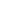This comment is often used to extol the virtues of the next big thing – Cloud, IoT, software-defined, the edge, Open Source, artificial intelligence, digitalisation – the list is seemingly endless. And while it’s part of the role of the DCS magazine to ensure that all our readers are kept abreast of the latest technologies and trends, just occasionally, maybe we should take a pause for breath, and realise that, for many data centre owners, operators and users, there’s enough to keep them busy just running and using their existing infrastructure, without confusing the picture with a whole new set of ideas.
However, time and tide wait for no data centre professional, so we’re not going to abandon bringing you what’s cutting edge, or even just edge(!), but hopefully balance the old and the new, the tried and the tested with the untried but must be tested. However, I would say that, having worked in and around the data centre industry for the best part of 20 years, I am constantly surprised when I attend industry conferences and workshops and see the same pictures of the same data centre bad practices time after time. It would seem that, despite the best efforts of vendors, consultants, trade associations, the media and others, there are still plenty of data centre managers and operators who don’t mind the ‘spaghetti’ cabling scenario, or are happy to have plenty of gaps in their hot or cold aisle containment strategies, not bothering to use blanking panels, or even a properly sized piece of wood or cardboard to plug the holes!
While the various surveys that predict the extinction of any business that fails to employ robots, IoT and a total Cloud strategy by, say, 2025, might be a little bit over the top, there is no doubt that the pace of change has never been quite so fast as right now. So, if you don’t at least start thinking about some kind of a future strategy soon, then you won’t be in any kind of position to respond to the next technology innovation wave – whenever that arrives (although we seem to be in the midst of one long such wave!).
Yes, the pace of change varies from country to country, and from technology to technology within each country as well, but anyone who doubts that massive change is taking place, needs only to think of some of the big names in virtually any industry sector that have disappeared for good. Sure, there will be many reasons why a company has to close, but I suspect that, in most cases, failing to keep pace with technology changes will be one of the main reasons. After all, properly implemented, the very latest IT offers a level of reliability, flexibility, efficiency and speed unheard of just a few years ago.
If you are not planning to change your data centre to keep pace with today’s available technologies, then there are plenty of companies who will be. No one can predict how, when, where new ideas and technical advances will come along, or even whether they’ll be adopted on a wide scale, but you’d be foolish to ignore them. Hit a wall of fog whilst driving your car and you have two choices – carry on at the same speed and hope that you don’t crash into the vehicle in front, or slow down and be as vigilant as you can to try and spot what’s out there. So, do you keep on doing the same things in the data centre, or make a decision to make some changes?
-l1uge6-aynu23.jpg)
Over 70% of IT organisations have trouble recruiting candidates for datacentre and facilities roles.
Despite on going consolidation worldwide and migration to public cloud, today’s datacentres are well-equipped to handle physical infrastructure requirements for the foreseeable future. Nearly 60% of organisations worldwide surveyed in 451 Research’s latest Voice of the Enterprise: Datacentre Transformation study said they have enough floor space and power capacity to last at least five years.Further, while the total number of IT employees is expected to decline over the coming 12 months, most organisations said the number of personnel dedicated to datacentre and facility tasks will stay the same or increase. This solid outlook was most often attributed to overall business growth (63% of respondents), but more than a third of organisations also pointed to demand from project-driven growth.
As a result of these demands, 73.7% of organisations said that recruiting for datacentre and facilities is at least moderately difficult. Respondents pointed to three common reasons: current candidates lack skills and experience, salary asking prices are too high, and a lack of candidates in the organisation’s region.
“The good news is many organisations are not facing a datacentre and facilities skills shortage at this time,” said Christian Perry, Research Manager and lead analyst of 451 Research’s Voice of the Enterprise: Datacentre Transformation. “Those who do have recruitment challenges say they most often train existing staff to learn new skills due to the dearth of available talent.”
Only 19.2% of the surveyed organisations facing these skills shortages said they would use managed service providers to fill the gaps. While this limits the opportunity for traditional MSPs and infrastructure vendors to offer value-added services, it creates opportunities for them to assist customers with training, for example providing education on eco-friendly HVAC (heating, ventilation and air conditioning) technologies.
Similarly, only 20.5% of the organisations that face skills shortages plan to move spending to public cloud, compared with 42% that said spending will not be impacted by those shortages, and 32.1% that said they will spend more on talent. However, 451 Research analysts found differences between organisations that have more generalists than specialists across their IT team.
“When IT teams consist primarily of generalists, they are more likely to invest to secure talent compared with specialist-heavy firms,” Perry said. “We find that siloed organisations tend not to be in a significant period of IT team transition, whereas generalist firms are transitioning to become even more generalist-heavy. This can backfire when personnel leave or retire, forcing them to scramble to find specialist skills in facilities, for example.”

In the second quarter of 2017, worldwide server revenue increased 2.8 percent year over year, while shipments grew 2.4 percent from the second quarter of 2016, according to Gartner, Inc.
"The second quarter of 2017 produced some growth compared with the first quarter on a global level, with varying regional results," said Jeffrey Hewitt, research vice president at Gartner. "The growth for the quarter is attributable to two main factors. The first is strong regional performance in Asia/Pacific because of data center infrastructure build-outs, mostly in China. The second is ongoing hyperscale data center growth that is exhibited in the self-build/ODM (original design manufacturer) segment.
"x86 servers increased 2.5 percent in shipments and 6.9 percent in revenue. RISC/Itanium Unix servers fell globally for the period — down 21.4 percent in shipments and 24.9 percent in vendor revenue compared with the same quarter last year. The 'other' CPU category, which is primarily mainframes, showed a decline of 29.5 percent in revenue," Mr. Hewitt said.
Hewlett Packard Enterprise (HPE) continued to lead in the worldwide server market based on revenue. Despite a decline of 9.4 percent, the company posted $3.2 billion in revenue for a total share of 23 percent for the second quarter of 2017 (see Table 1). Dell EMC maintained the No. 2 position with 7 percent growth and 19.9 percent market share. Huawei experienced the highest growth in the quarter with 57.8 percent.
Table 1
Worldwide: Server Vendor Revenue Estimates, 2Q17 (U.S. Dollars)
| Company | 2Q17 Revenue | 2Q17 Market Share (%) | 2Q16 Revenue | 2Q16 Market Share (%) | 2Q17-2Q16 Growth (%) |
| HPE | 3,204,569,547 | 23.0 | 3,536,530,453 | 26.1 | -9.4 |
| Dell EMC | 2,776,347,626 | 19.9 | 2,594,180,873 | 19.1 | 7.0 |
| IBM | 963,279,264 | 6.9 | 1,226,947,968 | 9.1 | -21.5 |
| Cisco | 866,450,000 | 6.2 | 858,924,000 | 6.3 | 0.9 |
| Huawei | 845,543,611 | 6.1 | 535,946,936 | 4.0 | 57.8 |
| Others | 5,281,754,345 | 37.9 | 4,801,420,134 | 35.4 | 10.0 |
| Total | 13,937,944,394 | 100.0 | 13,553,950,355 | 100.0 | 2.8 |
Source: Gartner (September 2017)
In server shipments, Dell EMC maintained the No. 1 position in the second quarter of 2017 with 17.5 percent market share (see Table 2). HPE secured the second spot with 17.1 percent of the market. Inspur Electronics experienced the highest growth in shipments with 31.5 percent, followed by Huawei with 26.1 percent growth.
Table 2
Worldwide: Server Vendor Shipments Estimates, 2Q17 (Units)
| Company | 2Q17 Shipments | 2Q17 Market Share (%) | 2Q16 Shipments | 2Q16 Market Share (%) | 2Q17-2Q16 Growth (%) |
| Dell EMC | 492,854 | 17.5 | 529,135 | 19.2 | -6.9 |
| HPE | 483,203 | 17.1 | 529,488 | 19.2 | -8.7 |
| Huawei | 176,426 | 6.2 | 139,866 | 5.1 | 26.1 |
| Inspur Electronics | 158,373 | 5.6 | 120,417 | 4.4 | 31.5 |
| Lenovo | 145,655 | 5.2 | 235,267 | 8.5 | -38.1 |
| Others | 1,367,176 | 48.4 | 1,203,525 | 43.6 | 13.6 |
| Total | 2,823,688 | 100.0 | 2,757,698 | 100.0 | 2.4 |
Source: Gartner (September 2017)
-notvgz.jpg)
Total EMEA external storage systems value fell by 2.9% in dollars in the second quarter of 2017 but remained fairly flat at -0.1% in euros, according to the International Data Corporation (IDC) EMEA Quarterly Disk Storage Systems Tracker 2Q17.
The all-flash market still recorded high-double-digit growth in value (53.1% in dollars), accounting for about a quarter of the overall market, while hybrid arrays recorded a marginal decline (-3.1%) and HDD-only systems continued to contract (-25.7%).
"As enterprise datacenters embark on their digital transformation, purchase patterns evolve too, shifting toward opex-based consumption models and a preference for more efficient, leaner datacenter infrastructure such as all-flash arrays [AFAs] and hyperconverged systems [HCIs]. This shift keeps putting pressure on industry revenue and margins, rewarding vendors that are quick to adapt to the new market imperatives," said Silvia Cosso, research manager, European Storage and Datacenter Research, IDC.
Western Europe
The Western European external storage market recorded the lowest YoY decline in the EMEA region, at -1.0% in dollars and 1.9% in euros. Capacity, on the other hand, grew by 7.6% to 2,366.2 petabytes.
Unfavorable exchange rates and tough competition are still dragging down the Western European market, but strong growth is still coming from the midrange and AFA segments. In fact, AFA storage solutions again registered strong YoY double-digit growth, albeit amidst an increasingly challenging competitive environment that is shaking up market share rankings in the region.
"As AFA systems have grown to account for a quarter of total Western European shipment value, the segment is heading toward maturity, showing horizontal adoption in terms of enterprise dimension and specialization, as well as workload coverage, also helped by a wider offer in diversified price ranges," said Archana Venkatraman, research manager, IDC Europe.
Central and Eastern Europe, the Middle East, and Africa
The external storage market in Central and Eastern Europe, the Middle East, and Africa (CEMA) declined again in the second quarter of 2017, with value declining 9% to $370.2 million and capacity slipping 4.7% to 748.3 terabytes. With nearly 24% share, AFAs considerably outperformed total market growth and together with hybrid solutions were responsible for 70% of the total market in CEMA.
"AFAs will continue to be the storage segment with the highest growth potential and CEMA is one of the top regions in terms of growth and penetration," said Marina Kostova, research manager, Storage Systems, IDC CEMA. "With NVMe maturity and new SSD technologies, we expect to see external flash storage developing in two directions: nurturing new technologies to boost the performance of HDD/flash hybrid arrays and offering AFA 'hybrid' solutions with different tiers of flash. Both of these will offer better performance and more accessible pricing, increasing the penetration but decreasing the market value."
By region, both Central and Eastern Europe (CEE) and the Middle East and Africa (MEA) performed better than in the previous quarter, paving the way to the long-expected market stabilization. A major boost came from high-end AFA arrays, which posted over 300% YoY growth to take more than 50% of the high-end segment value. Similar to last quarter, CEE market performance was stable, excluding Russia due to the weaker performance of some of the largest incumbents. MEA market value was almost flat year on year as large-scale projects in the pipeline came to fruition.
| Top 5 Vendors, EMEA External Disk Storage Systems Value ($M) | |||||
| Vendor | 2Q16 | 2Q16 Market Shares | 2Q17 | 2Q17 Market Shares | 2Q17 YoY Growth |
| Dell Inc. * | $514.28 | 32.71% | $409.58 | 26.85% | -20.36% |
| Hewlett Packard Enterprise ** | $267.22 | 17.00% | $248.61 | 16.29% | -6.97% |
| NetApp | $212.83 | 13.54% | $246.69 | 16.17% | 15.91% |
| IBM | $162.67 | 10.35% | $163.31 | 10.70% | 0.39% |
| Hitachi | $110.41 | 7.02% | $116.31 | 7.62% | 5.35% |
| Others | $304.89 | 19.39% | $341.22 | 22.36% | 11.92% |
| Grand total | $1,572.30 | 100.00% | $1,525.71 | 100.00% | -2.96% |
Notes: Dell Inc. represents the combined revenues for Dell and EMC. Hewlett Packard Enterprise includes the acquisition of Nimble, completed in April 2017.
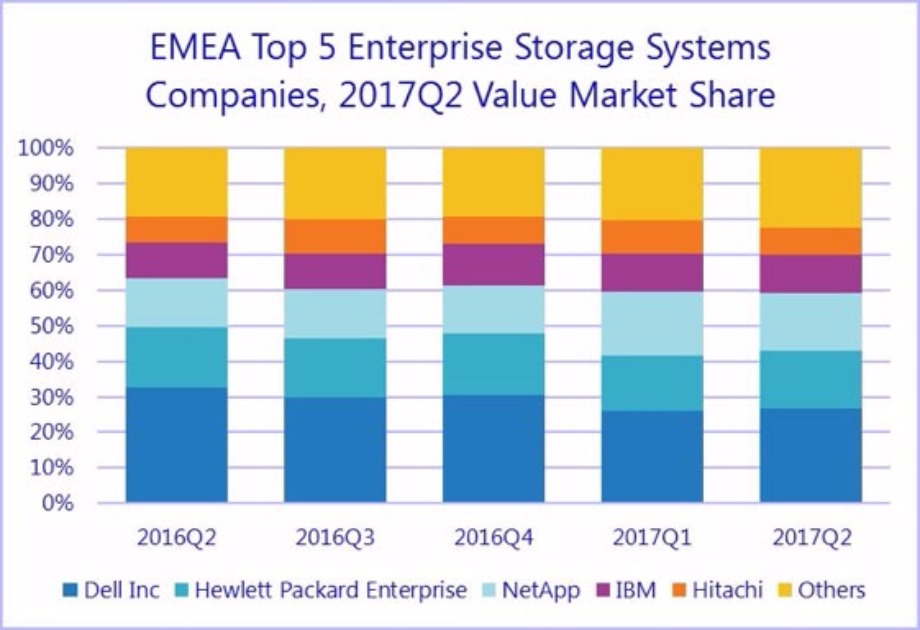

