic simple in the implementation.
The main message though is that without some means of quantifying and validating the data centre availability, incorporating renewable energy sources into power concepts will be consistently challenged. OSDA is showing promising signs of becoming the answer that data centre operators are looking for.
And hunting zombie servers?
By popular definition, a server is considered a “zombie” or comatose when it is unused, disused, or unproductively used, and it is no coincidence that zombie servers and neglected servers are often one and the same. These servers are among the most vulnerable to being compromised because they receive precious little IT department attention – it is both the cause and result of their zombie condition.
The search for Zombie servers has already started, and the whitepaper to be published later this year will support our members to tackle this issue. In retrospect, it is a highly unfortunate fact that there is so much IT infrastructure consuming energy without having actually serving its purpose – and then add on top the energy needed to cool this IT infrastructure.
And then there’s DC automation using DCIM?
One could argue that in the search for a common understanding on the what, why and how of DCIM, data centre operators are looking for a more impartial and independent response. The Green Grid is stepping up to help the industry.
The DCIM working group has taken on the topic at a holistic level. This means that they are producing a working concept, on which the whole industry can build and evolve. In doing so we will provide a framework to define where DCIM begins and where it ends. A working draft is well underway and we can expect finalisation and publication this year.Finally, Redfish API utilisation?
Again, there is a need to interconnect. Redfish is a REST API specification and related schema published by the Distributed Management Task Force (DMTF) that defines a modern, secure, scalable management API for server, storage, network, and data centre equipment. Such an approach would enable further developments to make data centres “smart”. The Redfish API group has just begun its work and there is still much to be done, so keep monitoring what this group will bring.
The Green Grid recently hosted a webcast on ‘Applying ICT capacity and utilisation metrics to improve data centre efficiency’ – how did this go?
We regularly organise roundtables throughout the year on various relevant issues impacting the IT industry, where we draw on a number of participants from across the world. For this roundtable, the feedback from the participants was very positive.
And Green Grid webcast planned on tackling water consumption in the data centre?
Water consumption in the data centre is often overlooked and we’re trying to bring more awareness surrounding this. Water coming from cooling towers must be treated with harmful chemicals, which then is directed down into the sewage and responsible for polluting the environment. We have a resource efficiency issue with the amount of water needed to cool, and a sustainability issue with the chemical treatment of the water. If we then add to the financial aspects associated with water, chemicals and maintenance, we’re seeing the big issue this poses.
To eradicate this problem, we’ve called on a data centre operator in Amsterdam to share their innovative solution, which has the potential to increase its momentum with other data centres in Europe. The approach has reduced water usage by 90 per cent, made the use of chemicals redundant, reduced maintenance efforts, and reduce the financial elements with this. The previous operating expenditures for the affected portion have seen a reduction by 60 per cent.
Are there any other data centre/ICT areas where the Green Grid is working, or looking to start a project – TGG Performance Indicator, for example?
The Performance Indicator has been completed and published including the tool and rationale. In recent weeks, we have heard from a number of data centre operators detailing that they are implementing the PI with success.
If there is one area that needs more work, then it is the link between the DC and the executive management. We need to bring the two worlds together. Additionally, we need to create awareness of what is already published and available. A substantial number of existing sites are still operating under “business as usual”, meaning that sustainability and resource efficiency remains to be implemented in their sites.
Therefore, we will be giving considerable attention this year towards bringing the pieces together.
Advertisement: Geist
Moving on to current industry issues, do you think that the Green Grid has a role to pay in the current trend towards Cloud Computing?
Absolutely! Cloud computing by its very nature are just larger data centres, many hyperscale (=>5MW), that provide processing and storage. The Green Grid metrics and tools are just as relevant for the cloud data centre as any other.
And the Software-Defined Data Centre?
Again definitely. A software-defined data centre is still a data centre as software will always need hardware to run on. Software defined facilities will still consume vast amounts of power and we are well placed to offer tools and metrics to ensure these facilities are as energy efficient as possible.
And the Big Data/IoT trend?
This is going to mean more data centres processing and storing data. The more we move towards IoT and big data the more reliance we are going to have on the facilities that process and store this data. Given that many IoT applications could be critical (car safety and healthcare) we could see a move back towards more mission critical (therefore less efficient) facilities. It’s important for us to promote energy efficiency best practice in this area.
The Green Grid membership is a mixture of data centre and ICT vendors – how do you ensure balancing their differing demands?
