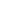Since the early days of Fibre Channel, when somebody/somebodies decided that it would make an excellent fit as the transport protocol for storage networks, the storage industry has enjoyed/endured a rollercoaster ride. Some years it seems that storage is the most import element of the whole IT stack; and in others it’s just been a necessary evil. There’s been serverless backup, the short-lived InfiniBand (at least in the storage sector), the rather longer-lived iSCSI/IP storage, virtualisation, SAS and SATA, object storage, Flash, and, most recently, software-defined storage (SDS) and hyperconvergence.
As each of these, and plenty of other new technologies and ideas, came to market, there was the usual jockeying for position amongst the vendors. Not surprisingly, those who had solutions to sell were heavy promoters of the next big thing, and those who were playing catch up would throw plenty of cold water on the new idea, at least until they’d developed their own solution.
And so it is with SDS and hyperconvergence. The problem for the end user, as ever, is to try and see through the marketing haze to understand what is being offered, what are the potential benefits, and what are the potential downsides.
Confession time. In both cases, I struggle to understand the exact benefits of both these technologies as they are currently being promoted and sold. For hyperconvergence, the idea of packaging together an IT stack to address a specific solution seems to go against the idea of the promise of virtualisation – creating flexible pools of storage and compute that can be accessed as, when and where required. Similarly, when it comes to SDS, many of the solutions are being sold as an appliance – which again seems counterintuitive to the idea of decoupling the hardware and software. Surely, true SDS is a software layer that sits on top of commodity hardware?
It seems that many end users are not quite ready for the ultimate freedom offered by SDS, and still prefer to buy packaged solutions that they know will work, out of the box, with little need for any configuration – hence the attraction of hyperconvergence and SDS appliances at the present time.
I’m also hearing that, for those who truly want to go the SDS route - using open technology and commodity hardware - the problems of putting together the necessary infrastructure are manifold and only solved by some serious technical brainpower. However, conversations with one or two folks at the recent DCW/Cloud Expo event suggest that his is not the case and that assembling an open, software-defined infrastructure environment is not complicated at all.
I suspect from the above that readers can guess who I’ve talked to, depending on the viewpoints expressed!
The lesson to be learnt from all of the above? Make sure you do your homework before deciding on any major IT infrastructure investment decision. After all, I’m even hearing that, where once the recommendation was to ‘put everything in the Cloud, it’ll be much easier and cheaper’, there’s now something of a backlash against the Public Cloud, as it may well not be cheaper, or even easier!
Who would be a CIO right now?!!
Total worldwide enterprise storage systems factory revenue was down 6.7% year over year while reaching $11.1 billion in the fourth quarter of 2016 (4Q16), according to the International Data Corporation (IDC) Worldwide Quarterly Enterprise Storage Systems Tracker. Total capacity shipments were up 18.3% year over year to 52.4 exabytes during the quarter.
Revenue growth increased within the group of original design manufacturers (ODMs) that sell directly to hyperscale datacenters. This portion of the market was up 3.2% year over year to $1.2 billion. Sales of server-based storage declined 7.8% during the quarter and accounted for $3.4 billion in revenue. External storage systems remained the largest market segment, but the $6.4 billion in sales represented a year-over-year decline of 7.8%.
It should be noted that the size of the server-based storage market has been updated this quarter to reflect a change to IDC's enterprise storage systems taxonomy. IDC's new methodology for sizing the server-based storage market is now more inclusive than in the past, thus increasing the size of the market in terms of value, systems shipped, and capacity consumed. Changes to the server-based storage market have been applied retroactively to ensure continuity with past quarters.
"2016 represented a year of considerable change for the enterprise storage systems market," said Liz Conner, research manager, Storage Systems. "While the broader enterprise storage systems market has been impacted by headwinds, companies continue to increase their investments in several key areas, such as software-defined storage, cloud-based storage, all flash storage systems, and converged systems. As a result, traditional enterprise storage vendors have aligned their portfolios to meet the shifting demands."
Advertisement: DCS Awards

4Q16 External Enterprise Storage Systems Results, by Vendor Group
Dell Technologies was the largest external enterprise storage systems supplier during the quarter, accounting for 32.9% of worldwide revenues. HPE, IBM, and NetApp finished in a statistical tie* for the number 2 position with 10.2%, 10.1% and 10.0% of market share, respectively. HPE's share and year-over-year growth rate includes revenues from the H3C joint venture in China that began in May of 2016; as a result, the reported HPE/New H3C Group combines storage revenue for both companies globally. Hitachi rounded out the top 5 with revenue share of 7.0%.
| Top 5 Vendors Groups, Worldwide External Enterprise Storage Systems Market, Fourth Quarter of 2016 (Revenues are in Millions) | |||||
| Vendor Groups | 4Q16 Revenue | 4Q16Market Share | 4Q15 Revenue | 4Q15 Market Share | 4Q16/4Q15 Revenue Growth |
| 1. Dell Technologiesa | $2,124.9 | 32.9% | $2,570.3 | 36.8% | -17.3% |
| T2. HPE/New H3C Group*b | $656.5 | 10.2% | $706.5 | 10.1% | -7.1% |
| T2. IBM* | $653.8 | 10.1% | $791.4 | 11.3% | -17.4% |
| T2. NetApp* | $642.0 | 10.0% | $650.9 | 9.3% | -1.4% |
| 5. Hitachi | $451.6 | 7.0% | $532.0 | 7.6% | -15.1% |
| Others | $1,920.0 | 29.8% | $1,741.8 | 24.9% | 10.2% |
| All Vendors | $6,499.0 | 100.0% | $6,992.9 | 100.0% | -7.8% |
| Source: IDC Worldwide Quarterly Enterprise Storage Systems Tracker, March 3, 2017 | |||||
Notes:
* – IDC declares a statistical tie in the worldwide enterprise storage systems market when there is less than one percent difference in the revenue share of two or more vendors.
a – Dell Technologies represents the combined revenues for Dell and EMC.
b – Due to the existing joint venture between HPE and the New H3C Group, IDC will be reporting external market share on a global level for HPE as "HPE/New H3C Group" starting from 2Q 2016 and going forward.
In the fourth quarter of 2016, worldwide server revenue declined 1.9 percent year over year, while shipments fell 0.6 percent from the fourth quarter of 2015, according to Gartner, Inc. In all of 2016, worldwide server shipments grew 0.1 percent, but server revenue declined 2.7 percent.
"There were some distinct factors that produced the final results for 2016," said Jeffrey Hewitt, research vice president at Gartner. "Hyperscale data centers (e.g., Facebook, Google) grew and, at the same time, drove some significant server replacements. Enterprises grew at a lower rate as they continued to leverage server applications through virtualization and in some cases, service providers in the cloud."
From a regional perspective, Asia/Pacific was the only region to exhibit positive growth in both shipments and revenue in the fourth quarter of 2016. All other regions declined, with Latin America experiencing the largest decline in shipments (12.2 percent, while the Middle East and Africa declined 14.7 percent in terms of revenue.
Hewlett Packard Enterprise (HPE) led the worldwide server market based on revenue in the fourth quarter of 2016 (see Table 1). The company ended the year with $3.4 billion in revenue for the fourth quarter of 2016 for a total share of 22.9 percent worldwide. However, revenue was down 11 percent compared with the same quarter in 2015.
Advertisement: DTC Manchester

Of the top five global vendors, only Dell and Huawei exhibited growth for the quarter, increasing 1.8 percent and 88.4 percent, respectively.
Table 1. Worldwide: Server Vendor Revenue Estimates, 4Q16 (U.S. Dollars)
| Company | 4Q16 | 4Q16 Market Share (%) | 4Q15 | 4Q15 Market Share (%) | 4Q16-4Q15 Growth (%) |
| HPE | 3,392,601,012 | 22.9 | 3,813,592,269 | 25.2 | -11.0 |
| Dell | 2,578,181,854 | 17.4 | 2,533,495,993 | 16.7 | 1.8 |
| IBM | 1,732,474,861 | 11.7 | 1,974,018,084 | 13.0 | -12.2 |
| Huawei | 1,249,813,371 | 7.7 | 610,225,437 | 4.0 | 88.4 |
| Lenovo | 946,283,185 | 6.4 | 1,136,141,494 | 7.5 | -16.7 |
| Others | 5,039,143,533 | 34.0 | 5,064,301,087 | 33.5 | -0.5 |
| Total | 14,838,497,815 | 100.0 | 15,131,774,365 | 100.0 | -1.9 |
Source: Gartner (March 2017)
Dell grew 6.5 percent and moved into the No. 1 position in worldwide server shipments in the fourth quarter of 2016, with 19.1 percent of the market. HPE experienced a decline of 19.4 percent and fell to the second spot with 17.2 percent market share. Huawei experienced the strongest shipment growth in the fourth quarter of 2016, increasing 64 percent over the same period last year (see Table 2).
Table 2. Worldwide: Server Vendor Shipments Estimates, 4Q16 (Units)
| Company | 4Q16 | 4Q16 Market Share (%) | 4Q15 | 4Q15 Market Share (%) | 4Q16-4Q15 Growth (%) |
| Dell | 562,029 | 19.1 | 527,736 | 17.9 | 6.5 |
| HPE | 504,407 | 17.2 | 625,543 | 21.2 | -19.4 |
| Huawei | 245,611 | 8.4 | 149,742 | 5.1 | 64.0 |
| Lenovo | 220,296 | 7.5 | 256,571 | 8.7 | -14.1 |
| Inspur Electronics | 141,132 | 4.8 | 140,166 | 4.7 | 0.7 |
| Others | 1,265,169 | 42.1 | 1,255,747 | 42.5 | 0.8 |
| Total | 2,938,644 | 100.0 | 2,955,505 | 100.0 | -0.6 |
Source: Gartner (March 2017)
x86 server demand increased in revenue by 1.1 percent, however, shipments declined 0.3 percent in the fourth quarter of 2016.
In 2016, worldwide server shipments increased 0.1 percent, while revenue declined 2.7 percent.
"x86 servers continue to be the predominant platform used for large-scale data center build-outs across the globe, and the growth of integrated systems (including hyperconverged integrated systems), while still relatively small as an overall percentage of the hardware infrastructure market, also provided a boost to the x86 server space for the year," said Mr. Hewitt. "The outlook for 2017 suggests that modest growth will occur being driven primarily by service provider build-outs while the enterprise will show a slight decline in unit purchases with only slight growth in revenue."
An independent survey commissioned by Zadara® Storage, the provider of enterprise-class storage-as-a-service (STaaS), has underscored the IT industry’s need for symmetrically scalable cloud storage, that can instantly scale up or down to meet business requirements, as a key challenge to growth in 2017 – and corroborates other recent analyses of IT demands for storage scalability in the coming year.
When asked to share their top strategy for managing their organisation’s data storage in 2017, one third of IT decision makers responding in Germany, the UK and the US, ranked “having cloud storage that scales up or down according to my organisation’s needs” as their #1 wish in 2017. Scalability was cited by nearly twice as many as those who selected the next highest response, outranking other mission-critical IT demands. The 2017 wish list unveiled by this research included:
33% – Deploy cloud storage that scales up and down according to my organisation’s needs17% – Obtain stronger service level agreements (SLAs) from my organisation’s cloud storage vendor13% – Deploy new storage hardware 11% – Deploy storage-as-a-service to make management easier 11% – Enjoy important storage updates in the cloud that are also available on-premiseEmploy other strategies including features to complete mundane storage tasks (9%), getting new storage software to provision the organisation’s data (7%), and other options such as budgeting and process improvement assistance (1%)
The survey demonstrated that IT decision makers are frequently relying on the public cloud. However, concerns around the integrity of data and level of service from cloud vendors have yet to be addressed. The second most popular wish for IT decision makers in both the UK and US this year was “stronger service level agreements from my organisation’s cloud storage vendor,” demonstrating issues around ongoing maintenance, proactive support from the vendor, ongoing system monitoring and 100% uptime. Meanwhile, German respondents indicated that “getting important storage features in the cloud that we have on-premise” was second on the list.
IT leaders around the world were remarkably united in their sentiment on their desire for scalability, with minor differences:
15% of UK IT leaders ranked strong SLAs as their main wish – tied second place with deploying software-as-a-service features so as to make their architectures more manageableTwice as many US IT leaders wished for stronger SLAs, at 20% of respondents, than their counterparts in Germany, at 11%Unlike their peers in the UK or US, German IT leaders ranked the need to get services to complete mundane storage tasks markedly higher, at 14% of total German responses, compared to 9% in the UK and just 6% in the US. This demand for freedom from the mundane tasks was tied with deploying storage-as-a-service so IT management is easier. German respondents also were interested in obtaining important on-premise features in the cloud, ranking this as the second most important item they would wish for in 2017, at 15% of total German respondents. Organisational size had little to no impact on IT ranking of 2017 wish list items. Responses from IT leaders in organisations with between 1,000 and 3,000 employees, and from enterprises with over 3,000 employees, followed the same ranking as the aggregate, and their percentage wish list items varied by only a percentage point or two.
Results corroborate other industry research showing that scalability is the #1 reason for moving to the cloud in the first place (at 51%), followed by business agility (46%) and cost (43%). They also echo numerous IT leader remarks on their own priority rankings of what they seek from the cloud storage vendors that serve them.
This new survey shows that, whether in the public or private cloud, IT decision makers need a flexible, scalable and reliable data storage solution first and foremost – storage that works according to the organisation’s short-term needs, but that can also rapidly adapt over time.

