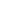Okay, so I haven’t seen the phrase being bandied around in the data centre or wider IT industry just yet, but there’s little doubt that, right now, organisations are focusing on technology not as a means in itself, but as a means to an end – the end being business transformation. And most of this (digital) transformation process revolves around the creation, use and storage of data, or information. With the GDPR legislation on the horizon, the idea of ILM has just become a whole deal more important.
Once upon a time in the storage networking industry, ILM was the next big thing. All the vendors were falling over themselves to offer ILM solutions (which didn’t really exist), and the importance of managing data throughout its lifecycle was understood, if not acted upon, by all.
Fast forward to today, and the importance of managing data is back at the top of the agenda. Only, this time, it’s not just the storage networking industry that sees ILM as important, but the whole data centre/IT industry. After all, every aspect of data centres and IT is, ultimately, to do with data logistics. And with IoT just around the corner, the idea of effective data management, or ILM, has never been so crucial.
When the GDPR does (finally!) arrive, ILM will need to take on a whole new dimension. It will no longer be enough for an organisation to have some vague idea as to what data it has created, where it came from, what it has done with it, where it’s stored and when, if ever, it was deleted. No, accurate, open record keeping, available for examination by customers as well as regulators, along with the actual data records themselves in many cases, demands a whole new level of data management.
For the time being, there seems to be a whole wave of GDPR-related scaremongering going on throughout the data centre/IT industry. Yes, compliance and security are vitally important to ensure that you do not fall foul of the new legislation. However, rather than do the minimum to ensure compliance, why not take the GDPR ‘frenzy’ as an opportunity to overhaul your overall data centre/IT infrastructure to ensure that you have the best possible hardware and software to provide the optimised ILM experience.
After all, GDPR is all about the need for proper data management, and no one should be complaining about that!
-l1uge6.jpg)

Research from The Green Grid highlights that while most view a broad range of KPIs as useful, many are yet to implement them.
IT leaders must use a diverse range of metrics to attain the level of detailed measurement and analysis required to ensure long term sustainability and to drive data centre efficiency. This is according to Roel Castelein, EMEA Marketing Chair for The Green Grid, who suggests it is important to adopt a three dimensional approach in order to gain a complete view of a data centre and to improve the effectiveness of their operations.
The latest annual Data Centre Industry Survey from Uptime Institute reveals that, in many cases, IT Infrastructure teams are still relying on the least meaningful metrics to drive efficiency. The majority of IT departments are positioning total data centre power consumption and total data centre power usage as primary indications of efficient stewardship of environmental and corporate resources.
Additionally, research from The Green Grid, which surveyed 150 IT decision makers, demonstrates that while most recognise that a broad range of KPIs are useful in monitoring and improving their data centre efficiency, many are yet to implement them. Key findings include:
88 per cent view Water Usage Effectiveness (WUE) as a useful metric but only 27 per cent use this; 82 per cent view Power Usage Effectiveness (PUE) as a use metric but only 29 per cent use this; 80 per cent view Data Centre Infrastructure Efficiency (DCiE) as a useful metric but only 59 per cent use this; 77 per cent view Data Centre Predictive Modelling (DCPM) as a useful metric but only 15 per cent use this; 77 per cent view Data Centre Energy Productivity (DCEP) as a useful metric but 31 per cent use this; 71 per cent view temperature monitoring as a useful metric but 16 per cent use this; 70 per cent view Carbon Usage Effectiveness (CUE) as a useful metric but 35 per cent use this.
Roel comments: “Our research clearly shows that there is an understanding of how useful each KPI can be. However, the reason for limited adoption may come down to the perception that implementation will have a negative impact on CAPEX and also OPEX. This doesn’t have to be the case. With enough resourcefulness and data centre know-how, you don’t necessarily have to be a big-spender to increase your data centre efficiency and therefore save money and do less harm to the environment. Oversimplifying or even focusing on a single metric can create wider business issues as key factors are ignored – the impact is however very real.”
“There’s no doubt that data centre energy consumption is a critical aspect of the maintenance, improvement, and operational planning of any facility. However, data centre providers need to harness an array of metrics in order to gain a holistic view of their facilities and to drive environmental stewardship. Poor measurement is just as bad as no measurement at all. Therefore, IT leaders need to expand from a single-metric view and include broader technical metrics and KPIs into a meaningful message. This will also help all parties within an organisation to improve their understanding. In essence, organisations should focus on metrics that range from detailed technical information right through to key performance efficiency indicators.
“By way of example, cooling is a key chokepoint in data centre efficiency, a place where significant cost savings and sustainability progress can be made with the judicious application of meaningful analysis, metrics and clever ideas. As such, a key metric here to take into consideration is Water Usage Effectiveness (WUE). Organisations should also be considering Carbon Usage Effectiveness (CUE) as well as the data centre lifecycle, taking into account how best to dispose of e-waste,” concludes Roel.
Despite the rising complexity of IT, respondents see promise in DevOps to help achieve future mission success. Download the full 2017 Splunk Public Sector IT Operations Survey on the Splunk website.
The survey polled a wide range of Public Sector IT professionals from national and local government agencies, national security, emergency services, higher education institutions and aerospace and defense. A converging host of factors and trends including constantly shifting budgets, changing regulatory compliance and modernisation initiatives have contributed to declining confidence, but emerging technologies focused on automation and increased visibility are helping Public Sector organisations today. Among the key findings, at least 60 percent of respondents felt as or less confident in carrying out their responsibilities in the following areas than they did 12 months ago:
Handling the scale and complexity of IT operationsAssuring performance and availability to consistently meet service level agreementsPinpointing root-causes and sources of failure quicklyEnsuring efficiency of IT operationsMigrating workloads and applications to the cloud
“The confidence gap we are seeing maps to other industry and government technology trends including growing public scrutiny, ever-present resource limitations and rapidly increasing expectations of technology by end-users. There’s never been a more important time for public sector organissations to embrace analytics to help them face and overcome these challenges with data,” said Larry Ponemon, chairman and founder of the Ponemon Institute. “It’s a challenging time to work in Government IT, but there are plenty of reasons to be hopeful for the future. It’s not surprising public sector IT leaders are looking to analytics, cloud and DevOps to help accelerate IT performance and management.”
IT Operations in Constant, Reactive Fire Drill Mode Due to Silos and Lack of Visibility
The survey also highlighted reasons for the overall loss of confidence across the Public Sector. Respondents felt that siloed IT systems and technologies, and an inability to integrate those systems (72 percent), were keeping them in a constant reactive state rather than being able to proactively plan for the future. IT managers also cited the lack of end-to-end visibility (73 percent) and too many alerts and false-positives (55 percent) among the biggest threats to service delivery along with a lack of skills, expertise and resources to effectively accomplish their jobs. Even where analytics tools were in place, most respondents felt they were ineffective at helping quickly pinpoint issues and determine root causes (78 percent).
As a result of limited visibility, overly manual processes and alert fatigue, the survey also found that the average system outage took 44 hours to resolve, while requiring 12.5 staff remembers to restore operational status to IT systems. This extended length of time and confusion often puts IT operators further underwater as they struggle to find the balance of executing on day-to-day operations while setting long-term proactive IT strategy.

Alert Logic has published the results of a comprehensive research, “Cybersecurity Trends 2017 Spotlight Report,” that explores the latest cybersecurity trends and organisational investment priorities among companies in the UK, Benelux and Nordics.
Conducted amongst 317 security professionals, the survey indicates that while cloud adoption is on the rise, the top concern is how to secure data in the cloud and protect against data loss (48 per cent). The next two biggest priorities for security professionals were threats to data privacy (43 per cent) and regulatory compliance (39 per cent).
The study also examined the top constraints faced by these organisations in securing cloud computing infrastructures. The study found that organisations lack internal security resources and expertise to cope with the growing demands of protecting data, systems and applications against increasingly sophisticated threats (42 per cent). This is closely followed by a desire to reduce the cost of security (33 per cent), moving to continuous 24x7 security coverage (29 per cent), improving compliance (24 per cent) and increasing the speed of response to incidents (20 per cent).
Public cloud platform providers like Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform offer many security measures, but organisations are ultimately responsible for securing their own data and the applications running on those cloud platforms.
According to Verizon’s recent security report, attacks on web applications are now the no. 1 source of data enterprise breaches, up 300 per cent since 2014. Similarly, the report found cybersecurity professionals – more than half of survey participants – to be most concerned about customer-facing web applications introducing security risk to their business (53 per cent). This is followed by mobile applications (48 per cent), desktop applications (33 per cent) and business applications such as ERP platforms (31 per cent). Application related breaches have negative consequences and can lead to revenue loss, significant recovery expense, and damaged reputation.
“Web applications are the most significant source of breaches for organisations leveraging cloud and cloud hybrid computing infrastructures,” said Oliver Pinson-Roxburgh, EMEA Director at Alert Logic. “They are complex, with a large attack surface that can be compromised at any layer of the application stack and often utilise open source and third-party development tools that can introduce vulnerabilities into an enterprise.”
Organisations can implement incentives to prevent gaps in the security policy of an application or to avoid vulnerabilities in the underlying system that are caused by flaws in the design, development, deployment, upgrade, maintenance or database of the application. Additionally, many businesses turn to cloud security vendors with a “products + services” strategy rather than technologies alone to fight web application attacks. Businesses increasingly find that a combination of cloud-native security tools provided in combination with 24x7 security monitoring by security and compliance experts is the best way to secure their sensitive data – and the sensitive data of their customers – in the cloud.
“A multi-layer web application attack defence is the cornerstone of any effective cloud security solution and strategy,” said Pinson-Roxburgh.

Software-defined wide area network (SD-WAN) solutions have only been commercially available for a few years, but the technology's ability to address pressing enterprise networking needs has led to remarkable growth. A new forecast from International Data Corporation (IDC) estimates that worldwide SD-WAN infrastructure and services revenues will see a compound annual growth rate (CAGR) of 69.6% and reach $8.05 billion in 2021.
The most significant driver of SD-WAN growth over the next five years will be digital transformation (DX) in which enterprises deploy 3rd Platform technologies, including cloud, big data and analytics, mobility, and social business, to unlock new sources of innovation and creativity that enhance customer experiences and improve financial performance. DX generally increases network workloads and elevates the network's end-to-end importance to business operations.
Another factor driving the growth of SD-WAN is the continued rise of public cloud-based software-as-a-service (SaaS) applications. The increase in SaaS adoption for business applications throughout the enterprise disrupts the prominence of MPLS-based WAN connectivity to the branch. SD-WAN is increasingly leveraged to provide dynamic connectivity optimization and path selection in a policy-driven, centrally manageable distributed network architecture.
Finally, the growth in SD-WAN will benefit from the broader acceptance, and adoption, of software-defined networking (SDN) throughout the enterprise. As virtualization, cloud management, and SDN continue to gain traction throughout enterprise networks, SD-WAN will benefit from this paradigm shift and receive increasing consideration.
"SD-WAN is not a solution in search of a problem," said Rohit Mehra, vice president, Network Infrastructure at IDC. "Traditional WANs were not architected for the cloud and are also poorly suited to the security requirements associated with distributed and cloud-based applications. And, while hybrid WAN emerged to meet some of these next-generation connectivity challenges, SD-WAN builds on hybrid WAN to offer a more complete solution."
SD-WAN leverages hybrid WAN, but includes a centralized, application-based policy controller; analytics for application and network visibility; a secure software overlay that abstracts the underlying networks; and an optional SD-WAN forwarder (routing capability). Together these technologies provide intelligent path selection across WAN links, based on the application policies defined on the controller.
The benefits of SD-WAN include cost-effective delivery of business applications, meeting the evolving operational requirements of the modern branch/remote site, optimizing software-as-a-service (SaaS) and cloud-based services such as UC&C, and improving branch-IT efficiency through automation. These benefits have resonated across the spectrum of enterprise IT and service providers alike, ensuring a broad-based uptake for this new paradigm in WAN architectures.

Worldwide IT spending is projected to total $3.5 trillion in 2017, a 2.4 percent increase from 2016, according to Gartner, Inc. This growth rate is up from the previous quarter's forecast of 1.4 percent, due to the U.S. dollar decline against many foreign currencies (see Table 1.)
"Digital business is having a profound effect on the way business is done and how it is supported," said John-David Lovelock, vice president and distinguished analyst at Gartner. "The impact of digital business is giving rise to new categories; for example, the convergence of "software plus services plus intellectual property." These next-generation offerings are fueled by business and technology platforms that will be the driver for new categories of spending. Industry-specific disruptive technologies include the Internet of Things (IoT) in manufacturing, blockchain in financial services (and other industries), and smart machines in retail. The focus is on how technology is disrupting and enabling business."
The Gartner Worldwide IT Spending Forecast is the leading indicator of major technology trends across the hardware, software, IT services and telecom markets. For more than a decade, global IT and business executives have been using these highly anticipated quarterly reports to recognize market opportunities and challenges, and base their critical business decisions on proven methodologies rather than guesswork.
Table 1. Worldwide IT Spending Forecast (Billions of U.S. Dollars)
|
| 2016 Spending | 2016 Growth (%) | 2017 Spending | 2017 Growth (%) | 2018 Spending | 2018 Growth (%) |
| Data Center Systems | 170 | -0.3 | 171 | 0.3 | 173 | 1.2 |
| Enterprise Software | 326 | 5.3 | 351 | 7.6 | 381 | 8.6 |
| Devices | 630 | -2.4 | 654 | 3.8 | 677 | 3.6 |
| IT Services | 894 | 3.2 | 922 | 3.1 | 966 | 4.7 |
| Communications Services | 1,374 | -1.3 | 1,378 | 0.3 | 1,400 | 1.6 |
| Overall IT | 3,396 | 0.3 | 3,477 | 2.4 | 3,598 | 3.5 |
Source: Gartner (July 2017)
The worldwide enterprise software market is forecast to grow 7.6 percent in 2017, up from 5.3 percent growth in 2016. As software applications allow more organizations to derive revenue from digital business channels, there will be a stronger need to automate and release new applications and functionality.
"With the increased adoption of SaaS-based enterprise applications, there also comes an increase in acceptance of IT operations management (ITOM) tools that are also delivered from the cloud," said Mr. Lovelock. "These cloud-based tools allow infrastructure and operations (I&O) organizations to more rapidly add functionality and adopt newer technologies to help them manage faster application release cycles. If the I&O team does not monitor and track the rapidly changing environment, it risks infrastructure and application service degradation, which ultimately impacts the end-user experience and can have financial as well as brand repercussions."
IT spending increased in 2016, but only two of the top 10 IT vendors posted organic revenue growth. With revenue sources still tied to the Nexus of Forces (the convergence of social, mobility, cloud and information), some of the top 10 vendors will fare better in 2017 due to strength in mobile phone sales. Worldwide spending on devices (PCs, tablets, ultramobiles and mobile phones) is projected to grow 3.8 percent in 2017, to reach $654 billion. This is up from the previous quarter's forecast of 1.7 percent. Mobile phone growth will be driven by increased average selling prices (ASPs) for premium phones in mature markets due to the 10th anniversary of the iPhone and the increased mix of basic phones over utility phones. However, the tablet market continues to decline, as replacement cycles remain extended.

The growth of digital business and the Internet of Things (IoT) is expected to drive large investment in IT operations management (ITOM) through 2020, according to Gartner, Inc. A primary driver for organizations moving to ITOM open-source software (OSS) is lower cost of ownership.
While acceptance of OSS ITOM is increasing, traditional closed-source ITOM software still has the biggest budget allocation today. Moreover, complexity and governance issues that face users of OSS ITOM tools cannot be ignored. In fact, these issues open up opportunities for ITOM vendors. Even vendors that are late to market with ITOM functionality can compete in this area," said Laurie Wurster, research director at Gartner.
Gartner believes many enterprises will turn to managed ITOM or ITOM as a service (ITOMaaS) enabled by open-source technologies and provided by a third party. With OSS, vendors can provide more cost-effective and readily available ITOM functions in a scaled manner through the cloud.
Through 2020, public cloud and managed services are expected to be leveraged more often for ITOM tools, which will drive growth of the subscription business model for both cloud and on-premises ITOM. However, on-premises deployments will still be the most common delivery method. This imposes multiple challenges to incumbent ITOM vendors. First, those vendors that do not offer a cloud delivery model will face continuous cannibalization from ITOM vendors that can deliver ITOM through both cloud and on-premises.
Second, platform vendors, such as Microsoft Azure and Amazon Web Services (AWS), are providing some native ITOM functionalities on their public clouds. Customers that are running workloads solely on these platforms may prefer these native features. There are also "hybrid" requirements for ITOM tools that can seamlessly manage both cloud and on-premises environments.
"Customer demand has driven traditional software vendors to transform and adapt to the changing technology and competitive landscapes. Competitive pressure from cloud (SaaS offerings) and commercial OSS (offerings with a free license plus paid support) is forcing ITOM providers to move toward subscription-based business models for both cloud and on-premises deployments," said Matthew Cheung, research director at Gartner. "This shift will eliminate revenue growth spikes as the large upfront investment seen in traditional models is spread out over time in a repeatable revenue stream."
The influx of new, smaller ITOM vendors focused on one or two major tool categories will continue to cause disruption for large traditional suite vendors. Given this situation, traditional vendors will need to react by changing how their products fit together. More importantly, traditional vendors need to change how their solutions are sold as customers exert significant pressure to shift to offering cloud-based services.