By engaging with both as often as possible. It’s in the best interest for vendors and DC operators to be as efficient with the energy consumed as an industry. Many of our metrics, like PUE and PUEv2 are applicable and relevant for both.
And do you see the increasing convergence of these two disciplines – DC facilities and ICT?
Sadly, not as quickly as we would like to in some cases. We still see a separation between IT and facilities in certain areas. The large hyperscale players (Google, Facebook, Amazon etc) are leading the way but many legacy and enterprise facilities (still the vast majority of DC estates) don’t work as well together as they should.
And does the Green Grid have a role to play in encouraging this convergence?
Very much so. We target both IT and facilities users to get the energy efficiency message across.
The ICT/data centre industry’s environmental track record manages to stay out of the limelight but do you worry that, at some stage, the media will start focusing their attention on their relatively high carbon footprint?
Yes, and not just the media, governments too. This is one of the reasons that it’s important to highlight our work. We are, every day, promoting and trying to educate the industry to improve. Are we perfect as an industry? No. Do we have a long way to go? No.
I think as an industry we are actually good at being as efficient as possible with the energy we use. Almost every data centre is either a revenue generator or a cost of a service. The energy cost is the largest on-going OPEX item so reducing that cost is at the forefront of everyone’s mind most of the time.
Do you think that there is a genuine will in the data centre/ICT industry to address green issues – or is it always a case of efficiency and costs first, with green benefits being a nice spinoff?
No one wants a hospital system or a major bank offline as a result of trying too hard to save energy. The cost of energy is increasing so using less makes business sense, as well as being “green”. Business need must come first though. Critical services and applications must be highly available before anything else.
It’s important in our understanding that energy efficiency and high availability are mutually exclusive. Availability must come first. It’s a tough balancing act, but it’s possible to do both.
Where does the Green Grid stand when it comes to the glass half empty/half full in terms of power availability moving into the future?
We are not seeing that many bottle necks currently apart from the usual central city locations. In fact, the reduction in certain types of facilities moving to the cloud has seen a reduction of power usages in some places.
The hyperscale operators are building where there is good power availability rather than going to more power constrained locations. Many are building off grid by using CHP solutions. It’s something we are monitoring but I don’t see the glass being empty any time soon.
The Green Grid is a global organisation – do you see any major geographical differences in the ICT/data centre industry approach to environmental issues – or not?
Every region has its own differences, but in general the approach to best practice and the need to use energy more efficiently is the same. The cost of energy is generally increasing everywhere – as well we all know that resource efficiency and environmental sustainability is a world-wide issue where all of us need to be consciously active.
Wind the clock forward five years, and what would you like to think that the Green Grid has achieved in that time?
The creation and adoption of a wider range of tools for the industry to use. We want to see our industry grow as it is, but doing so responsibly. A lot can happen in five years though. With technology moving at such a rapid pace there could be a paradigm shift in that time. Quantum compute, renewable energy, energy storage etc.
And how do you think attitudes to green issues in the ICT/data centre industry will have changed in those five years?
Unless we will have created a clean way of generating an abundance of energy then the focus will very much still be there. Hence, ignorance will be a poorly chosen. In fact, the number of people being aware of the impact on the environment is today considerably larger than it ever was. But we are also going to see is that being green and competitive will no longer be contradicting objectives.
A recent survey of 400 IT decision makers in organizations across the United States and Europe found that on average, 40 percent of all organizations' applications are deployed in the cloud, a number expected to grow by an additional 30 percent in the next 12 months. The growth of cloud computing in the enterprise is taking IT environments to new levels, where efficiency and cost benefits battle with challenges like privacy, security, and the data protection and availability of critical business assets.
By Tom Grave, SVP Marketing, CTERA.

As enterprises increase their reliance on cloud-based file services, it’s critical that they are keenly aware of the basics around security in the cloud. As we have learned over the last few years, don’t discriminate; one of the largest beaches in 2016 included Britain’s Three Mobile, when hackers successfully accessed its customer upgrade database simply using an employee login. This occurred on the heels of another major breach at TalkTalk where the details of more than 150,000 customers were stolen including the bank account details of around 15,000. The result was 95,000 lost subscribers, which cost the company £60million.
Prioritizing ownership of security within cloud activities must be be of utmost importance as C-level, IT managers, CISO’s and security professionals plan their cloud security strategies. Below are recommendations for ensuring cloud security. While these might seem a bit overwhelming, the alternative is even scarier -- risky cloud use that leaves organizations vulnerable. With thorough planning and a new perspective on cloud security, your company’s data will be more secure in 2017.