Easily scalable Quantum archive improves long-term integrity and availability of content while minimising costs.
Atlanta based Crawford Media Services is using Quantum's Lattus® object storage to build a content repository that supports mass migration of its clients’ legacy content to digital formats and provides ongoing media storage and management. Designed to hold an initial 1.2 petabytes of archived assets as well as content ingested during new projects, the system gives Crawford Media a sophisticated storage infrastructure that cost-effectively accommodates ongoing expansion of the company’s services and customer base.
At Crawford Media, the mass digitisation of clients’ content involves the generation of thousands of media files, all at the high bit rates and large file sizes suitable for production. As its business continued to grow, the resilience limitations of its existing archive architecture became ever more obvious.
“When you are dealing with large archives of media files at preservation quality, you start creating a data footprint and a performance demand that outstrip the capabilities of typical IT departments,” said Steve Davis, executive vice president and chief technology officer at Crawford Media. “Our challenge was to develop a digital archive that would become more robust as it grew in size, rather than more fragile. We explored solutions that would allow us to keep large data sets cost-effectively in perpetuity without degradation, and to survive the costs of media and technology refreshes over time. After extensive research and testing, it became clear that object storage with erasure code — and specifically, Lattus — was the ideal choice.”
Advertisement: Flash Forward

According to Davis, a key factor in his selection of Lattus was the level of robustness, availability and immunity to failure it provided, which he saw as “impossible to achieve with simple replication.” Lattus’ self-healing and self-migration capabilities preserve the integrity of media files, and it offers seamless, infinite incremental scaling with no downtime.
“One nice thing about the Lattus approach, in particular, is that the growth increments are very manageable and very flexible,” Davis explained. “You don’t have to conform to a certain hard drive form factor or size to expand the system. The system simply uses capacity as you add it, becoming more robust as it gets bigger.”
“The advantages of erasure code for an archive are overwhelming,” Davis continued. “Unparalleled data integrity, immunity to entropy, a smaller data footprint than replication, high immunity to system failure, automatic rebalancing of data, and media refresh as the archive grows. With Lattus, AMBER offers our clients the extremely high levels of data durability and data integrity they need in their digital media archives.”
Along with Lattus, Crawford Media deployed Quantum’s Artico™ archive appliance, which incorporates Quantum’s StorNext® data management to move content to and from Lattus automatically while maintaining full access to the files. In addition, StorNext enables the company to write to tape for its clients.
In short, Quantum’s integrated, multi-tier storage solution enables Crawford Media to capitalise more easily and cost-effectively on new revenue-generation opportunities.
“When storage-as-a-service is your business, you need an underlying infrastructure that enables you to onboard new clients and new data as aggressively as possible,” said Davis. “With Quantum’s strong technology and support, we enjoy confidence in the overall archive and its integrity over the long term. That’s peace of mind we’d never get by assembling components ourselves. The reliability of the system keeps our cost points stable, which in turn gives us the freedom to offer better services at a competitive price.”
Set within an impressive 700-acre estate in the Surrey Hills in South-East England, Woldingham School is one of the top girls boarding schools in England and provides world-class education to both home and international 11 to 18-year old’s. It was established in 1842 as Covent of the Sacred Heart, with a legacy of Sacred Heart principles and values. The school is founded on the principles of respect for intellectual values, a sense of community, social awareness, the importance of personal growth and the development of an individual Christian faith.
With first class facilities for drama, music and sport, the school is very proud of its excellent record of public examination success alongside an extensive choice of extra-curricular activities.
The 200-acre main school site is comprised of a mix of traditional and modern buildings for teaching, boarding accommodation for over 350 pupils and over 50 houses and flats for teaching and support staff. With over 550 students and 200 staff on premise, IT Operations Manager Edd Rogers, and his IT team of four, manage a complex network with high demand to support the teaching and learning, the school’s business elements and the social use of technology for entertainment and communication.

One of the challenges within Woldingham’s environment is making sure all of the data stored across the network is backed up and available easily should anything go wrong.
Prior to implementing a dedicated online backup solution, the school was utilising a hybrid solution to back up both physical and virtual servers which meant that once the data had been backed up to a storage array, a copy of that data would then be transferred to tape. Whilst the solution had been adequate in the past, the significant increase in student and staff data challenged the scalability of the solution. It became clear they were in need of an upgrade.
Edd Rogers, IT Operations Manager for Woldingham School, explains: “It was becoming increasingly obvious that the software we were using was struggling to meet our needs. We needed to back up more data each night than the backup solution could manage without affecting the performance of the network during the school day and evenings. It wasn’t uncommon to come in first thing in the morning and see the process was still running or that it would have issues that needed troubleshooting. When making full backups for end of term archives it could take up to three days before we had a copy on tape that we could store securely. In short, the team and I were spending a lot of time fixing issues to ensure we had a reliable backup of our data.”
In addition to an out of date solution, the school found that because they were using separate providers for the virtual and physical backup, they didn’t have a single point of contact for support.
“Towards the end of using our old solution we were finding that we had issues on a daily basis. This problem was intensified by having no support contracts,” comments Toby Peyton, Infrastructure Specialist at Woldingham School.
He continues: “Thankfully we never experienced an issue where we lost any student data whilst using our previous backup solution. However, the thought was constantly on my mind as everyone would look to us if an incident did occur. That was one of our main motivations to begin looking for an alternative option.”
The IT team began looking for a new backup solution in 2013 with a list of specific criteria that needed to be met. They were also conscious that they needed a provider that was reliable, supportive and could justify monetary investment.
“Ideally we were looking for a solution that would minimise us having to maintain and manage the backup process. We were also looking to back up around 4TB of data and with the possibility for the amount of data to increase; we needed something that would be scalable,” comments Edd Rogers. “In addition to needing a reliable solution provider we also wanted to use a service that would provide a greater level of support than our previous offering.”
Having looked at a number of solutions, Edd Rogers and his team met Redstor in January 2015. Following a demo of the Redstor Backup for Schools Service (RBUSS), the solution was rolled out at the school in August the same year.
Edd Rogers says, “We had looked at a number of providers throughout our search but when we had a demo with Redstor they instantly stood out to me. As we were running through their RBUSS offering I was mentally ticking off all the boxes in my head. It was perfect.”
Following a smooth implementation process, with no downtime due to the school overlapping their old backup with Redstor, the school is now successfully backing up over 4TB of student and staff data.
Redstor’s cloud backup solution provides schools with quick, cost-effective, secure offsite backup; allowing them to recover data anytime and anywhere. In addition, the service guarantees security by ensuring that data is encrypted at source, in transit and at rest in Redstor’s data centres using either 128-bit AES, 256-bit AES or 448-bit Blowfish security.
The RBUSS offering is also ISO 27001 and ISO 9001 certified which allows organisations to comply with the legislation and guidelines which are outlined by Ofsted, Data Protection Act and The Information Commissioner’s Office. These guidelines require schools to securely back up data off-site on a daily basis. Using Redstor’s solutions means that Woldingham School have greater peace of mind that they are continuing to comply with these guidelines.
“One of the biggest differences since rolling out Redstor’s RBUSS has been the usability and reliability of the solution. The backup is usually complete within just one hour and there is significantly less time troubleshooting any problems. I leave the backup to complete by itself and remain confident the process will complete with no issues. It gives me great peace of mind, we have a full report in the morning so we know immediately if there have been any issues” comments Edd Rogers.
Redstor’s solution is fully automated and simplifies the management of the software for the IT team; meaning that it reduces time spent ensuring a backup completes. The service also addresses the challenge of coping with data growth within the school as Redstor’s service can scale without any additional hardware or software requirements.
In early 2016 the school encountered an issue whereby they lost access to one of their servers. By carrying out Redstor’s restore process, they were able to recover all data and up and running within a few hours. “If we had still been using our old solution, I’m not confident the restore process would have been as simple,” comments Mr Rogers following the incident.
He concludes: “Our overall experience of working with Redstor has been fantastic. From the excellent backup offering, ongoing technical support and dedicated account manager, we have been extremely happy since partnering with them.”
The Vitec Group plc enables the capture and sharing of exceptional images. Vitec provides customers in the broadcast and photographic markets with the products and services they need to seize the opportunity and capture the moment.
The broadcast and photographic markets have undergone major changes with the arrival of drones, smartphones, YouTube, Netflix and Instagram. According to Brandwatch, people watch 500 million hours of YouTube videos each day and share 80 million photos on Instagram. To capitalise on these growing markets, Vitec expanded into new technologies and engaged in a disciplined approach to merger and acquisition. Vitec grew rapidly, and so did its IT infrastructure.
“Managing a large, remote IT infrastructure and recovering each location quickly in times of crisis became major challenges,” said Ben Skinner, Head of Corporate Network and Infrastructure at Vitec. “We worried the company’s two core applications—an integrated financial system and a corporate performance management system—couldn’t be recovered fast enough to avoid an adverse impact on business performance and revenue.”
Vitec’s IT infrastructure spans several time zones, so 24.7 Availability of core applications is tremendously important. When U.S. offices close for Thanksgiving, U.K. offices pick up the pace, and vice versa when U.K. offices close for Boxing Day.
Advertisement: MSH Summit UK