According to the International Data Corporation (IDC) Worldwide Quarterly Security Appliance Tracker, the total security appliance market saw positive growth in both vendor revenue and unit shipments for the second quarter of 2017 (2Q17). Worldwide vendor revenues in the second quarter increased 9.2% year over year to $3.0 billion and shipments grew 7.0% year over year to 706,186 units.
The trend for growth in the worldwide market driven by the Unified Threat Management (UTM) sub-market continues, with UTM reaching record-high revenues of $1.6 billion in 2Q17 and year-over-year growth of 16.8%, the highest growth among all sub-markets. The UTM market now represents more than 50% of worldwide revenues in the security appliance market. The Firewall and Content Management sub-markets also had positive year-over-year revenue growth in 2Q17 with gains of 9.5% and 6.4%, respectively. The Intrusion Detection and Prevention and Virtual Private Network (VPN) sub-markets experienced weakening revenues in the quarter with year-over-year declines of 11.7% and 1.3%, respectively.
Regional Highlights
The United States delivered 41% of the worldwide security appliance market revenue and was the major driver for spending in Q2 2017 with 9.2% year-over-year growth. Asia/Pacific (excluding Japan)(APeJ) had the strongest year-over-year revenue growth in 2Q17 at 20.9% and captured 23.9% revenue market share. The more mature regions of the world – the United States and EMEA – combined to provide nearly two thirds of the global security appliance market revenue. Both regions had positive growth in the single-digit range. Europe, the Middle East and Africa (EMEA) saw an annual increase of 2.3%. Asia/Pacific (including Japan)(APJ) and the Americas (Canada, Latin America, and the U.S.) experienced year-over-year growth of 17.2% and 8.8%, respectively.
"Over the last quarter, there has been growth in every region with particularly strong growth in Asia/Pacific. Firewall and UTM continue to be the strongest areas of growth, as those products continue to add security features leveraging and addressing cloud protection." said Robert Ayoub, research director, Security Products at IDC.
| Top 5 Vendors, Worldwide Security Appliance Revenue, Market Share, and Growth, Second Quarter of 2017 (revenues in US$ millions) | |||||
| Vendor | 2Q17 Revenue | 2Q17 Market Share | 2Q16 Revenue | 2Q16 Market Share | 2Q17/2Q16 Growth |
| 1. Cisco | $479.60 | 15.9% | $448.72 | 16.3% | 6.9% |
| 2. Palo Alto Networks | $421.09 | 14.0% | $333.68 | 12.1% | 26.2% |
| 3. Check Point | $380.32 | 12.6% | $358.05 | 13.0% | 6.2% |
| 4. Fortinet | $320.12 | 10.6% | $269.61 | 9.8% | 18.7% |
| 5. Symantec | $139.35 | 4.6% | $127.13 | 4.6% | 9.6% |
| Other | $1,267.10 | 42.1% | $1,216.50 | 44.2% | 4.2% |
| Total | $3,007.59 | 100.0% | $2,753.68 | 100.0% | 9.2% |
| Source: IDC Worldwide Quarterly Security Appliance Tracker Q2 2017 September 18, 201 | |||||

A survey by leading law firm Blake Morgan has revealed nine out of 10 businesses have still not made crucial updates to their privacy policies – a key requirement ahead of major changes to data protection laws.
As time runs out to comply with the General Data Protection Regulation (GDPR), the survey found many organisations may be at risk of non-compliance, risking regulatory action and reputational and brand damage for not getting their house in order.With the massive growth of the digital economy, GDPR represents the biggest shift in data protection for many years and all organisations which retain or process personal information will need to comply. The new law focuses on greater transparency as to how personal data is collected, retained and processed, makes organisations more accountable and gives enhanced rights to those whose personal data is being collected and processed.
It is backed up with a significantly higher fines regime for the most serious breaches of up to £17m or 4% of worldwide turnover (whichever is greater) and a requirement to notify personal data breaches within 72 hours where they are likely to result in a risk to people's rights and freedoms. Blake Morgan’s research revealed just over 10 per cent of those surveyed had updated their privacy policies to comply with the new law, while only a quarter had put in place systems to ensure data security breaches were notified in line with GDPR.
The findings showed almost 40 per cent of organisations surveyed had not taken steps to prepare for the new regulations, while more than a third were not confident they would be able to comply with GDPR by 25th May next year when the law comes into force. A key finding was that just over a fifth of businesses surveyed were not aware of GDPR and the forthcoming and related ePrivacy Regulation and what these will mean for their organisation. Simon Stokes, a Partner specialising in data protection law at Blake Morgan, said: “Our survey highlights that a significant proportion of organisations across the public and private sectors are still underprepared for these major changes to data protection law.
“There appears to be a genuine confusion among many business leaders about what the new law means and how to achieve full compliance. “Some of the survey comments highlight a desire for clearer guidance and the mountain of work that many organisations believe they are facing because of the sheer volume of data and a limited timescale. “With the clock counting down to the law coming into force, we would recommend a focused effort by businesses to get to grips with the changes and implement a strategic plan of action.
“GDPR Compliance is good corporate housekeeping. Not only will it avoid running the risk of financially and reputationally damaging fines or sanctions – ultimately it will assure the public’s trust in your organisation at a time when data privacy and security are more important than ever before. As the UK's data protection regulator ICO has recently highlighted GDPR is essentially about trust.” Important findings included: Only around one in 10 businesses (13 per cent) had updated privacy policies, one of the significant requirements of GDPR.
Almost a quarter of businesses (23 per cent) said they were unaware of the new data protection laws despite the looming deadline of 25 May 2018. Around four out of 10 businesses (39 per cent) had not taken any steps at all to prepare for the new law – leaving just months to act. Around four out of 10 businesses (38 per cent) were not confident they would be able to comply with GDPR by 25 May. Around one in five businesses (21 per cent) did not currently have a senior person in place responsible for data protection.
More than three quarters of businesses (76 per cent) had not put in place systems to ensure data security breaches are notified in line with GDPR. More than three quarters of businesses (77 per cent) had not reviewed their data processing contracts which will be under greater scrutiny under GDPR.
More than four out of 10 businesses (42 per cent) were unaware that the rules on direct marketing and the use of internet cookies are likely to change with the forthcoming ePrivacy Regulation which also has a target implementation date of 25 May 2018.

New Q2 data from Synergy Research Group shows that over the last 24 months, quarterly spend on all data center hardware and software has grown by just 5%, while spending on the public cloud portion of that has grown by 35%.
The private cloud infrastructure market has also grown, though not as strongly as public cloud, while spending on traditional, non-cloud data center hardware and software has dropped by 18%. ODMs in aggregate account for the largest portion of the public cloud market, with Cisco being the leading individual vendor, flowed by Dell EMC and HPE. The Q2 market leader in private cloud was Dell EMC, followed by HPE and Microsoft. The same three vendors led in the non-cloud data center market, though with a different ranking.
Total data center infrastructure equipment revenues, including both cloud and non-cloud, hardware and software, were over $30 billion in the second quarter, with public cloud infrastructure accounting for over 30% of the total. Private cloud or cloud-enabled infrastructure accounted for over a third of the total. Servers, OS, storage, networking and virtualization software combined accounted for 96% of the Q2 data center infrastructure market, with the balance comprising network security and management software. By segment, HPE is the leader in server revenues, while Dell EMC has a strong lead in storage and Cisco is dominant in the networking segment. Microsoft features heavily in the rankings due to its position in server OS and virtualization applications. Outside of these four, the other leading vendors in the market are IBM, VMware, Huawei, Lenovo, Oracle and NetApp.
“With cloud service revenues continuing to grow by over 40% per year, enterprise SaaS revenue growing by over 30%, and search/social networking revenues growing by over 20%, it is little wonder that this is all pulling through continued strong growth in spending on public cloud infrastructure,” said John Dinsdale, a Chief Analyst and Research Director at Synergy Research Group. “While some of this is essentially spend resulting from new services and applications, a lot of the increase also comes at the expense of enterprises investing in their own data centers. One outcome is that public cloud build is enabling strong growth in ODMs and white box solutions, so the data center infrastructure market is becoming ever more competitive.”

Following assessment and validation from the panel at Angel Business Communications. The shortlist for the 24 categories in this year’s SVC Awards has been put forward for online voting by our readership.
Voting is free of charge and must be made online at www.svcawards.com