Angel Business Communications is pleased to announce the categories for the SVC Awards 2017 - celebrating excellence in Storage, Cloud and Digitalisation. The 30 categories offer a wide-range of options for organisations involved in the IT industry to participate. Nomination is free of charge and must be made online at www.svcawards.com

Storage Project of the Year - Open to any specific data storage related project implemented in any organisation of any size in EMEA.
Digitalisation Project of the Year - Open to any ICT project that has incorporated/implemented one or more digital technologies to transform a business model and provide new revenue and value-producing opportunities.
Cloud Project of the Year - Open to any implementation of a cloud-based project (public cloud, private cloud or hybrid cloud) in any organisation of any size in EMEA.
Hyper-convergence Project of the Year - Open to any implementation of a project (public cloud, private cloud or hybrid cloud) based on a set of hyper-converged products/solutions in any organisation of any size in EMEA.
Managed Services Provider of the Year - Open to any Managed Services Provider operating in the storage, virtualisation and/or cloud technologies market in the EMEA region.
Vendor Channel Program of the Year - Open to any IT vendor’s channel program in the storage, virtualisation and/or cloud technologies market introduced in the EMEA market during 2017 that has made a significant difference to the vendor’s and their channel partners business in terms of storage revenue increases, improved customer satisfaction or market awareness.
Channel Initiative of the Year - Open to any IT system reseller, distributor, MSP or systems integrator who has introduced a distinctive or innovative vendor specific or vendor independent program of their own design/specification to boost sales and/or improve customer service in EMEA.
Excellence in Service Award - Open to any IT vendor or reseller/business partner delivering end-user customer service in the UK or EMEA markets. Entries must be accompanied by a minimum of THREE customer testimonials (in English) attesting to the high level of customer service delivered that sets the entrant apart from their competition.
Channel Individual of the Year - Open to any senior individual working within any organisation manufacturing, selling and/or supporting the storage, digitalisation and/or cloud sectors in the EMEA market that has made a significant contribution to his or her employer’s business or that of their partners or customers.
Infrastructure
Backup and Recovery/Archive Product of the Year - Open to any solution that’s primary design is to enable data backup and restore or long-term archiving.
Cloud-specific Backup and Recovery/Archive Product of the Year - Open to any solution that’s design is to enable cloud-based data backup and restore or long-term archiving via a service offering.
SSD/Flash Storage Product of the Year - Open to any storage solution that can be classified as using SSD/Flash or NVMe to store and protect IT data and information.
Storage Management Product of the Year - Open to any system management solution that delivers effective and comprehensive storage resource management in either single or multi-vendor environments.
Software Defined/Object Storage Product of the Year – Open to any product that delivers a ‘software-defined- storage model’ or any ‘object storage’ product or solution.
Software Defined Infrastructure Product of the Year: Open to any solution that enables a ‘software defined’ set of solutions normally associated with traditional non-physical infrastructure deployments such as networks, application servers etc.. (excludes storage).
Hyper-convergence Solution of the Year – Open to any single or multi-vendor solution that delivers on the promise of an architecture that tightly integrates compute, storage, networking and virtualisation resources for the client.
Cloud
IaaS Solution of the Year - Open to any product/solution that delivers or contributes to effective Infrastructure-as-a-Service implementations for users of private and/or public cloud environments.
PaaS Solution of the Year - Open to any product/solution that delivers or contributes to effective Platform-as-a-Service implementations for users of private and/or public cloud environments.
SaaS Solution of the Year - Open to any product/solution that delivers or contributes to effective Software-as-a-Service implementations for users of private and/or public cloud environments.
IT Security as a Service Solution of the Year - Open to any product/solution that is specifically designed to enable the securing of data within private and/or public cloud environments
Cloud Management Product of the Year – Open to any product/solution that delivers or contributes to effective Cloud management or orchestration for users and/or providers of private and/or public cloud environments.
Co-location / Hosting Provider of the Year – Open to any company/organisation offering hosting and/or co-location services to end-users and/or service providers in the EMEA market.
Companies of the Year
Storage Company of the Year - Open to any company supplying a broad range of storage products and services in the EMEA Market.
Cloud Company of the Year - Open to any company supplying a wide range of cloud services or products in the EMEA Market.
Hyper-convergence Company of the Year - Open to any company supplying a clearly defined Hyper-converged product set in the EMEA Market.
Digitalisation Company of the Year - Open to any company supplying a clearly defined set of digitalisation services and or products in the EMEA Market.
Innovations of the Year (Introduced after 1st June 2016)
Storage Innovation of the Year – open to any company that has introduced an innovative and/or unique storage service, product, technology, sales program, or project since 1st June 2016 in the EMEA market.
Cloud Innovation of the Year – open to any company that has introduced an innovative and/or unique public, private or hybrid cloud service, product, technology, sales program, or project since 1st June 2016 in the EMEA market.
Hyper-convergence Innovation of the Year – open to any company that has introduced an innovative and/or unique hyper-convergence service, product, technology, sales program, or project since 1st June 2016 in the EMEA market.
Digitalisation Innovation of the Year – open to any company that has introduced an innovative and/or unique digitalisation service, product, technology, sales program, or project since 1st June 2016 in the EMEA market.
The re-emergence of the edge is not inconsistent with the growing concentration of IT capacity in central sites and at the hands of IT service providers. On the contrary, it is a direct consequence of it: operators will maintain and even increase edge capacity closer to users and connected machines as data volumes keep growing and as the cost of subpar response times (let alone downtime) escalates.
By Rhonda Ascierto Research Director, Datacentre Technologies & Eco-Efficient IT, 451 Research and Daniel Bizo Senior Analyst, Datacentre Technologies, 451 Research.


If there is a single underlying thread behind the anticipated wave of new edge capacity, it is about data: speed of access, availability and protection. Workload requirements across these three vectors can vary considerably. While the datacentre they are best suited for will often be determined by location as it relates to data requirements, other factors will come into play, including specific business requirements.
Here at 451 Research, we are noting multiple application types that show affinity for an edge presence outside of core datacentre sites. This affinity is based on their data requirements defined as a combination of latency, volume, and availability and reliability requirements.
To help give structure to the growing complexity of workload placements, we have devised a framework that evaluates, in broad strokes, the types of workloads that may benefit from an edge presence.
This is not to say that data is the sole determiner of where to run an application. There are many other factors that organisations weigh up when making such decisions, including compliance, security and manageability, and costs of any changes to the software architecture.
This framework is designed to help businesses identify candidates, ranging from IoT gateways to branch back-up and recovery, virtual reality consumer applications and Industry 4.0.

The edge affinity framework
Much of the IT industry shares a consensus that most workloads are migrating to large datacentres and ultimately headed to public clouds running out of hyperscale sites. This view is somewhat supported by sales dynamics at large IT and datacentre equipment vendors, which are reporting stagnant or eroding enterprise sales, offset to some degree by sales to commercial datacentre service providers growing steadily.
However, we believe most of the smaller datacentre sites will remain, albeit transformed. Even with the rapid increase in network access bandwidth, realised data speeds remain insufficient to move large data sets around on demand. Reliability and availability of network connections are generally lacking and, in most locations, cannot be relied on for critical applications.
This means that demand for locally running applications and data stores remains – even in the face of the centralisation of core systems. We anticipate public and private cloud-based digital services to be no different and, contrary to some views, to ultimately generate demand for even more edge capacity to optimise the delivery of cloud-originated services including CDNs as well as get data from users and the myriad connected machines.
We view the edge as being defined and driven by data requirements, whether speed, availability and reliability of access, rate of generation or security (or any combination thereof). The key technology component is the WAN, which largely defines these aforementioned characteristics, much more so than relatively inexpensive compute or storage capacities. Scaling bandwidth or adding redundant WAN paths is typically much more difficult, slower and ultimately more expensive than upgrading computing and storage speeds and feeds. Improvements in latency are limited by the laws of physics.
Through this lens we have classified a limited, select number of workload types per site by:
· Latency tolerance: Applications differ greatly in how sensitive their performance is to speed of access to data.
Criticality: What the availability and reliability requirements are for the application to meet business objectives.
· Data volume per site: Data that is aggregated, generated, processed or stored at a location.
Ours is not a vetted, scientific approach. Instead, our objective was to visualise in broad strokes different workloads by their affinity for an edge presence. We preselected 16 workloads we felt were strong candidates for local presence, including those that are considered to be in an established edge area, as well as those that are expected to be, as part of emerging distributed IT infrastructures.
The workloads that score very high in either latency or criticality requirements (that is, they have no tolerance for losing access to the data or application from a site) can be thought of as having hard (technical) requirements for an edge presence, while those that score lower in these but generate high volumes of data specific to a location (e.g., rich sensory data) have a soft (economic) preference for edge capacity.
We used scores from 1-6 that represent a logarithmic scale as the steps between scores are typically an order of magnitude. For example, a score of 6 for latency requirements means a sub-1ms latency, while a score of 5 maps to 1-10ms, and so on. For criticality, we used the amount of time for losing data access to/from the site that's still acceptable for the business.
Again, in a similar fashion, we scored 6 for those where we thought 0 downtime was acceptable, 5 for a few seconds, 4 for a few hours. Volume of data originating from, heading to or transiting through the site defines the size of the bubble – again, using a factor of 10-step change between categories.
Figure 1: Scoring values for an edge affinity
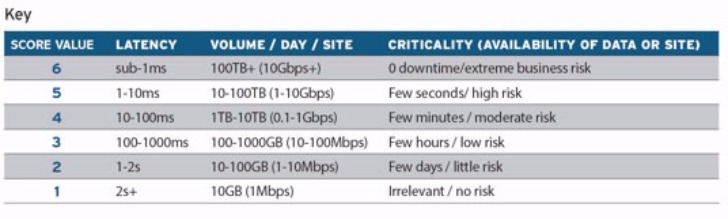
Putting it all together
Using this scoring system, we mapped out select edge workloads, weighting criticality and latency requirements and taking into account the relative volume of data per datacentre site (as illustrated by the size of the bubble in Figure 2).
Broad descriptions of the workload samples that we preselected for this analysis are:

By Steve Hone, DCA CEO and Cofounder of the Data Centre Trade Association
The DCA summer edition of
the DCA journal focuses on Research and Development and I’m pleased to say we
have received some great articles this month. Research leads to increased
knowledge and the ability to develop and innovate, the benefits of this
investment was plain to see in July in Manchester at the DCA annual conference.

The DCA’s update seminar on the 10th was not only an opportunity to bring DCA members up to speed with the work undertaken to date but also to share the plans for the future in its continued support of members and the data centre sector.
The Seminar also provided an opportunity for members to gain updates from some of the DCA’s strategic Partners including Simon Allen who spoke about the new DCiRN (Data Centre Incident Reporting Network) and Emma Fryer who provided an update on the valuable work Tech UK do in supporting of the data centre sector, this was followed by networking drinks in the evening.
On the 11th July the DCA hosted its 7th Annual Conference which took place at Manchester University. Data Centre Transformation Conference 2017 organised in association with DCS and Angel Business Communications was a huge success and continues to go from strength to strength.
The quality of content and healthy debate which took place in all sessions was testament as to just how well run the workshops were; So, I would also like to say a big thank you to all the chairs, workshop sponsors and the committee who worked so hard to ensure the sessions were interactive, lively and educational.
The workshop topics covered subject matter from across the entire DC sector, however research and development continued to feature strongly in many of the sessions which is not surprising given the speed of change we are having to contend with as the demand for digital services continues to grow.
Having seen the feedback sheets from all the attending delegates it was clear that a huge amount was gained from the day, not just in respect of contacts and knowledge but also the insight gained from speaking too and listening to others who share the same issues and same business challenges. One delegate said it was “refreshing to come to an event where he felt comfortable enough to speak out and learn on his own terms, without feeling we was being sold too”. High praise indeed so thankyou to all the delegates who attended and helped make the day such a success.
We closed the conference with a sit-down dinner in the evening with good food & wine served by the university students and of course great company which for some meant we were still out to watch the sun come up!
Although some will be taking the opportunity to slip away to recharge their batteries; you still have time to submit articles for the DCM buyers guide; the theme is “Resilience and Availability”;
Copy deadline date for this is the 20th August. There is also still space for copy in the next edition of the DCA journal with a theme of Smart Cities, IOT and Cloud which always seems to be a popular subject matter, copy deadline for this is the 12th September. Please forward all articles to Amanda McFarlane (amandam@datacentrealliance.org) and please call if you have any questions.


By Dr Jon Summers, University of Leeds, July 2017
For the last six years at the University of Leeds a group of researchers in the Schools of Mechanical Engineering and Computing have been trying to deal with the extremely complex question of how to manage simple thermodynamics and fluid flows derived from very complex digital workloads.

It is a question that does now need to be addressed and this can only be achieved using real live Datacom equipment – servers, switches and storage. Data centres should really be considered as integrated, holistic systems, where their prime function is to facilitate uninterrupted digital services. Would you go out and purchase a car with all of its technology of aerodynamics, road handling, crashworthiness and engine management without an ENGINE, which you as the driver would need to specify and source for engine size, shape, capacity and performance? No you would not, they are integrated systems. The same is true of data centres – the engine of the car is equivalent to the datacom, which is key to the provision of the intended function of the system. That is why research and development around providing the facility for the datacom should actually use real live datacom.
The group at the University of Leeds have in the past received funding from data centres, namely Digiplex and aql to develop experimental setups that can lead to a better understanding of the Datacom operation and performance with differing thermal and fluid flow scenarios. With the involvement of Digiplex we constructed a large data centre cube with a hot and cold aisle arrangement and have run this with live Datacom and some Hillstone loadbanks, the latter has been shown as a 4U proxy to replicate (with one fan and one heater) 4 times 1U pizza box servers operating at full capacity. The data centre cube is shown in Figure 1 and to augment this activity of thermal management of real Datacom in a live data centre environment, a generic server wind tunnel supported by the Leeds based data centre and hosting company, aql. The wind tunnel offers finer control on the thermal and airflow aspects of management Datacom and is shown in Figure 2.


Figure 1: Left shows a front view of the cube with a standard wind tunnel connected to the left of the cube. Right highlights the connection of the wind tunnel exhaust to the inlet to the cold aisle of the data centre cube.
The generic server wind tunnel offers the capability to test Datacom equipment at different inlet temperatures and humidity, although the latter is not easily controlled. The equipment has enabled the team to look at Datacom performance in terms of power requirements when the facility fan pressurises the cold aisle. Both the cube and the wind tunnel have helped to look at the effects of pressure and airflow on the Datacom delta temperature between front and back.


Figure 2: Left shows the exit of the generic server wind tunnel. Right shows the full extent of the wind tunnel with the working cross section.
The work at Leeds has come to the attention of the nearly 2 year old Data Centre research and development group that operates as part of Government Research Institutes in Sweden, namely SICS North, under the leadership of Tor Bjorn Minde. We are now forging a strong collaboration between SICS North and the University of Leeds with the exchange of expertise with my taking up a study leave for two years at SICS North, where we will continue to grow integrated and holistic data centre research and development using live Datacom.
Figure 3 shows the two new data centre pods with real Datacom available for a number of research projects around data centre control, operation and performance. The figure shows SICS ICE module 1 to the left, which houses the world’s first open Hadoop-based research data centre offering the capability to do open big data research. Module 2 to the right is a flexible lab with 10 rack much like the cube but with additional functionalities.

Figure 3: The two data centre pods at SICS North, Sweden, with SICS ICE on the left housing the open Hadoop-based research data centre.
By combining the expertise at Leeds on thermal and energy management of a myriad of Datacom systems with the data centre operational capabilities at SICS North, we anticipate to be able to offer a stronger understanding of the integration of the Datacom with the Data Centre facilities at a time of great need.
Acknowledgements
I would like to acknowledge the contribution of PhD student Morgan Tatchell-Evans and my colleague Professor Nik Kapur for the design and construction of the data centre cube with kind support from Digiplex and PhD student Daniel Burdett for the design and construction of the generic server wind tunnel and generous support from AQL.
Dr. Jon Summers is a senior lecturer in the School of Mechanical Engineering at Leeds. During the last 20 years, he has worked on a number of government and industry funding projects which have required different levels of computational modelling. Since 1998, having built and managed compute clusters to support many research projects, Jon now chairs the High-Performance Computing User Group at Leeds University and is no stranger to high performance computing having developed software that uses parallel computation. Applications of his modelling skills have led to publications in the areas of process engineering, tribology, through to bioengineering and as diverse as dinosaur extinction. In the last three to four years Jon’s research has focussed on a range of air flow and thermal management and energy efficiency projects within the Data Centre, HVAC and industrial sectors.

By Mark Fenton, Product Manager at Future Facilities
When one of our developers, Bo Xia at Future Facilities HQ put on the Oculus Rift headset for the first time, we were skeptical about what his reaction would be.

To the rest of the team watching from the real world, it was a curious scene: Bo was standing in our office strapped into a VR headset, moving his head and arms around wildly. But Bo had been transported and was now completely immersed in one of our data centre models—walking down the aisles, looking at live power consumption and watching simulated airflows. He was experiencing for the first time a fully-immersive data centre simulation. He took off the headset and delivered his verdict with a huge grin: “Amazing!”.
Everyone we have delivered the Rift experience to has had this reaction. Often, this has been their first experience of VR and so has come with a healthy level of skepticism and even trepidation towards the technology. What is amazing is watching how quickly that melts away once they are transported to a rooftop chiller plant or back in time to an IBM mainframe facility. Once immersed, there is full freedom to explore the data centre as you please. Walk an aisle, fly through the duct system, watch airflows or engage with any asset of interest. You quickly forget the limitations of being human and fly up to get a bird’s eye view before diving into the internals of a cabinet.
This fully-flexible experience may be the foundation of almost unlimited opportunities for our data centre ecosystem: designers walking clients around their concepts, colocation providers selling a proposed cage layout, upper management touring their investment, facility engineers troubleshooting their own sites and much more. It’s clear that VR will not only change the way we visualise our data centres but more excitingly, it will change the way we work with them as well.
For operational sites, VR will naturally progress to AR (augmented reality), where performance data can be overlaid onto the real world. Imagine walking through your data centre, putting on your AR glasses and superimposing live DCIM data or simulation results directly onto your view. With human error causing the largest percentage of data centre outages, AR could be invaluable in training and assisting site staff to ensure fewer mistakes are made.
When looking at cooling performance, site staff could visualise the airflow around overheating devices to fully understand the thermal environment - and then interactively make improvements. In addition, IT and Facilities could use this technology to proactively visualise their next deployments, a maintenance schedule or even a worst-case failure. VR offers a fully-immersed testbed, where you can experience first-hand the engineering impact of any data centre change you’re planning to make.
So what about when you can’t physically walk around the data hall floor? With the rapid growth of IoT and edge computing, there is a drive towards smaller local facilities that provide low-latency connectivity between users and their cloud requirements. From autonomous cars to the next Pokemon Go, there is an exponentially-increasing volume of data being produced, and an unwavering pursuit towards faster connectivity to make use of it.
This trend towards larger cloud data centres supported by a discretized network of hundreds - or even thousands - of remote edge sites will be a significant management challenge. This lends itself beautifully to the VR world: VR provides remote operators the tools to assess alarms and find faults, then make adjustments to mitigate the risk of downtime - all from the comfort of their chair. This concept was demonstrated by Vapor IO at the recent Open19 launch: they showed a Vapor chamber being used in a remote edge location, streaming live data from OpenDCRE and simulation airflow from our own 6SigmaDCX software.
The future of data centres is embarking on an exciting journey towards higher demand, local edge connectivity and a fully-connected IoT world. Engineering simulation techniques will ensure these sites can deliver the highest number of applications with the lowest energy spend - all with no risk to downtime. Combining the power of simulation with VR will allow data centre professionals to engage and immerse themselves in their remote environments and, for the first time, truly understand the impact of any change they wish to make. VR certainly has the ‘wow’ factor, but it is becoming increasingly clear the technology will also provide a huge benefit to the running and optimising of the next generation of data centres.