“Our goal was centralised management of backup, replication and recovery so we could standardise disaster recovery and business continuity in every location,” Skinner said. “We were gearing up for cloud-based workloads, so we also needed a fully integrated, fast and secure way to back up, replicate and restore from the cloud.”
Veeam® Availability Suite™ centralises backup, replication and recovery for Vitec. Veeam helps keep core business applications running 24.7.365 in every location and enables the company to standardise disaster recovery and business continuity across the enterprise. As Vitec’s IT infrastructure continues to grow through merger and acquisition, Veeam provides what legacy backup could not: enterprise scalability and support for digital transformation.
No matter how large Vitec’s IT infrastructure grows, Veeam’s enterprise scalability ensures every location is “always on.” No matter what digital challenges newly acquired companies bring, Veeam supports their transition to virtualisation with fast, reliable backup, replication and recovery.
“The best word to describe Veeam is flexibility,” Skinner said. “By unifying and centralising backup, replication and recovery, Veeam lets us determine our own destiny. Veeam gives us the choice of how often we back up and replicate—and to where—based on what best suits the business’ needs in terms of availability and cost.”
One of the choices Veeam offers is backup, replication and recovery from storage snapshots. Veeam integrates fully with two of Vitec’s storage systems: Hewlett Packard Enterprise (HPE) 3PAR StoreServ and Dell EMC VNX; therefore, Vitec makes backup and replicas from storage snapshots as often as the company chooses because there is little to no impact on production. Vitec restores from storage snapshots because recovery is nearly instantaneous.
Veeam Cloud Connect gives Vitec a fully integrated, fast and secure way to back up, replicate and restore from the cloud rather than paying for and maintaining a separate offsite infrastructure. Vitec is incorporating Microsoft Azure into its DR strategy, and Veeam lets Vitec quickly restore (or migrate) workloads to Azure without complex configurations or additional investments.
“Veeam Cloud Connect lets us add Disaster Recovery-as-a-Service (DRaaS) to our Availability strategy without a layer of management complexity and cost,” Skinner said. “We can replicate onsite, offsite to regional data centres and/or to Azure — it’s our choice. Veeam’s competitors don’t allow that flexibility or convenience.”
Veeam Availability Orchestrator offers additional flexibility and convenience by helping Vitec execute, test and document disaster recovery plans. Veeam synchronises 24.7 Availability requirements across Vitec’s backup and replication targets.
“We love Veeam’s flexibility,” Skinner said. “We’re even making good use of our old tape libraries with Veeam’s native tape support. Veeam copies our backups to tape for offsite data archival.”
• Ensures critical systems run 24.7 at every company location
Before Veeam was deployed at Vitec, recovering critical systems with legacy backup could take up to 72 hours. Instant VM Recovery® with Veeam restores the same critical systems in minutes.
• Adds DRaaS to Availability strategy without added complexity and cost
Veeam Cloud Connect lets Vitec replicate virtual machines to Microsoft Azure rather than building and maintaining an offsite infrastructure. Data is encrypted in flight and at rest.
• Executes, tests and documents disaster recovery plans
Veeam Availability Orchestrator provides orchestration of Veeam backups and replicas through a defined disaster recovery plan, non-disruptive testing, automated documenting, updating and reporting. This combination of capabilities helps companies ensure 24.7 Availability, maintain reliability, reduce costs of manual processes and satisfy compliance requirements.
“The best word to describe Veeam is flexibility. By unifying and centralising backup, replication and recovery, Veeam lets us determine our own destiny. Veeam gives us the choice of how often we back up and replicate—and to where—based on what best suits the business’ needs in terms of availability and cost.” - Ben Skinner Head of Corporate Network and Infrastructure The Vitec Group plc
Most organizations refer to their high-performance computing environment as simply “the HPC,” or even “the cluster,” but at Florida Atlantic University, the team calls it “Ko'Ko.” As simple and easy to remember as that pet name may be, however, the supercomputing resource it describes is both powerful and highly complex.
Based in Boca Raton, Florida Atlantic University (FAU) is a public, four-year coeducational doctoral degree-granting institution with five satellite campuses. In 2012, FAU became a member of the Sunshine State Education & Research Computing Alliance (SSERCA), which provides HPC resources to researchers, students and academics.
FAU’s Office of Information Technology received a SSERCA grant in 2013 to create the first set of 20 nodes in what became Ko'Ko. The goal was to provide students access to a diverse set of HPC resources to perform world-leading research, and to support faculty in providing word-class education. Beyond purchasing equipment and software, FAU spent considerable time making connections in the supercomputing sector and learning best practices. In 2014, for example, the university hosted the quarterly SSERCA Summit, becoming an equity member. Internally, FAU set up an HPC Governance Committee comprised of both researchers and faculty to guide the strategic thinking behind its efforts.
Advertisement: MSH Summit Europe