The SVC Awards celebrate achievements in Storage, Cloud and Digitalisation, rewarding the products, projects and services as well as honouring companies and teams. The SVC Awards recognise the achievements of end-users, channel partners and vendors alike and in the case of the end-user category there will also be an award made to the supplier who nominated the winning organisation.
Voting remains open until 3 November so there is time to make your vote count and express your opinion on the companies that you believe deserve recognition in the SVC arena.
The winners will be announced at a gala ceremony on 23 November at the Hilton London Paddington Hotel.
Welcoming both the quantity and quality of the 2017 SVC Awards shortlist entries, Jason Holloway, Director of IT Publishing & Events at Angel, said: “I’m delighted that we have this annual opportunity to recognise the innovation and success of a significant part of the IT community. The number of entries, and the quality of the projects, products and people they represent, demonstrate that the SVC Awards continue to go from strength to strength and fulfil an important role in highlighting and recognising much of the great work that goes on in the industry.”
All voting takes place on line and voting rules apply. Make sure you place your votes by 3 November when voting closes. Visit : www.svcawards.com
Storage Project of the Year
Cohesity supporting Colliers International
DataCore Software supporting Grundon Waste Management
Mavin Global supporting The Weetabix Food Company
Cloud / Infrastructure Project of the Year
Axess Systems supporting Nottingham Community Housing Association
Correlata Solutions supporting insurance company client
Navisite supporting Safeline
Hyper-convergence Project of the Year
HyperGrid supporting Tearfund
Pivto3 supporting Bone Consult
UK Managed Services Provider of the Year
EACS
EBC Group
Mirus IT Solutions
netConsult
Six Degrees Group
Storm Internet
Vendor Channel Program of the Year
NetApp
Pivot3
Veeam Software
International Managed Services Provider of the Year
Alert Logic
Claranet
Datapipe
Backup and Recovery / Archive Product of the Year
Acronis – Backup 12.5
Altaro Software – VM Backup
Arcserve - UDP
Databarracks – DraaS, BaaS, BCaaS solutions
Drobo – 5N2
NetApp – BaaS solution
Quest – Rapid Recovery
StorageCraft – Disaster Recovery Solution
Tarmin – GridBank
Cloud-specific Backup and Recovery / Archive Product of the Year
Acronis – Backup 12.5
CloudRanger – SaaS platform
Datto – Total Data Protection platform
StorageCraft – Cloud Services
Veeam Software - Backup & Replication v9.5
Storage Management Product of the Year
Open-E – JovianDSS
SUSE – Enterprise Storage 4
Tarmin – GridBank Data Management platform
Virtual Instruments – VirtualWisdom
Software Defined / Object Storage Product of the Year
Cloudian – HyperStore
DDN Storage – Web Object Scaler (WOS)
SUSE – Enterprise Storage 4
Software Defined Infrastructure Product of the Year
Anuta Networks – NCX 6.0
Cohesive Networks – VNS3
Runecast Solutions – Analyzer
Silver Peak – Unity EdgeConnect
SUSE – OpenStack Cloud 7
Hyper-convergence Solution of the Year
Pivot3 - Acuity Hyperconverged Software Platform
Scale Computing - HC3
Syneto - HYPERSeries 3000
Hyper-converged Backup and Recovery Product of the Year
Cohesity – DataProtect
ExaGrid - HCSS for Backup
Syneto - HYPERSeries 3000
PaaS Solution of the Year
CAST Highlight - CloudReady Index
Navicat – Premium
SnapLogic - Enterprise Integration Cloud
SaaS Solution of the Year
Adaptive Insights – Adaptive Suite
Impartner – PRM
IPC Systems - Unigy 360
Ixia - CloudLens Public
SaltDNA - Secure Enterprise Communications
x.news information technology gmbh – x.news
IT Security as a Service Solution of the Year
Alert Logic – Cloud Defender
Barracuda Networks - Essentials for Office 365
SaltDNA - Secure Enterprise Communications
Votiro - Content Disarm and Reconstruction technology
Cloud Management Product of the Year
CenturyLink - Cloud Application Manager
Geminaire - Resiliency Management Platform
Highlight - See Clearly - Business Performance Acceleration
HyperGrid – HyperCloud
Rubrik – CDM platform
SUSE - OpenStack Cloud 7
Zerto - Virtual Replication
Storage Company of the Year
Acronis
Altaro Software
DDN Storage
NetApp
Virtual Instruments
Cloud Company of the Year
Databarracks
Navisite
Six Degrees Group
Storm Internet
Hyper-convergence Company of the Year
Cohesity
Pivot3
Syneto
Storage Innovation of the Year
Acronis - Backup 12.5
Altaro Software - VM Backup for MSP’s
DDN Storage - Infinite Memory Engine
Excelero – NVMesh
Nexsan – Unity
Cloud Innovation of the Year
CloudRanger – Server Management platform
IPC Systems - Unigy 360
SaltDNA - Secure Enterprise Communications
StaffConnect - Mobile App Platform
Zerto - ZVR 5.5
Hyper-convergence Innovation of the Year
Pivot3 - Acuity HCI Platform
Schneider Electric - Micro Data Centre Solutions
Syneto - HYPERSeries 3000
Digitalisation Innovation of the Year
Asperitas – Immersed Computing
IGEL - UD Pocket
Loom Systems - AI-powered log analysis platform
MapR – XD
For more information and to vote visit: www.svcawards.com
True or false? When it comes to Tier Certification, just ask Uptime Institute.
By Uptime Institute Staff.
Uptime Institute’s Tier Classification System for data centers has reached the two-decade mark. Since its creation in the mid-1990s, Tiers has evolved from a shared industry terminology into the global standard for third-party validation of data center critical infrastructure.
In that time, the industry has changed, and Tiers has evolved with it, remaining as relevant and important as it was when Uptime Institute first developed and disseminated Tiers. At the same time, Uptime Institute has observed that public understanding of Tiers has been clouded by the many myths and misconceptions that have developed over the years.
Uptime Institute has long been aware that not everyone fully understands the concepts described by the Tier Standards, and yet others disagree with some of the definitions. Both these situations lead to classic misunderstandings in which individuals substitute their preferences for accurate information. Other times, however, marketers have invoked a kind of shorthand based on Tiers. While objectionable, these marketers have coined terms like Tier III plus when speaking to their potential customers. These terms have no basis in Tiers but can be especially confusing to IT, real estate, procurement personnel, and even CFOs, all of whom might lack a technical background.
Other myths develop because some industry professionals reference old, out-of-date publications and explanatory material that is no longer valid. There may be other sources of myth, but knowing that the Uptime Institute is the only source of current and reliable information about Tiers is what is really important. We conduct numerous classes during the year, write many articles, and eld numerous inquiries to keep the industry current on Tiers.
Fundamentally, Uptime Institute created the Tier Classification System to consistently evaluate various data center facilities in terms of potential site infrastructure performance, or uptime. The system comprises four Tiers; each Tier incorporates the requirements of the lower Tiers.
Data center infrastructure costs and operational complexities increase with Tier level, and it is up to the data center owner to determine the Tier that fits the business’s need.
Uptime Institute is the only organization permitted to Certify data centers against the Tier Classification System. Uptime Institute does not design, build, or operate data centers. Uptime Institute’s role is to evaluate site infrastructure, operations, and strategy.
From this experience, we have compiled and addressed many of the myths and misconceptions. You can read about some of these experiences in Uptime Institute eJournal articles such as “Avoid Failure and Delay on Capital Projects: Lessons from Tier Certification” and “Avoiding Data Center Construction Problems.” For even more information, please contact us at https://uptimeinstitute.com/contact.
False. Tiers is a performance-based, business-case-driven data center benchmarking system. An organization’s risk tolerance determines the appropriate Tier for the business. In other words, Tiers is predicated on the business case of an individual company. Companies that fail to develop a unique business case for their facilities before developing a Tier objective are misusing Tiers and bypassing the internal dialogue that needs to occur.
False. An organization’s tolerance for risk determines the appropriate Tier to support the business objective. Tier IV is not the best answer for all organizations, and neither is Tier II. Owners should perform due diligence assessments of their facilities before determining a Tier objective. If no business objective is defined, then Tiers may be misused to rationalize unnecessary investment.
Tier I and Tier II are tactical solutions, usually driven more by first-cost and time-to-market than life-cycle cost and performance (uptime) requirements. Organizations selecting Tier I and Tier II solutions typically do not depend on real-time delivery of products or services for a significant part of their revenue stream. Generally, these organizations are contractually protected from damages stemming from lack of system availability.
Rigorous uptime requirements and long-term viability are usually the reason for selecting strategic solutions found in Tier III and Tier IV site infrastructure. In a Tier III facility, each and every capacity component can be taken out of service on a planned basis, without affecting the critical environment or IT processes. Tier IV solutions are even more robust, as each and every capacity component and distribution path can sustain a failure, error, or unplanned event without impacting the critical environment or IT processes.
A Tier IV solution is not better than a Tier II solution. The performance and capabilities of a data center’s infrastructure should match a business application; otherwise companies may overinvest or take on too much risk.
For example, before building a Tier II Certified Constructed Facility, which by definition does not include Concurrent Maintainability across all critical subsystems, an owner should consider whether the business can tolerate a planned or maintenance-related shutdown and how the site operations team would coordinate a site-wide shutdown for maintenance. Similarly business objectives should drive decisions to build a Tier I, Tier III, or Tier IV Certified Constructed Facility.
False. Tier Certification is a performance-based evaluation of a data center’s specific infrastructure; it is not a checklist or cookbook. Unfortunately, some industry shorthand employs N terminology—where N is de ned as the number of components that are minimally required to meet the load demand—to define availability. Incorporating more equipment can be described as designing an N+1, N+2, 2N, or 2(N+1) facility. However, increasing the component count does not determine or guarantee achievement of any specific Tier level, because Tiers also includes evaluation of distribution pathways and other system elements. Therefore, it is possible to achieve Tier IV with just N+1 components, depending on how they are configured and connected to redundant distribution pathways.
False. The first step in a Tier Certification process is a Tier Certification of Design Documents. Uptime Institute Consultants review the 100% design documents, ensuring each electrical, mechanical, monitoring, and automation subsystem meets the fundamental concepts and there are no weak links in the chain. The Design Certification is intended to be a milestone so that data center owners can commence data center construction knowing that the intended design meets the Tier objective.
Tier Certification of Design Documents applies to a document package. It is intended as provisional verification until the Tier Certification of Constructed Facility. Uptime Institute has not verified the constructed environment of these facilities, and thus cannot speak to the standard(s) to which they were built. To emphasize this point, Uptime Institute implemented an expiration date on Design Certifications. All Tier Certification of Design Documents awards issued after 1 January 2014 expired two years after the award date.
During a Facility Certification, a team of Uptime Institute consultants conducts a site visit, identifying discrepancies between the design drawings and installed equipment. The consultants observe tests and demonstrations to prove Tier compliance. Fundamentally, this is the value of the Tier Certification, finding these blind spots and weak points in the chain. Uptime Institute consultants say that in almost every site visit they find that changes have been made after the Design Certification was awarded so that one or more systems or subsystems will not perform in a way that complies with Tier requirements.
More recently, Uptime Institute instituted the Tier Certification of Operational Sustainability to evaluate how operators run and manage their mission-critical facilities. Even the most robustly designed and constructed facilities may experience outages without a well-developed comprehensive management and operation program. Certification at all three levels is how data center owners can be assured they are realizing the maximum potential of their data centers.
False. Uptime Institute removed references to “expected downtime per year” from the Tier Standard in 2009, but they were never a part of the Tier definitions. Tier Standard: Topology is based on specific performance factors (outcomes) that demonstrate that a facility has met specific performance objectives, such as having redundant capacity components, Concurrent Maintainability (generally, the ability to remove any capacity or distribution component from service on a planned basis without impacting IT), or Fault Tolerance (generally, the ability to experience any unplanned failure in the site infrastructure without impacting IT). However, even a Tier IV data center, which is Fault Tolerant, may experience IT outages if it is not operated and managed effectively.
There are statistical tools to predict the frequency of failures and time to recover. Availability is simply the arithmetic calculation of time a site was available over total time. The number, frequency, and duration of disruptions will drive the availability result. However, caution is appropriate when using these tools. Human activity is often not considered by statistical models. In addition, the statistical prediction of a 100-year storm, for example, can obscure the possibility that several 100-year storms can happen in the same year.
False. Uptime Institute has Certified many existing buildings. However, the process can be more challenging when working in facilities with live loads. For best results with an existing facility, the process should begin with a Tier Gap Analysis rather than a formal Certification effort. Tier Gap Analysis provides a high-level summary review for major Tier shortfalls. This allows the owner to make an informed decision whether to proceed with a detailed, exhaustive Certification effort. Tier Certification of Constructed Facility can be performed with any load profile, including resistive load banks, live critical IT load, or a mix.
False. Uptime Institute is currently delivering Tier Certifications in more than 85 countries. Tiers, which allows for many solutions and a variety of configurations, gives the design, engineering, and operations teams the flexibility to meet both local regulations and performance requirements. To date, there has not been a conflict between Tiers and local building codes, statutes, or jurisdictions.
False. In 2014 Uptime Institute and the Telecommunications Industry Association (TIA) agreed on a clear separation between their respective benchmarking systems to avoid industry confusion and drive accountability. In fact, any reference to the TIA rating of a data center may not include the word Tier.
The core objective of Uptime Institute Tiers is to define performance capabilities that will deliver availability required by the data center owner. By contrast, TIA member company experts focus on the need to support the deployment of advanced communications networks. See https://uptimeinstitute.com/uptime-tia for a more detailed explanation.
False. According to Tier Standard: Topology, the only reliable source of power for a data center is the engine- generator plant. This is because utility power is subject to unscheduled interruption—even in places with reliable power grids. As a result, the number of utility feeds, substations, and power grids that provide public power to a data center neither predicts nor influences Tier level. As a consequence, utility power is not even required for Tiers. Most Tier Certified data centers use utility power for main operations as an economic alternative, but this decision does not affect the owner’s target Tier objective.
False. Tiers does not require that the engine-generator plant actually run at all times; however, data centers will typically utilize a public utility a majority of the time for cost or regulatory reasons. At the same time, the engine-generator plant must be properly configured, rated, and sized to have the capability to carry the critical load without runtime limitations. Hence, the performance requirements outlined in the Tier Standard must be met with the data center supported by engine-generator power. Meeting these criteria requires special attention to engine-generator capacity ratings and power distribution.
False. There is no correlation between EPA’s Tiers (or other restrictions of engine-generator operation) and Uptime Institute Tiers, except that both systems use a similar hierarchical system of nomenclature. The EPA’s limits on runtime may complicate a facility’s testing and maintenance regimens and add costs when a facility is forced to rely on backup power for an extended period. However, runtime limitations posed by local authorities do not exempt a data center from having on-site power generation rated to operate without runtime limitations at a constant load.
False. When code or the local authority having jurisdiction (AHJ) mandate an EPO, this does not prohibit Tier compliance. At the same time, Uptime Institute does not recommend EPO installation, unless it is compelled by a local code because even Tier Certified data centers are vulnerable to outages from purposeful or accidental activation of the EPO system. Analysis of the Uptime Institute Network’s Abnormal Incident Report (AIRs) database confirms that accidental EPO activation is a recurring cause of downtime.
The Tiers Standard requires that maintenance, isolation, and/or removal can be performed on the EPO system without affecting the critical load for Tier III data centers. Tier IV data centers additionally require a Fault Tolerant EPO system.
False. The choice of under floor or overhead cooling is a decision to be made by the owner based an operational preference. In Uptime Institute’s experience, a raised floor enhances operational flexibility over the long term. Yet, decisions such as raised floor or on-slab, Cold Aisle/Hot Aisle, containment of Cold Aisle/Hot Aisle, and gallery cooling can affect the efficiency of the computer room environment, but are not mandated by Uptime Institute Tiers.
True. The Tier Standard includes a concession for equipment with odd numbers of cords (1,3,5) in the form of rack-mounted transfer switches to provide access to multiple power paths. However, Tier III and Tier IV data centers must still have multiple and independent feeds to the rack.
The Tier Standard focuses on ensuring that the facility’s infrastructure meets the requirements of the Tier objective. There are many reasons why a facility may contain single-corded IT devices or those with an odd number of power supplies, including lack of knowledge of the facility impacts, lack of options for equipment vendors, and colocation environments where facility personnel have no control over the types of IT devices within the data center. Rack-based transfer switches are most typically supplied by the IT side of the organization, so the facility’s infrastructure can meet the Tier objective. However, planned isolation or fault of these rack-based transfer switches may lead to an outage for individual racks or devices.
Partially true. Tier II allows for Concurrent Maintenance of capacity components, but not distribution pathways or critical elements. So a Tier II Certified facility can perform Concurrent Maintenance on engine generators, UPS, chillers, cooling towers, pumps, air conditioners, fuel tanks, water tanks, and fuel pumps
but not switchboards, panels, transfer switches, transformers, bus bars, cables, and pipes. In many cases, this limitation will require the computer room to be shutdown for planned maintenance or replacement of critical pathways and elements.
The requirement to maintain any component, pathway, or element without shutting down equipment, known as Concurrent Maintainability, defines Tier III. Many owners’ business cases, including healthcare, domestic outsourcers, and state governments, require Tier III. The list of organizations that have protected their investment with Tier Certifications may be found on Uptime Institute’s website.
Partially true. Tier III requires active/active distribution for critical power distribution (which is defined as the output of the UPS and below). Outside of that, active/inactive is acceptable. This means that if a rack receives dual power from two separate power distributions, they must both normally be active. It is not allowable to have one feed normally disabled, nor is it Tier III compliant to have one of the power feeds directly fed from utility power while bypassing a UPS power source.
There are no active/active requirements for mechanical systems in Tier III data centers. So if there are N+1 chillers in a Tier III facility, with each chiller feeding separate A and B chilled water loops, it is permissible for one of the loops to be normally disabled, with all air conditioners normally fed from the same loop.
False. Infrastructure changes must be approached using carefully developed and written procedures and processes. If the topology of a facility changes, it may no longer be Concurrently Maintainable or Fault Tolerant, so clients should have Uptime Institute review designs and construction that might affect a facility’s topology to protect their investment and Tier Certification. Tier Certifications can be revoked if unreviewed changes compromise a facility’s Concurrent Maintainability or Fault Tolerance.
Mostly false. The Tier Standard requires only that Tier IV facilities provide stable cooling to the IT and UPS environment for the time it takes for the mechanical systems to completely restart after a utility power outage and provide rated load to the data center. Tier IV data centers must also be able to maintain a stable thermal environment for the duration of the mechanical restart time and for any 15-minute period in accordance with the 2015 ASHRAE Thermal Guidelines. Tier IV facilities are also required to be active/active for all systems. This is intended to ensure that Continuous Cooling solutions are not negated by a lack of active operation of components. A lightly loaded data center or one with a very complex control system may be able to meet these requirements, without using all the available cooling units. However, there are Tier IV data center designs, especially those at full load, that would in fact require all units to run during normal operations.
Typically false. Makeup air systems in data center applications are typically designed to meet one of three objectives (or a combination of the three):
Data centers are rarely designed in a manner that require the makeup air handler to be active in order to meet the N cooling capacity requirement. However, the existence of a makeup air handler and its operations cannot negatively impact compliance with Tiers. For example, if a makeup air handler is not sized to ASHRAE extremes in compliance with Tiers, the additional heat load from this air handler at those conditions must be considered when sizing the critical cooling system.
False. The Tier Standard is vendor and technology neutral, which means it is possible to Tier Certify facilities that include a wide variety of innovative and new technologies, including DRUPS.
Facilities tend to deploy DRUPS, which combine a diesel engine and a rotary UPS that uses kinetic energy to eliminate batteries, which require high levels of maintenance, somewhat frequent replacement, and a lot of extra space for battery placement/storage. This design usually provides ride-through times of between 10-30 seconds, depending on the application, which is shorter than other technologies. The Tier Standard does not include a minimum ride-through time. In fact, Uptime Institute has Certified several facilities that include DRUPS technology.
DRUPS may also be used to power motor loads. That means that caution must be exercised to ensure that the DRUPS have sufficient capacity to power each and every system and subsystem, including cooling systems, which is accomplished by putting the mechanical components on a no-break bus.
False. Tier Certification analyzes each and every system and subsystem down to the level of valve positions and panel feeds. Ductwork, just like piping systems, may need planned maintenance, replacement, or reconfiguration. As such, traditional ductwork distribution systems must meet the requirements of the Tier objective.
Uptime Institute understands that there is a lot of confusion about what “maintaining” ductwork means to meet Concurrently Maintainable requirements. But in this case, Concurrent Maintainability is about having the capability to isolate a system or part of a system to maintain, repair, upgrade, or reconfigure the data center without impacting any of the computer equipment.
False. Although a critical consideration for the life-cycle operation of the facility and in determining, evaluating, and mitigating risk to the data center, geographical location does not affect a facility’s Tier level and is not part of the Tier Standard: Topology.
Data center designers can take precautions to address the specific risks of a site. A data center sited in a high-risk earthquake zone can include equipment that has been seismically rated and certified as well as incorporate techniques that mitigate damage from seismic activity. Or if a data center has been sited in a high-risk tornado area, designers can consider wind protection measures for the exterior electrical and heat rejection equipment.
Site Location is a criterion in the Tier Certification of Operational Sustainability.