Advertisement: ColoCONNECT Days

Almost three out of five CIOs we speak with today tell us that technology providers often seem to be pushing Software Defined Networks (SDN) simply to sell hardware – and they just don’t need more hardware.
Peter Konings, Director of Enterprise Networks and Managed Services at Verizon

Let’s be clear: SDN isn’t a box. It is about enabling better performance and efficiency in the software layer. What all CIOs today really need to understand is how to leverage SDN to improve performance and reinvent their business processes in order to be able to compete more effectively.
While cost reduction will usually be the most compelling benefit for any technology adoption, the more persuasive argument for SDN adoption is that the technology can drive enterprise-wide change. Successful proof-of-concepts are frequently moving to production quicker than planned. Greater network agility and reduced cost allows a CIO to package services differently, which can reduce time to market and reduce opportunity costs. This gives the CIO greater business agility, which in turn offers more freedom to innovate, catalyzing an upward innovation spiral.
In the simplest of terms, no network means no cloud and no applications. Nonetheless, cloud adoption has risen without the wonderful benefits of SDN technology. How does that work?
If you look at network models used across most organizations, they haven’t really evolved much since the 90s. But how much has technology has changed? We’ve applied Moore’s Law to networking in moving from 10 Mbps to 10 Gbps and beyond, but we have only just started seeing changes in network architecture. As our perimeter dissolves, more applications are being hosted in the cloud, and with application hosting environments sitting outside the traditional internal network, a different, more optimal model is required.
Now, imagine an application that can detect demand and move compute instances and network loads to different server farms based on where the user is located. Bear with me here: SDN helps to fulfil this by decoupling control from the hardware plane. Rather than requiring hardware, physical equipment or significant human intervention to provision for expansion or contraction based on usage needs, SDN enables a CIO to scale up and down as needed via software controls. As a result, SDN is an enabling technology that allows an organization to drive far greater efficiency and agility from their network and virtualization environments. It also allows for significantly improved management, increased visibility and better automation. No more over-provisioning!
The same application could change network routes based on revenue projections or data sensitivity within the application.
For example, an eCommerce application currently serving users within the U.S. market plans to expand internationally; however, due to data privacy laws, data must remain locally stored. Rather than running lengthy infrastructure build-outs and network implementation projects, the application could move instances to a cloud provider in that respective territory, provisioning VPN back to the company’s headquarter and detect and encrypt personal data to meet privacy rules. With SDN and automation this could be done in just minutes – or seconds.
As legacy network architectures change with the adoption of new technologies such as SDN, so too do security architectures. SDN is enabling the world to move towards the era of embedded security.
Advertisement: Vertiv
Embedded security isn’t a new concept. A few years ago, the Jericho Forum was started with a view to developing a way of stopping network attacks against application infrastructure. The drive for setting up the forum was the rise in cyber-attacks such as phishing, SQL and distributed denial of service (DDoS) attacks that give attackers access to internal systems.
One such technology is the Software Defined Perimeter (SDP). This technology re-architects the perimeter to provide advanced identity and application-specific access control. It is a far superior security model, and is particularly valuable for companies active in cloud-based environments.
Here’s another benefit: having to manage and secure increasing amounts of data means that full network visibility and transparency are essential. The network automation and orchestration gained via SDN and SDP delivers more data that can itself deliver valuable, timely alerts, enabling IT executives to perform security analytics. When you consider that 25% of all data breaches remain undiscovered by the victim for weeks (or even months), the importance of this becomes obvious
So armed with all this information, how do you even start to think about transforming your network?
Understand and document what you want to achieve through the implementation of SDN, so that you can measure its success. Remember that while the reporting the financial success of any implementation is important, IT teams may lack the skills to effectively describe business benefits. Don’t let the hardware/software vendors lead your discussions, as they may have vested interests. Look at open systems and tools where available and understand how these can be supported and used across the organization.
You also need to consider SDN’s impact on your support structure. Explore how process and workflow can be improved, as this can often lead to a change in the support structure for operational teams. Instead of having compute, network and application teams, it is now quite common for organisations to move to an application-centric support model that includes staff with skills in server and network technologies. Tooling may need aligning to this support structure, and it’s important to identify these systems up front. A good configuration management database (CMDB) really can help to understand enterprise applications, the uses and value of these and the critical components in their delivery.