By Professor Xudong Zhao, Director of Research, School of Engineering and Computer Science University of Hull
It is universally acknowledged that the cooling systems consume 30% to 40% of energy delivered into the Computing & Data Centres (CDCs), while electricity use in CDCs represents 1.3% of the world total energy consumption. The traditional vapour compression cooling systems for CDCs are neither energy efficient nor environmentally friendly.

Several alternative cooling systems, e.g., adsorption, ejector, and evaporative types, have certain level of energy saving potential but exhibit some inherent problems that have restricted their wide applications in CDCs.
One of the most promising directions is the application of the dew point cooling system, which has been widely used in other industrial fields potentially has the highest efficiency (20-22 electricity based COP) over other cooling systems if designed properly.
To promote its application in CDCs, an international and inter-sectoral research team, led by University of Hull and supported by the DCA Data Centre Trade Association, has been formed to work on a joint EU Horizon 2020 research and innovation programme dedicated to developing the design theory, computerised tool and technology prototypes for a novel CDC dew point cooling system. Such a system, included critical and highly innovative components (i.e., dew point air cooler, adsorbent sorption/regeneration cycle, microchannel loop-heat-pipe (MCLHP) based CDC heat recovery system, paraffin/expanded-graphite based heat storage/ exchanger, and internet-based intelligent monitoring and control system), it is expected to achieve 60% to 90% of electrical energy saving and is expected to have a comparable initial price to traditional CDC air conditioning systems, thus removing the above outstanding problems remaining with existing CDC cooling systems.
Five major parts in the innovated system, as shown in Fig. 1, are being jointly developed by several organizations of the research team, including:
(1) a unique high-performance dew point air cooler;
(2) an energy efficient solar and (or) CDC-waste-heat driven adsorbent sorption/desorption cycle containing a sorption bed for air dehumidification and a desorption bed for adsorbent regeneration; both are functionally alternative;
(3) a high efficiency micro-channels-loop-heat-pipe (MCLHP) based CDC heat recovery system;
(4) a high-performance heat storage/exchanger unit; and
(5) internet-based intelligent monitoring and control system.
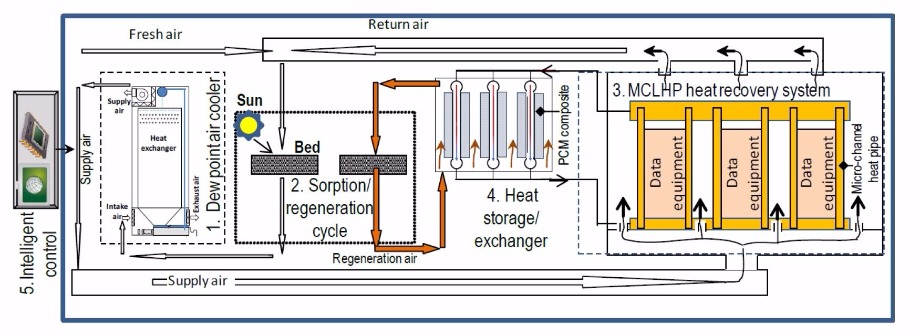
Fig. 1 Schematic of the CDC dew point cooling system
During operation, mixture of the return and fresh air will be pre-treated within the sorption bed (part of the sorption/desorption cycle), which will create a lower and stabilised humidity ratio in the air, thus increasing its cooling potential. This part of air will be delivered into the dew point air cooler. Within the cooler, part of the air will be cooled to a temperature approaching the dew point of its inlet state and delivered to the CDC spaces for indoor cooling. Meanwhile, the remainder air will receive the heat transported from the product air and absorb the evaporated moisture from the wet channel surfaces, thus becoming hot and saturated and being discharged to the atmosphere.
As the adsorbent regeneration process requires significant amounts of heat while the CDC data processing (or computing) equipment generate heat constantly, a micro-channels-loop-heat pipe (MCLHP) based CDC heat recovery system will be implemented. Within the system, the evaporation part of the MCLHP will be stuck to the enclosure of the data processing (or computing) equipment to absorb the heat dissipated from the equipment, while the absorbed heat will be released to a dedicated heat storage/exchanger via the condenser of the MCLHP.
The regeneration air will be directed through the heat storage/exchanger, taking away the heat and transferring the heat to the desorption bed for adsorbent regeneration, while the paraffin/expanded-graphite within the storage/exchanger will act as the heat balance element that stores or releases heat intermittently to match the heat required by the regeneration air. It should be noted that the heat collected from the CDC equipment and (or) from solar radiation will be jointly or independently applied to the adsorbent regeneration, while the system operation will be managed by an internet-based intelligent monitoring and control system.
This super high performance has been validated by simulation and the prototype experiment carried out in Hull and other partners’ laboratories. The coefficient of performance (COP) of the proposed dew point cooling system reaches as high as 37.4 in ideal weather condition, while the average COP of traditional cooling system is around 3.0. The tested performance of the new system at various climatic conditions are depicted in Fig. 2.
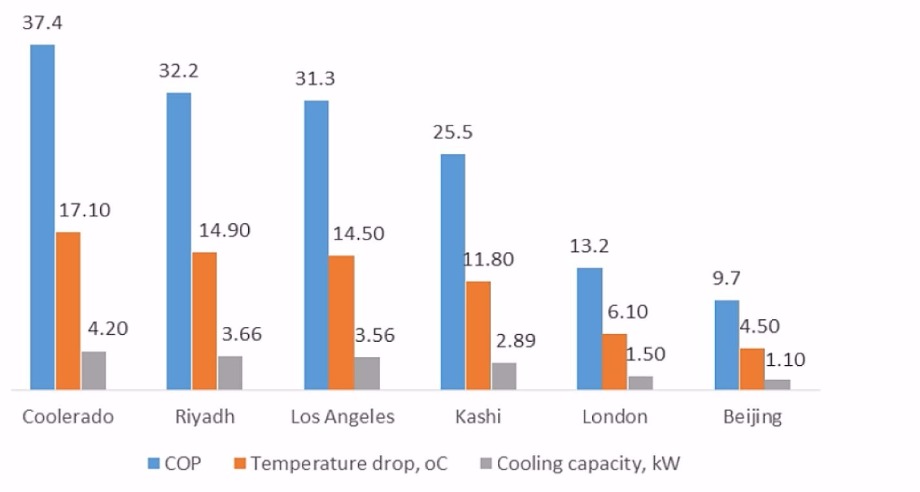
Fig.2 Performance of the super performance dew point cooler at various climatic condition.
The dynamic simulation was also carried out under UK (London) climate for 4 scale type of CDCs (i.e. small, medium, large, super) and 5 application scenarios (room space level, row level, rack level, server level). The result shows dramatic annual electricity saving compare to the reference cases with traditional cooling plans, especially for the application at server level cooling. The annual energy consumption comparison for large scale CDC is provided as an example shown in Fig 3. The results also show that the bigger the CDC`s scale the more electricity would be saved by applying the super dew point air conditioning system.
The estimated annual electricity saving for the reference Data centres in UK were:
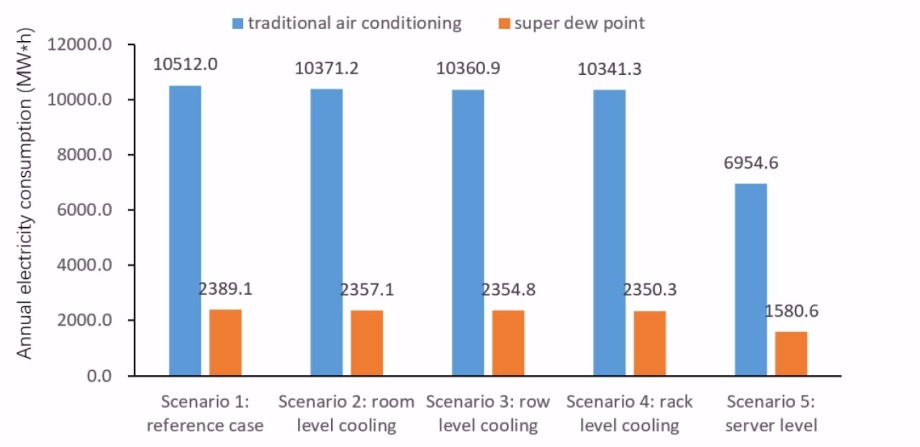
Fig.3 The annual energy consumption comparison of tradition and new cooling system for large scale CDC at various application scenario.
To summarise, the development, test and demonstration of the innovative super performance dew point cooling system for CDCs are going to be completed by 2020. The wide application of such high-performance cooling system will overcome the difficulties remaining with existing cooling systems, thus achieving significantly improved energy efficiency, enabling the low-carbon operation and realizing the green dream in CDCs.
Professor Xudong Zhao, BEng. MSc. DPhil. CEng. MCIBSE, is a Director of Research and Chair Professor at the School of Engineering and Computer Science, University of Hull (UK), and has enjoyed the global reputation as a distinguished academia in the areas of sustainable building services, renewable energy, and energy efficiency technologies. Over the 30 years of professional career, he has led or participated in 54 research projects funded by EU, EPSRC, Royal Society, Innovate-UK, China Ministry of Science and Technology and industry with accumulated fund value in excess of £14 million, 40 engineering consultancy projects worth £5 million, and claimed five patents. Up to date, he has supervised 24 PhD students and 14 postdoctoral research fellows, published 150 peer-reviewed papers in high impact journals and referred conferences; involved authorization of three books, chaired, organized, gave keynote (invited) speeches in 20 international conferences.

By Matthew Philo Product Manager – Denco Happel
The data centre industry continues to develop and innovate at a pace like no other, but this does not change core principles for the operations managers; they want simplicity and efficiency, but never at the cost of reliability. Matthew Philo, Denco Happel’s Product Manager CRAC, explains why these principles were central during the testing and development of their new free cooling solution.

As energy costs continue to rise, data centre owners and managers are looking for ways to reduce the amount of energy used by both IT and supporting infrastructure. Considering that the energy used for climate control and UPS systems can be around 40% of a data centre's total energy consumption1, efficient cooling systems can significantly cut carbon footprints and energy bills. Over the past year, we have been looking at a new way of combining free cooling with the reliability of mechanical cooling technology to help IT managers improve their Data Centre Infrastructure Efficiency (DCiE) and Power Usage Effectiveness (PUE).
The existing Multi-DENCO® range was taken as a starting point, which had introduced inverter compressors so that we could match heat rejection exactly to the room requirements. Whilst a data centre operates in a 24/7 environment, the cooling requirements vary throughout the day and across different seasons. This means that many units spent most of their life in part-load conditions, below 100% output.

It therefore made sense to increase efficiency at lower conditions to reap the biggest benefits. When we incorporated variable technology, such as EC fans and inverter compressors into our refrigerant-based, direct expansion (DX) Multi-DENCO® solution, it provided the opportunity to reduce energy consumption because it benefits from the ‘cube root’ principle. A good rule of thumb is a 20% reduction in speed will give a 50% reduction in energy consumption. This means if you can operate 80%, rather than 100%, very quickly you see your energy consumption halving.
However, this did not mean our progress on efficiency had finished. We realised that we could deliver further energy savings by exploiting the variability of the outdoor environment - in particular when it gets colder.
We knew that we needed to keep the full DX circuit within our design, to give the reliability that was required by our customers. But a refrigeration circuit does not benefit greatly from colder weather, so we focused on using indirect free cooling to provide suitably cold water to the indoor unit.

Outside of peak summer temperatures, this water circuit would reduce or remove the need for mechanical cooling (i.e. a direct expansion circuit), and the Multi-DENCO® F-Version was born.
In typical indoor conditions, 100% of the cooling requirements could be provided by the free-cooling circuit up to an outdoor temperature of 10°C. If the unit is operating in part-load conditions, it can continue to fully meet a datacentre’s cooling needs beyond this temperature, which means that the DX circuit’s compressor can be switched off for longer to save energy. To maintain the unit’s reliability, the free-cooling water circuit was kept separate to ensure that the DX circuit could operate independently if it was needed to fully meet the cooling load. A new EC water pump was chosen to give variable control and deliver the same energy-saving benefits offered by other models in the Multi-DENCO® range.
Whilst the benefits of 100% free cooling are easy to understand, the significant advantages of the mixed-mode operation can be easily overlooked. Mixed-mode, where both the free cooling and the direct expansion operate simultaneously, can be until 5 degrees below the indoor environment’s set point (for example a set point of 30°C would allow mix-mode until 25°C), which in Europe can be a large percentage of the year.
During those many hours of mix-mode operation, the ‘cube root’ principle is being exploited. The free cooling circuit may only be contributing a small percentage of the cooling, but it is also reducing the operating condition of the direct expansion circuit. As mentioned early, if the free cool circuit can provide 20% of what is required, then this is 20% less for the direct expansion circuit. This means the direct expansion circuit will save 50% in energy consumption when the unit is in mix-mode.
Energy consumption continues to be a key factor in the operational cost of a data centre. As datacentres come under mounting pressure to increase performance, managers want to take advantage of any efficiency options available. By combining the reliability of a direct expansion circuit with a simple indirect free cooling circuit, energy efficiency can be improved without risking interruptions to a datacentre’s critical operations.
For more information on DencoHappel’s Multi-DENCO® range, please visit http://www.dencohappel.com/en-GB/products/air-treatment-systems/close-control/multi-denco

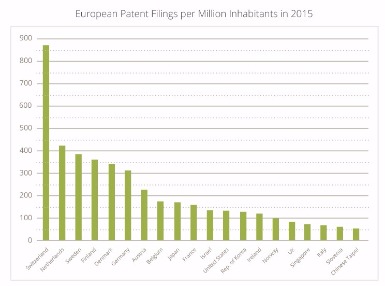
A recent document published by the European Patent Office (EPO) includes a graph which claims to be “measuring inventiveness” of the world’s leading economies using the ratio of European patent filings to population[1].
The data, reproduced in the graph (top right), shows the number of European patent filings per million inhabitants in 2015. Switzerland comes out on top, with 873 applications per million inhabitants, whilst the UK sits 16th on the list with only 79 applications per million inhabitants. This means that Switzerland has over ten times as many European patent filings as the UK, per million inhabitants.
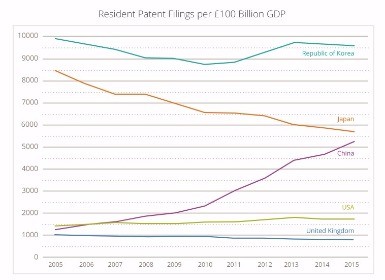
Additional data, provided by the World Intellectual Property Organisation (WIPO)[2], shows resident patent filings per £100bn GDP for the last 10 years - see the graph (bottom right). The UK is at the bottom of the pile, flat-lining at only about one filing per £100m GDP. In 2015, the USA beat the UK by a factor of about two and Korea beat the UK by a factor of over ten.
These graphs show slightly different things. One shows European patent filings, the other shows resident patent filings (i.e. filing in a resident’s “home” patent office). However they both make the same point loud and clear - UK companies file significantly fewer patent applications, in relative terms, than their competitors in other countries.
What is less clear is why the numbers are so low. Broadly speaking, there are two possible explanations.
One is that the UK really is less inventive than the rest of the world - as the EPO graph would have you believe. We would like to think that’s not true - the UK is renowned in the world of innovation, with UK inventors famously having invented the telephone, the world wide web, and recently even the holographic television, to name but a few.
A more plausible explanation is that the UK has a different patent filing “culture”, which originates from a number of factors:
£24bn takeover was the biggest ever tech deal in the UK, and the majority of that value can be attributed to ARM’s patent portfolio.
So the reasons are many and varied, but the message to UK companies is clear: your international competitors are likely to be filing more patents than you, and you need a strategy that takes this into account. This might involve filing more patent applications, or simply becoming more aware of your competitors’ patent portfolios.
Withers & Rogers is one of the leading intellectual property law firms in the UK and Europe. They offer a free introductory meeting or telephone conversation to companies that need counsel on matters relating to patents, trademarks, designs and strategic IP. For more information call 020 7940 3600 or visit www.withersrogers.com
[1] EPO Facts and figures 2016, page 15
Jim Ribeiro
Matthew Pennington


This year, global cloud computing revenue in all its guises will grow 18 per cent to $247 billion. The number of connected ‘things’ is also forecast to grow significantly. Gartner predicts that by the end of 2017, around 8.4 billion devices will be in use worldwide.
By Jackson Lee, VP of Corporate Development at Colt DCS.

The ripple effects of these market forces will be felt by data centre providers in several ways. The mainstream larger cloud service providers will continue to build more compute capacity, networking and storage. This will be in the form of hyperscale server farms, designed to accommodate growing data demands and workloads. To appreciate the scale of transactions today, consider that as I write this, Twitter is handling over 500 million tweets a day. Meanwhile, payment network provider Visa is capable of processing more than 24,000 transaction per second.
We’re also seeing hyperscale demand expand into new areas as cheaper compute power and sensors drive adoption of digital technologies in emerging markets. In industries such as manufacturing, machine-to-machine interactions directed by the Internet of Things (IoT) are creating new hyperscale segments. A good example is engineering giant General Electric (GE). A pair of its jet engines on a Boeing 787 Dreamliner generate a terabyte of information per day.
On the opposite side of the same coin is the evolution of edge computing and micro-data centres.
When applications and data are moved from centralised points to the outer layers of a traditional internet hubs, the distance between users and that data inevitably narrows. It makes delivering the right information at the right time to the user or the device quicker and more efficient. The increase in interconnectivity between machines, applications and other IoT-based devices using cloud providers is directly tied to this trend. As virtual reality (VR), the connected home and driverless cars emerge as mainstream products and services, a latency-centred product that sits closer to the user is key.
Today, almost every company and user requires near-instant access to data in order to be successful. This might explain why edge computing has been publicised as the next multibillion-dollar tech market. Organisations across the board are increasingly looking to double-down on customer experience through the delivery of services, content and data in real-time.