By Steve Hone CEO, The DCA
This
month’s DCA journal theme is Smart Cities, Big Data, Cloud and IoT. All of
these topics are intrinsically linked and put the data centre at the heart of
the Internet of Everything. As more smart city projects are rolled out the
reliance on data centres to support these services will become more and more
critical to the health and sustainability of our society.

Someone asked me today to predict the future demand over the next 10 years. Taking a leaf out of the politician’s guide book I decided to skirt round the question simply because I’m not sure anyone can truly know where this road will lead us in the next five years, let alone ten. Maybe we will all be flying around like the “Jetsons” by then – Wow! Now that shows my age!
What I do know is if you think we produce a lot of data now “you ain’t seen nothing yet”. The concept of smart cities and IoT is only just in its infancy and as it matures it will in turn produce a mind-boggling amount of data which will all need to be gathered, stored, processed and analysed somewhere, and that somewhere will probably be in a data centre. A more interesting question is - what will a data centre in 2027 look like?
So, if IoT, Cloud and Big Data are helping to facilitate these Smart City initiatives what’s the driver behind it? Well, the answer is “necessity”.
At the start of the 2nd World War we were still flying around in prop planes covered in fabric; within six years we had jet fighters; you can say the same for Radar, Sat Nav and even the first computer. All these innovations were driven though necessity.
The necessity to initiate Smart City projects is largely driven by the increase of the global population and more importantly the fact that a sizable percentage of the population are choosing to live in cities. If you look at the figures of any city around the world, urbanisation continues to increase at an alarming rate. The reason for this is more than just a tribal or herding instinct; go back a hundred years and this move in population was because of the mechanisation of farming which drove people towards towns and cities to find work. This migration to our cities has continued to accelerate ever since at a rate of 150,000 every day according to latest figure. Between 2011 and 2050, the world’s urban population is projected to rise by 72 %; from 3.6 billion to 6.3 billion. Demographers predict that by the end of the next century half of the world's population will be urban dwellers.
The traditional methods of supporting our cities inhabitants is simply not going to be scalable enough when faced with this predicted explosion in the population. We need to start to work smarter not harder to ensure all services (both public and private) operate at optimum efficiency if we are to continue to support our citizens and achieve economic, social, and environmental sustainability.
This will also only be made possible by improving a city’s efficiency, this requires the integration of new infrastructure and services. While the availability of smart solutions for cities continues to rise rapidly we need to make sure the data centre sector can respond and keep pace.
This transformation also requires radical changes in the way cities are run today, therefore developing smart cities is not just a process allowing technology providers to offer technical solutions and of city authorities implementing them; but the development of the right environment for smart solutions to be effectively adopted and used.
The DCA continues to provide a trusted environment where knowledge can be both shared and gained and where collaboration can flourish. Thank you to all the contributors this month and I look forward to a time when my car drives me to work while I read the paper, I have a feeling I won’t have long to wait.
The next edition provides you all with an opportunity to let your customers speak for you and tell everyone how great you are; the deadline for “End User Case Studies” is the 24th October. Please forward all submissions to Amanda McFarlane - amandam@datacentrealliance.org
By Ian Shaylor, Head of Customer Insights and Data, British Gas Business
The myth that ‘big data’ is somehow the preserve of large corporations like British Gas Business lingers over many small firms.

These large, complex datasets may sound overwhelming but when it comes to interpreting and applying this information to add business value, being small can actually be an advantage. This is because small businesses tend to be more agile than larger corporations and can therefore act more quickly on the insights offered by big data. And having access to analytics can be insightful, regardless of the actual size or scale of your dataset.
Whatever business you’re in, you’re part of a supply chain and you’re likely to already be part of the big data picture – particularly if you have big corporate customers who are almost certainly using big data business analytics to assess what is being delivered. On this basis, there’s no ‘opt-out’ clause. The smart reaction is to look at big data as an opportunity and play your scale and agility in your favour.
Another myth is that applying business analytics is an expensive process but in fact there are many simple, low-cost – or sometimes even free – tools and software packages available that can make analytics accessible. Google analytics, for example is a free means of gathering customer insights, while Microsoft’s Azure range is affordable for small businesses. And some of your suppliers may also offer tools to help you analyse specific sets of data.
To use data analytics most effectively, it’s important to stay focused and start small. Identify the specific business issue that you would like business analytics to solve or the question that you want analytics to help you answer.
Are you looking, for example, to better understand how your customers use your website or do you want to assess whether your own perception of your industry matches that of the market? By pinpointing the issue, you will be able to use the available analytics most effectively for your purpose.
To really take advantage of the benefits of big data, having someone near the top of your business with strong analytical and technical abilities as a business analytics champion can make a big difference. This person should be an advocate for data-backed insights and their use in decision-making and should ensure that the application of data across the business grows at a manageable rate.
One way that small businesses across the UK can use big data to their advantage is by analysing their energy consumption to understand how energy is being used and where changes can be made to improve efficiency. As a first step, you need to have a smart meter installed. More than a third of our business customers already have this technology. Smart meters automatically send readings securely to energy suppliers. This means more accurate bills but also more data that can be analysed to help small firms add value to business.
At British Gas Business, we analyse the data we collect in order to provide helpful insights that allow our customers to take advantage of energy efficiencies as part of the smart meter code of practice.
For example, recently we wrote to all our smart customers who were using a lot of energy out-of-hours to offer them advice on how to reduce this consumption. Businesses – both large and, more often, small – benefit from personalised guidance and free insight thanks to big data.
But, you can also analyse your own data and play around with this to understand patterns of energy usage. Our free online Business Energy Insight tool helps you see how much electricity you’re using by year, month, week, day and even hour. The dataset that you will be working with will be small and manageable and provide actionable insights but it is because of big data that you will be able to do this.
While we are at the forefront of this revolution and see it as an opportunity to offer market leading service in energy, other companies in other industries will be offering similar opportunities also.
Big data provides big opportunities for small businesses – and these will only continue to grow over the coming years. Using analytics to understand specific business issues will help your business to develop strategies that are backed by data and insight – and ultimately add value.
Rolf Brink, CEO and Founder, Asperitas
Sustainability has been a theme within the IT industry since the introduction of the energy star label for hardware. Since 2007 sustainable digital infrastructure became a topic internationally shaped by a variety regional organisations running green IT programs to reduce the footprint of layers within digital infrastructure including datacentres.

Reducing the overall footprint of the datacentre industry is an impossible challenge as the rate growth of the adoption of digital services, and therefore the need for infrastructure, has outpaced the rate at which the energy footprint can be reduced. Industry orchestration will be needed if this challenge is to be met and new standards for datacentre sustainability are to be set. Years have passed and excess datacentre heat reuse is still not delivering its promise, often because technology, organisational and operational elements cannot be matched. Recently stakeholders have been aiming to change that by stimulating a new role for datacentres, which is the transformation we still need to see on a large scale: the transformation from energy consumers to flexible energy prosumers in smart cities. This is possible with technologies available today, the future is now!
FROM ENERGY CONSUMER TO ENERGY PRODUCER
The global move to cloud based infrastructures and the Internet of Things (IoT) generates high demand for datacentre capacity and high network loads. The energy demand of datacentres is rising so quickly that it is causing serious issues for energy grid operators, (renewable) energy suppliers and governments. Grid operators and energy suppliers can hardly keep up with the demand in the large datacentre hubs let alone ensure enough renewable energy generation is available where we see the demand. Not only does this raise questions of sustainability on all levels, the demand for flexibility and high loads requires a different approach to the business model of the datacentre. With the ultimate challenge of becoming an energy neutral industry.
The key to resolving this challenge is the adoption of liquid cooling techniques in all its forms. Asperitas is committed to approaching this challenge head-on by taking an active role in discarding the limitations of IT systems and datacentre infrastructures of today to find new ways to drastically improve datacentre efficiency. This can help to develop a future where the datacentre is transformed from energy consumer to energy producer. These excerpts from our whitepaper present our vision of the datacentre of the future. A datacentre that faces the challenges of today and is ready for the opportunities of tomorrow.
With all these advantages, liquid offers solutions that are just not attainable in any other way. This is why liquid is the future for datacentres. But what does this future look like? Which liquid technologies are available and what does this mean for the infrastructure of the datacentre?
In the next chapter, we outline the basic liquid technologies operating in datacentres today. After that we explore the most beneficial environment for these technologies: a hybrid temperature chain. Further on, a model of connected, distributed datacentre environments is introduced. With the dedication to liquid, Temperature Chaining and the distributed datacentre model, the datacentre of the future transforms from energy consumer to energy producer. This approach will drastically reduce the carbon impact of datacentres while stimulating the energy efficiency of unrelated energy consuming industries and consumers.
THE HYBRID INFRASTRUCTURE
The introduction of water into the datacentre whitespace is most beneficial within a purpose-built set-up. This focus for the design of the datacentre must be on absorbing all the thermal energy with water. This calls for a hybrid environment in which different liquid based technologies are co-existing to allow for the full range of datacentre and platform services, regardless of the type of datacentre.
Immersed Computing® provides easy deployable, scalable local edge solutions. These allow for rejecting heat to whatever reuse scenario is present, like thermal energy storage, domestic water, city heating etc. If no recipient of heat is available, only a dry cooler is sufficient. Reducing or even eliminating the need for overhead installations like coolers for edge environments, providing a different perspective on datacentres. Geographic locations become easier to qualify and high quantities of micro installations can be easily deployed with minimal requirements. These datacentres will be integrated in existing district buildings or multifunctional district centres. A convenient location for the datacentre is a place where heat energy will be utilised throughout the whole year. Datacentres can also be placed as a separate building in residential and industrial areas. This creates the potential for a connected datacentre web consisting of mainly two types of datacentre environments. Large facilities (Core Datacentres) which are positioned on the edge of urban areas or even farther away and micro facilities (Edge Nodes) which are focused on optimising the large network infrastructure and are all interconnected with each other and with all core datacentres.
The main purpose of the edge nodes is to reduce the overall network load and act as an outpost for IoT applications, content caching and high bandwidth cloud applications. The main function of the core datacentres is to ensure continuity and availability of data by acting as data hubs and high capacity environments.
This is an excerpt of an Asperitas whitepaper: the Datacentre of the Future, authored by Rolf Brink, CEO and founder of Asperitas. This whitepaper was presented at the DCA’s Datacentre Transformation event in Manchester.
http://asperitas.com/resource/immersed-computing-by-asperitas/
By Lewis Page, Editor of CW Journal
Almost everyone involved in the automotive, transport and mobility sectors believes that significant technology-driven change is coming. Both established vehicle manufacturers and new entrants like Google and Tesla have many projects underway, not only aimed at autonomous or “driverless” cars but also exploring the various concepts grouped under the banner of Mobility as a Service (MaaS).