When Ko'Ko went live on the Jupiter campus in late 2014, FAU chose Bright Cluster Manager to provide critical support in administering the HPC environment. There is already high demand from students and faculty, who are using Ko’Ko’s resources for teaching Hadoop Map Reduce, pursuing bioinformatics research and other modeling and visualization work.
“Bright Cluster Manager has been a great help,” says Eric Borenstein, HPC Administrator at FAU. “Before this project, I was a Windows admin. Bright made things easy. It’s a simple learning curve, compared with other alternatives.”
Ko'Ko has given FAU the ability to speed up research while reducing costs by offering high bandwidth and low latency. More specifically, Borenstein says Bright Cluster Manager provided value in these key areas:
Automation: Borenstein said it’s a relief using Bright Cluster Manager to handle everything from large projects to more simple tasks like the DNS and HTTP.
“I could do it all manually, but Bright made it a breeze, he says. “I like how it monitors everything – the implementation of Hadoop was really straightforward, especially having never worked with Hadoop before. It was great to just bring up new nodes or move them into another category. Once you figure out the workload, you can rebuild in two minutes.”
Troubleshooting: Given that HPC was new to FAU, first-class support was essential, and according to Borenstein, Bright Computing delivered.
“I would get good feedback, and even within the same day of reaching out, the team at Bright would send me a package to fix any little issue,” he says. “I’ve used their support quite a lot. They probably recognize my email by now!”
Scalability: Borenstein says the environment has quickly grown to 56 nodes since the launch, with about 44 compute nodes in its main cluster, a small Windows cluster and a test cluster. Ko'Ko is expected to double in size every year as FAU pursues more areas of research. This could include medicine, big data analytics, physics and astronomy. Other academics at FAU are considering the cluster for work in software development.
As Ko'Ko becomes an integral part of getting important work done at FAU, Borenstein said Bright Cluster Manager is making sure he and his team achieve their primary goal: complete user satisfaction. “The biggest thing for us is feedback from our customers,” he says. “If faculty and students are happy, we’re happy.”
NetApp has been selected by Comfy Quilts, a leading manufacturer of quilts and pillows, to bolster its IT infrastructure with robust new solutions to support the business and increase productivity.
Headquartered in Cheshire, with manufacturing and distribution sites across the Manchester region, Comfy Quilts has cushioned our sleep since 1973. The company has grown steadily over the years – and exponentially since its acquisition of Bedcrest in 2000. As a result, its existing IT infrastructure struggled to keep up with the steep rise in business growth. The systems would frequently crash, affecting every aspect of the business from production to dispatch
In order to combat these challenges and help the business transition from an SME to becoming a larger corporate entity, Comfy Quilts approached NetApp’s partner LIMA with a brief to develop a modernised, robust IT infrastructure, who then engaged NetApp in the ambitious project. The solution included a new virtualised environment, capable of handling five times as many systems users while also supporting continuous production and ongoing business growth.
The installation included a FlexPod with Hyper-V clustered virtual environment running a dual-control NetApp FAS hybrid array, which immediately solved the server downtime by providing more server resources and storage, and laying the groundwork for the move towards a full virtual desktop infrastructure. Comfy Quilts also opted for disaster recovery using a NetApp FAS hybrid system with the ONTAP storage operating system for scalability, and integrated Veeam Backup and Replication to create a failover platform.
Jason Corfield, Head of IT, Comfy Quilts, said: “I looked at a lot of storage providers but ultimately chose NetApp. I had experience of working with NetApp in the past and knew that it wasn’t just a technology purchase but actually a complete solution. This made the difference.Advertisement: DCS Awards
“Our new system has given us the ability to make our production continuous, crucial for helping the business grow. It has dramatically reduced system downtime, and even manged to save us around £150,000 every year in power and uptime costs. To top it all off, the installation process was very simple – the solution integrated perfectly with our existing infrastructure and immediately produced results against our existing challenges.”
Mohamed Bakeer, CTO, LIMA added: “As an award winning NetApp Gold Partner, our relationship with NetApp is a strong one. Our work with Comfy Quilts illustrates how this partnership enables us to provide our customers with the next generation of IT infrastructure and storage technology. We are proud to have enabled such a successful business transformation, and look forward to working with Comfy Quilts to utilise the full potential of its new digital solution.”
Matt Watts, Director, Technology and Strategy, NetApp concluded: “Comfy Quilts is an industry leader in Europe, bringing comfort to customers across the region with its portfolio of bedding companies and manufacturing outlets. Its drive to reinvigorate business by modernising its IT infrastructure is exemplary. As it grows and delivers products with increased efficiency, thanks to its new, scalable virtual environment, it is a clear benchmark in the true business value of digital transformation.”
Western Digital's HGST Active Archive System, the first in a family of products to include the ActiveScale™ P100 and X100, is enabling the École Polytechnique Fédérale de Lausanne (EPFL) to archive more than 17,000 hours’ worth of live music, video, and data from the Montreux Jazz Festival to instantly enjoy, study and interact with the content well into the future. Converted from tape to digital format and stored on the HGST Active Archive System, the performances and supporting data are easily accessible in real-time and on-demand, removing physical and technological barriers, and resulting in substantial research and production workflow improvements at EPFL.
As part of the Montreux Jazz Digital Project, the HGST Active Archive System stores and delivers live video and audio recordings from a variety of concerts dating back to 1967. The recordings span 18 different media formats that were used to capture 11,000 hours of video and 6,000 hours of audio from more than 5,000 concerts. The archive is the most comprehensive collection of live music footage ever created and contains classic performances from Marvin Gaye, Ella Fitzgerald, B.B. King, Johnny Cash, Deep Purple, Eric Clapton, and more, all of whom have performed at the Montreux Jazz Festival. In recognition of its 50 years of music and video archiving, the collection was inducted into the UNESCO Memory of the World program in 2013.
“Quincy Jones declared the Montreux Jazz Festival archives to be ‘the most important testimonial to the history of music, covering jazz, blues, and rock.’ As part of EPFL’s preservation and valorization project, the HGST Active Archive System enables the Montreux Jazz Digital Project to save irreplaceable video, audio, and data for generations to come, eliminating many of the issues presented by using tape in frequently accessed data archives. By digitizing festival archives and storing them on the HGST Active Archive System, this project is enabling future generations to relive some of the greatest performances from legendary musicians,” said Alain Dufaux, director of Operations and Development for the Montreux Jazz Digital Project.
Advertisement: MSH Summit
The HGST Active Archive System is an easy-to-deploy, Amazon S3®-compliant, scale-out object storage system, upon which EPFL is currently storing three petabytes (PB) of data and planning to accommodate for a growth of 30 percent over the next five years. EPFL deployed three HGST Active Archive Systems over three locations in a geographically spread configuration to archive the entire Montreux Jazz Festival files, allowing continuous data access from any location – even in the event of a data center outage. This configuration allows EPFL to protect its data through erasure coding with higher reliability and at lower cost than a traditional multi-copy approach, while delivering the accessibility to support their services. This architecture ensures that the 15 generations of existing tape copies are maintained as required by the UNESCO Memory of The World register, while simplifying provisioning of select recordings to the public and all recordings for research and study across EPFL.
“The HGST Active Archive System, as well as the new ActiveScale systems, are perfectly suited to capture the entirety of the Montreux Jazz Digital Project archives,” said Dave Tang, general manager and senior vice president, Data Center Systems business unit, Western Digital. “Creating a permanent home for 50 years of live performances by countless legends of jazz, rock, and popular music demands not only unwavering reliability and protection of these priceless treasures, but also instant access so that they can be enjoyed by generations to come.”
La Redoute, a leading international clothing and homeware retailer, has implemented a managed cloud backup solution from managed cloud service provider, Adapt (a Datapipe company), to improve the reliability and performance of key elements of its backup strategy across the organisation.
The service, which will be delivered by Adapt in partnership with specialist solutions provider, ORIIUM, will be based on Commvault backup and recovery technology. The solution replaces La Redoute’s previous on-premise solution, ensuring that its backup and file restoration systems can keep up with the company’s growth.
The service, ORIIUM CX:Protect, offers La Redoute three levels of cover: Mass Data Protection (MDP) for physical server and associated file storage, Intelligent Application Protection (IAP) for databases and directory services, and Virtual Server Essential Protection (VSEP) for the virtual server estate.
“Adapt and ORIIUM offer a best of breed approach to the backup challenges we needed to address,” explained Head of IT and Facilities at La Redoute UK, Andy Green. “As a growing fashion and homeware retailer, we wanted to leverage the versatility and cost advantages offered by a cloud solution, but also be confident that the levels of service and security were of the highest standards. Adapt fully understood the challenge and this approach integrates all these requirements, as well as being highly cost-effective.”
“We’re excited to be working with La Redoute and supporting their business growth. La Redoute is drawing on the combined experience and expertise of Adapt and ORIIUM to capitalise on the core benefits of a cloud-first approach,” commented Scotty Morgan, Chief Sales Officer at Adapt. “It allows their IT team to focus on strategic elements of their infrastructure, confident in the fact that they have a much more reliable and secure approach to backup than before.”
URALSIB Insurance Company, part of Financial Corporation URALSIB in the Russian Federation, has consolidated a number of its data storage systems to the InfiniBox™ enterprise-proven data storage solution. Purchased through IT partner Softline, the InfiniBox enables the firm to consolidate VMware virtual infrastructure data, business intelligence systems and its Virtual Desktop Infrastructure (VDI) to one system, while reducing the company’s storage costs by 2.5 times and allowing better productivity.
Headquartered in Moscow, URALSIB Insurance Company is involved in liability insurance, property and voluntary medical insurance, as well as banking insurance. Previously, the company used IT equipment from different manufacturers, purchasing each piece separately and when needed. Because of the ever-increasing amount of information processed, URALSIB had to update its data storage system to manage these larger volumes of data. The company contacted its IT partner Softline, who proposed a solution based on INFINIDAT’s Infinibox storage array.
The criteria for choosing the new solution were performance, reliability and total cost of ownership (TCO). The storage system was tested by specialists both remotely at Softline’s data processing centre, as well as on site at URALSIB, thanks to a try-and-buy offer. The results exceeded expectations achieving half the latency they had with their existing arrays and, consequently, URALSIB purchased a data storage system with a usable capacity of 130TB. The InfiniBox F2240 URALSIB purchased has 38TB of cache and 330TB of useable capacity. Today capacity is only limited by the license. INFINIDAT’s “capacity-on-demand” model enables instant storage expansion just by purchasing additional licenses.
The implementation included the installation of the equipment in the customer’s data centre, reliability testing, and integration into the IT infrastructure. The new storage system showed superior performance. For example, standard analytical reports are now generated almost three times faster. As a result of the project, URALSIB Insurance Company has acquired a universal, scalable and resilient storage solution that meets its overall business requirements.
"We have seen great results with the INFINIDAT storage solution. We reduced our storage costs by 2.5 times, and were able to increase performance while removing all issues related to future upgrades," said Sergei Zherdev, head of the IT department of URALSIB Insurance Company.
"Thanks to this project for URALSIB Insurance, we have been able to affirm the high reliability and performance of our solutions. This has allowed the customer to not only consolidate their diverse business needs in a single storage system, thereby saving on support and management, but also to gain a distinct advantage in performance," said Alexander Rabkin, INFINIDAT Director of Business Development and Sales in Russia and CIS countries.
"This is our first experience of implementing an InfiniBox system for a Russian customer. We are confident that in the future, the popularity of this solution in the domestic market will continue to grow, and we are already offering our clients the chance to test the equipment in our demo area,” said Oleg Pismarev, Softline Senior Manager for Financial Institutions.
Czech Television, the public television broadcaster in the Czech Republic, has implemented DDN’s MEDIAScaler® parallel file storage for better support of an explosion of digital video content and the demands of high-end production equipment, challenging 4K workflows and ultra-high-definition formats. In meeting its goal to deliver news, sports and entertainment broadcasting 24/7, including a wealth of original programming, Czech TV required the highest levels of storage performance and capacity.
The organisation had to ensure uninterrupted workflows across video ingest, editing, transcoding, distribution and archiving. In addition, Czech TV needed to accommodate multiple teams of people concurrently working on the same large files who were performing necessary color corrections and also restoring many old films that were in bad condition. To eliminate potential performance bottlenecks and operational delays, the company upgraded its legacy DDN storage infrastructure with a state-of-the-art DDN MEDIAScaler, a fully integrated storage platform with one petabyte of capacity and more than 7GB/s single-stream performance to keep pace with the most data-intensive media workflows.
According to Jaroslav Sladek, video department chief for Czech Television,
seamless data access is strategic to maximising production value while
minimising time to delivery both now and in the future. “DDN’s MEDIAScaler is
an essential piece of our future global storage network,” he says. “And the
best part of all is that the platform does exactly what it’s supposed to do.
The best product is the one you forget about because it simply works—and that’s
DDN.”
As Czech TV’s centralised, shared storage solution, DDN’s MEDIAScaler supports
multiple workloads, including 2K scanning using a Bone Spirit scanner; 4K
restoration via three Diamant restoration suites; 4K color correction with two
Baselight 4, four-node clusters; both 4K and 2K color correction using
Baselight 2; and 2K DVS Clipster® for finalising production files. The robust
storage enables more workload clients to be added as needed without delay while
streamlining the process of adding more drives and storage capacity without
disrupting operations.
Advertisement: Flash Forward
With DDN, satisfying evolving requirements, such as 3D and 8K formats, is straightforward, as is accommodating a move to open networking. DDN’s support of OpenFlow, the emerging industry protocol for enabling software-defined networking, gives Czech TV a fast, flexible path to the future. The trouble-free implementation was completed in less than two weeks with no disruption in critical operations. Moreover, various teams from both broadcast and post-production now work on massive files concurrently without any performance degradation.
“DDN’s MEDIAScaler provided an all-in-one turnkey solution designed to overcome the scale, performance and cost hurdles associated with data-hungry media environments,” says David Stein, CEO of Interlab, a France-based systems integrator with extensive experience in the film and broadcast industries. “This made it easy for Czech TV to grow capacity and performance with both scale-up and scale-out schemas.”
As the leading broadcast storage solution on the market, DDN supports more than 600 media and entertainment installations, including some of the biggest in the industry. Media companies rely on DDN’s deep industry experience and unmatched performance to future-proof their environments and stay ahead of their competition by having the optimal storage solution to accommodate current and next-generation broadcast and post-production capabilities.
A project to deploy a virtual desktop infrastructure (VDI) solution at Calor Gas, the UK’s leading supplier of liquid petroleum gas (LPG) has gone live after Atlantis Computing was able to deliver a 35 percent end user performance improvement over their existing storage solution. The solution, running on the Citrix XenApp environment with Atlantis HyperScale and USX storage is also 28 percent cheaper than their existing solution.
Calor Gas is responsible for more than 900 office-based employees and remote workers, so both high performance and concrete reliability are critical for core business operations. Atlantis HyperScale and Atlantis USX have been deployed to build, support and manage Calor Gas’ new virtualized IT environment.
In the initial project trials, Calor Gas evaluated the VDI deployment based on Citrix XenDesktop, but significant performance issues in its existing SAN arose. Calor Gas needed a VDI solution to support resource-intensive applications and specialist software on a regular basis for remote development and external contractors, which would have required extending the SAN.
“We needed to increase our storage performance to cope with the bursty traffic that is typical in a VDI environment, but expanding our existing storage wasn’t cost effective at all,” says Andy Browne, infrastructure manager at Calor Gas. “We initially parked the entire VDI project as a result.”
Advertisement: DT Manchester
Deploying Atlantis HyperScale offered Calor Gas a cost effective solution, which combines compute and storage into a single appliance, developed, supported and maintained by a single vendor. “The Atlantis HyperScale appliance smooths out the peaks and gives the consistent performance needed in a VDI environment,” said Browne.
“An organization like Calor Gas requires constant high performance and reliability, and we are pleased Atlantis could play an important role in delivering this solution,” said Chris Plant, EMEA vice president at Atlantis Computing. “We continually look to transform user experience for customers working with Citrix. This achievement demonstrates how well these solutions can work together to increase business performance.”
Calor Gas installed a second Atlantis HyperScale appliance for the new virtual desktops to support the heavy workloads of power users. HyperScale works to provide consistent performance in a VDI environment, which typically fluctuates in traffic. Atlantis Computing designed a solution for Calor Gas that provides a fully redundant storage solution. Through continual replication of both HyperScale appliances to Atlantis USX virtual platform, Calor Gas has a highly effective disaster recovery and business continuity solution along with a high performing reliable VDI.
However, there is something of a mystique surrounding these different data center components, as many people don’t realize just how they’re used and why. In this pod of the “Too Proud To Ask” series, we’re going to be demystifying this very important aspect of data center storage. You’ll learn:•What are buffers, caches, and queues, and why you should care about the differences?
•What’s the difference between a read cache and a write cache?
•What does “queue depth” mean?
•What’s a buffer, a ring buffer, and host memory buffer, and why does it matter?
•What happens when things go wrong?
These are just some of the topics we’ll be covering, and while it won’t be exhaustive look at buffers, caches and queues, you can be sure that you’ll get insight into this very important, and yet often overlooked, part of storage design.
Recorded Feb 14 2017 64 mins
Presented by: John Kim & Rob Davis, Mellanox, Mark Rogov, Dell EMC, Dave Minturn, Intel, Alex McDonald, NetApp