In conclusion, SDN really is here to stay. CIO evangelists tell us that SDN enables them to design their network to flex on demand to meet the demands of their business, rather than design to peak - with the added layer of security a bonus. Perhaps most compelling is the fact that, with these new technologies, the time of deployment can in some cases be reduced from 500 days to as few as 65. And this is why very early adopters have tended to include companies undergoing mergers and acquisitions, as SDN allows them to integrate acquisitions on-board faster.
Fast, secure, flexible. What’s not to like?
How future-ready cabling solutions help data centres optimise their space
The demand for data shows no sign of slowing down. First, there was the increasing adoption of cloud computing, the growing demand for virtualisation, big data, and video. Now, the internet of things, virtual/augmented reality, and artificial intelligence are driving an industry-wide push towards faster transmission speeds and a need for sophisticated fibre-management solutions.
By Anthony Robinson RCDD CDCDP™ CNIDP®, Corning.

Fortunately, today’s networking technology enables data centre operators and facility owners to meet this challenge on a number of fronts, establishing a future-ready infrastructure capable of handling even greater network strains. Optimising data centre density is the industry best practice for adding capacity, as it’s far more efficient and less costly than expanding the physical boundaries of the data centre.
There are many solutions that provide high-density capabilities, but the biggest challenge is “theoretical” vs. “usable” density. Data centre operators need to evaluate which solutions enable them to provide easily manageable, highly flexible, and scalable solutions that not only permit continuous moves, additions, and changes but also maintain the integrity of live circuits to reduce risk and maintain internal service-level agreements.
Corning has worked with data centre customers for more than 20 years to overcome these challenges and to deliver a range of solutions that provide the highest level of flexibility. Corning has been at the forefront of density solutions since the launch of our EDGE™ solutions back in 2009. Thanks to our recent EDGE8™ solution with universal wiring, we now enable port disaggregation of higher-speed 40/100G switch circuits to support 10/25G server connections. Port breakout modules deployed in the main distribution area can significantly reduce the number of line cards in the device for savings in both density and power requirements.
Corning’s project with managed service provider Kinetic IT to maximise capacity in Telehouse North’s colocation centre offers a great example of the transformative power of a high-density infrastructure solution and how the installation should be approached for maximum efficiencies.
Telehouse North is Europe’s first purpose-built, carrier-neutral colocation data centre. One of four Telehouse data centres located at the Docklands campus in London, it is the primary home of the London Internet Exchange and one of the most connected data centres in Europe. It provides end-to-end information and communications technology solutions including managed services, integrated communications services, virtualisation services, content management, system security services, and disaster recovery services.
With tens of thousands of HDOT (High Density Outlet Technology) PDUs already installed, Server Technology has now completed its most popular and innovative product line ever with the addition of the HDOT Switched POPS® (Per Outlet Power Sensing) PDU. Now with device level monitoring, the most uniquely valuable rack PDU on the market provides the #1 solution for density, capacity planning, and remote power management for the modern data center.
Telehouse’s cabling infrastructure required an update in order to maximise capacity in its 9,717 square metre, highly secure colocation centre, which consists of 32 suites over multiple floors. A central hub room required a new cable management solution that would provide flexible and future-ready, intrabuilding connectivity to each of the five floors and customer colocation suites. Most importantly, the new central hub had to be operational within three months.
From an infrastructure perspective, the design had to meet a number of objectives. These ranged from the pressures of a strict project timeline and budget to resilience – namely supporting 100 percent diverse routing of connectivity to customer suites for high availability 24 hours a day, seven days a week.
Fundamental to the project was ensuring a high-density infrastructure solution by maximising port capacity within a small footprint and ensuring the infrastructure was flexible and scalable to changing business requirements and future growth.
Corning proposed an infrastructure solution designed around its Centrix™ system. The innovative design of the Centrix system enables an ultra-high-density deployment in a compact footprint and provides a scalable fibre management solution for cross-connect applications in the data centre’s central hub. With superior patch cable management and an innovative fibre routing system, the Centrix system is a cross-functional solution that meets the requirements of multiple application spaces.
The Centrix system supports up to 4,320 LC connector ports per 2200 mm frame with a 900 mm wide, 300 mm deep footprint. The highest density of 17,280 optical fibre ports in one square metre is possible in a quad configuration.