The growing adoption of digitalisation has given rise to new forms of competition and lifestyle improvement for end users. However, more digitalisation also presents significant resource and data processing challenges.
Firstly, a data centre strategy that combines hyperscale and edge computing into one, or chooses one over the other, is neither cost effective or competitive. It is no longer practical for every connected device or application to use the cloud in the same way smartphones do. Consider the millions of connected artificially intelligent devices, medical equipment, manufacturing robots and VR headsets in use today. The strain on network bandwidth and speed that these devices can pose soon makes sense. In short, it is highly likely that the user experience of such devices will rapidly deteriorate if congestion and latency is not addressed.
This is why a hybrid strategy – one that welcomes both full hyperscale (centralised) and edge (decentralised) computing – is so important. If the type of product or service offered is not latency or bandwidth-driven (e.g. the billing process after a transaction has been made on Amazon) it makes more sense to host it in the server farm that sits out of town away from the user. Low-level processing, backup or storage are other examples to mention.
However, technologies such as drones, driverless cars and connected fridges are latency-sensitive they require more “edge” locations so that the information can be distributed quicker and the distance between device and data narrowed, thus improving the end user experience. These products produce too much data for it to be processed in a location far away. In order to function effectively and meet the demands of the user, the products need immediate results. This is particularly true of driverless cars.
Edge computing will continue to grow in importance over the next decade as the world of “connected things” continues to unfold. These data centres will play a key role addressing issues including availability, latency and bandwidth. However, these edge nodes will be no more important than large, centralised server farms that allow organisations to continually scale the IT load to meet user demands.
The future is undoubtedly a hybrid one where organisations have the best of both worlds: the separation of edge and hyperscale data centres so that workloads and content demands are shared and distributed based on enhancing the customer experience with your brand.
Technological innovations drive the data centre infrastructure and enterprise environment where capacity, data speed, latency, bandwidth, and security are daily priorities for developers and operators. This speed of change has given rise to suggestions that Standard Development Organisations (SDOs) are losing influence in the market, especially in niche high performance segments, such as finance which require economically beneficial solutions fast, whether standards based or otherwise.
By Michael Akinla, Manager of Technical System Engineers, EMEA, Panduit.

The incredible growth in data requirements inevitably leads to innovative technology solutions. In the past 10 years, we have witnessed and helped drive the development of 1GBase-T, 10GBase-T, 25GBase-T, 40GBase-T and now 100GBase-T which are amazing achievements. In some instances, there are spikes in the technology roadmap where innovation may leap-frog the plan, nonetheless, the standards are crucial to that roadmap and provide wider technical and economic benefits across the industry.
As an organisation that contributes time and expertise to various committees, within the IEEE, TIA, Fibre Channel, IEC and BSI across the globe, we have witnessed a marked positive change in the attitude of standards bodies to remain relevant and ‘fit for purpose’. In a highly competitive, performance orientated industry, why do we rely on voluntary policy-based rules and guidelines to provide the ‘general’ direction of the technologies within the market? Standards continue to serve the data centre and enterprise environments by facilitating trade through common performance levels, vendor interoperability and finally customer choice, and these cannot be over emphasised in a global market.
We are observing more instances of organisations circumnavigating traditional SDOs and using less formalised Multi-Source Agreements (MSAs), alliances and consortiums to produce de-facto standards. This is particularly true for application setting standards such as IEEE, while individual components, for example fibre optic connectors and cable, remain largely under the purview of traditional SDOs, a MSA faction has developed PSM4, Parallel Single Mode (4 Channel) a multi-vendor, multi-technology optical interface standard for 100Gbps optical interconnect. A reason that we are seeing this shift is that MSAs with fewer members and common perspectives on the technology allows a faster consensus on a standard. This development can provide a short-cut route on to the SDO agenda for a technology solution. Either way, the fundamental value of a standard is largely maintained regardless of the organisation that produces it.
Standards do not constrain technology breakthroughs, rather the SDO roadmaps offer targets for innovators to reach for, developing new insights and products in their efforts to gain market advantage. Standards also provide a platform for secondary product development, where an innovation may not be specified within the standard, but is backwards compatible to it, and offers competitive advantages. For example, 28-AWG patch cords, the standard prescribes 24-AWG copper cable, however, the 28-AWG cabling has significantly smaller diameter wire, offering 41 percent space saving and providing Cat6, Cat6A and Cat5e capabilities, making access to the cabinets, patch panels and cable housing easier and less likely to cause line interference when MACs take place.
Standards by their nature or SDO design are Open Source to enable the widest possible involvement in their development and application. SDOs review competing technologies designed to solve the next generation challenges and deliberate at length to achieve an approach which generates the critical mass necessary for a solution to be ratified. At this point an unsuccessful alternative technology may splinter off and continue development within an MSA or a proprietary market leader and reappear in the market later. In all circumstances, there has been valuable in-depth peer evaluation of the technology and all parties will gain from the process.
We are encouraged to take an active role in shaping the standard organisations that we participate in. While some organisations simply monitor, or contribute to the administration of the standards organisations, we take an active role in the technical aspects of the standards development process. Although many of our technical innovations are applied to differentiate our products, we recognise that our expertise can be applied within the standards community to advance the industry. For example, the contribution we have made in advanced testing of fibre optic channels and components. This has demonstrated improvements in the reliability of fibre optic channels across the industry.
Standards also generate a substantial economic benefit, not only to individual manufactures and organisations, also to the market and the economy in general. The impact of standards on global trade is illuminating, a 2015 BSI (British Standards Institute) report – ‘The Economic Contribution of Standards to the UK Economy’ states that Standards are essential for opening new markets, linking UK companies into global supply chains and reducing technical barriers to trade. The report illustrated that standards compliance is hugely influential in boosting the sales of UK products and services abroad, with reported impacts averaging 3.2percent, equivalent to £6.1 billion per year in additional exports.
The research also indicates that the industry sectors which are the most intensive users of standards are the most productive, outpacing the economy as a whole by a factor of four.
Technical standards also ensure process information and product descriptions match the expectations of suppliers and purchasers across the globe. Standards organisations distribute technical knowledge ensuring information is readily accessible to all firms. This allows for an efficient exchange of information, which assists in reducing transaction costs. This allows third party organisations to provide value into the supply chain, through distribution or consultancy activities further increasing economic activity. Global supply chains are the key to economic development and would be unthinkable without the standards’ guarantee of product and service compliance. This assurance allows data centres to be built across the globe by local contractors, to the same specifications with interoperable systems.
Standardising components is essential in complex industries such as ICT and data centres where components maybe sourced from hundreds if not thousands of suppliers. Each data center is composed of thousands of separate parts sourced from hundreds of companies across the supply chain. Site developers use both internal and international standards of effectively communicate technical requirements to their suppliers, and the vast majority of these devices and components need to be interoperable and easily replaceable.
Independent Testing Laboratories or third party test facilities by their nature offer to the consumer when done right the assurance that the product that is being bought is compliant to the required standards. This can be used as a measure of where a manufactured product sits when compared to its peers.
Table 1. Summary of types of standards and the economic problems they solve
| Standard Type | Positive Impact | Negative Impact |
| Facilitating interoperability of products and processes | · Network externalities · Avoids lock-in of old technologies · Increases choice of suppliers · Promotes efficiency in supply chains | · Can lock in old technologies in the case of strong network externalities |
| Efficient reduction in the variety of goods & services | · Generates economies of scale · Fosters critical mass in emerging technologies and industries | · Can restrict choice · Can increase market concentration · Can lead to premature selection of technologies |
| Efficient quality & promoting efficiency | · Helps avoid adverse selection · Creates trust · Reduces transaction costs | · Can be misused to raise rival’ costs |
| Efficient distribution of technical information | · Helps reduce transaction costs by helping to eliminate information asymmetries · Diffuses codified knowledge | · Can result in excessive influence of dominant players on regulatory agencies |
It is important to remember that standards represent a useful and often superior policy alternative to government regulation, which would need to be developed independently per country, or trading block by block. The legitimacy of the voluntary standard achieved within industry through the consensus process provides a clear demonstration of the high standing SDOs have gained through the quality and consistency they guarantee to a global market.

Atchison Frazer from Talari explores how SD-WAN technology is helping to deliver robust enterprise cloud applications.
The mass adoption of the cloud has resulted in a decline of traditional enterprise WAN traffic from a business and its branches to the corporate data centre, or from one remote site to another. But what we have seen is an explosion in the volume of enterprise internet traffic driven by digital transformation initiatives and the migration of business-critical apps to hybrid-cloud architectures.

What started as projects around file sharing and remote data access has rapidly escalated into the adoption of cloud-native Software-as-a-Service (SaaS) applications and the mass relocation of on-premises IT systems to the cloud. Many companies have now re-architected key applications to take advantage of Platform-as-a-Service (PaaS), which makes the ability to optimise application performance from the LAN to the WAN to the Cloud, even more significant.
But as the cloud’s influence on the enterprise grows, the risk of poor WAN performance also increases. There’s no tolerance for the trombone effect that can plague traffic traveling from branch to cloud over legacy WANs - possibly adding tens of milliseconds of access latency. This is compounded by the lack of investment in high-bandwidth solutions, a particular problem for cloud-based services married to mission-critical applications, potentially resulting in an unacceptable user experience.
A recent survey conducted by Talari found that more than a third of respondents had no outage tolerance, stating that “no downtime was acceptable,” while more than 25 percent said, “only a couple seconds without a critical business app was acceptable.”
The situation won’t get any better on its own, given the continuing expansion of cloud apps and the significant traffic influx they create. Enterprises are already using 20 times more cloud apps than they track and monitor, according to the Shadow Data Report published by Symantec. Employees and business units can easily sign up for cloud apps on their own without IT’s permission - all they need is an expense account.
The foundation of cloud application transformation lies in embracing failsafe Software Defined WAN technology. A failsafe WAN frees businesses from having to rely solely on traditional high-bandwidth transport methods such as MPLS for moving data between remote sites and the enterprise data centre. The costs to expand MPLS links accelerate rapidly as mission-critical traffic to the cloud increases and bandwidth demand spikes become more commonplace. Instead, SD-WAN offers faster and more affordable options for companies to connect their disparate sites to the cloud.
But to do this, WANs need to be more flexible, scalable and affordable and be connected directly to the cloud. Adaptive, deterministic intelligent routing makes it possible to match workloads between a company’s branch offices and cloud instances to the best transport method, whether that’s broadband or MPLS. By aggregating two or more links to connect locations to the cloud, with each path constantly measured and assessed in each direction for availability and quality, it is possible to route each packet down the best path.
In effect, next-generation SD-WAN jacks up last-mile WAN performance and ensures that enough bandwidth is always in reserve for QoS-priority mission-critical apps. It maximises application quality and reliability by automatically and instantly moving traffic to a higher-quality path in the event of any single network failure or problem, including congestion-based loss and latency increases.
Like any transformational IT movement, there is a cause and effect. The benefits offered by the cloud can be negated if last mile performance and reliability are impacted. But with new SD-WAN technology, businesses can enjoy the benefits of reliable branch-to-cloud traffic flows, enabling them to provide superior support for their branch infrastructure and the best-quality user experiences. In an enterprise that is becoming ever more reliant on cloud technology ensuring you are set up to deliver these is essential.

DCS talks to Prism Enclosures Managing Director, Oliver Reynolds, about all things rack and cabinet related, discovering that there’s rather more to these data centre essentials than meets the eye.

1. Please can you provide some background on Prism Enclosures?
Prism are the UK’s leading manufacturer and supplier of high quality server racks, data cabinets and the associated accessories specialising in 19 inch rack mount enclosures for computer networking equipment and data comms infrastructure within office and high density data centre environments.
2. And who are the key personnel at the company?We have an incredible team of 42 key personnel and are expanding on a monthly basis. I work closely alongside two further Directors; Paul Southern (Operations), Sarah Fitzpatrick (Finance) and a Senior Management team that work tirelessly to ensure our operation runs smoothly and continue to increase our internal efficiencies. Nick Jacklin (Head of Channel) is the latest addition to the SMT and had increased the revenue from that side of the business every month since his arrival back at the end of 2016.
3. And what have been the key milestones to date?
How it started - The Prism Brand was created in 1997 by the current shareholders due to the increasing demand for a quality 19’’ enclosure product on a quick turnaround. After buying product through another manufacturer and seeing their lead times treble they decided to manufacture their own product solely to satisfy their client base. Shortly after creating the product, the cabinet sales quickly overtook the network distribution side of the business and thus Prism Data Cabinets was incorporated.
In 2009 - Company restructure, Prism Enclosures Ltd started trading
More recently, in 2016 – Launch of Prism’s ‘TAB’ HAC / CAC system and Prism Security Caging Solution
2017 – Prism Data Centre Solutions Ltd (Prism DCS) was incorporated to focus specifically on the Data Centre market.
4. Please can you provide an overview of the Prism portfolio?
Prism Enclosures offers an unrivalled range of products from our Next Day PI cabinet, to fully bespoke, client specific solutions. Full details of our services and offering can be found on our website at www.prism-online.co.uk
5. And you offer the PI and Fi cabinet ranges?
PI Cabinet – Cost effective cabinet for small to medium installations available up until 7pm for NEXT DAY delivery service. Due to the flexibility of our service levels (data cabinets with mesh doors instead of glass, wardrobe style doors, black and grey) we do not hold ANY cabinets in stock, however due to the efficiency of the Watford based operation we can have cabinets ready, from component form, within 12 minutes of receiving a client’s PO. Accompanied by a full range of associated products from shelves, to fans, cable management to plinths and castors, we currently deliver an average of around 1000 cabinet per month to the UK market alone.
FI Cabinet – Designed for the Data Centre environment, the FI Cabinet is our Aluminium framed Server cabinet offering an unrivalled specification including 84% curved Airflow mesh front door and reduced air loss management for increased efficiency in HAC / CAC operations.
Manufacturing the FI rage to order allows end client’s to specify a cabinet that meets their exact requirements without waiting longer than 5-7 days for delivery from placing the order.
6. Moving on to Prism’s specific data centre range, can you tell us about the Prism Bio O solution?
Prism’s Big ‘O’ advanced high density patching frame offers a dynamic solution to the challenges of cable management. It is designed to meet the evolving demands of high density cabling applications in the data centre field. It is user friendly, flexible and durable. The Big ‘O’ has a variety of configuration options, and guarantees the effective utilisation of available space. It promises your network protection, and peak performance.
The Big ‘O’ patching solution builds on the established foundation of the FI range of products and incorporates the key values and materials used. This product is available in a number of footprint sizes in single or double faced enclosures. The enclosures has been specifically chosen by today’s cable manufactures top accommodate and maintain to correct level of bend radius required for the high specification cabling systems. The internal cable channels are designed to accommodate the additional lengths supplied on all patch leads as well as providing access at a later date and throughout the life of the installation.
7. And then there’s hot aisle and cold aisle containment?
Prisms ‘TAB’ Hot aisle and Cold aisle containment system has been chosen by a number of the UK’s leading Multi-Tenant Data Centre Operators as well as a number of the world’s leading technology brands to ensure both their rented space and their own data centres are operating as efficiently as possible. Ensuring an absolute air seal, separating Hot air and Cold air within the Data centre space guarantees that the operating temperature can managed properly which in turn has resulted in huge cost savings for our client base.
Offering a fully bespoke solution available with a manufacturing AND installation lead time of between 7-10 days means that we can guarantee to have the DC space handed back to the client quicker than any competitor in the market.
8. And the overhead raceway?
With data centres of today being designed to accommodate increased densities of cable and infrastructure and with the increased diameter of new structured cable, the requirement for a detailed overhead cable management solution is critical.
With this in mind the new raceway solution from Prism provides the client with the scope to install this unit as a whole package or individually on specific rows of cabinets.
The solution has the flexibility to be manufactured to the exact requirements of the client and can also be accommodated on third party cabinets. It has been designed in conjunction with matting products to provide additional cable support and provides the correct level of support and direction for the main cable infrastructure.
9. Can you tell us a little bit about some of the key partnerships you have in the data centre space?
We currently work with a number of leading MTDC’s including Virtus, Cyxtera and Green Mountain (Norway) to name but a few.
10. And what are the Prism routes to market?
Historically, Prism Enclosures has operated via a committed and loyal channel of Distributors and Resellers which we continually work to streamline. 92% of our turnover is delivered via the channel and that figure continues to rise on a monthly basis.
Prism Data Centre Solutions talk directly with Data Centre owners and operators and offer a full, one stop offering with a ‘first time, every time’ mentality to our installations meaning that our clients do not suffer revisits and delays due to unnecessary project snagging.
11. And how are you looking to develop these?
Nick Jacklin, Head of Channel, is constantly working with his team to ensure the channel have the tools and products to compete with the cheaper, imported products available in the market.
As far as Prism Data Centre Solutions arm of the business is concerned, with our HAC / CAC offering and Caging Solution being relatively new, we are constantly visiting Data Centre clients as well as exhibiting at Data Centre focused exhibitions to get the product sets more familiar with our desired clients.
12. And we mustn’t forget the continuing drive for energy efficiency?
Absolutely, regular design workshops and direct communication with the Data Centre Managers allows us to continually evolve our product sets and, ensuring a air tight HAC / CAC system, even around third party cabinets, means that there is absolutely no recirculation of Hot Air into the Cold Aisle or vice versa. Similarly, minimising the air loss through the cabinets, outside of the 19’’ mounting space is also a huge drive which, through simple design tweaks is winning us business across the DC world on a weekly basis.
13. What can we expect from Prism over the remainder of 2017 and into 2018?
The future is a very exciting place for the Prism Group. In tandem with our fully self-sufficient UK Manufacturing facility, our service levels and lead times allow us to impress new clients as well as continue to satisfy our existing client base needs. Given the growth we have seen over the past six months I am confident that the business will continue to go from strength to strength.