One idea here is that the cost of using shared vehicles - particularly ones with autonomous driving capability and/or networking - could be considerably less than the cost of owning a vehicle personally, and perhaps the shared vehicle might be more useful too.
These concepts were explored by a group of speakers and attendees at the CWIC Starter: Transport and Mobility event in March this year. All the stakeholders were there: car makers, autonomy developers, telematics and traffic analysts, shared and hire-car services, the insurance industry and - naturally, given that this subject will hinge so much on future regulations - lawyers.
Many interesting concepts were brought up. Julian Turner of Westfield Sportscars, a company famous for offerings such as the GTM - very much drivers’ cars - was nonetheless very enthusiastic about the possibilities which autonomy and networking could unleash for vehicle manufacturers. Westfield is developing the concept of driverless “pods” useful for “last mile” tasks such as home deliveries, school runs and mobility within large complexes such as hospitals or shopping centres.
If autonomy can deliver on its promise of much greater safety, there might be no need any longer for heavy crash structures in pods and other vehicles. This could permit the production of easily recyclable cellulose vehicles, or even ones in which the bodywork is made of carbon and helps propel the car by being part of a supercapacitor. Supercapacitors offer much less range than today’s li-ion EVs, but have the advantage of charging up in less than a minute and being more durable.
Quite apart from autonomy there is the matter of future vehicle networking, a field which is potentially even more complex - especially if networking is used for safety, with attendant legal ramifications. The problems of autonomous driving could be appreciably simplified, for instance, if every vehicle were sharing its location, direction of travel, speed (and perhaps, its intentions) with other vehicles nearby. Ships at sea already do this using AIS, and such systems are also in use in aviation. Such a system could have prevented the well-known crash last year in which a Tesla car on “Autopilot” hit a truck crossing the road ahead: neither the car’s sensors nor the driver detected the light coloured trailer against the light sky.
Networking between vehicles and traffic-control infrastructure could also permit autonomous vehicles to tailgate as routine at high speeds, allowing the roads to carry much more traffic and hugely improving fuel efficiency. This is an idea imagined as long ago as the 1970s, of course (Judge Dredd’s megacity of the future had a prison placed on a traffic island, normally escape proof due to the continual flow of high speed computer controlled vehicles around it).
It could even be that the autonomous, networked vehicles of the future would mean more personal cars and journeys, not fewer. With a personal car that could be summoned from afar by app, you would not need a parking space either at work or at home to use it for commuting: more people might choose to own a car. In such a case there would be as many as six car journeys per commuter per day rather than just two.
The CWIC event did make one thing about the future of mobility clear. Almost all participants agreed that it will be difficult to build the future without some clarity on the legal and regulatory frameworks which will be in place. At the moment, however, no vehicle has yet been permitted onto a public road anywhere without a human driver.
The technology will be there: indeed, in many cases it is already there. It isn’t clear when it will be allowed to reach its full potential, however.

Dr Marcin Budka, Principal Academic in Data Science at Bournemouth University
The alarm on your smart phone went off 10 minutes earlier than usual this morning. Parts of the city are closed off in preparation for a popular end of summer event, so congestion is expected to be worse than usual. You’ll need to catch an earlier bus to make it to work on time.

The alarm time is tailored to your morning routine, which is monitored every day by your smart watch. It takes into account the weather forecast (rain expected at 7am), the day of the week (it’s Monday, and traffic is always worse on a Monday), as well as the fact that you went to bed late last night (this morning, you’re likely to be slower than usual). The phone buzzes again – it’s time to leave, if you want to catch that bus.
While walking to the bus stop, your phone suggests a small detour – for some reason, the town square you usually stroll through is very crowded this morning. You pass your favourite coffee shop on your way, and although they have a 20% discount this morning, your phone doesn’t alert you – after all, you’re in a hurry.
After your morning walk, you feel fresh and energised. You check in at the Wi-Fi and Bluetooth-enabled bus stop, which updates the driver of the next bus. He now knows that there are 12 passengers waiting to be picked up, which means he should increase his speed slightly if possible, to give everyone time to board. The bus company is also notified, and are already deploying an extra bus to cope with the high demand along your route. While you wait, you notice a parent with two young children, entertaining themselves with the touch-screen information system installed at the bus stop.

Once the bus arrives, boarding goes smoothly: almost all passengers were using tickets stored on their smart phones, so there was only one time-consuming cash payment. On the bus, you take out a tablet from your bag to catch up on some news and emails using the free on-board Wi-Fi service. You suddenly realise that you forgot to charge your phone, so you connect it to the USB charging point next to the seat. Although the traffic is really slow, you manage to get through most of your work emails, so the time on the bus is by no means wasted.
The moment the bus drops you off in front of your office, your boss informs you of an unplanned visit to a site, so you make a booking with a car-sharing scheme, such as Co-wheels. You secure a car for the journey, with a folding bike in the boot.
Your destination is in the middle of town, so when you arrive on the outskirts you park the shared car in a nearby parking bay (which is actually a member’s unused driveway) and take the bike for the rest of the journey to save time and avoid traffic. Your travel app gives you instructions via your Bluetooth headphones – it suggests how to adjust your speed on the bike, according to your fitness level. Because of your asthma, the app suggests a route that avoids a particularly polluted area.
After your meeting, you opt to get a cab back to the office, so that you can answer some emails on the way. With a tap on your smartphone, you order the cab, and in the two minutes it takes to arrive you fold up your bike so that you can return it to the boot of another shared vehicle near your office. You’re in a hurry, so no green reward points for walking today, I’m afraid – but at least you made it to the meeting on time, saving kilograms of CO2 on the way.
It may sound like fiction, but truth be told, most of the data required to make this day happen are already being collected in one form or another. Your smart phone is able to track your location, speed and even the type of activity that you’re performing at any given time – whether you’re driving, walking or riding a bike.
Meanwhile, fitness trackers and smart watches can monitor your heart rate and physical activity. Your search history and behaviour on social media sites can reveal your interests, tastes and even intentions: for instance, the data created when you look at holiday offers online not only hints at where you want to go, but also when and how much you’re willing to pay for it.
Personal devices aside, the rise of the Internet of Things with distributed networks of all sorts of sensors, which can measure anything from air pollution to traffic intensity, is yet another source of data. Not to mention the constant feed of information available on social media about any topic you care to mention.
With so much data available, it seems as though the picture of our environment is almost complete. But all of these datasets sit in separate systems that don’t interact, managed by different entities which don’t necessarily fancy sharing. So although the technology is already there, our data remains siloed with different organisations, and institutional obstacles stand in the way of attaining this level of service. Whether or not that’s a bad thing, is up to you to decide.
Suppliers of managed services are taking on more responsibilities as they become the driving force for IT industry growth, delegates at the Managed Services & Hosting Summit were told in London this week. More than two hundred managed services providers (MSPs) and aspiring providers of managed services were advised their need to become rounded providers of business productivity, by adopting the right mindset, getting more training on key issues and by working together to offer a more comprehensive range of services.
Mark Paine, Gartner Research Director told the conference that service providers had to take account of the changing attitudes of buyers by focusing on the business outcomes and the raised expectations among buyers now that IT has had to become a productivity asset for the business. And they need not try to do it all themselves - partners can co-operate to address the wider market requirements, he said. MSPs had to carefully choose go-to-market partners that can talk both technology and business; and they had to start with a vision; look at use cases; and consider processes, challenges and outcomes for their customers.
Customer acquisition costs (CAC) versus lifetime value (LTV) also had to be brought into the equation, considering margins, partnering agreements and questions as to who owns the invoice, plus the on-going up-selling/cross-selling opportunities. The rewards were there through continuing revenues and repeatable business, as successful MSPs have shown. The rewards for getting it right are substantial, Mark Paine says, including valuable access to customers' ecosystems, becoming a pivotal part of customers' success stories, and benefiting from lead sharing with technology partners.
The added benefit of recurring revenue from cloud services is substantial and this was echoed at the Summit by Michael Frisby, Managing Director of Cobweb Solutions, which sells cloud solutions from Microsoft, Mimecast, Acronis and others. Frisby said: “We became a cloud managed service provider from originally focusing on traditional solutions like Exchange, and 95% of our revenues are now recurring. But you have to make sure you get the marketing right to do it.” Continuing training and education of the MSP were essential, he added, pointing out that Cobweb itself had boosted its investment in this four-fold in the last year.
Other issues covered included the growing importance of compliance particularly with regard to GDPR: legal firm Fieldfisher's partner Renzo Marchini warned that the rules were changing and the impact on MSPs would be profound. Service providers are to be regarded as 'data controllers' under GDPR, with that comes the potential for huge fines in the event of regulation breaches.
The theme of partnering was confirmed later in a round-table discussion when the Global Technology Distribution Council’s European head, Peter van den Berg, outlined how distributors were investing heavily in services and education. Security was also a key issue, with the service provider very much in the firing line in the event of any incident. Datto revealed some of the latest research from its global survey: Business Development Director Chris Tate revealed that “87% of our partners have had to deal with a ransomware attack on behalf of their clients.” Earlier, SolarWinds MSP had shown how all-pervading the issue was becoming in discussions with customers, and how MSPs needed to increase their understanding, particularly in relation to the challenges faced by smaller businesses.
The Managed Services & Hosting Summit, now in its seventh year, was also a platform for other news: Kaspersky's Global Product Manager Oleg Gorobets made the case for its growing programme for better security among MSPs. But there was a general air of optimism with the prospect of vast fields of data and an increasingly information-rich environment produces new sales and growth opportunities for the MSP according to David Groves, Director of Product Management, Maintel speaking on behalf of sponsor Highlight.
M&A specialist Hampleton’s Director, David Riemenschneider, demonstrated that these opportunities and the surge in demand in such areas as AI and security could yield rich rewards for MSPs building value into their own business while addressing the need to create value for their clients. He pointed to heightened interest in services providers, especially those with security, financial services or automotive expertise.
Managed Services & Hosting Summit 2017 (www.mshsummit.com ) sponsors included: Datto, Highlight, Kaspersky, Mimecast, SolarWinds MSP, Autotask, Cisco Umbrella, ConnectWise, DataCore Software, ESET, ForcePoint, ITGlue, Kingston Technology, Nakivo, WatchGuard, 5NineSoftware, Altaro, APC by Schneider Electric, Beta Distribution, Continuum, Deltek, Egenera, F-Secure, Identity Maestro, iland, Barracuda MSP, Kaseya, RapidFire Tools, SpamExperts, Webroot and Wasabi.
Many of the themes and issues addressed in this week’s London event will be developed further in the second annual European Managed Services & Hosting Summit which, it has just been announced, will be staged in Amsterdam on 29 May 2018. (www.mshsummit.com/amsterdam )

Containerisation is the name of the game. It’s a technology that has firmly established a foothold within the developer community. At the DockerCon conference last summer, it was revealed that there were 460,000 applications using Docker worldwide – that’s a dizzying 3,100 per cent growth in the past two years. And, given that rate of increase, those statistics are already well out of date.
By Kelly Murphy, founder and CTO at HyperGrid.