The frame design provides optimised routing paths for patch cables, reducing the risk of entanglement, while the operations staff can install or remove a single patch cable in less than two minutes regardless of the cable route. To further simplify deployment and stock levels, the Centrix frame requires a single-length patch cable of just 4 m to connect any port(s) within the frame.
The foundation of the Centrix system is a modular cassette that can be tailored in a variety of ways to provide flexibility and functionality without sacrificing density. Each cassette contains fibre guides as well as a splice section, and it can hold 24 or 36 LC connector adapters. Telehouse personnel can easily access the fibre ports as the cassettes have a sliding mechanism with a drop-down handle.
Corning indoor/outdoor cables, typically 96 fibre, were terminated on cassettes within the Centrix frame and installed along diverse routes to each of the customer suites. These cables utilise low-loss Corning® SMF-28® Ultra fibre, which provides a solid foundation of high performance for the newly upgraded infrastructure. SMF-28 Ultra fibre offers industry-leading specifications for attenuation and macrobend loss. Low attenuation enables extended reach of network connectivity between locations, while 33 percent better macrobend performance than the G.657.A1 standard helps improve existing duct utilisation and the support of smaller enclosures.
The project involved the initial termination of over 16,000 fibre ports on the Centrix frame as well as the installation of cables to each suite. Completed in March 2016, within a 12-week timeframe, the installed system has the capacity to allow for expansion of up to 130,000 ports with the use of additional cabinets.
Telehouse is now able to provide fast and flexible provisioning of connectivity to suites and respond quickly to the changing business needs of its business customers. This installation will create the basis for future project stages, including the infrastructure in a new Telehouse building scheduled for completion later in the year.
Network operators must realise that today’s network is a living and growing entity. What seems like more than enough capacity will most likely not be sufficient for tomorrow. A successful, well-built network must be based on a strong fibre-cable management system that is flexible, simple, and provides superior density.
Luke Brown, VP & GM of EMEA, India & LatAm at Digital Guardian argues that IT teams must shift their focus away from securing the perimeter and towards securing data. After all, if you have no visibility into your data, you can’t be sure that it hasn’t already left the building.

You might think the hackers are winning. In the news, we read about a new data breach almost every day, despite security budget increases and constant developments in cybersecurity. The amount of successful breaches has led to a number of companies taking a pessimistic view towards cybersecurity solutions and protocols. They feel like investments don’t offer their organisations complete protection. Their attitude to cybercrime becomes a ‘we’ll deal with it when it happens’ approach, rather than taking the necessary, proactive measures.
The fact is that companies - and even consumers - are creating, storing and utilising data at an unprecedented rate, and it’s this data that cybercriminals are keen to get their hands on. What’s more, experts predict the attack opportunities for hackers will blossom further once the Internet of Things proliferates and makes valuable data accessible from an ever-widening selection of entry points.
Clearly, it’s time for a rethink. Yet a study by 451 research shows that companies continue to allocate just 1% of their total security technology spend to data protection measures. And they’re paying a heavy price for focusing solely on network and device security alone.
Until now organisations have largely adopted a perimeter-based security strategy that’s failed to keep pace with evolving attack approaches.
In 2010 companies spent nearly half of their security technology investment (44%) on network security. In the same year, 761 major data breaches were recorded, compromising 3.8 million records. Physical tampering, spyware and data-exporting malware were the top three attack methods utilised, yet little spend was dedicated to protecting the very data that serves as the target for so many attacks.
In 2011 the use of stolen credentials emerged as the top mode of attack, with companies like Sony PlayStation and Steam falling victim to cybercriminals. A total of 855 major data breaches were recorded, compromising 174 million records – a major uptick on 2010 statistics – yet companies continued to invest 39% of their security technology spend on network security. Despite the massive increase in attacks through the use of stolen credentials, companies continued to invest just 1% in data protection.
During 2012 backdoor exploitation materialised as the hot new threat on the block. In response to the growing cyber threat companies upped their total spend on network security to 43%, with more than a fifth (21%) of budgets going to database security, 13% to endpoint security/anti-virus, 8% to identity management – but once again just 1% was dedicated to data protection.
By 2014, stolen credentials, RAM-scraping malware and spyware had become the most popular modes of attack employed by cybercriminals. Sony experienced yet another major breach and the overall number of data breaches experienced by companies increased dramatically. Overall there were 2,122 major recorded breaches, compromising 700 million records, yet once again companies failed to shift their security spend accordingly.