The weakest link in any critical infrastructure chain is often the human element. Various studies of mission-critical environments are often drawn to a similar conclusion: that human error is a leading cause of downtime. It follows that efforts concentrated on reducing the effects of human error will yield rewards in terms of increased reliability and uptime.
By Patrick Donovan, Sr. Research Analyst, Data Center Science Center, IT Division, Schneider Electric.

Today’s data centres are by their very essence round-the-clock operations hosting many critical services that require maximum, or continuous, uptime. Quite apart from the technical issues of regular backups and the provision of redundant and failover systems to take up the slack in the case of an equipment failure, staff must be sufficiently well trained and familiar with the critical elements of a data centre to minimise the risk of unwittingly causing a disruption to its service.
Although it is never possible to eliminate human error—in fact attempts to create foolproof systems through the excessive use of automation often backfire when that automation becomes so complex that manual intervention becomes more difficult when the unexpected occurs—it can be substantially mitigated with the proper tools. Two of the most important being documentation and training.
Certified and trained personnel will understand how a data centre works, how to operate and maintain it safely and what to do in the case of a disruptive event; a power surge, UPS failure, or in some cases breakdown of sevices through human interference. To support their expertise it is essential to have a properly documented description not only of the equipment installed within the facility and its operating or maintenance requirements, but also of the various operating procedures that personnel should be expected to follow whenever required.
Without doubt, a detailed and properly thought out training or documentation program can prove to be a cost-effective investment in maintaining the smooth operation of a data centre.
There is unfortunately a tendency to view proper documentation and staff training as non-essential luxuries, especially if budgets are among the first to be curtailed when considering cost-cutting measures. Paradoxically, there can also be a tendency to “throw money at the problem” and produce a surfeit of documentation which can look very well on a shelf, however volume does not neccesarily guarantee efficiency.
What is really required is a set of best practices and methodologies that each have a proven track record of success and that can be implemented in a cost-effective manner.
Virtually everything that takes place in a data centre should have a documented procedure which is designed to accomplish several important goals. Such procedures can be categorised in three ways.
Standard Operating Procedures (SOPs) detail common operating procedures which can be functional (e.g. how to rotate equipment using a Building Management system - BMS) or administrative, e.g. how to create a maintenance ticket. These can be referred to whenever needed to ensure common tasks are reliably and consistently performed.
A Method of Procedure (MOP) is a detailed step-by-step procedure that is used when working on or around any piece of equipment that could impact the critical load. A library of MOPs should exist for scheduled maintenance operations and each MOP could reference one or more SOPs that need to be performed during its execution.
Emergency Operating Procedures (EOPs) describe in detail the response to a predicted or previously experienced failure event. They should cover how to return to a safe condition, restore redundancy and isolate the trouble. EOPs also describe disaster recovery situations.
Keeping a written record of a procedure forces the writer to examine it with a level of detail that may not otherwise occur. It encourages the Author to consider all the nuances and consequences of the actions described within.
A well constructed training document not only provides the information needed to perform a thorough standardised procedure, it also provides a framework for performing activities in the proper sequence and empowers individuals to stop work when events deviate from expectations and creates a written record of what occurred, when it occurred and who carried out each action.
Subjecting the written procedure to peer review on completion increases the chances of improving the process. Furthermore, the establishment of a written procedure provides a valuable reference tool and allows a good procedure to be improved over time, leading to an inevitable culture of continuous process improvement. It also greatly simplifies the training process and ensures that all employees carry out vital tasks in a consistent fashion.

To complement procedural documents it is important to produce reports that track the status and condition of the facility. Report documents include: Walkthrough Reports which verify that mandated activities were performed and check on the status of a site’s equipment; Shift Reports that record all significant activity on a shift and which are presented to the incoming shift to appraise them of any significant development of which they should be aware; Deficiency Reports which provide detailed accounts of any deficiency along with risk assessment, suggested remediation and estimates of likely costs; and Lessons Learned reports which document important lessons learned in the course of operating or maintaining a facility to enable technicians and operators to benefit from the experience of others.
Producing effective documentation, and ensuring that it is properly used, requires a disciplined approach to document management. A good document must contain all relevant information and a checklist of such items—a document to document a document!—can be a useful tool in its own right. Such a checklist for a MOP document might include: schedule information, site and contact information, safety requirements, tool and material requirements and step-by-step work details to name only a few of the essential list elements.
A document management system to store all important documents and provide easy access to them is also essential. Ideally this would be an automated system storing digital documents with built-in retrieval and archiving functions as well as some workflow elements, especially for Quality Assurance purposes. As a minimum, a document management system should include: an effective catalogue, to facilitate search and retrieval; a Quality Assurance procedure for reviewing and amending documents, and a version control system to ensure that everyone has access to the latest revisions and is “singing from the same hymn sheet”.
Establishing an effective ongoing training plan is essential to ensure that a facility continues to operate at maximum efficiency and that continuous improvement, rather than process deterioration, is a feature of the operation. When equipment is installed for the first time, it is common for vendors to provide a modicum of training on the new features. However, the reality of staff turnover and career progression demands that persistent on-the-job training is necessary to reduce human error and increase site efficiency.
A systematic training program should provide and verify training at progressive levels of expertise. Individuals that pass through the program become certified to perform specific tasks that are matched to their level of training. The training program should be progressive and follows several logical steps beginning with a course, with measurable qualifications, for basic supervised operations, followed by a qualification for routine operations and maintenance and a further qualification for advanced operations and maintenance leading finally to a course and qualification that certifies expertise in a particular subject.
Once employees have completed each stage of the qualification process, management can have confidence that the site’s personnel have sufficient knowledge of the equipment and procedures particular to the site that the probability of human error causing a major malfunction is minimised.
As ever, cost is a major concern for management and training is regrettably an area that is at or near the top of the list of items to be curtailed if finances are tight. However, a proper appraisal of the costs involved in training can help tight financial control to be maintained while ensuring that staff are adequately equipped with necessary skills and knowledge.
Much of the cost of developing procedures and producing the associated documentation is a one-off investment occurring in a facility’s first year of operation. Thereafter, with proper document management and version control costs will settle down throughout a facility’s working life.
The critical element to bear in mind is the cost of ongoing training compared with the cost of downtime that would ensue from an event that might have been avoided with adequately skilled personnel, trained to follow well considered standard operating procedures and primed to react to anticipated threats by following the steps detailed in emergency operating procedure documents.
Differentiating by accelerating
By Steve Mensor, Vice President of Marketing, Achronix Semiconductor Corporation.
Most commentators would agree that data centres have become a commercial sweet spot for the technology sector, showing healthy revenue growth and attracting new system solutions in both hardware and software. Unlike the promise claimed by AI, robotics and the IoT, data centre growth and innovation is actually happening, with an even brighter future ahead.

The dynamism of growing markets always delivers a continual stream of challenges. Led by the examples set by the gigantic server farms of Google, Amazon and Facebook, the arrival of Big Data, and the oceans of unstructured information it has spawned, has forced data centre designers to move away from custom hardware architectures and towards commodity hardware with the holy trilogy of high port counts, low power consumption and high performance. This approach supports scalability and redundancy while minimizing costs or the need to expand or re-structure installed services and their associated ventilation and power infrastructure. Data centre technicians ideally want to be able to leave their installation unchanged while simply swapping out boards or blades with other products that offer higher performance, lower power, and feature upgrades.
Some levels of customization are still required however to maintain flexibility for supporting new applications and specific user demands. This demand is precisely what gave Intel the opportunity to branch into a non‐PC market segment, x86‐based Xeon CPUs have been able to follow Intelʹs PC‐centric semiconductor technology roadmap along with all the performance benefits this has entailed. Coupled with the broad software ecosystem support for Xeon, it initially appeared that Intel had provided the data centre segment with just enough support for needed software‐level personalization to meet individual customization needs, while leaving installations safe and secure in their commodity hardware and software architectures that maximized performance and minimized cost. Yet data centre architects are beginning to find the adoption of commodity CPU hardware is not sufficient for all their needs.
Taking networking as an example, CPUs serve admirably in performing administrative and protocol tasks for networking control plane applications but lack the performance to support the packet based processing requirements of layers 4 and below. This is understandable, in that various bit‐intensive tasks of the lower OSI layers are far less efficient in execution on a CPU than the word/block‐oriented data structures at the transport, network and higher layers. The problem is so severe that data centre architects are finding it increasingly difficult to properly control power consumption, maintain performance and architectural scalability. A custom multi‐core CPU array or a processor with associated hardware accelerators might have been called for, but this goes against all the cost and commodity themes of todayʹs data centre design constraints.
The dynamism of growing markets always delivers a continual stream of challenges. Led by the examples set by the gigantic server farms of Google, Amazon and Facebook, the arrival of Big Data, and the oceans of unstructured information it has spawned, has forced data centre designers to move away from custom hardware architectures and towards commodity hardware with the holy trilogy of high port counts, low power consumption and high performance. This approach supports scalability and redundancy while minimizing costs or the need to expand or re-structure installed services and their associated ventilation and power infrastructure. Data centre technicians ideally want to be able to leave their installation unchanged while simply swapping out boards or blades with other products that offer higher performance, lower power, and feature upgrades.
Some levels of customization are still required however to maintain flexibility for supporting new applications and specific user demands. This demand is precisely what gave Intel the opportunity to branch into a non‐PC market segment, x86‐based Xeon CPUs have been able to follow Intelʹs PC‐centric semiconductor technology roadmap along with all the performance benefits this has entailed. Coupled with the broad software ecosystem support for Xeon, it initially appeared that Intel had provided the data centre segment with just enough support for needed software‐level personalization to meet individual customization needs, while leaving installations safe and secure in their commodity hardware and software architectures that maximized performance and minimized cost. Yet data centre architects are beginning to find the adoption of commodity CPU hardware is not sufficient for all their needs.
Taking networking as an example, CPUs serve admirably in performing administrative and protocol tasks for networking control plane applications but lack the performance to support the packet based processing requirements of layers 4 and below. This is understandable, in that various bit‐intensive tasks of the lower OSI layers are far less efficient in execution on a CPU than the word/block‐oriented data structures at the transport, network and higher layers. The problem is so severe that data centre architects are finding it increasingly difficult to properly control power consumption, maintain performance and architectural scalability. A custom multi‐core CPU array or a processor with associated hardware accelerators might have been called for, but this goes against all the cost and commodity themes of todayʹs data centre design constraints.
A solution can be found by applying a programmable NIC developed to meet these needs at the networking layers L4 and below, supporting custom bit‐intensive tasks through a configurable hardware acceleration engine. The Achronix PCIe Accelerator‐6D board is a good example, for connectivity it has four quad small form‐factor pluggable (QSFP+) hot‐swap transceivers that support 4 × 40G or 16 × 10G Ethernet communications, twelve DDR3 small‐outline, dual in‐line memory modules (SODIMM) comprising a total 192GB of memory and 690Gbps bandwidth, a PCIe Gen3 ×8 pluggable form factor with 64Gbps throughput and an HD1000 FPGA. The board can be used to implement a broad variety of accelerators for data shaping, header analysis, encapsulation, security, network function virtualization (NFV) and test and measurement.
The Achronix board improves system performance and efficiency by unburdening CPUs of laborious memory accesses and pipeline executions and directly addressing system memory for protocol stack processing and physical layer transactions. This opens up the possibility for data centres to employ the Accelerator‐6D for a broad variety of general DMA applications, via the RDMA over converged Ethernet (ROCE) or iWARP protocols.
Currently, low‐cost generic NIC cards transfer the processing load for ROCE directly to the system software stack, which negatively impacts system performance and power so a custom NIC solution is typically out of the question because of cost and scalability concerns. By implementing ROCE/iWARP on the Accelerator‐6D, system CPU overhead can be bypassed for East‐West transactions between servers, while supporting standard networking and tunnelling protocols for more conventional North‐South communications, enabling server applications to access the Internet or other remote resources. Using the Accelerator‐6D for such local communications and processing eliminates the need to burden either the network software stack and system memory resources.
Cloud services providers must provide their users not only with server and network resources capable of high performance, but also with exemplary security. The Accelerator‐6D offers system administrators a resource that is decoupled from system CPUs to implement encryption schemes in whatever configurations are desired across the data centre. Further security enhancements are possible, again without burdening system CPUs, by employing the Accelerator‐6D for NFV applications, particularly in network visibility and monitoring.
Both physical and virtual taps can be implemented, with applications including traffic management, performance monitoring, load balancing, filtering, firewalls, intrusion detection and data loss prevention. This and more is possible using the Accelerator‐6D as a configurable hardware accelerator reducing CPU loads, improving data centre power consumption, performance and efficiency and enabling service providers to ensure service‐level agreement (SLA) compliance.
The network test and measurement market is highly specialised and directly affects the data centre costs. Highly customized and expensive equipment is required to test new networking installations. The Accelerator‐6D helps test and measurement vendors take a much-needed step towards standardization by allowing test functions to be instantiated in a reconfigurable hardware accelerator. Frame generation, packet and protocol checking and other analysis functions are implemented using the Accelerator‐6D as an agnostic NIC.
Lastly the Accelerator‐6D provides 64Gbps of PCIe bandwidth, right sized to support 40 GE NFV Networking applications and high‐performance OVS offload. The PCIe interface caps the bandwidth limit for both receive and transmit communications and as such reduces the DDR bandwidth over‐subscription challenges when managing full‐duplex network interfaces. With such a combination of class‐leading memory bandwidth and a rich programmable fabric, delivery of highly differentiating NFV and OVS solutions becomes quite straightforward.
Yes, there are other board solutions containing embedded programmable logic for the NIC market. However, none have the memory bandwidth and memory density linked to a large programmable FPGA such as the HD1000. This single chip offers a multitude of hardened cores for memory management and L1/L2 Ethernet functions — six DDR3 controllers, two 10/40/100G Ethernet MACs and two PCIe Gen 3 controllers. The performance and low-power profile of the embedded hardened IP elements of the HD1000 FPGA free up more programmable fabric for customisation. Together with the 12× SODIMM modules, the Accelerator‐6D offers high performance, low power, cost and scalability in line with today’s data centre requirements.
Most importantly the board serves as a proof‐of‐concept platform for data centre administrators to safely explore further optimisation potential for installed hardware. This new path for innovation will facilitate data centre performance and efficiency improvements without creating the problems previously associated with the customisation of data centre architectures.

Speed to data. That’s what it’s all about. In a world where data is being increasingly generated and demanded planet-wide rather than just in the Tier 1 cities, the winners in the colocation and cloud services race will be the companies that can deliver data the fastest to end users worldwide.

By Mark O’Sullivan, Regional Sales Director, Flexenclosure.
But here’s the issue… in order to meet the demands of enterprises outsourcing to the cloud, or indeed end consumers wanting a faster more seamless experience when using social media or content streaming services, most of the existing hyperscale data centres are too far away from users in Tier 2 or 3 cities and certainly too far from emerging economies, with the result that latency increases and user experience suffers.
The solution of course is to build new data centres physically closer to these users and with large enterprises having facilities distributed geographically, colocation and cloud providers need to be thinking seriously about establishing facilities closer to the edge with secure access to multiple networks. In these regional cities or developing markets though, building hyperscale facilities is costly, time consuming and they’d be way oversized for the local market’s requirements. So this is where more flexible prefabricated facilities – such as Flexenclosure’s eCentre – come in to their own.
The lower up-front cost of prefabricated data centres versus larger traditionally built facilities, will lower the cost of market entry making edge markets more accessible to service providers and making the cost of the services hosted there more attractive to the ultimate customers.
With prefabricated solutions minimizing their initial capital outlay at individual sites, colocation companies will also see an increase in the total number of markets they can address as they will be able to spread their investment in modular data centres across a larger number of sites.
These factors will open up edge market opportunities for collocation providers, reducing overall investment risk and thereby making them more financially viable.
Unlike traditionally built data centres which can sometimes take years to build, the much faster speed of construction of prefabricated data centres will enable colocation providers to start bringing in revenue faster and to respond to customer demands more quickly.
In fact, the speed of prefabricated construction allows a colocation company to build an order book at the same time as building the facility offsite, without any serious risk that they will be late to deliver service.
Traditionally constructed data centres are typically built oversized and then fractionally occupied over time – an expensive and highly inefficient process. By contrast, because prefabricated facilities are built in a controlled factory environment before being assembled on site, the lead times are shorter. This enables capacity to be planned over a much shorter time horizon and then incrementally expanded as the need for more capacity arises.
This provides a number of key benefits:
Taking a prefabricated approach effectively introduces an on-demand or just-in-time (JIT) model to the provisioning of datacentre capacity – an unheard-of concept until now.
A large element of the cost of data centres is the design element. With a prefabricated solution though, using a repetitive design approach will streamline the process, minimise the cost and standardise not only the facility design but also the associated operational processes such as training, support, spares, engineering, etc. In this way repetition not only reduces capital expenses (with lower ongoing design costs) but also operating expenses (with lower and more streamlined operational processes).
Using the same design for every site, means the design cost is only incurred once for the very first facility. Regional variations may be added over time but site-specific designs can be kept to a minimum. Additionally, a standard design opens up the possibility of repetitive manufacturing that further increases efficiency and reduces cost.
With increasing numbers of businesses and consumers demanding quicker access to data outside the world’s Tier 1 cities, market opportunity at the edge is growing fast.
There is no question that the next wave of data centre development will be the land grab at the edge and the colocation companies that take a prefabricated approach to building their new facilities will undoubtedly be best positioned to take full advantage of this growth market while at the same time minimizing their risks.
Speed to the edge for providers translates into speed to data for customers – a winning formula for both.
DCS talks to Jeff Klaus, GM of Data Center Software Solutions, Intel, about what DCIM has delivered to date, and what we can expect from DCIM 2.0?