It’s easy to see why containers have made such headway. Containers offer a degree of control and efficiency that system administrators have not had before. That may seem strange given that in the last few years, VMware and other virtualisation vendors have altered the IT landscape, but that’s only part of the story.
The move to virtualisation was a step in the right direction but there were still issues with that particular technology. For one thing, virtual machines contain a complete instance of an operating system and when, as will be the case, there are hundreds of VMs running in a cloud workload, these are going to be extremely resource-hungry.
Containerisation does away with some of these issues: by encapsulating applications in a ‘container’, the user is still deploying virtualisation but because they’re no longer running a complete operating system, there’s more efficient use of resources and orders of magnitude faster spin up times – which unleashes DevOps.
Container technology can work with any type of infrastructure but it really comes into its own when it’s used with cloud technology. This makes sense when you realise that its appeal is going to be for enterprises, which want to operate at scale.
It’s an amazing success story, but just because there’s been a massive increase, it doesn’t mean that the technology is having a clear run; there are still issues to be resolved.
All the talk about cloud computing has been dominated by conversations about public cloud – thanks to the tremendous efforts made by Amazon in securing the bulk of the market. But there are downsides to the use of public cloud. There’s the lack of control when you’re relying on outside resources and, just this year, the major Amazon outage has shown the weakness of relying on public cloud for a consistent service – and it has to be remembered that this was the second major Amazon incident, following the day-long shutdown of one of its east coast data centres in 2011 – a hiccup that led to a couple of firms going out of business.
All the problems of managing and support add up to a considerable headache for CIOs. They ask themselves why they’re spending time managing infrastructure and keeping the lights on, time that could be better spent in making sure technology is being gainfully used. There’s a simple solution to this: if the application is not core to the business, put it in the cloud.
But this turns out not to be as simple as all that. There are several issues at play here. There’s the management of public cloud deployment which can be complex, particularly if different providers are being used for different applications; there’s the way in which cloud instances can be left running, adding to the costs and then there’s the integration of legacy apps into a cloud environment. In effect, the cloud is quickly becoming the next infrastructure / application silo that IT needs to manage – and the cost of just keeping the lights on has actually increased.
This last-named is definitely one of the ways that containerisation will really aid enterprises: it offers the ideal opportunity to ‘lift and shift’ legacy applications, helping those companies who are exploring the possibilities of a DevOps approach and assisting in this shift. Containers in effect mobilise applications and allow them to operate cross-platform – cross-cloud – and eliminate the infrastructure silo.
The real benefits of the technology when combined with any sort of cloud deployment are seen when it comes to speed of deployment. It means that business departments looking to start new projects - or implementing new processes - are no longer left waiting for IT departments to get themselves organised and provision equipment.
But perhaps the main advantage of the use of containers is the way in which they can be deployed in shaping legacy applications for intensive use. This is an area where upgrading has proven to be financially challenging: modernising legacy software can be an expensive undertaking, and while cloud has been a way to rationalise costs, bringing long-established applications to the party has proven to be a stumbling block.
However, it’s not all plain sailing. There are some technical challenges involved in moving enterprises to containers (which is why so many of the initial forays in this area have been test-and-development projects rather than full production). For example, there’s the requirement to find the people with the right skills, there’s the lack of management tools for containerisation, and there’s been issue with the levels of security.
There are particular problems when it comes to running containers to scale. Besides the headache of reconfiguring enterprise applications such as databases, there’s a lack of automation tools out there. While companies will still be able to benefit from the advantages of containers, they’ll only be able to do so after they’ve performed lots of manual provisioning.
HyperGrid solves many of those issues. Using the orchestration portal, users can deploy containers quickly and effectively by a process of automation, keeping manual provision to a minimum.
One area where HyperGrid scores heavily is in security, freeing CIOs from managing the security of their own deployments. And with the incoming GDPR legislation affecting every company that does business in Europe, there’s going to be even more anxiety about security right now.
In the future, there are going to be some significant changes in the way that technology will be used: the growing interest in the Internet of Things is going to reshape businesses, in much the same way that it’s starting to shape consumers’ lives. As more IoT implementations get rolled out, what’s to stop each of the ‘things’ being a container? It would make management of such a deployment easier to handle. And through HyperGrid’s orchestration tool, customers can create self-service portals for easy containerisation: this will enable more efficient control of IT. In a world where containers are the future, it’s going to be the way forward.
Borderlight AB, a leading supplier of advanced IT and Telecom services to the public sector and industry sectors, has decided to build a new data center with large scale heat reuse in cooperation with Europe’s leading district heating operator Fortum Värme in Stockholm, Sweden. With full IT load, the implementation will run at more than 5 MW and heat some 10,000 modern residential apartments.
Borderlight’s sister company GoGreenHost will provide the server blades and racks specifically optimized for heat recovery, with rack densities reaching up to 100 kW per 19" rack. The cooperation between Borderlight, GoGreenHost and Fortum Värme is a strong validation of Stockholm Data Parks’ objective to attract and promote a data center industry where no heat is wasted.
The excess heat from the Datacenter will be captured, recovered and reused for heating of buildings in Stockholm. This is made possible by Fortum Värme’s district heating network which connects more than 10,000 buildings, representing an aggregated heating demand of 12 TWh per year.
“Borderlight’s and GoGreenHost’s target is to become a leading supplier of advanced IT services coupled with efficient heat recovery from data centers that reach close to 100% recovery of consumed electrical power. GoGreenHost technology creates a new potent heat energy source with a very low carbon foot print. Our plan is to contract installation of 30 MW in new data center capacity 2017 and another 60 MW 2018 in sizes from 1-6 MW per site, all connected to a redundant high capacity fiber backbone. GoGreenHost’s ramp up time to delivery of full heat capacity per new data center site is typically 6-12 months", says Sten Oscarsson, CEO of Borderlight and GoGreenHost AB.
-hgyrop.jpg)
GoGreenHost’s solution uses new inventive heat recovery technology integrated directly in the server systems in combination with new heat pump design. Recovered heat energy is fed directly from the data center to the district heating network at the required temperature. Fortum Värme purchases this recovered heat from GoGreenHost.
“Borderlight and GoGreenHost will make a very significant contribution to Stockholm Data Parks' objective to reuse data center excess heat on a large scale. It's particularly exciting to see how the digitalization of our societies and GoGreenHost's high-density technology can enrich one another to the benefit of all parties as well as the environment", says Erik Rylander, Head of Stockholm Data Parks at Fortum Värme.
Close to ninety percent of all buildings in Stockholm are connected to the district heating network. The Swedish capital is one of the few cities in the world where large-scale heat reuse from major data centers is possible. The long-term objective is to meet ten percent of the city’s heating needs through data center waste heat reuse.
Leverages Verne Global’s access to Iceland’s abundant, renewable power for its 5.1 petaFLOPS supercomputer.
Verne Global says that DeepL has deployed its 5.1 petaFLOPS supercomputer in its campus. Designed to support DeepL’s artificial intelligence (AI) driven, neural network translation service, this supercomputer is viewed by many as the world’s most accurate and natural-sounding machine translation service. Verne Global was selected because of the following factors:
The innovative campus design specialised to support HPC and other intensive compute environments driven by the rise in AI, machine learning and big data analyticsThe expertise and technical knowledge of the Verne Global team, andVerne Global’s access to Iceland’s abundant, renewable power and its highly reliable, low-cost energy grid.
“For DeepL, we needed a data center optimised for high-performance computing (HPC) environments and determined that our needs could not be met in Germany. Verne Global’s Icelandic campus provides us with the scalability, flexibility and technical resources we need. In addition, the abundance of low-cost renewable energy and free cooling will allow us to train DeepL's neural networks at lower cost and faster scalability,” says Jaroslaw Kutylowski, CTO of DeepL. “Verne Global's team has a high level of technical expertise, which helps us to implement ad hoc requests quickly and easily. I've never seen such an excellent cooperation before.”
On the supercomputer located within Verne Global’s campus, DeepL trains the neuronal translation networks based on collected data sets. As DeepL learns, the network leverages AI to examine millions of translations and learn independently how to translate with the right grammar and structure.
“We are pleased that our HPC-optimised campus was the ideal location for DeepL’s supercomputer. Our location in Iceland provides a low and stable energy price with the highest possible availability and scalability – criteria that are indispensable for computational and power-intensive applications,” says Tate Cantrell, Chief Technology Officer of Verne Global. “We are seeing growing interest from companies using AI tools, such as deep neural network (DNN) applications, to revolutionise how they move their businesses forward, create change, and elevate how we work, live and communicate.”
ISG has secured an £7.6 million datacentre project with global charitable foundation, the Wellcome Trust at its Genome Campus in Hinxton, Cambridgeshire. The Trust carries out cutting-edge research into human and animal health, and this scheme provides additional computing power and enhanced network resilience at Wellcome’s world-renowned campus.
ISG will build out the final quadrant of the existing on-site datacentre, delivering a new 1.2 MW high density rack facility, with associated mechanical and electrical infrastructure. As the Trust’s demand for increasing computing power rises, this additional capacity is vital to assist research and development (R&D) operations.
The second element of the project provides greater power supply resilience to the Trust’s core infrastructure. ISG will install a series of diesel rotary uninterruptible power supply units (DRUPS) to provide secure and stable power to the datacentre, as well as installing new high voltage (HV) infrastructure across the campus.
Danny Blakeston, managing director of ISG’s Engineering Services business, commented: “The demand for additional compute power and storage capacity, combined with the certainty of mechanical and electrical systems resilience are key drivers for Wellcome Trust, and our first project at the Genome Campus will help address these core requirements.
“This is a challenging and highly complex scheme in a busy, live environment, where maintaining continuity for critical infrastructure throughout the project duration is a pre-requisite. Our international datacentre delivery credentials proved key to our appointment and we’re looking forward to playing a small role in the ongoing success of the campus and its important global research projects.”

T-Systems Turkey has joined the Zenium ecosystem at Istanbul One.
T-Systems is the corporate customer arm of Deutsche Telekom, one of the world’s leading integrated telecoms companies. T-Systems Turkey’s decision to take space in Zenium’s state-of-the-art data center confirms its commitment to offer a range of integrated ICT solutions for business customers from the heart of Istanbul.“Businesses are under increasing pressure to respond to and meet the challenge of more devices, connected via more networks to transport more data,” commented Sinan Kilicoglu, the Managing Director of T-Systems Turkey. “Our decision to partner with Zenium will enable us to support customers that are determined to embrace the benefits of the digital economy whilst continuing to provide classical ICT services, in a scalable and secure environment.”
T-Systems Turkey’s confidence in Istanbul One has already enabled it to secure its first enterprise customer at the data center. It will provide one of the largest Turkish manufacturing groups with the carrier neutral, highly connected and energy efficient environment it requires to support its growing business.
The partnership will enable existing customers at Zenium Istanbul One to benefit from T-Systems Turkey’s comprehensive range of ICT solutions, including the secure operation of legacy systems, the transformation to cloud-based services (including tailored infrastructure, platforms and software) as well as new business models within the scope of telco related services.
“Security, flexibility, scalability and connectivity are top of the agenda as organisations strive to provide services and compete in an increasingly connected world. We are pleased to be able to provide T-Systems Turkey with a world class solution that delivers the carrier neutral approach to the data center that is essential for its ongoing growth and success,” said Franek Sodzawiczny, Founder and CEO at Zenium.

The Japanese Bankers Association (JBA) will employ a Fujitsu cloud service-based blockchain platform to be made available over Fujitsu Cloud Service K5.
The Collaborative Blockchain Platform is a financial services blockchain technology testbed environment that JBA plans to provide to its member banks. In this way, JBA plans to offer this Fujitsu cloud service as one testbed environment to its member banks and other institutions starting from October 2017.JBA will provide its Collaborative Blockchain Platform to its member banks and other institutions as a testbed environment for applications employing blockchain technology, such as for settlement and funds transfer services, and identity and time-of-transaction authentication. JBA will support efforts toward practical implementation of these applications.
Amid rapid advances in Japan and elsewhere in the field of FinTech, a new trend in financial products and services, initiatives to transform the infrastructure for funds settlement and encourage financial innovation employing IT are important from the perspective of improving international competitiveness.
Since 2016, JBA, an association of banks and other organizations operating in Japan, has administered the Review Committee for the Possibility and the Challenges of Utilizing Blockchain Technology, and has undertaken initiatives regarding blockchain. As part of these initiatives, JBA has established its Collaborative Blockchain Platform, a testbed environment for developing financial services employing blockchain technology, and plans to offer it to its member banks and other institutions starting in October 2017.Open source software has been around for a long time, but the last few years have seen a dramatic proliferation of open source programs across a variety of problem domains. Android, Hadoop, MySQL, React and Spark are all examples of open source projects that have enabled rapid development, spurring multiple startups and billions of dollars of VC investment in the ecosystems around them.
By Sameet Agarwal, VP Engineering at Snowflake Computing.

Open source presents a great opportunity – and also a conundrum for CIOs figuring out a software strategy for their organisations. Getting open source right presents a great opportunity to lower costs and reduce friction. A mistake here can lead to headaches and dead-end investments.
There are two aspects to successfully using open source software: understanding what phase the open source software you’re considering using is in currently, and assessing the importance of your business problem.
Different Phases of Open SourceOpen source software offers different value in different phases of the technology adoption lifecycle:
Open source projects are a great fit for problems that are not critical to the business. Incubation ideas and nice-to-have tools can easily use a variety of open source projects and cut down significantly on cost and development time.
But even if a project is business-critical and there are no off-the-shelf solutions that meet the requirements, an early-stage open source project might be a great choice. The company has to be willing to invest in-house talent to staff an engineering team to contribute and support the open source project. This is not a cost-reduction plan, and you have to be prepared to take over the project if all other contributors abandon it and move on. There is serious commitment required to be part of the community developing the solution. It’s best to have some committers in your organisation who can help influence the project to meet your requirements.For all other projects, early-stage open source platforms are not a good choice. The choice for these projects is among solutions provided by a set of vendors, some of which may be late-stage open source projects. The criteria for vendor selection are very similar to closed-source-only solutions, though with a few twists:
Total cost of ownership: Though the license cost of software for an open source platform is zero, that may be a very small part of the total cost given hardware, support, implementation cost, and more. The entire cost must be compared across all the vendors.It is undisputable that containers are one of the hottest tickets in open source technology, with 451 Research projecting more than 250% growth in the market from 2016 to 2020. It’s easy to see why, when container technology has the ability to combine speed and density with the security of traditional virtual machines and requires far smaller operating systems in order to run.
By Marco Ceppi, Ubuntu Product & Strategy Team, Canonical.