In a repeat performance of previous years, network security technology investments continued to take the lion’s share of security spending at 38%, with 16% going on application security, another 16% on database security, and 13% to identity management. Contrast this with data protection, which yet again represented the lowest spending category at just 1% of total IT security technology spend.
2016 saw some of the biggest data breaches on record. Last year’s mega breaches included Yahoo, Snapchat, Adult Friend Finder and San Francisco’s public rail system.
Add to this the growing threat of state sponsored hacktivism, and a worrying picture begins to emerge. The last 12 months has seen more than its fair share of highly targeted, state sponsored cyber attacks, with China and Russia two of the major perpetrators, amongst others. It’s widely believed that the US election was targeted by Russian hackers, for example.
But while attacks are growing in sophistication, many individuals and organisations are also encountering old tactics being used in more creative ways. In particular, social engineering attacks like spear phishing have become more targeted and resourceful, relying on crafty cyber sleuthing and other tricks to make their efforts even more effective. Thanks to the prevalence of social media, an attacker can look up everything they need to know about a person and their interests, craft an email specially tailored to that person, and email something directly to them, which increases the chances of that person clicking the malicious link.
With the Internet of Things here to stay and the growing availability of new mobile payment instruments such as Apple Pay, the possibilities for attack are undoubtedly set to increase. Today’s technology is advancing apace as new ways to leverage cloud applications and mobile devices come into play. The only factor that hasn’t changed is that sensitive data is vulnerable and needs to be secured with data protection technologies and policies that follow a corporation’s sensitive data while it’s in use, in transit and at rest.
Put simply, walls can no longer protect our data; it’s not confined to the network anymore. It’s a big move, but organisations need to reverse their traditional cybersecurity strategies. They need to focus on data protection and data strategies rather than wasting resources securing the network perimeter and attempting to find and stop threats from breaking through firewalls. With this evolution, organisations will find that their data is much better protected.

There are several approaches to calculating PUE (Power Usage Effectiveness) for one’s data centre, and the most appropriate method may depend on the reason for wanting a PUE rating in the first place.
By Wendy Torell, Senior Research Analyst, Schneider Electric’s Data Center Science Center.

PUE is a popular and widely accepted metric for the energy efficiency of the physical infrastructure systems that support the IT loads of a data centre. Defined as the ratio of total energy expended by a facility to the energy consumed only by the IT systems, PUE helps data centre managers to assess and to demonstrate how efficiently they are managing their facility in terms of energy consumption.
One may want to calculate a PUE figure because of an internal requirement in pursuit of a business-wide Green initiative. Or one may be required to meet a certain level of efficiency in terms of PUE because it is mandated by a government agency. But in the final analysis, an accurate PUE figure can help you to reduce costs by organising your cooling effort in such a way as to minimise energy bills.
One approach to calculating PUE is with estimation based on a model. There are a number of readily available tools which allow one to input assumptions about capacity, IT load and power and cooling architectures from which a PUE figure can be calculated. This is the lowest cost and quickest means of achieving a calculation but it is also can be the least accurate since the assumptions made in the model may or may not align with the actual data centre.
Calculating a figure using a model can be useful at the design stage of a data centre, or when planning an upgrade. As an aid towards managing the operational efficiency of a facility in practice it is inferior to other methods.
Another approach to calculating PUE is to take a single “point-in-time” measurement, in which data from meters embedded in equipment such as a UPS (uninterruptible power supply) or PDUs (power distribution units) are supplemented by data from temporary meters brought on site to take measurements elsewhere in the system to calculate a single value of PUE.
This approach entails a moderate cost outlay and can give an accurate calculation for PUE at a particular moment. It can be useful to benchmark the progress of a facility towards achieving better efficiencies, and may suffice to satisfy the mandatory requirements of an internal or regulatory initiative to optimise PUE. However, it takes no account of variations over time in climatic or load conditions, either of which can have a significant effect on the cooling requirement of a data centre and by implication on the energy outlay and the efficiency of its operations.
Advertisement: Geist
To take full account of such variations, continuous metering is required. This is the most expensive option because it requires planning at the initial stages, the installation of additional metering throughout a data centre and the adoption of an appropriate management-software system to aggregate and analyse all the data acquired. However it gives the most accurate picture of the energy consumption of a data centre and enables the most reliable calculation of PUE.