1. There's some suggestion that DCIM solutions to date have not met the expectations of the hype - ie the management bit has under-delivered. Do you have any thoughts on this?
The goals were broad and the expectations high based on a number of ‘exuberant’ analyst reports. Also the technology may not have translated well into clear management use cases, but we believe the industry has reacted quickly to the marketplace and we see tremendous adoption now. These lessons won’t be forgotten by the provider or the customer, and probably will make the next set of offerings more successful.
2. Following up, do you think that a truly successful DCIM solution needs to ensure that both the facilities and IT aspects of the data center are given equal prominence?
Yes, and no. DCIM needs to reflect where the organization is, and where it’s focused on going. New technologies, business and regulatory requirements have a significant influence on IT and data center operations (for example DCIO). I think that makes an enterprise’s use of DCIM have to be smart and focused on what the enterprise needs / wants to pay attention to in order to operate and grow. So I think the customer will be looking for a more nimble solution with excellent post sales services.

3. Looking ahead, what can we expect from DCIM 2.0 solutions?
The lessons of the past will have a large influence on demand. I see the next gen as more flexible, providing deeper value from better analysis, and stronger communication / workflow capabilities, we may even see some automation options for operators.
4. And how do you see DCIM fitting in to the overall data centre/IT management scenario - for example, cloud orchestration tools are growing in importance, alongside some of the more traditional management tools?
Well, I think there will be a central set of elements and processes it supports around operations, but it has to also help enterprise strike a balance between physical and cloud. It needs to be more flexible in how it talks to other IT and facility devices because it will need to communicate with an even wider spectrum of devices (both old and new). Certainly cloud orchestration tools can take advantage of the dynamic aggregation capabilities provided by the increased instrumentation being architected for both IT and facilities equipment. More data, more analysis, more insight.
5. And do you think that Information/Product Lifecycle Management will be making a return and, even act as the overall, fabled 'single pane of glass' into which all other management software will report?
PLM is so broad and includes people, data, and systems. It’s hard to see how the elements in DCIM don’t fold into it. That said, I think DCIM absolutely can add to a PLM through its areas of practice. If DCIM can combine machine learning with real-time data connection across IT and facilities, it has a real shot of being integral to future growth.
In today’s hyper-competitive global economy, delighting the customer has taken centre stage. And it’s easy to see why. Organizations that are winning are those that have perfected the customer experience, while those grasping for market share have fallen short in this area. A crucial step for companies can be modernizing legacy IT infrastructure to meet increasingly sophisticated technology demands to succeed in today's hyper-competitive market.
By Carl Davies, UK CEO at TmaxSoft.

This renewed focus on the customer owes much to advances in technology, access to which is changing all aspects of business – shaping growth, lowering the barriers to entry to new markets, and enabling the development of new business models and services. The net result is unprecedented levels of disruption and competition, putting new power in the hands of the customer. If customers don’t like the service they receive, they will simply vote with their checkbooks.
Witness the current trailblazers of the new application driven economy – companies like Uber, Airbnb, Netflix and Amazon. They each cater to very different buyers and have different needs, but they have successfully and drastically disrupted markets. And they've done so by using technology that puts the customer experience at the heart of their operations.
But it’s important to note that it’s not just the new players that are constantly transforming their operations to become more customer-centric; more established organizations are reengineering their business models to better serve the needs of their customers and enable them to consume their services in ways desired.
However, the path to becoming more customer-centric for established businesses is not without its challenges, and legacy technology presents a major stumbling block.
Increasingly, technology and how well it performs is the key determinant of a business’s success or failure, and business leaders have taken note. Take Delta Airlines for example. Following a technical glitch at the airline last August that led to 2,300 flight cancellations, frustrated passengers, and a nosedive in profit forecasts, its CFO, Paul Jacobson, said that it was as much of a “technology company… as an industrial transportation company,” and needed to act as such.
That kind of statement several years ago would have been unheard of, but we’ve seen similar statements made from organizations of all sectors, from finance and manufacturing to retail and charity. Every business is a software business and depends upon technology to succeed, even if some business leaders haven’t quite worked that out yet.
The Delta case is an interesting one and one with which many IT leaders will be able to sympathize. The root cause of the airline’s troubles? Legacy IT – a 22-year-old piece of equipment that caught fire and knocked out its backups system. And while it is an extreme example of the havoc that legacy IT can wreak, CIOs battle with these types of situations on a daily basis.
CIOs across the board are trying to reduce costs while delivering more value and a better experience for their customers, but despite their best intentions, many transformation efforts are being stymied by legacy IT. Research by Forrester found that, on average, IT leaders spent almost three quarters (72 percent) of their budgets simply keeping the lights on, leaving few resources to put toward new initiatives.
Fragmented IT infrastructures, consisting of a mixture of old mainframes, databases, languages and servers, are all too common, increasingly costly and difficult to maintain, and put the brakes on innovation. How can you focus on the customer experience when most of your time and resources are being spent on keeping things up and running?
Inflexible and burdensome service contracts are a further issue. In uncertain times, it’s important that CIOs have the freedom to react to changing market conditions, flexing services up and down as required. But, increasingly, it’s clear that the services offered by some of the incumbent large IT providers aren’t compatible with the new ways of working, with many organizations forced to pay more for services and licenses they don’t even need.
In this new customer-centric world, agility and flexibility are the orders of the day, and finding a way to embed these attributes into an organization’s technology should be a priority. With the move toward digital transformation, there is a growing realization that it can only be achieved by accelerating the delivery of infrastructure and application services. In many cases, that means near total data center refreshes. It is the only way to embrace agile deployment models for rapid time to market and eliminate IT bottlenecks.
What better time to consider not just the hardware lying around the data center – consuming vast amounts of space and power – but also the total cost of ownership in relation to your company’s software applications? And there is no better place to take a forensic look at the total cost of ownership than by starting with your legacy mainframe.

Choosing the right design & manufacturing partner, with Sanmina.
It is critical for system companies to understand their vendors’ roadmaps, and to optimize their design processes to maximize new product ROI.
Availability of commercial off-the-shelf hardware helps companies get to market faster by using standard hardware platforms. However, these companies also need to maximize the product lifetime for ROI purposes and take advantage of new hardware features. A major problem often facing system companies that use industry-standard compute platforms is lack of visibility into the roadmaps of critical vendors. While this may seem like a minor problem, not knowing of a major feature change can result in the need to rapidly update a now-obsolete component, or worse an entire platform. As an example, just think if a company was to introduce a product based on 10Gb Ethernet with optical interconnect just before 10G Base-T Ethernet (which is significantly cheaper) came out – that company would now be at a disadvantage versus a competitor with better insight into its vendors’ new products. If a system company knows in advance that these changes or new features are coming, they can plan accordingly and actually be “ahead of the technology curve”, and potentially the competition.
This is specifically the situation that one medium-sized network and storage systems company found itself in. The company designs and manufactures infrastructure monitoring hardware, software, and systems built on industry-standard server platforms. The company utilized a large contract manufacturer (CM) to procure, configure, test, and ship their hardware platforms, and to build a custom optical network monitoring card for their products. However, the systems company was not able to get adequate visibility into the technology roadmaps from Intel and other key vendors, and in several cases they chose the wrong Intel processors for their hardware platforms. As a result, the system company’s hardware platforms often had a useful lifetimes of as little as 18 to 24 month before they became obsolete. The company was also chronically late to market with their new products, negatively impacting their market share and revenue.
These issues forced the company’s management team to find a new partner for the design and production of their hardware platforms. One of the executives at the company had previously worked with Sanmina, and knew them to be very capable developing and delivering products based on industry-standard servers. To boost the chances for success on this transition, the company’s executive management team met with Sanmina and laid out four specific goals for the program:
The company also needed Sanmina to design a new custom optical networking board for their platform. Their current hardware utilized repeater ports on network switches to monitor traffic, which added significant complexity for customers who now had to dedicate switch ports as the repeater ports. The use of repeater ports also increased the cost of deploying the company’s solution (switch ports are not cheap, and there are seldom extra ports left unused), which impeded customer acceptance of the company’s products. A custom optical board would eliminate the need to use repeater ports, as simple network optical taps could be used to connect the network to the custom networking board. The use of optical networking ports also had the added benefit of increased flexibility on both the traffic to be monitored (essentially, any optical link could be monitored), and on the placement of company’s platform in the data centre rack, as optical cables have significantly longer reach than do copper cables.
The design of the optical networking board was not a difficult undertaking for Sanmina – they had designed and manufactured similar hardware for a variety of telecom companies. The challenge from Sanmina’s perspective was to get the company’s engineers to work hand-in-hand with Sanmina engineers during the design process, as the previous CM had always designed systems for the company as a “black box” (little/no interaction with the company’s engineers). Sanmina had successfully used interactive design processes with previous customers, and knew that these processes would actually make the company’s engineers more productive by allowing quick decisions on changes to approved vendor lists (AVLs), test plans and production schedules. Moreover, it allowed the company’s hardware engineers to leverage Sanmina’s knowledge of optical networking and server-based platform design as they worked with the software team.
For those in the data centre industry whose livelihood is based on building platforms based on industry-standard servers, there are two key lessons that this relationship highlights. The first is that large manufacturing partners, because of the breadth of their combined programs, often have much better vendor relationships than OEMs have. Correctly leveraged, the vendor relationships of the partners can benefit OEMs as well. The second lesson is that while interactive hardware design with a manufacturing/design partner may seem to put increased burden on the hardware engineers of system companies, the exact opposite is true when the partner has expertise in server-based systems and in the specific technologies that the systems company utilizes for their products. The partnership between Sanmina and the networking company in this case study illustrates the advantages of this approach, and the results that can be obtained from such partnerships. For the data centre community, the result is better products that are available quicker, allowing them to leverage new technologies at a faster pace.

Traditional business models are being rapidly transformed and even threatened by digitisation. Comparison websites commoditised insurance. Utilities have turned to self-service. Customers in all sectors expect access to a brand through whichever channel they choose at any given time.
By Stephen Long, EVP at KCOM.
This unprecedented pace and impact of technological change means enterprises need to re-imagine and re-architect their processes, systems and organisational structures. Many still aren’t taking advantage of powerful and flexible cloud-based IT to become more agile, more responsive and more focused on their customers’ needs. With the right response, this digital disruption doesn’t have to be viewed as a threat.
However, the question of how to improve customer experience is now one that concerns not just heads of customer experience and contact centres, but also COOs, CMOs and CCOs. Suddenly, responsibility for enterprise technology is no longer solely the remit and responsibility of the CIO. Yet if technology is the solution to a broader range of problems, how should this affect the way it is selected and procured? And how does this compare to the reality?
During the internal planning phase of a technology project, many businesses will be highly creative, collaborative and objective. The individual end customer will rightly be the focus of the decision-making and the plan will be (ideally) meticulous in remaining true to the end goal and to overall business objectives. But then it is, in most cases, forced into an outdated process that undermines these good intentions: the RFP.
Put simply, the strategy and concept requirements identified by a company’s leadership team don’t easily translate into a traditional RFP format. Firm adherence to this structure, and to the typical IT procurement process more generally, simply cannot reflect the modern, integrated thinking required by both the enterprise and its potential suppliers. This results in the organisation’s strategic ideals being quickly diluted.
In order to determine the exact degree to which the typical RFP process has constrained innovation, we undertook a research project to analyse all RFPs for strategic IT projects received by KCOM over the past 18 months. We aimed to quantify the adherence to a few key tenets that are essential to scoping a successful technology initiative: creativity, customer-centricity, collaboration and futureproofing.
Pragmatic creativity may manifest itself in “digital workplace” initiatives, unified communications and collaboration projects, seeking efficiencies from the cloud or the intention to make better use of the enterprise’s data through business analytics and automation.
But this open-mindedness and willingness to adopt innovative approaches is not translating into the creation of RFPs. Only 39% of the RFPs examined by KCOM actively sought or encouraged innovation from their suppliers. In the remainder, the idea of innovation was noticeable by its absence, as it fell between the cracks of internal discussion and the process of seeking potential suppliers.
Also, limiting working relationships to simple supplier-client interactions rather than partnerships, and curtailing channels of communication reduces opportunities for expert suppliers to demonstrate more creative approaches to business challenges. By failing to encourage creativity and long-term views from respondents, these projects are themselves destined to become much-maligned ‘legacy technology’.
The driver behind changing business processes is often the delivery of tangible benefits for the end customer. Unsurprisingly, 82% of the RFPs examined were for projects that were inherently customer-facing, such as contact centre restructures or API projects for customer facing applications.
Yet while 74% of these clearly articulated a customer-orientated objective for the project, only 41% specified expectations, formal metrics or success measures for customer experience improvements.
Asking suppliers to deliver solely on technical metrics, without regard for the practical impact of the project on wider business objectives or on customers, not only ring-fences suppliers’ strategic input but also severely hampers their ability to introduce innovation.
The lip service paid to business objectives and the focus instead on technical factors described above could be caused by a lack of internal collaboration.
Just 14% of the RFPs examined by KCOM showed evidence of collaboration between the IT function and the wider organisation in their creation. Some RFPs for contact centre upgrades requested only IT-centric metrics rather than asking suppliers to show how agent performance and customer experience could be improved.
Moreover, of the RFPs that had customer-focused objectives, only 24% showed signs of collaboration between IT and the rest of the business. This means that most customer-facing IT projects are procured in ‘IT isolation’, with technically-focused measures of success that undermine the enterprise’s capability to improve customer service.
In an ideal world, collaboration between numerous functions and stakeholders is the norm during the internal planning phases as business objectives are discussed and outline solutions are devised. Those involved in technology projects may recognise within their own organisations an early focus on collaboration as meetings are held, scoping documents are shared and suggestions are incorporated.
Inevitably, most RFPs examined had objectives that were inherently future-looking, such as replacing legacy technology, enabling new strategic initiatives or migrating to cloud architecture. Those that weren’t strictly future-focused included RFPs for IT resources to assist in implementing existing projects and for the migration of existing platforms to the cloud to achieve cost efficiencies.
Again, of the future-focused RFPs, a substantial proportion indicated a preference for a supplier-client relationship rather than a strategic partnership. 67% of the RFPs were written in ways that stifled strategic or creative input in advance of or during the project kick-off and thus limiting the degree of flexibility and insight that potential suppliers could build into their proposals.
Worryingly, only 43% asked prospective vendors to outline how they would future-proof the proposed approach – a clear omission given the core objective of the project.
Despite its failings, the RFP process cannot be scrapped and re-built. Too many legal and procurement-based imperatives exist for this well-established process to be discarded. But it can be and should be amended.
Firstly, enterprise IT projects need to encourage agility and innovation from suppliers to meet the strategic goals, so specifying exact technical requirements should be avoided. Enterprises should also avoid issuing RFPs that will pigeonhole their suppliers. If they want to receive strategic and creative input from suppliers, they should not design projects that limit their involvement to distinct areas.
One of the most common complaints from vendors about the RFP process is the inability to engage directly with the customer. Many say that a positive, mutual understanding and two-way communication is essential to fully understand the central needs of the project and therefore propose the most suitable approach. Provided of course that this dialogue remains within the bounds of what is acceptable for legal and procurement departments.
Another way to amend the RFP process is by making sure the weighting of scores does not encourage suppliers to lie and simply tick all the boxes to win the business. Strategic input, creativity and innovative futureproofing are all typically assigned relatively low weighting on scorecards, compared to pragmatic requirements such as technical familiarity, teams’ qualifications or the number of reference sites that can be put forward. Clearly, this undermines a supplier’s capability to address the client’s core business needs, rather than simply their technical demands.
In cases where the intention is to reduce costs, vendor selection risk can be mitigated by ensuring that proportions of fees are only payable when certain metrics are met. Better yet, it may be possible to structure financial rewards for suppliers based on the effectiveness of the proposed solution. Such an approach, especially when combined with stretch targets, will also encourage greater innovation from the supplier.
Finally, enterprises need to be willing to take advice from suppliers on how to stay agile and adapt the project to fit the new shape of the business or to meet the revised objective. Legal and procurement requirements can still be met, especially if an agile contract exists above the core delivery contract. It may be appropriate to put in place a Centre of Excellence: a real-world environment where modern technologies can be tested by both the customer and the supplier to ensure that IT solutions are practical before they go live.
The RFP process in its current form does not lend itself to the way in which the IT function has evolved. Its immovable focus on technical specifications and unquantifiable metrics does not reflect the creativity and strategic thinking that the modern enterprise IT function requires. Without changes to the approach, IT projects will continue to underperform and underwhelm.
Download the full report here: The Enterprise IT RFP: New dogs, old tricks?
DCS talks to Server Technology’s Calvin Nicholson about how Zero Touch Provisioning offers a new level of PDU automation.

ZTP is a feature that allows devices like PDUs to be provisioned and configured automatically, eliminating most of the manual labour involved with adding them to the network.
To successfully implement ZTP, you will need the following:
The communication process between the PDU and the DHCP server goes as follows:
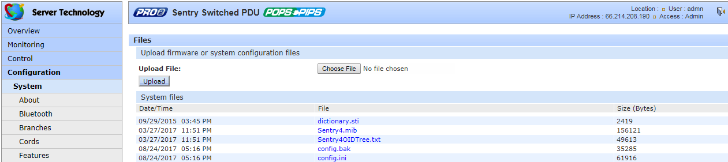
One easy way to get started with ZTP is to use one of the existing PDUs to create an initial configuration file that includes most of the defaults that will be used across all PDU’s.
After the PDU has been configured to your standard, you need to export the configuration file. On PRO2 PDUs this can be done under System -> Files -> Config.ini.
Then create a configuration file specific to each unit being provisioned via ZTP. This requires more upfront configuration work since we need to create one configuration file for each unit being provisioned via ZTP, however, it does offer us greater flexibility since it is possible to configure the IP address and the outlet names as well. And, since most of the configuration files will be 95% identical, a simple script would be able to automate the creation of these config files with ease. When saving the configuration file to the TFTP server, we also included the MAC address of the unit on the file name.
Security is always an important consideration but these changes are typically done on a secure isolated network where standard security protocols are implemented.
Yes and Yes. Fast provisioning ensures that the PDU is quickly up on the network providing valuable power and environmental information along with alerts and alarms. Configuration is provided via a STIC file that has ability to set a large number of items should the user choose to do so.
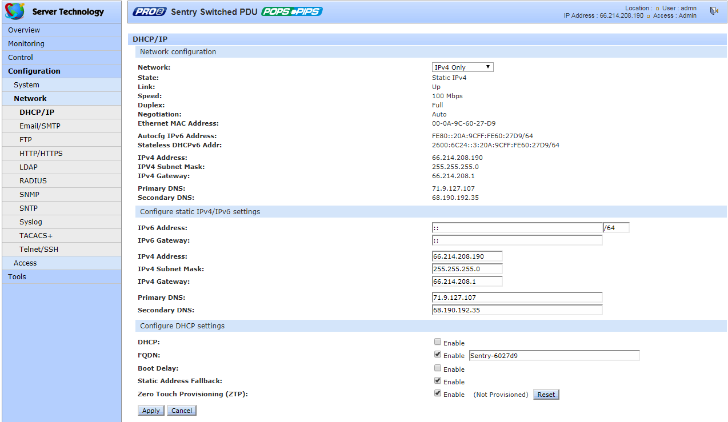
Yes and Yes. Once setup and ready to go all the user needs to do is power and plug the PDU into the network. There is no need to have any real technical staff like a network engineer available as new PDUs are installed.
Yes considerably. Considering much of the original configuration can be copied/taken from an existing PDU already up on the network and working if the user chooses to do so.
Minutes versus hours.
PRO Series products.