Of course, it’s still early days and similar question marks faced OpenStack technology on its path to market maturity and widespread revenue generation. Customers are still asking, “can any of this container stuff actually be used securely in production for an enterprise environment?”
Another common misconception that might present an obstacle to enterprise adoption is the concept of security. However, there are several controls in place that enable us to say, with confidence, that an LXD container is more than secure enough to satisfy the CIO that is, understandably, more security-conscious than ever.
One of these is resource control, which, inside of a Linux kernel, is provided by a technology called cgroups (control groups), originally engineered at Google in 2006. Cgroups is the fundamental technology inside of a Linux kernel that groups processes in a certain way, ensuring that those processes are tightly coupled. This is essentially what a Docker or LXD container is – an illusion that the Linux kernel creates around the group of processes that makes them look like they belong together.Within LXD and Docker, cgroups allows you to assign certain limiting parameters, for example, CPU, disk storage or throughput. Therefore, you can keep one container from taking all of the resources away from other containers. From a security perspective, this is what ensures that a given container cannot perform a denial of service (DDoS) attack against other containers alongside it, thereby providing quality of service guarantees.
Mandatory access control (MAC) also ensures that neither the container code itself, nor the code run within the containers, has a greater degree of access than the process itself requires, so the privileges granted to rogue or compromised process are minimised.In essence, the greatest security strength of containers is isolation. Container technology can offer hardware-guaranteed security to ensure that each containerised machine cannot access one another. There may be situations where a virtual machine is required for particularly sensitive data, but for the most part containers deliver security. In fact, Canonical designed LXD from day one with security in mind.
Containers, in tandem with edge computing, are optimised for enabling the transmission of data between connected devices and the cloud. Harvesting data from any number of remote devices and processing it calls for extreme scaling. Application containers, with the help of tools such as Docker and Ubuntu Core, which runs app packages for IoT known as “snaps”, can help provide this.
Container technology has brought about a step-change in virtualisation technology. Organisations implementing containers see considerable opportunities to improve agility, efficiency, speed, and manageability within their IT environments. Containers promise to improve data centre efficiency and performance without having to make additional investments in hardware or infrastructure.
For Linux-on-Linux workloads containers can offer a faster, more efficient and cost effective way to create an infrastructure. Companies using these technologies can take advantage of brand-new code, written using modern advances in technology and development discipline.We see a lot of small to medium organisations adopting container technology as they develop from scratch, but established enterprises of all sizes, and in all industries, can channel this spirit of disruption to keep up with the more agile and scalable new kids on the block.

DCS talks to FibreFab Marketing Manager, Gary Mitchell – covering the company’s extensive product portfolio, its successful development to date, and plans for the future.

1. Please can you provide a brief introduction to FibreFab – how long the company’s been around, its technology focus and the like?
FibreFab was founded in Milton Keynes, UK way back in 1992. We remained the industries best kept secret, OEM manufacturing for some of the biggest brands in the market place and providing many distributors with plain label or own brand fibre and copper connectivity products. Then in 2013, AFL, a division of Fujikura, acquired FibreFab and quickly realised that our engineering capabilities, solution set, supply chain, customer service and commercial relations were destined for far greater things.
Now, our vision is to be an innovative connectivity solutions company selected by Partners worldwide. We are embarking on a global mission to bring performance, innovation, fast-turnaround and real value (economic, and operational) to the market through dependable distribution and installation partners, to our customers across the globe.
2. And who are the key personnel involved?
Collaboration is one of our core values and we are firm believers that exceptional ideas stem from shared social capital between us, our partners and our customers.
FibreFab is a big family, and our distribution and installation partners are an extension of us. It is clichéd to say, but truly our people and our partners are fundamental to the success of our business.
3. And what have been the major milestones to date?
2017 – Release of FibreFab MPO connector
2013 – AFL acquires FibreFab
2009 – Setup FibreFab sales office in China to service APAC regions
2007 – Setup FibreFab sales office in the Dubai to service Middle East
2006 – Acquires UK fibre termination facility to enable fast-turnaround multi-fibre assemblies into UK and Europe
1992 – FibreFab established
4. Please can you give us a brief product portfolio overview?
We offer end to end fibre and copper network solutions. Our product portfolio consists of assemblies with single or multiple connectors, bulk cable, protection and management, as well as tools, test and termination equipment across fibre and copper.
5. In more detail, can you talk us through the fibre product line?
Working alongside our family of companies we are one of the only companies that can really offer an end to end fibre network solution. Starting with Fujikura (our Grandparent company) we have access to their world-leading fusion splicers – one of their latest innovations is the Fujikura 70R – this fusion splicer can splice 12 fibres at a time. You also have the Fujikura Wrapping Tube Cable with SpiderWeb Ribbon - that is a real game changer. Some data centres are redesigning their fibre backbone and OSP cable specs on the back of this cable. It is available from 144 fibres all the way to 3456 fibres, and generally speaking has a smaller cable diameter by 30-40%, and about 30% lighter than similar fibre counts in other cable constructions. The fibres are intermittently bonded in 12 fibre ribbons so you can multi-fusion splice, or separate one of the fibres and individually splice. One of our customers saw this cable and asked us to design a splice cabinet that would fit on a 600mm x 600m floor tile and hold 10,368 fibres. So we did it, it’s easy to use, easy to install, easy to manage, the customer told reported back that they had about an 80% reduction in time from single fibre splicing.
AFL our parent company –are well known for their test and measurement equipment, fibre cable, and network cleaning products. It is great for us to leverage their solutions and innovations and include it as part of what we offer.
Within FibreFab, we design and manufacture every manner of fibre assemblies including MPO trunks, QSFP assemblies, multi-fibre pre-terms, ultra-high density modules, patch leads and pigtails.
Fibre Management products include 144 fibre Ultra High Density (UHD) Panels, chassis for UHD modules (capable of 288 fibres in 2U), BASE8 transition modules, ODFs, racks, cabinets, sliding panels, pivot Panels, OSP enclosures, and a whole array of cable management products.
Then we have bulk cable, so we have CPR Rated loose tube, tight buffered and steel tape armour cable, as well as access to Fujikura SpiderWeb® Ribbon Cable.
It is fair to say we have a very broad fibre solution offering, ensuring we can put together a custom network solution that meet our customers requirements! Also splice protectors, can’t forget about the splice protectors.
6. And you also manufacture a comparable copper product line?
Our copper range covers high performance CAT5e, CAT6 and CAT6a, and we have everything you would expect including bulk cable, keystone jacks, patch cords, pre-terminated assemblies, and every manner of copper panel – but then we also offer CleanPatch which places 12 copper patchcords into one module which you can connect easily into the front of any patch panel or blade server. It’s a really easy, useful system and makes large copper installations even quicker and easier.
7. Do you have any thoughts on how fibre and copper solutions will develop in the coming years, bearing in mind the demand for every increasing ‘feeds and speeds’?
In terms of technology and bandwidth we believe copper is more or less at its final destination – that said there is an ongoing extension of applications for twisted pair copper in the enterprise space. With POE, POAP, VOIP and connected security devices.
In the data centre space, all main working connections are converting to higher bandwidth with all equipment now shipping with pluggable interfaces. Short range connections inside the rack continue to be made with Direct Attach Copper (DAC) - a high performance variant that does not use keystone jacks, instead opting for transceiver plugs. Active Optical Cables (AOCs) are being utilised widely for mid-range and pluggable transceivers for long range. As bandwidth demand increases over the next 5 years, DAC will become far more restricted in its applications, with AOC picking up in its space.
In mega dcs/cloud data centres most connectivity is already on single mode fibre, whilst enterprise, edge and some mid-scale dc networks use multimode. Multimode we believe will have one more generation before it slowly becomes redundant in future networks. OM5 has a very limited shelf life and is almost already irrelevant. Our advice, use single mode, install single mode and your network infrastructure will have the capability to reach 400gb/s and beyond, in fact single mode cabling will be able to support 1.2tb/s at short range.
8. FibreFab offers a variety of optical networking solutions, starting with the Optronics line?
OPTRONICS® is the name of the network system that we manufacture. Application wise we have network systems available for data centres, telecom networks and enterprise.
Through OPTRONICS®, we design and manufacture pioneering network connectivity solutions that maximize space, expand capacity, deploy quickly, migrate easily and offer fantastic economy. OPTRONICS® is a comprehensive platform of fibre and copper connectivity solutions aimed at enabling network evolution better than anybody else.
9. And the company also offers UHD solutions?
UHD stands for Ultra High Density, and it is really our jewel in the crown. At the heart of the OPTRONICS® UHD solution is our 1U, 2U and ZeroU chassis. Each designed to accept the UHD Modules or UHD Adaptor Plates. The modules are easy to install and allow your network to pay as you grow. UHD Modules can be connected by MPO, direct termination (LC or SC) or by splicing (LC or SC). Across a 2U chassis, fully populated with UHD modules, which would enable access to 288 LC ports.
The OPTRONICS® UHD Solution can also interconnect with our host of customizable, high performance MPO, multi-fibre pre-terms and range of high performance patch cords.
10. And hyperscale solutions?
FibreFab is a member of the AFL IG Group. The Hyperscale (AKA Cloud) computing providers are a major focus of the Group. We provide engineered and customised optical fibre cabling and bespoke fibre management solutions in high volume to this segment.
11. And what can you tell us about the pre-terminated solutions?
Pre-terminated solutions for many are why FibreFab is known and loved. You would be hard pushed to find a better pre-term on the market. From 4 fibre to 144 fibre we have large volume and focussed manufacturing capabilities around the globe. Our customers can determine tail length, tail labelling, connectors, end to end length, and we make the process easy and convenient. We have a patented break out module used on some assemblies meaning that ruggedized tail lengths can withstand 1000N of pulling force – all the while we just created our own MPO connector using Fujikura’s latest MT ferrule, creating the most optimised MPO connector on the market. Our preterms assure quality, flexibility and performance above all else.
12. Not forgetting FibreFab’s ability to provide custom solutions?
Network infrastructure when done right is so much more than just off the shelf solutions. Our engineering expertise is a key differentiator in our market approach and a significant factor in our commercial success. We work with our customers to identify network architecture issues they are unsure how to alleviate and through a process of brainstorming and rapid prototyping, create innovative solutions to sometimes very complex scenarios…and then sometimes we just bend some metal and insert some screw holes…but in a way that our customer needs us to.
13. And then there are the future solutions?
Future solutions is more an outlet for us to explore what next generation architecture might look like by keeping a close eye on key market drivers and technology requirements. This is more a research and development domain for us that allows us to explore how the demands of industry, technology and society are going to impact communications. This is a domain for our engineers and creatives to let their minds run riot and get quite philosophical about optical fibre.
14. You’ve already shared some thoughts on how the market might develop in terms of the general demand for faster and faster networks. More specifically, how do you see Cloud and edge impacting on your market sector?
Cloud computing will continue to grow dramatically and require more and higher bandwidth connectivity between and inside mega data centres. Cloud data centres have already converted to single mode fabric cabling which will support several future technology generations. Cloud connectivity inside colocation data centres and hybrid Cloud implementations will facilitate strong growth in this sector.
The primary use cases driving Edge compute forecasts are IoT and autonomous vehicles with 5G networks supporting much higher data transport requirements. Some form of Edge compute evolution will occur with Cloud and Telco players competing strongly for the emerging business. It is too early to predict the detailed shape and scale of Edge computing but we do know that some form of Edge computing will evolve and that there will be lots of fibre involved.
15. And do you see IoT making a big impact on FibreFab’s customers over time?
I’m sure our Hyperscale, Telco and Colocation customers will all compete for the emerging IoT data transport and compute business.
16. In terms of FibreFab’s market presence, where is the company right now?
We had commercial activity in over 90 countries last year and our market presence is always growing. We know where we want to be and we recognise we have a way to go.
17. And where would you like to be in, say, two years’ time in terms of geographical coverage and, say, specific industry sector success?
We already have global coverage, for now we are happy to spend our efforts maximising the opportunities in the countries we are already operating in.
In relation to industry sector success, we have a vision and we have a plan of action to achieve it. When you think fibre optic networks we want the market to think FibreFab. We have made a profound impact in the hyperscale and dc space already so those that are close to us, are already aware of our capabilities.
18. How do you believe that FibreFab differentiates itself in what is quite a crowded optical networking marketplace?
A responsive, customer centred service, our ability to act fast, and our willingness to engage in custom design to solve problems as opposed to just off the shelf solutions.
19. And, without giving away any secrets(!), how do you see FibreFab developing to stay relevant/keep ahead of the market in the next year or so?
We will continue to be the disruptor in the market and challenge the status-quo created by legacy brands. Then enter new markets, release new product offerings and continue to shake up and challenge the market.
20. What are the one or two pieces of advice you would give to end users who are seeking to understand their optical networking options as they try to keep on top of the demands of the digital world?
Firstly, pay attention to and think about how best to use the lessons learned by the Cloud computing players – software defined everything, disaggregation of hardware and software, resilience not redundancy and provisioning more than sufficient bandwidth.
Secondly, focus on fundamentals and don’t let brand power manage your decisions. Be open to information and recommendations from diverse sources. Then call FibreFab.
21. Any other comments?
Thank you for your questions!
In any mechanical cooling system, the compressor acts as the heart of the operation. Cooling systems used in both household fridge freezer applications and industrial-scale air conditioning in data centres operate off the same basic principles. Inside these closed-loop systems, fluid refrigerant carries heat energy away from the cold coil (i.e. evaporator coil) to the compressor where it is condensed from a low-pressure, low-temperature vapour to a high-temperature, high-pressure liquid, before being pushed around the refrigeration loop for the purpose of heat rejection.
By Victor Avelar, Director and Senior Research Analyst, Schneider Electric Data Center Science Center.