The main power drain on a data centre, apart from the IT itself, is the cooling infrastructure necessary to maintain optimum operating temperatures. It follows that minimising the energy expended on cooling is the top priority for any attempt to improve PUE.
To calculate PUE it is important to take accurate measurements of electric and thermal performance throughout the facility. The Green Grid defines four levels of PUE reporting which vary in terms of accuracy, cost, and metering complexity. Levels 1 to 3 are concerned with continuous monitoring with 1 being the most basic, requiring metering only at the UPS level to measure IT equipment energy and at the utility input to measure overall facility energy. The minimum required frequency for measurements is one month.
Level 2 is the intermediate stage which requires measurements to be taken daily at a minimum. Here again, measurement at the utility input is sufficient to calculate overall energy consumption but measurements of how much energy the IT equipment is consuming must be taken at the output of PDUs.
Both of these cases allow data to be gathered relatively cheaply. It is common for UPS systems, PDUs and remote power panels (RPPs) to have embedded meters which can perform the necessary measurements and so there is no additional metering needed.
The greater accuracy provided by Level 2 methodology is necessary if non IT loads are being powered from the UPS. If the UPS is only powering IT systems then its embedded meter reading can be assumed to be a close approximation to the power consumed by IT equipment only and so Level 1 is sufficient for an accurate calculation of PUE. If however units such as air handlers are also being driven by the UPS then this will result in an inaccurate PUE calculation. Therefore the Level 2 approach of taking readings at the PDU level is necessary to split out the power measurements for IT equipment only.
At the most advanced Level 3, measurement intervals are reduced to 15 minutes and power metering is more complex still. To measure energy consumed by IT equipment alone, metered rack PDUs are placed in every rack and their readings summed together.
If a data centre is part of a mixed-use facility, simple measurement of the power at the utility input is insufficient for an accurate PUE calculation because some systems are shared like chillers and generators. Calculation instead is much more granular with measurements taken at a variety of locations to determine what percentage of the power from those systems is devoted to the data centre facility.
Data centres change over time both in terms of load and layout and so does the electrical infrastructure that supports them. It is therefore necessary to have up to date documentation describing the circuits in the facility, what equipment they serve and how they are to be assigned to accurate calculation of PUE. Tracing the circuits is an essential prelude to installing the metering necessary for acquiring accurate data.
The decision on where to place the additional meters will depend on the electrical and mechanical architecture of the building. The number of meters should be minimised for cost reasons, but nevertheless accuracy must be maintained so some additional outlay is inevitable. This is especially important in a shared facility where it is essential to isolate non data centre loads from those of the data centre itself.
In the simplest case, a standalone data centre, measuring the total facility power is straightforward: a meter at the service entrance is enough to get the necessary information of total facility energy. In the majority of cases, however, this is insufficient because one may need to gather more data at subsystem level for the purpose of making improvements or the facility may share infrastructure such as chillers with operations other than the data centre.
In cases where the majority of the electrical load is data-centre related it makes sense to meter the input to the main switchboard panel and subtract out the power requirements of any other offices or business units not related to the data centre. In situations where a minority of the electrical load goes to the data centre it makes sense to meter only the breakers that feed the data centre equipment and sum them together to get a figure for the overall electrical load.
To aggregate the data from all meters and to calculate PUE on a regular basis requires the use of a good Data Centre Infrastructure Management (DCIM) system. Once deployed in support of appropriately positioned metering points, DCIM can provide an accurate continuous reporting of PUE especially as it varies over time with changing IT load, cooling equipment and weather.
Continuous monitoring clearly costs more in terms of metering units, planning and design effort and ongoing measurement and management of data centre operations. For the most accurate picture however, and to afford the best possible data in support of efficiency optimisation, it provides the most reliable means of achieving and verifying an optimal PUE.
Schneider Electric’s white paper 204, Continuous Metering and Monitoring of PUE in Data Centers, provides more details on steps and considerations to deploying a PUE measurement and monitoring system.
However, there is something of a mystique surrounding these different data center components, as many people don’t realize just how they’re used and why. In this pod of the “Too Proud To Ask” series, we’re going to be demystifying this very important aspect of data center storage. You’ll learn:•What are buffers, caches, and queues, and why you should care about the differences?
•What’s the difference between a read cache and a write cache?
•What does “queue depth” mean?
•What’s a buffer, a ring buffer, and host memory buffer, and why does it matter?
•What happens when things go wrong?