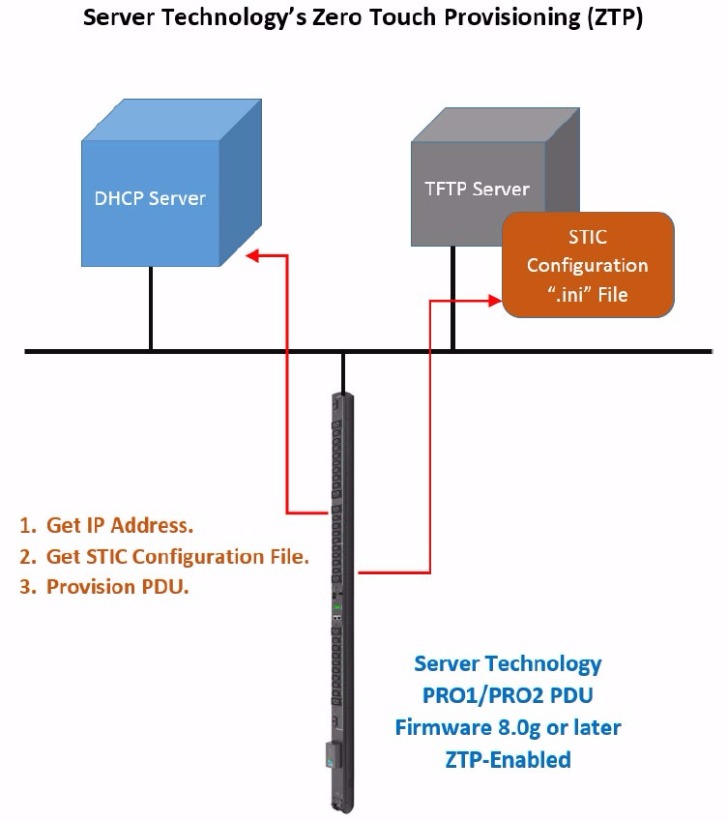
Already implemented in the firmware and shipping in all PRO series products now. Also available if you wish to do a firmware upgrade on existing PRO1/2 products.
Yes, but we do have other tools like Start Up stick or configuring the PDU via Sentry Power Manager software.
Our ZTP works much the same way that network switches and other devices do when it comes to ZTP.
One way to implement our ZTP solution is by using a product from Opengear which can provide both the DHCP/TFTP servers.
You can download further information on ZTP here.
Transferring an organisation’s data centre responsibilities to an external colo (colo) or multi-tenant service provider is a popular choice.
By Robert Neave, Co-Founder & VP, Product Management at Nlyte Software.

It’s become a proposition worth considering because colocation providers assume the responsibilities for rack space and power while maintaining all critical facility utilities such as HVAC units for cooling. In addition to these reasons, many others outsource their data centres to address or augment security, space availability, scalability, economics and internal staff’s skill.
In fact, the growth in data centre colo facilities has been remarkable, with 26.6MW of take-up and 38MW of new supply in Q1 2017 according to global real estate advisor CBRE.
If the reasons above motivate you to move operations to a colo facility then the next step is to choose a provider with the appropriate service offerings for your needs. Not all colos offer the same services so picking a provider needs some careful research, time and patience.
Before kicking-off, identify your specific needs to find the best match and make sure the selected colo provider has the tools to address your requirements now and as you grow. Plan for the future ‘you’.
Here are five areas to address with prospective colo providers:
An organisation needs to be wary of colo providers who bill based on circuit capacity – AKA metered billing. Make sure the provider bills on actual usage. This is possible when the multi-tenant provider has proper monitoring software in place to report on the energy and space usage of individual tenants. The provider must also be able to separate their facility into zones to keep track of your usage and bill verses the other tenants. You shouldn’t have to foot the bill for other customers – colo services have moved on from imprecise measurements.
This is a two-part inquiry, like the roots and shoots of a plant that work together to nourish the whole.
First determine how robust the power grid is where the colo is located. Look into how far the nearest power station from the colocation facility. Don’t take their word for it, find out through other means if they ever experience power rationing or blackouts. Discover when their last power outage was. How long did it take them to regain operations?
Secondly, inquire as to whether colo has the power monitoring capability to bill accurately – and the agility to change should your power-draw increase or decrease over time. It’s good to know up front that if they save power by increasing their efficiency, that savings will be passed on to you.
Time and again this is one of the main reasons that a business turns to colos.
It’s an absolute necessity to make sure the colos you consider provides access to multiple, geographically diverse data centres in case the worst should happen. Primary and secondary locations improve backup and disaster recovery preparedness.
Ensure to ask if the colo has:
Your very business may depend on their uptime, so it’s worth pushing hard to understand what’s on offer.
If this area of questioning draws a blank look, reconsider your choice immediately. Data Center Infrastructure Management (DCIM) solutions have gone from being a nice-to-have to a must-have, especially in large facilities like colos. Without a DCIM solution to pull and integrate information from all the siloed systems in a data centre, the colo provider will never have the single pane-of-glass view of all data to prove SLAs are being met.
That means they can’t accurately answer your queries, bill you, or manage your infrastructure as well as they could. That’s bad news for all parties.
The colo you choose should be able to prove that SLAs are being met at any time, by simply pulling a report. If they do not have this information at their fingertips then you can’t be sure they have control of their service.
The decision to go colo or not is very personal to the business needs of an organisation.
So make sure that the colo you choose offers a multi-tenant DCIM solution, understands your needs completely, and can deliver the kind of attention to detail and transparency that your business requires.
And if they don’t have a DCIM solution, make sure you have one yourself to ensure you can manage and optimise the assets you deploy in the colocation provider. You are paying for that space and power so you should try to maximise the use of those limited resources with a system which helps you automate the management of precious resources.
And if you take away just one pointer that can help you, it’s this: Data Center Infrastructure Management solutions should be part of the service package offered by successful colos. If not, they’re just being loco.
Justin Blumling, a sales engineer for Geist, covering a fifteen state US territory, examines the role of the PDU as the ‘last mile’ in the data centre power chain.

I was reminiscing with a colleague recently about some of the most secure sites we’ve ever visited as an equipment vendor. I had more than a few stories about heavily-armed security personnel, guard dogs who barked like Cujo before examining my rental car, multiple layers of exterior security gates, and vendor check-ins that took some 90 minutes to complete.
I like to think about these experiences in the context of my role at Geist. As a rack PDU supplier, we are the “last mile” in the data centre power chain. And the enormous investments that our clients make in data centre construction and fortification—massive electrical, mechanical, and security infrastructures—are done principally so this last mile operates flawlessly—so the IT can receive clean, continuous power and perform the useful work of the facility.
The rack PDU is an indispensable part of data centre service delivery, and most suppliers treat this criticality with the engineering attention that it deserves. To the credit of rack PDU manufacturers, innovations within the rack PDU footprint have extended the product’s utility beyond conductors and circuit breakers. This innovation has been manifested as intelligent PDUs.
Many early adopters chose intelligent power solutions to help future-proof their data centres or simply because it was the newest technology. Today, the number of data centres adopting intelligent rack PDUs is growing – and expectations are high for PDUs to make significant impact. The rest of this piece will discuss the potential impacts through customer use cases.
An intelligent PDU has two (2) hallmarks:
1. Embedded systems
2. Access to these systems using established protocols and interfaces
Whether the data is accessed via a web server (http), SNMP communication to supervisor software (like DCIM or network management), or APIs, intelligent PDUs enable a user to connect individual PDU points—total kW, branch circuit loading, outlet kW—to meaningful metrics that influence their decisions. Rack PDU data can quantify rack kW, watts per square foot, and Total IT load used for PUE calculations. PDU branch circuit loads can also drive conversations around capacity planning and risk prevention. For PDUs configured with outlet level measurements, users can compute the impact of virtualisation on CPU utilisation and track hardware energy consumption in kilowatt hours.
The first use case connects to this article’s introduction: security. A customer was planning a new 30-rack rollout in their facility. The build included both intelligent PDUs and door sensors to alert to cabinet access—both of which would be visualised in an existing DCIM package. The original design included door contact closures wired to collectors in distant enclosures, requiring long cable runs. The DCIM package, licensed by the number of devices, would require the customer to incur costs to integrate all new devices with IP addresses (the PDUs and the dry contact collectors).
This scenario highlights a yet-unmentioned virtue of intelligent PDUs; they can act as gateways to other valuable data in ways that minimise additional labour and hardware requirements. Instead of purchasing dry contact collectors, which require their own network connections, labour to install, and DCIM licenses, the planned door sensors could be connected to the rack PDUs via a small analog-to-digital converter. The result: shorter cable runs, no additional IP addresses (for the collectors), fewer DCIM device licenses, and reduced labour time to install.
This feature pertains to cabinet access, a crucial part of some organisations’ security plans. But the intelligent-PDU-as-a-gateway can address other big picture elements like service-level-agreement (SLA) compliance and risk mitigation. A tenant in a colocation facility, for example, may not have visibility to the temperature measurements within his landlord’s monitoring system. However, with intelligent PDUs, he can couple temperature sensors with his PDUs, tracking temperature alongside rack power and ensuring the supplier is keeping their end of the bargain.
A PDU with outlet-level monitoring and switching has long been the gold-standard of intelligence. It is both granular and powerful, capable of precise measurement and broad action. The second use case highlights the possibilities of both.
When I spoke earlier of meaningful metrics, I left out a big one (deliberately): cost. There’s a cost to five-9s of availability and for some data centre operators, it’s a cost the business demands. But, there are other IT environments—labs and other research environments, for example—that operate with a 7x24 mind-set when the business or operational needs don’t require it.
One customer (a lab manager) used his intelligent PDUs to quantify the impact of 7x24 operation and modelled these figures alternatively against a planned 5x18 availability. The results were compelling enough that he implemented an efficiency program, using both his DCIM software and intelligent PDUs. His DCIM provider crafted code that would switch off/on outlets based upon certain conditions, saving energy on hardware use. This visibility provided the raw data for a business case the lab manager could present to his management. And they created a strategy that served both their users and their bottom line.
As mentioned earlier, the touchstones of intelligent PDUs are embedded systems and access—commonly defined as network access via HTTP and SNMP. This definition, however, precludes a certain segment of customers, whose internal security measures prohibit rack PDUs on any production network. Their level of visibility has historically stopped at the PDU’s amperage display—something that would fall short of the goal when trying to phase balance a 60Amp, 3 phase rack PDU.
There’s been movement to create an intermediate level of intelligence—something portable that goes beyond an amperage display while not tethered to a network connection. Mobile technology has enabled such innovation, where apps can read special display codes on the PDU display and provide a full download of power data. Users can then download the data into popular spreadsheet tools for ongoing tracking and data manipulation.

This functionality, in the end, still requires a certain level of connectivity. Apps need to eventually email files to a user to manipulate in spreadsheet tools, and some facilities forbid the use of cellular technology within the data halls. But, as with any engineering decision, there are trade-offs and work-arounds. This level of intelligence delivers the desired intermediate position between a local display and a network connection.
Intelligent rack PDUs exist to increase awareness along the last mile of the power chain—where power is going and how it is being utilised. But, as we’ve shown here, intelligent PDUs can also be deployed to provide more comprehensive operational intelligence, illuminating areas like SLA compliance, security & access, risk prevention, and operating costs. If the past is any indication, we can expect providers to continue to innovate functionality in the PDU footprint while ensuring last mile reliability is inviolate.

DCS talks to Michael O’Keeffe, Vice President Service of Vertiv in Europe, Middle East and Africa, about how the company has developed under its new brand name, with a particular focus on the company’s focus on developing the technologies of the future.

a. The Vertiv launch has been a great success in terms of customer feedback and market response. We are pleased to say that our products and services continue to have strong recognition and that the Vertiv brand is positioning us even more as the market leaders in our field. Of course, branding and reputation are the results of ongoing efforts as we need to prove our expertise and capabilities to our customers, day after day, project after project. It’s not something you achieve overnight or that you can take for granted. We like to define ourselves as a “4 billion-dollar startup” as we have the size and experience of an industry veteran along with the passion and vision of a startup, and I think that this is exactly what our customers are looking for.
a. It’s no secret that more and more industries rely on digital connectivity, but which ones are actually the most critical? Vertiv convened a team of global experts to analyse the impacts of an outage and determine a Criticality Calculator. While some of the answers might not surprise – clearly, cloud and colocation services rely heavily on IT availability – others will make you think. At the top of the list of the World’s Most Critical Industries we find Utilities, which might sound strange if you’re thinking about coal-burning power plants, but not if you consider computer hacks have crippled power grids. Other industries that scored the highest on our criticality rubric were Mass Transit and Telecommunications, where implications can be life-threatening more than in other markets. Ultimately, the Most Critical Industries report underscores the importance of protecting uptime.
The industry-leading Liebert® EXL S1 is the latest addition to our power portfolio which has been already launched in North America and will soon be made available across in EMEA. It is a high-power density UPS that delivers size, flexibility and efficiency to minimise stranded facility space. With configurations that address the critical needs for cloud, colocation and progressive enterprise environments, it allows to increase capital efficiency and reduce operating costs while enabling rapid deployment.
a. On the power side, our portfolio spans from standard grade to industrial grade AC and DC power systems, that can be configured and customised to meet the specific needs of our customers’ critical assets. With unit capacities ranging from less than 1 kW to more than 1 MW, and that can be easily scaled up to several MW, we offer a complete range of efficient, reliable UPS systems for a wide variety of applications, not just in the data centre space but also for communication networks as well as for the commercial and industrial markets. Retail, transportation and manufacturing are just a few examples of areas where power continuity has become increasingly important.
a. Thermal management has evolved tremendously over the past few years and so has our offering – freecooling, adiabatic, evaporative, pumped refrigerant, you name it, we have it. The main challenge in the cooling field is to provide the most cost-effective solution based on the exact needs of the IT infrastructure along with the specific climate conditions, and our award-winning portfolio can address all scenarios. For example, in EMEA we are seeing strong market adoption of the Liebert EFC, an environmentally responsible evaporative cooling system that can achieve pPUE levels as low as 1.03.
a. This area is paramount for the data centre and IT industry as critical systems are requiring more sophisticated management tools to achieve operational SLAs. Vertiv’s infrastructure monitoring, intelligent controls and centralised management systems work together to increase equipment availability, utilisation and efficiency. Our Trellis DCIM platform provides IT managers with real time visibility into operations and allows them to remotely manage their critical assets to ensure security and optimisation. This can be a key differentiator especially for cloud and colo operators and is one of the areas where Vertiv is investing more. Our goal is to define the next generation of software, focusing on where we can add unique value and tailored offerings to our customers
a. We are continuing to develop our rack and PDU offerings to maximise flexibility and performance, and also integrating all our power, thermal, software equipment to deliver the SmartCabinet™. Moreover, the Knurr DCD air-water heat exchanger that can be incorporated into the rear door of a server cabinet has been recently upgraded to absorb heat loads of up to 50 kW. The new features also allow more combinations of direct chip cooling for high performance computing applications and the product is already utilised for cloud services and in hyperscale deployments.
a. We are continuously evolving our software offering to address the growing complexities of IT infrastructure. The new Trellis™ Power Insight allows widespread, centralised monitoring and control of UPS systems and networked servers, offering a comprehensive set of notifications and automated actions, now also including controlled server shutdown. More than 500 users are already using the application to simplify and improve data centre management.
With regards to edge computing and IoT, these are two major trends that are starting to shape tomorrow’s digital landscape and are expected to grow massively. The new Avocent® ACS800 serial console extends our portfolio of IoT enabled devices, offering a compact and cost-efficient solution for remote monitoring, out-of-band management and IoT connectivity for market segments beyond the traditional data centre. This is a great fit for Edge and IoT focused market segments, including users with multiple remote locations such as education, financial and retail.
a. Building on our market-leading technologies in power, thermal, software and racks, our Solutions business is able to integrate these to provide a broad range of prefabricated, pre-engineered systems which are rapidly deployable while enhancing reliability and efficiency. From smaller systems like the SmartCabinet™ to hyperscale facilities, our Solutions team works closely with customers to design and test customised systems that can then be quickly installed on-site. With our holistic approach, we ensure that all technologies work together in a seamless way starting from our factories. Prefabricated solutions are ideal for micro data centres with limited space, but also for companies looking to quickly upgrade their server rooms and local nodes to support increased data processing for machine-to-machine communication, especially for IoT and edge applications.
a. Gartner has predicted that by 2020 there will be 20.4 billion connected things worldwide, and this trend is already starting to show its real potential. With users requiring connections to happen instantaneously, this requires levels of latency that can only be delivered with edge systems, while also requiring continuous growth in data centre capacity, as many of the services we use most often are cloud-based. To make IoT a reality, businesses will need to quickly deploy new infrastructure both at the core and at the edge of the network. So basically, the key ingredients for IoT are all already available, but whether these will actually be deployed as much as we foresee now will ultimately depend on the success with users and the businesses’ ability to keep up with the market’s computing demands.
a. Customers can rely on our services during the whole life-cycle of a critical infrastructure – from project design to ongoing maintenance and performance optimisation. The Vertiv service network counts on over 3,000 field engineers and hundreds of service centres to provide a truly worldwide support for our global customers. On the project side, we proactively work with customers and contractors in scheme design, installation, commissioning, and testing to make sure the optimal technologies are in place and that operations stay on schedule and on budget. Managing the countless aspects of complex projects demands focus and expertise, and having expert manufacturer’s resources to support as a turn-key delivery or as part of a main contractor arrangement can be key in keeping complicated projects on schedule. Vertiv specialists can provide a single source of proven expertise at every step, eliminating headaches and inefficiencies and maximising investments.
a. A well-designed and executed maintenance strategy is fundamental in keeping systems up and running 24/7 and is a core part of our service offerings. In addition, Vertiv LIFE™ Services provide remote monitoring so that our technicians can quickly, accurately, and safely restore equipment to its proper operating conditions These experts receive specialized training and have access to extensive tools and increasingly analytical data to aid in optimizing the health of critical systems. The end result is increased uptime and operating efficiency.
a. Most legacy IT infrastructures don’t really leverage their full potential. We’ve been working in the data centre space for over 20 years and we see that many infrastructures have undergone significant changes, with original designs that are no longer matching today’s needs. Either significant loads are transferring to the cloud, or businesses need to re-assess facilities to allow for more capacity. Our performance optimization services help reconfigure technical spaces to lower energy costs and increase productivity. We can make a real difference by identifying vulnerabilities and root out causes of lost performance for maximum availability and TCO.
a. Training and sharing knowledge is definitely the key behind our industry-leading expertise. Our corporate Academy delivers dedicated training and development courses to all our field engineers to keep them constantly updated on the latest applications. These courses can also be made available for customers and partners to advance their skills and technical knowledge in both industry best practices and Vertiv products, while also helping them understand the full potential of their infrastructure.
a. We are pleased to say that we will soon launch a brand new Adiabatic Freecooling Chiller Innovation Lab within our Customer Experience Centre for Thermal Management. This is yet another demonstration of our laser focus on our customers and on developing the technologies of the future. The Centre offers first-hand experience of our wide-ranging portfolio, supported by constant consultation from R&D and engineering specialists. On one side this allows customers to test and validate our systems under real field conditions for their ultimate piece of mind, while in parallel providing our R&D engineers with exclusive insights on the markets’ growing needs. The Vertiv Customer Experience Centres are becoming the cradles of our product development and this is exactly why we are continuing to invest and expand on their capabilities. Stay tuned for the inauguration this autumn!
We all know that server equipment doesn’t like to get too hot and that costly, inefficient cooling plants are required to remove the heat from data centres. We also realise that the humidity of the cooling air needs to be controlled - but it’s probably not something we’ve thought a lot about.