Advertisement: Cloud Expo Europe

Converged Infrastructure (CI), Hyperconverged Infrastructure (HCI) along with Cluster or Cloud In Box (CIB) are popular trend topics that have gained both industry and customer adoption. As part of data infrastructures, CI, CIB and HCI enable simplified deployment of resources (servers, storage, I/O networking, hardware, software) across different environments.
However, what do these approaches mean for a hyperconverged storage environment? What are the key concerns and considerations related specifically to storage? Most importantly, how do you know that you’re asking the right questions in order to get to the right answers?
Find out in this live SNIA-ESF webcast where expert Greg Schulz, founder and analyst of Server StorageIO, will move beyond the hype to discuss:
· What are the storage considerations for CI, CIB and HCI
· Fast applications and fast servers need fast server storage I/O
· Networking and server storage I/O considerations
· How to avoid aggravation-causing aggregation (bottlenecks)
· Aggregated vs. disaggregated vs. hybrid converged
· Planning, comparing, benchmarking and decision-making
· Data protection, management and east-west I/O traffic
· Application and server I/O north-south traffic
Live online Mar 15 10:00 am United States - Los Angeles or after on demand 75 mins
Presented by: Greg Schulz, founder and analyst of Server StorageIO, John Kim, SNIA-ESF Chair, Mellanox

The demand for digital data preservation has increased drastically in recent years. Maintaining a large amount of data for long periods of time (months, years, decades, or even forever) becomes even more important given government regulations such as HIPAA, Sarbanes-Oxley, OSHA, and many others that define specific preservation periods for critical records.
While the move from paper to digital information over the past decades has greatly improved information access, it complicates information preservation. This is due to many factors including digital format changes, media obsolescence, media failure, and loss of contextual metadata. The Self-contained Information Retention Format (SIRF) was created by SNIA to facilitate long-term data storage and preservation. SIRF can be used with disk, tape, and cloud based storage containers, and is extensible to any new storage technologies.
It provides an effective and efficient way to preserve and secure digital information for many decades, even with the ever-changing technology landscape.
Join this webcast to learn:
•Key challenges of long-term data retention
•How the SIRF format works and its key elements
•How SIRF supports different storage containers - disks, tapes, CDMI and the cloud
•Availability of Open SIRFSNIA experts that developed the SIRF standard will be on hand to answer your questions.
Recorded Feb 16 10:00 am United States - Los Angeles or after on demand 75 mins
Simona Rabinovici-Cohen, IBM, Phillip Viana, IBM, Sam Fineberg

SMB Direct makes use of RDMA networking, creates block transport system and provides reliable transport to zetabytes of unstructured data, worldwide. SMB3 forms the basis of hyper-converged and scale-out systems for virtualization and SQL Server. It is available for a variety of hardware devices, from printers, network-attached storage appliances, to Storage Area Networks (SANs). It is often the most prevalent protocol on a network, with high-performance data transfers as well as efficient end-user access over wide-area connections.
In this SNIA-ESF Webcast, Microsoft’s Ned Pyle, program manager of the SMB protocol, will discuss the current state of SMB, including:
•Brief background on SMB
•An overview of the SMB 3.x family, first released with Windows 8, Windows Server 2012, MacOS 10.10, Samba 4.1, and Linux CIFS 3.12
•What changed in SMB 3.1.1
•Understanding SMB security, scenarios, and workloads•The deprecation and removal of the legacy SMB1 protocol
•How SMB3 supports hyperconverged and scale-out storage
Live online Apr 5 10:00 am United States - Los Angeles or after on demand 75 mins
Ned Pyle, SMB Program Manager, Microsoft, John Kim, SNIA-ESF Chair, Mellanox, Alex McDonald, SNIA-ESF Vice Chair, NetApp

•Why latency is important in accessing solid state storage
•How to determine the appropriate use of networking in the context of a latency budget
•Do’s and don’ts for Load/Store access
Live online Apr 19 10:00 am United States - Los Angeles or after on demand 75 mins
Doug Voigt, Chair SNIA NVM Programming Model, HPE, J Metz, SNIA Board of Directors, Cisco


It had to come one day. After the initial and growing adoption of 10G Fibre Channel over Ethernet (FCoE) since the end of 2008, it was just a matter of time before the market introduction of the next speed level would materialize.
By Fausto Vaninetti, SNIA Europe Board Member.

The first switch capable of 40G FCoE appeared in the middle of 2013 but during 2016 a wider portfolio of 40G FCoE capable devices was brought to commercial fruition by some vendors. At first sight, 40G FCoE may seem just a speed bump as compared to its predecessor but a closer look shows a different story.
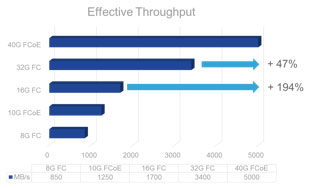
The original idea behind FCoE was network convergence and that is why FCoE technology started with 10G and not 1G bit rate. Having a single adapter, a single cable, a single switch for both LAN and SAN traffic seemed a good idea in terms of lowering cost and reducing administrative burden. When FCoE was first introduced, 8G Fibre Channel (FC) technology was already available but majority of deployments were still only using 4G FC. As a result, a 10G pipe offered a nice consolidation opportunity by bringing together native Ethernet traffic with Ethernet-encapsulated Fibre Channel traffic.
A few years after the availability of 10G FCoE capable adapters and switches, 16G FC became available. The convergence benefit provided by FCoE technology was still there, but the bandwidth advantage that FCoE could offer on top of 8G FC was now lost in favor of 16G FC. As a result, 10G FCoE saw a slowdown in adoption and remained confined to the place where it still makes a lot of sense: the access network. As a proof point of this, many blade chassis are nowadays sold with some type of embedded FCoE connectivity. This choice appears convenient since it reduces network adapter’s footprint on blade servers, minimizes cabling and shaves out overall cost. Rack mount servers, instead, are mostly sold with separate Ethernet and Fibre Channel adapters. As of now, market research indicates Fibre Channel traffic out of servers is using converged network adapters in approximately 30% of cases, leaving the rest to native FC host bus adapters.
The tangible savings when adopting FCoE are mostly coming from consolidation in the access, where server nodes connect to the network edge, but when you need to interconnect switches or connect to disk arrays, or simply when there is no interest in network convergence, 16G FC has won the majority of deployments. This is not to say 10G FCoE cannot be used for end-to-end multi-hop solutions, but not many organizations have embraced that deployment option.
The introduction of 40G FCoE could change the scenario again. In fact, 40G FCoE is supported by both switches and modular platforms and could fit organizations of different sizes. It also offers three times the bandwidth of 16G FC for approximately twice the price, so that it captures attention in terms of cost/Gbps ratio. All in all, when cabling simplification is accounted for, the total cost of ownership of 40G FCoE becomes even more interesting.
This means the window of opportunity for 40G FCoE is not going to reach an end when 32G FC will grow in popularity and both protocols are expected to be seen in use within datacenters.
With the continuous increase in processing power within compute nodes, bandwidth needs on servers keeps growing. Between 2015 and 2017, cloud service providers are expected to double their virtual machine density per host in order to improve their profitability. At the same time, new applications within enterprises will leverage the newly available processing power to push network needs beyond 10G. When consolidation is a priority, 40G adapters are more than adequate for transporting modern Data Center traffic and can be a valid alternative to deploying separate 16/32G FC HBAs and 10/40G NICs. As a result, since their commercial introduction in 2015, 40G FCoE converged network adapters have experienced a slowly growing market penetration.
With the continuous increase in processing power within compute nodes, bandwidth needs on servers keeps growing. Between 2015 and 2017, cloud service providers are expected to double their virtual machine density per host in order to improve their profitability.
At the same time, new applications within enterprises will leverage the newly available processing power to push network needs beyond 10G. When consolidation is a priority, 40G adapters are more than adequate for transporting modern Data Center traffic and can be a valid alternative to deploying separate 16/32G FC HBAs and 10/40G NICs. As a result, since their commercial introduction in 2015, 40G FCoE converged network adapters have experienced a slowly growing market penetration.
However, the future is a bit uncertain. The combined effect of an increased price pressure, real aggregate bandwidth needs out of servers and newly introduced network speeds are possibly casting a shadow on 40G adoption. In fact, chances are that 25G will be the next speed on servers after 10G becomes insufficient. The consequence of this explains why the sweet spot for 40G FCoE seems to be as a technology to interconnect network devices more than anything else. If 10G FCoE became notorious for convergence in the access network, 40G FCoE could become popular to interconnect the edge of networks to the core, leveraging the high bandwidth it can deliver. This approach seems very reasonable for IT departments that already embraced FCoE in the access but could be viable also for organizations that are relying on a native FC access network.
As bit rate increases, the complexity of circuitry, modulated light transmitters and receivers will grow and consequently another important aspect will influence decisions: the cost of the transceiver itself as compared to the cost of a network port on a switch. A multimode transceiver at 16G FC can be approximately 20-40% of the cost of a 16G FC port on a switch. These pricing considerations will have an impact on the speed of adoption for 32G FC transceivers on both servers and switches, but for sure they will not impede their use on inter switch links even during the initial ramp up phase for the higher bit rate. Moreover, 32G FC is expected to enjoy a growing success on the storage side as well. In many cases, network devices and disk arrays are not refreshed at the same time and there is a need for the newly purchased equipment to be able to work with the existing installed base. From this point of view, the main feature that will drive 32G FC adoption in place of the 40G FCoE approach will be its backward compatibility with 8G and 16G FC ports.
It is never easy to make predictions, but do not be surprised if during 2017 the situation for new deployments will see 10G FCoE remaining popular in the access and 40G FCoE and 32G FC both gaining traction for networking devices interconnection and trending up elsewhere. Rather than competing solutions, they seem to be the two faces of the same coin, clear representation of reliable, scalable, deterministic storage networking options.

Third-platform pillars such as social, mobile, big data and cloud are growing and companies are becoming increasingly digital. This creates a strain on the underlying IT infrastructure, and as this strain increases, businesses are needing infrastructure solutions that provide the agility and scalability to adapt to rapidly-changing business needs and IT dynamics.
By Bruce Milne, Chief Marketing Officer, Pivot3.