These are just some of the topics we’ll be covering, and while it won’t be exhaustive look at buffers, caches and queues, you can be sure that you’ll get insight into this very important, and yet often overlooked, part of storage design.
Recorded Feb 14 2017 64 mins
Presented by: John Kim & Rob Davis, Mellanox, Mark Rogov, Dell EMC, Dave Minturn, Intel, Alex McDonald, NetApp

Converged Infrastructure (CI), Hyperconverged Infrastructure (HCI) along with Cluster or Cloud In Box (CIB) are popular trend topics that have gained both industry and customer adoption. As part of data infrastructures, CI, CIB and HCI enable simplified deployment of resources (servers, storage, I/O networking, hardware, software) across different environments.
However, what do these approaches mean for a hyperconverged storage environment? What are the key concerns and considerations related specifically to storage? Most importantly, how do you know that you’re asking the right questions in order to get to the right answers?
Find out in this live SNIA-ESF webcast where expert Greg Schulz, founder and analyst of Server StorageIO, will move beyond the hype to discuss:
· What are the storage considerations for CI, CIB and HCI
· Fast applications and fast servers need fast server storage I/O
· Networking and server storage I/O considerations
· How to avoid aggravation-causing aggregation (bottlenecks)
· Aggregated vs. disaggregated vs. hybrid converged
· Planning, comparing, benchmarking and decision-making
· Data protection, management and east-west I/O traffic
· Application and server I/O north-south traffic
Live online Mar 15 10:00 am United States - Los Angeles or after on demand 75 mins
Presented by: Greg Schulz, founder and analyst of Server StorageIO, John Kim, SNIA-ESF Chair, Mellanox

The demand for digital data preservation has increased drastically in recent years. Maintaining a large amount of data for long periods of time (months, years, decades, or even forever) becomes even more important given government regulations such as HIPAA, Sarbanes-Oxley, OSHA, and many others that define specific preservation periods for critical records.
While the move from paper to digital information over the past decades has greatly improved information access, it complicates information preservation. This is due to many factors including digital format changes, media obsolescence, media failure, and loss of contextual metadata. The Self-contained Information Retention Format (SIRF) was created by SNIA to facilitate long-term data storage and preservation. SIRF can be used with disk, tape, and cloud based storage containers, and is extensible to any new storage technologies.
It provides an effective and efficient way to preserve and secure digital information for many decades, even with the ever-changing technology landscape.
Join this webcast to learn:
•Key challenges of long-term data retention
•How the SIRF format works and its key elements
•How SIRF supports different storage containers - disks, tapes, CDMI and the cloud
•Availability of Open SIRFSNIA experts that developed the SIRF standard will be on hand to answer your questions.
Recorded Feb 16 10:00 am United States - Los Angeles or after on demand 75 mins
Simona Rabinovici-Cohen, IBM, Phillip Viana, IBM, Sam Fineberg

SMB Direct makes use of RDMA networking, creates block transport system and provides reliable transport to zetabytes of unstructured data, worldwide. SMB3 forms the basis of hyper-converged and scale-out systems for virtualization and SQL Server. It is available for a variety of hardware devices, from printers, network-attached storage appliances, to Storage Area Networks (SANs). It is often the most prevalent protocol on a network, with high-performance data transfers as well as efficient end-user access over wide-area connections.
In this SNIA-ESF Webcast, Microsoft’s Ned Pyle, program manager of the SMB protocol, will discuss the current state of SMB, including:
•Brief background on SMB
•An overview of the SMB 3.x family, first released with Windows 8, Windows Server 2012, MacOS 10.10, Samba 4.1, and Linux CIFS 3.12
•What changed in SMB 3.1.1
•Understanding SMB security, scenarios, and workloads•The deprecation and removal of the legacy SMB1 protocol
•How SMB3 supports hyperconverged and scale-out storage
Live online Apr 5 10:00 am United States - Los Angeles or after on demand 75 mins
Ned Pyle, SMB Program Manager, Microsoft, John Kim, SNIA-ESF Chair, Mellanox, Alex McDonald, SNIA-ESF Vice Chair, NetApp

•Why latency is important in accessing solid state storage
•How to determine the appropriate use of networking in the context of a latency budget
•Do’s and don’ts for Load/Store access
Live online Apr 19 10:00 am United States - Los Angeles or after on demand 75 mins
Doug Voigt, Chair SNIA NVM Programming Model, HPE, J Metz, SNIA Board of Directors, Cisco