There’s one other factor that many of us have possibly never have thought about: Servers don’t like to be too cold either.
With racks full of servers emitting kilowatts of heat you wouldn’t think being too cold was an issue, but in Northern Europe, the Nordics and the Arctic Circle, ambient temperatures are often as low as -20C to -30/35C and sometimes even -40C. If that air were to enter directly into a server it could seriously damage the components. Also, very cold air is ultra-dry – which leads to electrostatic build-up and discharges that can also damage electronic components.
Although these northern territories have an abundance of cold air, free cooling with very cold air is not as simple as you might think. So we asked a man who knows a lot about this – Alan Beresford, CTO and MD at free cooling specialists EcoCooling – to tell us what they’ve learned in the last two years of conquering cooling in Northern Europe and the Nordics.
There is a ‘bible’ for the data centre environment. It’s produced by ASHRAE – the American Society of Heating Refrigeration and Air Conditioning Engineers. Working with server and other active equipment manufacturers, ASHRAE produces environment standards (mostly based around refrigeration cooling).
In essence ASHRAE does all the hard work of understanding temperature, humidity and IT equipment reliability and then produces rules illustrated by somewhat complicated-looking graphs with coloured boundary-boxes on them (see Dia 1).
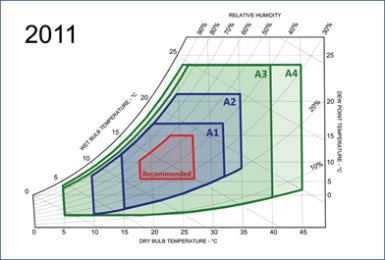
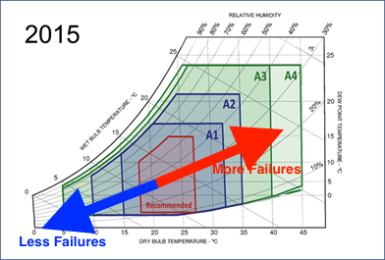
There are two of these boxes that matter to us in data centre atmosphere/environmental control and they are firstly the ‘Recommended’ box which shows the ideal operating constrains of temperature and humidity.
The second important box is the larger A1 box which covers the ‘Allowable’ operating range.
For all of us, when designing data centres, the aim is to keep the operating environment 100% within the ‘A1’ box and as much as is reasonably and economical practical within the ‘Recommended’ box.
Sounds simple doesn’t it? If only it was!
You’ll note, I’ve added two arrows to the 2015 graph that you don’t usually see. ASHRAE calls this extra variable the “X-Factor” which predicts IT equipment failure rates. In essence, there’s a significant trade-off between higher failure rates at cheaper/easier to achieve high operating temperatures - and lower failure rates at lower temperatures (see box-out).
Incidentally, before the 2015 (4th Edition) of ASHRAE, you can see that the 2011 Recommended and A1 boxes were very much smaller. Thankfully, modern equipment is far more tolerant to both higher and lower excursions of temperatures and humidity.
As readers may know, EcoCooling has been leading the march towards direct fresh air ‘free cooling’ backed up by adiabatic (evaporative) cooling as a significantly lower cost alternative to refrigeration cooling. It’s important to note that this approach works in climates that are not constantly hot and humid. As this article is about cooling in Northern Europe and the Nordics, that’s spot on target.
When we first started developing fresh-air/evaporative cooling systems, we worked on the basis of keeping to the lowest temperature in the -Recommended ASHRAE box (green on the following diagrams).
It you look at Dia 2, there are 8760 purple dots (one for every hour of the year) plotted for a London data centre with an EcoCooling system.
The purple ‘line’ is actually the main concentration of the dots – showing that by enabling evaporative cooling at 18C, we could keep the data hall at 18C for most of the year.
In terms of compliance with A1 (orange box on these diagrams), this gave us 73.7% compliance with Recommended and 94.5% compliance with A1/Allowable. It also gave a 90% X-Factor, so 10% fewer server failures than the norm.
Next we looked at allowing the temperature to rise higher towards 23C, the level generally found in refrigeration-cooled data centres.
On the one hand (Dia 3) it was better; Recommended compliance went up to 97.6% and Allowable to an impressive 99.5%.
But – and it’s the Elephant-in-the-Room that no one ever talks about - the X-Factor at 23C is 115%. That means the server reliability is seriously degraded. 15% worse than the average enterprise data centre and 10+15=25% worse than our previous 18C ‘keep-it-cold’ solution.

What we now needed was to create a more intelligent solution – one that increased compliance without introducing reliability issues. So our next development was to program our bespoke CREC controller to defer the temperature at which evaporative cooling kicked-in from 18C up to 23C.
This reduced the proportion of time that the evaporative cooling needed to run; increasing the amount of ‘free cooling’. This took the green/Recommended compliance to 82.9% and the orange/Allowed to 98.2% (Dia 4).
And at 91%, the X-Factor was very significantly better than 115% in the previous scenario.
It was a very positive improvement – but not quite ‘there’ yet.
We noticed that those purple dots that are ‘outside’ the green and orange boxes are almost exclusively where the humidity is out of bounds. And that gave us an insight as to what to do next.
You may know that Relative Humidity (RH) and air temperature are inextricably linked. So using our software controller, we developed Dynamic Humidity Control such that, when RH looked set to exceed the ASHRAE 60% line, it would increase the air temperature slightly until the RH dropped back into spec.
If you look at Dia 5 you’ll see the results were stunning! Compliance flew up to 97.6% in the green/Recommended zone and 99.5% Allowable.
An X-Factor of 91% means server reliability is 24% better than in many refrigeration cooled data centres where the X-Factor is 115%.
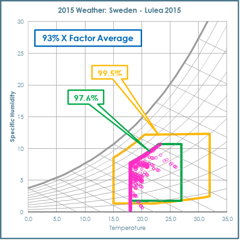
And I should also mention that the operational saving that can be made cooling, for example, a 1MW data centre using this approach is around £75,000 (in London, UK) and £240,000 (in Lulea. Sweden) per year compared to a traditional refrigeration approach.
Now, all of the research and development I’ve mentioned above was based on temperate climates (think latitudes from London or Paris up to the top of Scotland).
Then, our clients started asking us to design solutions for even further North – in Northern Europe, and the Nordic countries.
Now, you might think a year-round supply of very air cold would be ideal to free-cool any amount of server equipment. But very cold air is also extremely dry and even with our advanced Temperature and Dynamic RH Control system there were a significant number of hours (amounting to about 8% of the year) where the purple dots show the humidity out of spec at the bottom and top of the graph (Dia 6).
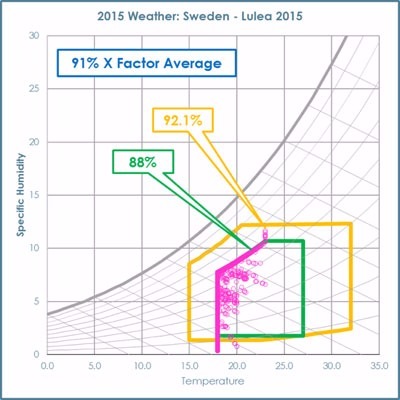
Although the ambient temperature can be -20C to -30C in the winter months , there are also days when it goes up to +26/27C – so we reckoned that we’d still need to provision evaporative coolers to cover the cooling requirement on those days.
We already had quite a sophisticated attemperation (air mixing) algorithm built into our control system. This mixes hot air from the data centre exhaust back into the cold air from the evaporative chillers so that it’s kept to an ideal temperature to feed the server inlets based on the current cooling demand and inlet temperatures.
It was very easy to extend this to attemperate the extremely cold external air which, as I mentioned earlier, would wreak havoc if allowed directly into the IT areas of the data centre - damaging both equipment and any people working there!
Dia 6 showed that with our normal combination of free fresh air, evaporative cooling and dynamic RH Control, although we were 92.1% in the ASHRAE Allowable zone, we would have only 88% compliance with Recommended due to the low humidity of the fresh-air.
We figured that our evaporative coolers could also be used just to provide humidification on the days where all incoming air was too dry. A very simple solution and without any additional capital expenditure for separate humidifiers. Unlike conventional humidifiers – which are very energy greedy – our evaporators hardly use any energy at all. So a very low cost solution.
Adding in the new humidification process (Dia 7) smashed 99.9% compliance in the Recommended zone and 100% Allowable! A fantastic result – and with 24% better reliability than many refrigeration-cooled data centres.
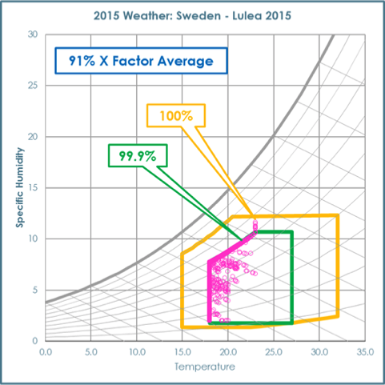
Having done all of the R & D work against the back-drop of ‘conventional’ enterprise data centres in temperate and cool markets, some of our more northerly clients wanted to reduce their total TCO (total cost of ownership) still further.
They asked us to model the cost-benefit of dispensing with both evaporative cooling and humidification. This would require allowing a small amount of deviation outside the ASHRAE A1/Allowed zone in return for reduced capital and operating costs. This was done in line with the principles found in the EU Code of Conduct for Data Centres.
So it was that we developed a set of fresh-air-only ventilation cooling units for deployment in high-grade colocation data centres.
The results were impressive!
Although it’s not immediately obvious on the diagram (Dia 8), this solution was 100% compliant on temperature control within the ASHRAE Recommended zone at a 91% X-Factor. The only excursions being at the bottom due to low humidity. Studies of the modern server equipment being deployed showed to our clients’ satisfaction that these excursions would cause no appreciable problems provided that normal anti-static precautions were taken within the data centre.
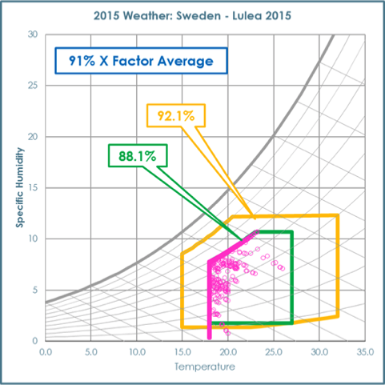
In cost benefit terms, our clients were very excited by the outcome.

Our CloudCooler® ventilation cooling units, the result of this development programme, allow for the very rapid installation programme that many of these new business applications require – they literally are plug-and-play requiring no plumbing; just electric supply and network connections.
We already have a 2MW installation of our intelligent ventilation-only product line in Lulea, Sweden for Hydro66 and they’ve announced plans to grow to 12MW by early 2018. Paul Morrison of Hydro66 said, “This unique combination of cooling solutions allowed Hydro66 to continue working with EcoCooling, a single vendor who could meet multiple use cases, both for enterprise and more price sensitive clients”.
As an example of the type of rapid growth we’re seeing in these northern territories, we are currently working with one customer who is rolling out 4MW of cooling and processing per week! Many other installations are now in progress.
Having demonstrated 100% in-service compliance on temperature, with only small dips out of ASHRAE Recommended at low humidity, the case for low cost, rapid roll-out, ventilation-only cooling for data centres in Northern Europe and the Nordics is incontrovertible. And the requirement is growing rapidly.
This is based on the rate of failures expected when operating at a constant 20C as the ‘norm’ and shows the % relative to that.
| Temp | X-Factor failures |
| 15.0C | 72% |
| 17.5C | 87% |
| 20.0C | 100% |
| 22.5C | 113% |
| 25.0C | 124% |
| 30.0C | 142% |
Traditionally, when building a new data centre, roughly 35% of capital expenditure would be spent on cooling equipment, which accounts for 50% of the ongoing running costs.
By Icetope.

New, more powerful processors put higher demands on traditional cooling technology and legacy equipment won’t cut it in a world of increasing heat loads with CPU’s in excess of 200W and GPU’s of 300W. Add to this the fact that new technologies such as the Internet of Things (IoT) are driving demand for more and larger data centres, along with substantial investment at the Edge of Network, it’s clear that cost effective and efficient cooling technology is needed.
Most agree that liquid cooling is the answer but until now it has been regarded as a niche technology, with many compromises, that can’t meet the demands of a modern data centre.
Iceotope has developed a versatile technology that answers the historical concerns around liquid cooling and is ready to redefine the data centre cooling landscape.
Thanks to Iceotope’s total immersion cooling technology, expenses such as chillers, computer room air handling (CRAH) equipment, raised floors or ducting are no longer necessary but that’s just the tip of the iceberg when looking into how liquid cooling can lower data centre costs:
without the need for power-hungry computer room air handling equipment and zero fans inside the servers, Iceotope’s technology can reduce energy bills by up to 80%. Iceotope also allows the recapture and reuse of waste heat leading to an improved corporate risk and social responsibility strategy.

There is a clear need to ensure your risk is managed but when you consider the exponential growth in big data and cloud computing, data centres need to adapt in order to deliver great customer service and profitability. Traditional data centre cooling equipment cannot cope with ever-increasing heat loads that new processors and apps demand. Sticking with the legacy approaches will only lead to larger footprints and increasing cost and complexity, with no competitive benefit.
Liquid cooling is essential in preventing this trend from continuing. It allows systems to be deployed with greater densities, faster speeds and more flexibility. Immersion cooling alone saves up to 75% of the floor space, simplifying data centre infrastructure.
Additionally, unlike previous types of liquid cooling, Iceotope’s specially engineered coolants are sealed and produce no residue or slip hazards within the data centre and is therefore cleaner and safer when servicing. With a similar architecture to air cooling, access to parts are straightforward with no specialist tools required. Servers are also hot swappable, allowing data centres to replace or add components with minimal disruption.
Previous iterations of liquid technology sacrifice flexibility in return for greater efficiency. Thanks to Iceotope; liquid cooling has moved into the mainstream and such compromises will no longer be necessary.
Both energy and water are in huge demand by the world’s expanding and developing population.
Around 2.8 billion people live in areas with high water scarcity and 2.5 billion have no or unreliable access to electricity. So when we consider that in 2040 there will be a 50% increase in electricity consumption and around 40 billion connected devices, our digital future must conserve our water and energy supply.
Traditional data centre infrastructure such as evaporative methods and cooling towers are recognised as a huge contributor to water consumption. Around 800 data centres in California consume enough water to fill 158,000 Olympic swimming pools per annum!
So importantly, our immersion liquid cooling technology uses clean, safe, dependable, engineered coolant to cool down electronics – not water resource.
Iceotope uses a two-stage cooling process – the first stage being a specially engineered liquid to cool all components with the second stage transferring the heat away using a coolant loop. Not only do the coolants demand zero water consumption, they last between 15-20 years and are fully recyclable – all contributing to an excellent water usage effectiveness (WUE) metric.
When we consider that Iceotope’s liquid cooling saves up to 80% energy consumption, and you can reuse the waste heat for district heating, liquid cooled data centres become a sustainably smart business model.
Conventional wisdom states that liquid and electronics do not mix well – this has long been a barrier to widespread adoption of liquid cooling technology.
Iceotope has developed a liquid cooling technology that revolves around a coolant that is completely safe to use around electronics. The coolant is non-flammable, has no flash-point and is the only liquid coolant to meet Factory Mutual (FM) Standard 6930 meaning it is fully insurable, unlike other cooling methods.
The coolant is hermetically sealed inside the server so, thanks to the lack of air intakes, the components inside are protected from dust and dirt leading to longer product lifecycles and zero failure.
As demonstrated throughout this article, there are legitimate concerns around liquid cooling, which our new technology and innovation are countering.
We have seen a confidence shift in liquid cooling technology from data centres and businesses who need flexible and scalable servers to keep up with increasing digital demand, cloud computing and big data.
Ultimately the future of IT, application development and, importantly, your competitive advantage will be forever changed by our technology.
Liquid cooling is the new mainstream, and it is the future of IT.