These companies are also looking for greater simplification of their IT environments to lower capital and operational expenses and better align IT with business outcomes. These emerging trends present new dependencies, which has led a growing amount of businesses across industries to adopt hyperconverged infrastructure (HCI) solutions to address a changing IT landscape and new business challenges.
HCI is the powerful, emergent technology that combines compute, storage, and storage networking on standard x86 hardware, effectively reducing or eliminating the need for traditional discrete IT components. Most HCI platforms feature automated deployment and orchestration features, pooled IT resources, single-pane-of-glass management, out-of-the-box flexibility, holistic scalability and predictive monitoring and analytics of an entire shared infrastructure.
Gartner predicts that HCI will represent more than 35 percent of total integrated system market revenue in just three years, building towards 67 percent of a $35 billion market in 2021. According to IDC Research, “Hyperconverged systems, which accounted for 8.7% of the larger converged system market in 2015, will increase at a five-year CAGR of 41.8%. Hyperconverged systems generated $1.4 billion in 2015 and is expected to grow to $5.9 billion in 2020, which translates to 32.3% of the market.”
What businesses need, and what HCI promises, is a new paradigm of datacenter economics and simplified management that can outperform traditional three-tier infrastructure and scale to meet the exponential growth of data generated by cloud computing and the internet of things.
To take advantage of this trend, CIOs and other technology leaders require solutions that meet the technical and operational requirements of the business, while reducing IT complexity and costs. HCI solutions must align to their prospective roadmap, and in most cases, it must integrate with a company’s existing infrastructure to avoid the sunken costs of abandoned IT resources.
Advertisement: DCS Awards
Further, HCI solutions must provide the scalability for broad application and stack support for datacenter modernization and infrastructure consolidation initiatives. Yet, not all HCI solutions are created equal and there can be great disparity between those that provide the flexibility and interoperability to satisfy scale-out and agile deployments for the merger of digital business and private or hybrid cloud infrastructures.
In a recent study by Technology Business Research (TBR), it was found that the biggest IT challenge prompting the purchase of HCI platforms was the cost structure of traditional IT environments, particularly as these organizations need to come online quickly with emerging line of business (LOB) and increasing workload needs. Both datacenter modernization and infrastructure consolidation require linear and modular scalability, characterized by the ability to scale out either compute and storage concurrently or independently, while also aggregating the performance and resource pools as new nodes are added. Unfortunately, most HCI solutions are not able to provide this.
Scale matters, but with each vendor claiming it, how can businesses evaluate options? At a high level, scaling doesn’t work in isolation; it must be approached holistically. At a more technical level, it’s about the underlying infrastructure. The marks of a truly scalable architecture are whether it is distributed or not, and does it simplify the scaling of infrastructure to accommodate evolving business needs. It must inherently aggregate resources and balance data placement and utilization across the cluster, resulting in simple, predictable, non-disrupting infrastructure scaling.
As more businesses turn to HCI to support their evolving needs, it is important to keep the following qualities and factors in mind when evaluating the scalability of various solutions available.
Resource Aggregation – Does the solution allow the enterprise to withstand the pressures that the modern user or application owner places on the system, no matter how great? Imagine a thousand individual sticks compared to a thousand sticks bundled together. Which one is easier to break?
Interoperability – Does the solution have the ability to present its storage anywhere? This gives it a great advantage over solutions which limit data services within a single cluster, which is pointless for an enterprise that wants to scale to massive volumes. These services must range widely across the whole system to truly deliver value to the enterprise.
Flexibility – Does the solution deliver storage-only or compute-only resources, yet still tether them to the cohesive HCI infrastructure? The solution should not dictate requirements to the customer or tie their critical data services to a specific node or hardware platform, but should instead provide the power of choice with the flexibility the customer needs to meet their specific requirements.
Quality of Service – With more resources and added performance comes greater responsibility to ensure that enterprise workloads get the resources they need, when they need them. The next phase of hyperconvergence will move beyond single workloads to run multiple mixed workloads through policy-based management.
Organizations shouldn’t have to think about whether their needs are a fit for hyperconvergence; rather they should be thinking about how to ensure their applications and workloads get the resources they need, when they need them, and in a dynamic matter.
This type of policy-based performance management goes beyond simply setting minimum and maximum caps on performance to address resource contention. A dynamic QoS, alongside the ability to scale holistically, is especially useful in multi-tenant environments in which multiple users or business units share the same system resources.
Hyperconvergence must provide the infrastructure agility to address a broader spectrum of application demands. As more organizations adopt HCI into their technology roadmaps, they must consider proven, real-world examples of performance, customer satisfaction, and the ability to scale while ensuring data protection and reducing costs.
Dynamic hyperconvergence – marked by scalability and managed with dynamic QoS – is the next step in the evolution of the software-defined data center with solutions that will provide continuous application delivery and economic models that can be optimized on the fly. This will provide the foundation needed to continually adapt to the changing needs of business.
How digital surveillance demands can be supported by the right storage
Cybercrime gets a lot of media attention. It’s new, it’s ever evolving and high profile hacks still have the power to shock us. Yet, don’t be distracted by thinking that old-fashioned face-to-face crime has been eradicated completely. Last year the cost of UK retail crime, for example, was £613m;[1] the largest since records began. Cybercrime was only responsible for a third of that. Of course, as many retailers move online, cyber security is a key concern, but it’s important to protect physical assets too, and more importantly guarding the well-being of staff.
By Geoff Barrall, CTO, Nexsan.

As well as being a deterrent, video surveillance allows organisations to identify suspicious and illegal behaviour before it’s too late. Advances in technology, such as the move from analogue systems to digital IP-based systems have led to a convergence of IT with physical security infrastructure, and the ability to monitor activities on a large scale.
It’s not simply a retail issue either. Heightened physical security concerns span across all industries including airports, governmental buildings, entertainment venues and financial institutions.
Increased camera resolutions are becoming a key strategic consideration for surveillance, providing the ability to cover far more area, zoom in on people or objects without loss of detail, and deliver sharp image quality for use by video analytics solutions. Many organisations require higher-resolution video to ensure compliance with insurance providers, maximise loss recovery and strengthen deterrence of criminal acts.
Unfortunately, high-resolution video also comes at a steep price, as more data is captured it requires increased capacity. High-definition video, for example, requires up to 20 times more storage capacity than lower-resolution video captured with older technology. But higher capacity requirements are only part of the challenge—HD recording also places enormous demands on the throughput performance of today’s surveillance storage solutions.
Simply put, a surveillance storage system’s video streaming bandwidth must be sufficient to consistently support and sustain write capabilities for multiple high-resolution feeds across a network. Note these bandwidth requirements can be daunting—just as an HD video requires vastly more capacity when it’s stored, it also demands far more bandwidth when it’s ingested into the storage system.
But that’s only part of the story; as noted above, a surveillance storage system must simultaneously support multiple high-resolution streams. That can mean recording dozens—sometimes hundreds—of parallel video streams, consuming huge amounts of bandwidth. What’s more, many surveillance environments can require 24×7 video monitoring, which boosts bandwidth utilisation even higher. Depending on the number, duration and actual resolution of the incoming video streams, a storage system may struggle to keep up, significantly increasing the risk of dropped frames.
By their very nature surveillance video images are transitory; should inadequate storage bandwidth cause frames to be dropped, any information contained within them is lost forever. As video evidence often plays key roles in civil and criminal proceedings, the loss of such information can have devastating financial and legal consequences.
Deploying a storage solution, that combines the enormous capacity and superior bandwidth that surveillance usage demands, requires a storage system utilising high-density architecture. Simply packing a conventional storage array with a multitude of high-capacity hard drives can yield vast amounts of capacity, but it will take up significantly more space, consume more energy and require more cooling than a properly engineered high-density array. More importantly, it will deliver lower performance per U than a high-density array.
The ability to deliver superior bandwidth in a space-efficient array is significant; because surveillance video solutions are deployed in a wide range of physical environments, they often must be installed in confined locations with little available floor space. Storage arrays that may present an acceptable footprint in conventional data centres are simply too bulky and inefficient for use in the cramped control rooms that confront many security professionals.
So, what should IT professionals look for in storage solution when it comes to digital surveillance?
The wealth of technological advancements has combined to offer organisations an extraordinary level of surveillance protection. An easy way to maximise ROI for a digital video surveillance system is to consider the investment in the storage platform as equally important. Taking full advantage of these surveillance advancements requires storage solutions that can deliver the scalability and performance needed to handle the hundreds of video streams and high definition video that modern DVS systems can generate, delivering secure, reliable and high quality protection 24/7.
[1] https://www.businesscrime.org.uk/publications/brc-retail-crime-survey-2015
It’s no news that cloud adoption has swiftly moved from an emerging technology to an established solution and IT requirement for all modern businesses. Cloud services have evolved to deliver new services to customers and increase business performance – organisations across the board are using the cloud for a range of purposes from testing beta applications to hosting critical workloads. Studies predict that 83% of data centre traffic will be cloud-based in three years (65% of data centre traffic is currently cloud-based).
By Michael Moreland, server DRAM product marketing manager at Crucial.

With growing cloud adoption set to increase server workload demands, it’s no surprise that 47% of IT pros plan to add more server memory this year, even though half of all their servers were already running at the maximum installed memory capacity.
When it comes to server workloads, your memory is either adequate or inadequate. If you have an adequate amount of memory for your server workloads, you won’t need to worry about RAM because other challenges will be more pressing. However, if you have inadequate memory, your servers and all the applications that run on them will slow down to a crawl because DRAM feeds your CPUs.
More importantly, memory can help solve the following top five workload constraints for IT Pros:
Getting the most out of shrinking IT budgets is dependent on comparing acquisition cost to total cost of ownership (TCO). If you increase your server’s efficiency, you ultimately decrease its TCO because you’re getting more performance out of your servers in the same period. Because memory feeds processing cores, it’s one of the most effective ways to ensure your CPUs are more efficient and productive, enabling you to handle fluctuating workloads without having to invest in new servers.
Virtualised server workloads need to maintain consistent quality of service (QoS) and eliminate fluctuating variances. More RAM helps remove service variance because it provides additional resources for virtualised applications to store and use active data. As an unpredictable workload spikes it quickly exhausts available memory. This forces the system to scramble for available resources, resulting in performance drops and disk thrash. More memory solves this problem by giving your applications more flexibility to meet fluctuating workloads.
What is the minimum amount of servers you need to achieve your workload requirements? Thinking about questions like this helps lighten your enterprise footprint because every idle server costs you more. Take for example, using 5 maxed-out servers to accomplish the workload of 10 half-full servers would save power, cooling, and software licenses. Especially when your floor space is at a premium you can only scale up, in other words, increasing your server’s installed memory capacity to get as much use out of the box and feed as many VMs as possible.
Hosting an uptake of new users on servers requires more memory to maintain the same QoS, which is similar to the constraint given by limited floor space. By adding more RAM, you achieve more flexibility and increase the servers’ ability to manage unpredictable workload requirements caused by sudden growth spurts in your userbase.
Although installing memory in a server increases its overall power consumption, the total amount of consumed energy will be less than using several partially full servers to deliver the same level of performance. More RAM helps your servers use power in the most efficient way possible from a workload perspective. Finally, if you are using fewer physical servers, the overall power and cooling costs will less.
When it comes to server workloads, it’s important to future-proof – and doing so through upgrading your severs’ memory doesn’t necessarily have to kill your IT budget. It’s possible to get the most out of your IT budget by identifying high growth, business critical applications and installing 32GB modules to deliver optimal server performance and scalability at a lower price than that of multiple lower-density modules.
By installing enough memory, you can deliver optimal performance today and for the foreseeable future – and potential server challenges such as growing cloud infiltration won’t be a bigger problem than it should be. Server memory is a long-term investment that looks beyond the here and now – it’s about future-proofing your servers for future workloads.
As we welcome in the New Year, we are already seeing multiple blogs prognosticating 2017 trends, setting priorities and suggesting resolutions. We are also rapidly approaching the 2017 budget cycle.I am sure you will read many articles concerning new plans or resolutions for the coming year, but this one will be about an old resolution: IT Disaster Recovery.
By Monica Brink, Director of Marketing, iland.

When disaster strikes, organisations need to be able to recover IT systems as quickly as possible. Not having a disaster recovery plan in place can put the business at risk of high financial costs, reputation loss and even greater risks for its clients, customers and employees. Despite this, each year business continuity gets cut from the budget and companies continue to fail to invest in DR.
Here are five common objections that continue to dominate the disaster recovery budget discussion and why IT leaders need to refute them:
It's going to cost a fortune.
Business leaders often assume that Disaster Recovery is going to break the bank. When thinking about a robust Disaster Recovery plan, secondary data centres complete with HVAC, as well as second copies of all servers, storage and networks comes to mind. Furthermore, there is a general misconception that systems are sitting idle, just waiting for disaster to strike, and all this is before even considering the maintenance costs involved.
However, having a robust disaster recovery plan in place doesn’t have to mean investing in a secondary data centre. Technology has developed massively in the last few years and there are now a number of different options that enable organisations to minimise the cost of DR without sacrificing the recoverability of IT systems. Cloud-based disaster recovery, often termed Disaster-Recovery-as-a-Service (DRaaS) enables failover of virtual machines to secure cloud locations. Often billed by VM or by TB of storage, DRaaS provides the flexibility to only pay for what you need. Having an on-demand pricing model means the costs are therefore remarkably low. With DRaaS, organisations do not have to sacrifice the ability to fail over in a time of need and are also gaining the benefits of security and compliance within the cloud platform. In most cases, it has now become a lot more cost effective for organisations to invest in DRaaS rather than building and managing a secondary data centre.
But I have backup down the hall.
Some businesses may argue they are covered in case of disaster because they have a robust backup system in the form of an on-site server. If you back up each day to this, then surely you do not need DRaaS?
However, backup ‘down the hall’ is not immune from a localised disaster and additionally, should disaster strike, restoring data from back up takes hours, if not days. DRaaS is about minimising downtime. With DRaaS organisations can restore operations quickly (often in minutes or even seconds) and in a highly automated fashion. It can also be tested in advance so that if and when an issue does arise the infrastructure can be recovered at the push of a button as the failover system has been fully tested and proven.
The difference between back up and DR is significant and both can co-exist happily in a secure and compliant business continuity strategy.
We don't get bad weather!
With headlines focusing on big natural disasters, many believe that if they live in a region with generally good weather, they are exempt from the danger of an outage. This is a false sense of security, however, as the ‘disaster’ in disaster recovery doesn’t just refer to natural disasters caused by weather events.
Outages are increasingly more likely to be the result of human error or malicious attacks – just look at the increase in ransomware attacks we’ve seen on businesses over the past year. Organisations are also susceptible to power outages, upgrade problems or bad coding.
Incidents such as these are completely out of an IT team’s control. It is therefore vital that there is a robust Disaster Recovery plan in place to be able to recover when the inevitable happens.
This objection is for the most part unrealistic. Generally, people do not like talking about outages. Usually it is not a case of an organisation not experiencing outages, it is more likely that these outages do not get fed back to senior leadership.
Whilst some smaller outages may go unnoticed and leave a business moderately unscathed, over the course of a week, a month or a year downtime adds up and ultimately becomes expensive, having an unplanned effect on revenue. In addition to this, downtime can impact reputation, customer loyalty and employee productivity.
When it comes to outages organisations need to be more transparent in their approach; utilise the data on outages, attacks, maintenance windows, patch and upgrade problems that exist in your IT department to implement a reliable and effective DR strategy.
The final objection is ‘we don’t need a robust DR plan because we can deal with a few minutes of downtime’. Businesses may question how much downtime will really impact the business and argue that since all their systems are not customer facing, it isn’t the end of the world.
However, downtime can actually have a very significant impact on revenue. In the last decade, our expectations as consumers and IT end users have changed. We expect everything instantly and business is increasingly conducted online. As a result, people are more sensitive to an interruption in service and having even a few minutes downtime could have a massive impact on customer loyalty, not to mention bottom line revenue.
The impact of downtime is tremendous. A 2016 survey conducted by Opinion Matters on behalf of iland showed that, for 69% of respondents, downtime of only minutes would have highly disruptive or catastrophic business impact. Additionally, Gartner has reported that 72% of firms had to use their IT disaster recovery plans** and estimates in their 2016 Magic Quadrant for Disaster Recovery as a Service that the DRaaS market will nearly triple in the next three years to a revenue point of $3.4 billion by 2019.
A robust Disaster Recovery strategy is vital to running a successful and secure business. If any of these five objections have influenced your decision to invest in a business continuity plan, it may be time to reconsider. Without an IT Disaster Recovery plan, you run the risk of incurring serious business losses through outages, hours of downtime, lost data, and negative impact on reputation. Make 2017 the year that DR is put firmly back in the IT budget.
**Gartner 2015 Business Continuity Management survey
Growing connectivity, competition and consumer power have left business leaders grappling with unprecedented change.
By Matt Leonard, Solution Engineering & Marketing Director, CenturyLink EMEA.

An environment in which organisations must disrupt others before they themselves are disrupted, means that new products, business models and ecosystems are required. Growing competition and consumer power has eroded traditional product-based advantages, forcing companies to shift into a new battleground – that of customer experience. And this requires an integration of the entire business in order to demonstrate value at each and every customer touchpoint.
As a result, ‘digital transformation’ has not only become the latest buzzword but is now also the cornerstone of many business strategies.
Despite this however, there may still be a lack of complete understanding and agreement around what the term actually means. Fundamentally, digital transformation is about the application and exploitation of technology in all aspects of an organisation’s activity. Success doesn’t necessarily come from the technology itself, but rather from the organisation’s ability to implement that technology innovatively by rethinking its business model, strategy, culture, talent, operating models and processes.
It’s not hard to understand why CIOs at many organisations are changing their IT strategies in an attempt to maximise the benefits of technology. Gone are the days when established enterprises could rely solely on their size as a critical success factor. To be successful today, companies need to be responsive, adaptable, agile, insight-driven, connected AND collaborative.
And in many cases it’s the smaller, more nimble start-ups that are best placed to take this approach to growing their enterprises and better serving their clients.
To keep up with these new, disruptive companies, CIOs should be looking at ways of building a digital transformation strategy that drives genuine value for the enterprise, rather than simply taking a “me too” approach based on what their peers are doing or following a barked order from the CEO to “use the cloud”.
Ten years ago, consumers were used to paying for products and services up front or on an annual subscription basis. Nowadays, though, a technological and material shift has led to a culture of on-demand consumption.
Customers today seek services and products from companies that align with their preferences and values as individuals, and are willing to share information in exchange for more personalised offerings.
This new way of purchasing and consuming products and services has filtered through into the business community, and many businesses are using digital transformation as a vehicle to strive for a “single complete view of the customer” that will allow them to hyper-personalise their interactions.
Beyond ensuring that the data analytics are in place that will provide this insight, businesses - whether serving a B2B or a B2C community – also need to work fast on “SaaSifying” their products, and ensuring their applications are on a sufficiently robust platform to be able to cope with peaks and troughs in demand.
However, when it comes to digitally transforming the portfolio of applications an organisation owns and manages, the most challenging will often be those that aren’t based in the cloud, they are either colocated or housed on on-premise legacy infrastructure. Deciding what to do with these applications in order to gain greater agility or faster response times, while juggling requirements such as regulation, data sovereignty, security, integration complexity, contractual certainty, and service level agreements into consideration, can be a little like playing three dimensional chess.
And the more thought a CIO gives to these legacy applications and the challenges they represent, the further away that nirvana of being responsive, adaptable, agile, insight-driven, connected and collaborative starts to feel.
Faced with increasing competition from emerging start-ups, the larger corporates are considering what they can do to behave more like their newer counterparts. After all, no-one wants to be the next business to get ‘Ubered’.
The solution – or so they believe – is to embark on a digital transformation programme. This is not as straightforward as simply investing in more tech though as, historically, major corporations have always been at the forefront of tech investment. Simply adding on more technology layers will not fix a broken process or an inefficient culture.
While major corporations are right in attempting to mirror some of the positive traits that nimble start-ups exemplify, simply embracing ‘digital’ without knowing why they’re doing it, or what they want to achieve, is not the answer.
Focusing on the back-end technology and how to implement it, rather than the desired business outcomes can either result in investment being wasted on technology that drives no specific business value, or can lead to complete inertia – leaving the enterprise at risk of being ‘Ubered’.
The world’s leading digital enterprises aren’t a success simply because they run on flexible, scalable cloud platforms, for example. Rather, their success lies in the fact that they have uncovered a problem and have taken the smartest, most efficient approach to solving it.
Mistakes can frequently be made when organisations follow their competitors feet first into the cloud without proper thought and planning. There’s no “one size fits all” approach to which environment is most suitable for a move to the cloud, so consideration should be given as to how it fits in as part of a broader transformation strategy, and how it meets the demands of the business and its customers.
Public cloud, for example, is best suited for workloads that require flexible or short term computing resources, that are highly scalable and have the ability to switch on and off easily. Private cloud, on the other hand, is more suitable for workloads that require predictable levels of resources for at least three years, and more complex security requirements. Grid computing with three year workloads can run in a custom security environment using managed hosting, saving money over cloud and supplemented with bare metal for short term needs. Some older applications at the end of their lifecycle may be best left alone or moved into a colocation environment for integration into other venues. The key to a successful digital transformation with a legacy IT estate is a hybrid IT model with the flexibility to choose the best execution venue for each application and integrate into other environments.
It’s becoming increasingly commonplace in today’s landscape for corporations with a strategy encompassing both public and private options to require a number of cloud providers. While this approach can offer a greater level of flexibility and efficiency, it can be a lot for the CIO to juggle. A less stressful option for CIOs of enterprises that rely on multiple cloud providers is to seek a managed services provider to provide a management layer ensuring that promised savings materialise, and that complexity is kept to a minimum.
Change is inevitable and businesses must either take steps to adapt or be overtaken by their more agile, flexible and versatile competitors.
When a business decides to embark on digital transformation, it’s important that consideration is given as to where that business currently is, what it wants to achieve, and how it will address the challenges and opportunities it faces during that transformation.
Customer demands for the way they purchase and consume products and services have changed forever, and the demands that this puts on a business have changed with them.
In ensuring that its customer-facing applications are up to the task, a business must think long and hard about any cloud migration strategy. Rather than “putting them in the cloud”, it’s important to ensure that the environment in which these application are housed, and how they’re managed are right for the business.
Researchers have estimated that 25 years ago, around 100GB of data was generated every day. By 1997, we were generating 100GB every hour and by 2002 the same amount of data was generated in a second. We’re on trajectory – by 2018 – to generate 50TB of data every single second – the equivalent of 2000 Blu-ray discs – a simply mind-boggling amount of information.
By Barry Bolding.

While the amount of data continues to skyrocket, data velocity is keeping pace. Some 90% of the data in the world was created in the last two years alone, and while data growth and speed are occurring faster than ever, data is also becoming obsolete faster than ever.
All of this leads to substantial challenges associated with identifying relevant data and quickly analyzing complex relationships to determine actionable insights. Which certainly isn’t easy, but the payoff can be substantial. CIOs gain better insight into the problems they face daily, to ultimately better manage their businesses.
Predictive analytics has become a core element behind making this possible. And while machine learning algorithms have captured the spotlight recently, there’s an equally important element to running predictive analytics – particularly when both time-to-result and data insight are critical: high performance computing. “Data intensive computing,” or the convergence of HPC, big data and analytics, is crucial when businesses must store, model and analyze enormous, complex datasets very quickly in a highly scalable environment.
Firms across a number of industry verticals, including financial services, manufacturing, weather forecasting, life sciences & pharmaceuticals, cyber-reconnaissance, energy exploration and more, all use data intensive computing to enable research and discovery breakthroughs, and to answer questions that are not practical to answer in any other way.
There are a number of reasons why these organizations turn to data intensive computing, three of which are outlined below:
In manufacturing, the convergence of big data and HPC is having a particularly remarkable impact. Auto manufacturers, for example, use data intensive computing on both the consumer side and the Formula 1 side. On the consumer end, the auto industry now routinely captures data from customer feedback and physical tests, enabling manufacturers to improve product quality and driver experience. Every change to a vehicle’s design impacts its performance; moving a door bolt even a few centimeters can drastically change crash test results and driver safety. Slightly re-curving a vehicle’s hood can alter wind flow which impacts gas mileage, interior acoustics and more.
In Formula 1 racing, wind flow is complicated by the interplay of wind turbulence between vehicles. During a race, overtaking a vehicle – for example – is difficult by nature. Drivers are trying to pass on a twisting track in close proximity to one other, where wind turbulence becomes highly unpredictable. To understand the aerodynamics between cars travelling at over 100 miles per hour on a winding track, engineering firms have turned to data intensive computing in order to produce images like the one below:
Simulation and data analysis enables auto manufacturers to make changes far more quickly than when running physical tests alone, as they try to address new challenges by altering a car’s material components and design layout. On the consumer side, this leads to the development of more fuel-efficient and safer vehicles. On the Formula 1 side, modeling is key to producing safer and faster supercars.

The promise of data intensive computing is that it can bring together the technologies of the newest data analytics technologies with traditional supercomputing, where scalability is king. This marriage of technologies empowers the development of platforms to solve the most complex problems in the world.
Developed for supercomputing, globally addressable memory and low latency network technologies bring the ability to achieve new levels of scalability to analytics. Achieving application scalability can only be done if the networking and memory features of the systems are large, efficient and scalable.
Notably, two apex cloud virtues are feature richness and flexibility. To maximize these virtues, the cloud sacrifices user architectural control and consequently fails to meet the challenge of applications that require scale and complexity. Companies across all different verticals need to find the right balance of usage between the flexibility of cloud and the power of scalable systems. Finding the proper balance results in the best ROI and ultimately segments leadership in a highly competitive business landscape.
Just as the cloud is a delivery mechanism for generic computing, now data intensive, scalable system results can be delivered without necessarily purchasing a supercomputer. Deloitte Advisory Cyber Risk Services – a breakthrough threat analytics service – takes a different approach to HPC and analytics. Deloitte is using high performance technologies of Spark, Hadoop, and the Cray Graph Engine, all powered by the Urika-GX analytics engine to provide insights into how an organization’s IT infrastructure and data looks to an outside aggressor. Most importantly this service is available through a subscription-based model as well as through system acquisition.
Deloitte’s platform combines supercomputing technologies with a software framework for analytics. It is designed to help companies discover, understand and take action against cyber attackers, and the US Department of Defense currently uses it to glean actionable insights on potential threat vectors.
In the end, the choice to implement a data intensive computing solution comes down to the amount of data an organization has, and how quickly analysis is required. For those tackling the world’s most complicated problems, gaining unknown insights into data provides a distinct competitive advantage. Fast-moving datasets help spur innovation, inform strategy decisions, enhance customer relationships, inspire new products and more.
So if an organization is struggling to maintain its framework productivity, data intensive computing may well provide the fastest, most cost-effective solution.
With the number of students enrolling at European universities continuing to grow, institutions are under increasing pressure to deliver high performance and continually available IT services to support study. As a result, universities are investing more strategically in virtualised workloads and servers in order to enhance IT performance.
But how does virtualisation work in the higher education sector? What are the particular challenges faced by universities, and how are they implementing virtualised environments to deliver better IT services?
Tintri has a lot of experience of working with universities that are utilising Virtualised Desktop Infrastructures (VDI) and consolidating servers to shrink their IT footprints, decrease power consumption and accelerate their applications. These higher education institutions are investing in virtualisation to more effectively balance performance and cost.
One area that is often overlooked is storage but it can have a significant effect on VDI performance. Unlike traditional legacy storage, Tintri’s VM-aware storage operates seamlessly at the VM level, helping departments at universities to streamline their IT operations and offer improved quality of service (QoS). The University of Hull in the UK, University of Maastricht in the Netherlands and the University of Paderborn in Germany have all been using VM-aware storage as part of their VDI strategies.
The University of Hull was experiencing an increased demand on its storage generated by rapid growth of its email environment, extensive research at the institution and vast amounts of multimedia recordings. Responsible for supporting the IT needs of over 20,000 staff and students, the University needed greater storage to meet projected growth requirements for a minimum of three years. It needed a solution that would bring better performance, enhanced resiliency and more manageability.
After choosing and deploying Tintri - which the University’s data storage manager Craig Stephenson notes was ‘even simpler than Tintri promised’ – the IT environment’s critical applications were migrated to the new systems and responsibility for storage moved over to an external team. This gave the University greater operational freedom to focus on more important issues, such as launching its new student information system. Stephenson concludes: “To date, Tintri has met or surpassed all of our expectations for performance, manageability and resiliency. As a result, Tintri will be our default storage platform for our virtual systems going forward.”
When Maastricht University in the Netherlands required a new IT environment because its existing system was reaching end-of-life, the University’s IT team decided to look for more innovative storage and software options that would improve the performance of the campus-wide virtual desktop deployment. It chose Tintri because it delivered much higher IOPS at a significantly lower price. “The Tintri deployment went very quickly,” comments Lucien Haak, IT team manager at Maastricht University. “We enlisted the help of the Tintri Professional Services organisation and the entire process took less than two hours.”
The University’s virtual desktop environment is now running much faster on the VMware and Tintri platform – with approximately 80% performance improvement - and the IT team has scaled the deployment to provide 1,100 concurrent VDI session for students. “With Tintri, we don’t have to spend a lot of time managing our storage environment anymore,” Haak explains. “We are now recommending the VM-aware system to other universities in the Netherlands“.
Tintri’s technology has also been deployed by The University of Paderborn in Germany. With large databases, such as the University library search engine catering to over 20,000 students and 216 professors, the institution was looking to improve the backup times of its very high performance applications.
Christopher Odenbach, server and system administrator at The University of Paderborn comments: “We were absolutely amazed at how easy it was to implement the system and integrate it with our infrastructure. We were also impressed with how transparent it is. You can see every virtual machine with every virtual disk, including specific IOPS on the storage. This was something completely new to us.”
With the University’s previous LeftHand systems, it could only see performance at the volume level, and each volume had 30 to 40 virtual machines. “If one VM went crazy and started churning out thousands of IOPS, we couldn’t see which VM was doing this,” Odenbach explains. “With Tintri, we can see exactly where we are having an issue and can fix it quickly.”
The Tintri systems are providing the high performance needed for all of the University’s infrastructure. “We were absolutely amazed at how simple it was to integrate, how fast it is compared to other systems, and how transparent the systems are. Switching to Tintri was clearly a smart decision for a University that wants to be known as a leader in the information society,” Odenbach concludes.
In summary, Tintri has helped educational institutions across EMEA gain greater visibility into their environments, guarantee application performance and drive material value. VM-aware storage brings the flexibility, scalability and manageability required by such high-profile academic institutions.
The Internet of Things has huge potential in the enterprise space as it continues to feed peoples’ appetite for being as connected as possible.
By Richard Agnew, VP NW EMEA at Veeam.

The ever-increasing network of connected devices and sensors is already revolutionising our daily lives but we’ve really only scratched the surface of its potential. Research firm Gartner projected that all services connected to the IoT would be worth around $235 billion last year but, with an estimated 20.8 billion devices to be connected to the internet by 2020, IoT is still in its infancy and has plenty of room for growth.
The fledgling fleet of IoT devices currently on the market already allow people to control their household and monitor their health anytime and anywhere. While the healthcare sector has also been quick to adopt connected devices to monitor health information.
As businesses become more dependent on IoT services and solutions it becomes increasingly important to ensure they are not interrupted. Nothing other than 24.7.365 availability will be acceptable to businesses and users, and failure to deliver this Always-On access may severely hamper its adoption.
Financial loss is a serious threat to businesses that cannot guarantee service availability around IoT devices. According to the Veeam Availability Report, downtime costs enterprises an average of $16 million a year, while more than two-thirds of IT decision makers (68 percent) acknowledge that it can affect customers’ confidence in their organisation.
One possible way of avoiding this is ensuring regular backups and snapshots from which businesses can restore their data. It’s also vital to ensure the increased flow of connected device data is protected and secure at all times. Businesses must deploy near-continuous data protection, verify their protection to guarantee recovery, and use appropriate encryption tools to protect against unauthorised access.
Forward-thinking businesses are increasingly incorporating availability into their data centre strategies and modernisation plans. Very few applications are not deemed ‘mission-critical’ by a business or its customers, which means protecting data using the 3-2-1 rule – keeping 3 different copies of data, on 2 different media, with 1 of those locations off-site.
IT leaders must properly assess these platforms and ensure a solid availability strategy is in place to underpin their digital goals. Putting it at the centre of any IoT plans will enable innovation to flourish, thus increasing consumer trust and allowing businesses to reap the full benefits of going digital – including ensuring all pets get fed on time.