There are many different types of compressors, however, each is appropriate for specific data centre applications (area to be cooled, efficiency, power rating, and cost). A simple classification into two types, namely “constant-speed” and “variable-speed” is common practice but is not sufficient for choosing the most appropriate technology for a facility, dependent on its size. For data centres, we can limit the different compressor options available down to five, shown in green in the figure below.
The most common type of compressors used in data centres are variants of the basic positive-displacement configuration. In positive-displacement systems, the cooling refrigerant is compressed using a chamber whose volume can change. This is typically achieved using the motion of a piston in a cylindrical chamber (single-acting). Other compressors in the positive-displacement category are rotary compressors where compression is achieved by the rotation of a vane in a cylinder (rotary vane) or by the rotation of a scroll (rotary scroll) or two matching helical screws inside a casing (rotary screw).
Piston compressors, much like the operation of a piston in a car engine, use the reciprocating motion of a motor-driven piston in a cylinder synchronised with suction and discharge valves. These compress the vaporised refrigerant from a low pressure and temperature to a high pressure and temperature.
Piston compressors can be subdivided further into sealed airtight or open types, the difference being that the former are not serviceable and are typically used for applications requiring small cooling capacities up to 1.8kW. The latter can be disassembled for service in the field and can be designed for capacities up to 350kW. Capacities can be adjusted by increasing the number of cylinders which can be arranged in various “letter-like” configurations such as Vs or Ws, in much the same way as car-engine cylinders.
Among the benefits of piston compressors are their wide use in many applications, in addition to their broad capacity range. However, they have low energy efficiency as the compressor suffers from high losses due to a number of factors, including resistance due to suction and discharge valves and gas leakage between the piston and cylinder.
Liquid slugging, the phenomenon of some refrigerant remaining in the liquid state while the majority has been vaporised, causes wear and tear on the piston components. Compared with other compressor types, piston compressors have large dimensions and therefore greater weight per unit capacity. Vibration due to discontinuous gas displacement also causes inevitable wear and tear.
The rotary vane compressor is similar in operation to a piston compressor in that the blade, or vane, splits the space between a fixed cylinder casing and a rolling piston into two sections, namely suction and discharge. As the piston rotates, these two volumes are increased and decreased to achieve gas suction, compression, and discharge. The compressor type can be subclassified by the drive speed into constant and variable-speed versions, or by the number of vanes.
Compared with a reciprocating piston compressor, a rotary vane compressor has higher efficiency. It has smaller dimensions and lighter weight per unit capacity and is also more reliable because of fewer components, reduced vibration less wear and tear.
However, compared to other compressors rotary-vane models are limited to small capacities below 18kW due to the limitations of their structure. They also have more components and lower energy efficiencies than other models.
Another type of rotary compressor uses one fixed and one orbital scroll to compress larger volumes of gaseous refrigerant to high pressure and temperature. The cool vapour refrigerant is drawn from outside the fixed scroll, compressed between the two and finally the compressed refrigerant is discharged from the centre with a continuous displacement. Like rotary-vane compressors, rotary-scroll models are available in constant or variable drive speed variants.
Compared with the compressors mentioned already, rotary-scroll compressors have higher reliability due to a simpler structure and fewer components; higher efficiency due to less losses because they do not have suction or discharge valves and less vibration due to continuous gas displacement through the sweeping motion of the rotors. However, they still can not match the efficiency or large capacities of the last two compressor types described below. Rotary-scroll compressors are typically used in applications requiring compressor ratings of between 18 and 35kW.
A rotary-screw compressor uses rotors to compress large volumes of gaseous refrigerant to a high pressure and temperature. This is achieved using male and female rotors that reduce the refrigerant gas volume as they rotate.
Cool vapour refrigerant enters from the suction port, is forced by the meshing rotors through the threads as the screws rotate and exits at the discharge port with high pressure and temperature. Compared to the compressors described already, rotary-screw models have larger capacity and higher efficiency due to a simpler structure and fewer components. There is less vibration and surging due to continuous gas displacement and they also less sensitive to liquid slugging, although this does become an issue for reliability in the long term.
Rotary screw models are only for larger applications as it is impractical to design a capacity below 70kW due to the rotor processing technology. They are typically used in applications in the capacity range between 70 and 637kW.
All of the foregoing are examples of positive-displacement compressors. An alternative to this basic mode of operation is the dynamic compressor in which cool vapour refrigerant is compressed to a high temperature and pressure by adding kinetic energy via a rotating component. One such example is the centrifugal compressor, sometimes called a turbo or radial compressor.
In centrifugal models, cool vapour refrigerant is forced to pass into and through an impeller which forces the fluid to spin faster and faster. The high-speed gas is then forced to pass through a diffuser where the refrigerant gas expands as its speed decreases. This process converts the kinetic energy of the high-speed low-pressure gas to a low-speed higher pressure gas. The higher the impeller speed, the higher the pressure.
A centrifugal compressor can be subclassified by the number of stages (single-stage, two-stage or multistage) and lubricating method (splash lubrication, forced lubrication or oil-free). In the case of oil-free lubrication the compressor uses friction-free magnetic bearings. As a result, there are no mechanical wear surfaces which enhances efficiency and reliability, reduces noise and lowers maintenance costs.
Centrifugal compressors have the highest capacity of all models described here, up to 35MW per unit. They also have higher efficiency under partial loads, higher reliability and lower maintenance costs, compact structure and less weight per capacity. Compared with reciprocating compressors weight can be reduced by between 80 and 90% and footprint by 50%.
This comes at a cost, however, as the capital costs are much higher although these can be offset by lower operation costs. The costs are incurred because of the need for higher quality material and precision machining during the manufacturing process.
Centrifugal compressors are impractical below 70kW due to the impeller's high rotation speed. Typically, they are used in applications requiring capacities above 700kW.
In summary, for small air-conditioning or cooling units up to about 70kW capacity, one should choose between sealed piston compressors, rotary-vane or rotary-scroll compressors. In the range between 70kW and 350kW, the choices come down to open piston compressors with multiple cylinders or rotary-screw compressors. For higher capacities above 350kW the choice is between rotary-screw and centrifugal compressors with the latter being the most practical at capacities over 700kW.
Among the trade-offs to be considered in each case are: cost, with piston compressors being cheaper per kW than rotary-vane compressors at low capacities; efficiency, with centrifugal and rotary-screw models being the most efficient; and input power per unit with piston compressors, rotary-vane and rotary-scroll being the lowest and rotary screw and centrifugal the highest.

The data centre market is constantly adapting. Such has been the speed with which the industry has grown, propelled by an ever-expanding client base with increasing demands for space and power, that it is of little surprise that the market has experienced a faster than usual rate of maturation. As the industry adapts, the players involved become more sophisticated. Providers no longer hold a monopoly of knowledge and expertise with occupiers showing an ever-deepening comprehension of the asset and the market.
By Liam Philips, Senior Associate, Real Estate, Reed Smith LLP.

When you combine this evolution against potential political and economic upheaval as we near the brink of Brexit, you have the circumstances for a potential power shift in the provider-occupier dynamic. So, are we witnessing a change, or is it business as usual?
As a lawyer who specialises in the data centre sector with experience of contract negotiations on both sides of the equation, one thing I can attest to is that the nature of these negotiations is undergoing change and unsurprisingly this change is mirroring the evolving state of the market. Whilst the outcomes of the negotiations may not necessarily have shifted the control from the provider to the occupier, the path taken to agree terms has. With the rise of the educated occupier has come an increased number of demands and a bolder initial negotiating stance. In this article, I explore a selection of demands that are arising more frequently.
The desire for contract and pricing uniformity, as delivered by an MSA, is an increasing trend in the market. These demands are driven by market, legal or commercial concerns for example Brexit or an increased interest in data centres as an investment asset class etc. It has historically been the case that only the largest players in the market have required such universal terms, however it is becomingly increasingly more common for smaller occupiers to seek global tie-ins. In practice however, often the provision of MSAs remain the reserve of those occupiers with large capacity needs and a pipeline of requirements. In only a few instances have I seen providers accede to such requests from smaller occupiers and in those examples it has been where the occupier can commit to repeat business.
The potential ramifications of Brexit have unsurprisingly bred concern amongst the occupier market. Uncertainty remains over the potential disruption to the current legal framework relating to GDPR and the EU-US Privacy Shield and the handling/processing of data within the EU and exporting such data to countries outside of it. These data centric concerns are in addition to the fears over potential import tariffs. Such uncertainty has led some occupiers to try and hedge their position through seeking the right to request mid-contract migration. Such rights would allow occupiers to obtain flexibility whilst continuing to benefit from the more attractive rates fixed longer term agreements offer.
The frequency of these requests might be on the increase, but accession to them remains low. The flexibility that is desirable to the occupier is not so favourable to the provider. Primarily, in order to be able to accommodate such a request, the provider must firstly have a European wide portfolio of data centres; secondly, the provider would have to reserve space and power in order to be able to fulfil the migration at any point requested. Few providers satisfy the first criterion and fewer still are willing to take up the commercially counterintuitive measure of reserving space and power in a market where there is such a high demand from occupiers willing to take up space and power from day 1.
Current belief suggests the UK and London in particular will be able to retain their positions as the central connectivity hub within Europe despite the UK’s impending exit and therefore if that theory proves true, the need for providers to accede to such migration requests will continue to remain low.
Efficiency has always been a hot topic for the sector. Historically the desire for energy efficient centres has been driven by economics coupled with the requirement to comply with governmental policies and initiatives. Recently a third factor has been introduced: the corporate social responsibility (CSR) policies of occupiers (and even a step removed, the CSR policies of the occupier’s clients, whichever industry they may be in).
A PUE that decreases year on year is in itself desirable, however, the requirement to “go green” is becoming more than simply a pressure to lower emissions for economic benefit or even governmental compliance. Large multi-national occupiers will invariably have committed to their own green mandates that obligate them and anyone they work with, to initiate and comply with such policies. These policies will stipulate requirements ranging anywhere from an increase in waste recycling to a reduction in worldwide carbon footprint.
Both HDOT and Alternating Phase are available through Server Technology's âBuild Your Own PDUâ configurator. Build Your Own PDU takes a Switched, Smart or Metered 42-outlet High Density Outlet Technology (HDOT) PDU and allows you to build an HDOT PDU your way in Four Simple Steps. Choose a configuration. Download a spec sheet and request a quote in four simple steps.
An example of a requirement that features in the CSR policies of some large occupiers, is a commitment to power their facilities with 100% renewable energy by the end of a given timeframe. At the negotiation stage of an agreement, occupiers are now attempting to pass on these targets to providers. The result of such obligations is that providers are now being squeezed from all directions. Whereas previously the pressure came on providers from above via national authorities to reduce emissions, etc., providers are now being pressurized from their customers below. In some circumstances, occupiers are even requesting termination rights should such policies or standards, etc. not be adhered to, thereby underlying the significance of such commitments made by the occupiers. That is not to say that such demands are being met (not necessarily due to an unwillingness, more often because the standards dictated are uneconomic or unfeasible), but as occupiers are often multi-national companies with large requirements, they are very attractive customers to any provider and providers are therefore having to be more amenable to working with some of the occupier’s requests.
So, where does that leave the power in the market? Has a shift in the dynamic occurred or is it on the horizon? In my opinion, not yet. It is true that the negotiation table has become a different place. The occupier market is, through leveraging their risk profile across a number of providers across the world whilst also in some instances running their own data centres, become increasingly more knowledgeable, commercial and globally-minded resulting in bolder negotiation requests. The demand for space and power continues to grow and occupation within the best facilities remains at a premium. The laws of economics therefore allow providers to continue to call the shots more often than not but the market is reacting to certain occupier contractual requests.
As for whether the desires of occupiers for the numerous reasons above ignite a move towards more widespread provider accession, a number of future events such as the impact of operating outside the EU, will likely dictate the future bargaining powers of the parties. In the meantime, providers will no doubt continue to hold firm. How long that remains for is to be seen, as does whether it will be Brexit or another factor such as CSR commitments that will be the catalyst for any change in the dynamic in the relationship between provider and occupier.
Future-proofing is a necessity for data centres that are feeling pressured by the continuing advancement of technology. For instance, the push by government and engineers to develop ‘Smart Cities’ is seeing an immense strain on data centres which will channel information at a significant rate. The strains for data centres are becoming more and more apparent, and therefore appropriate solutions must be implemented to ensure their longevity and viability.
By Dirk Paessler, CEO of Paessler

To ensure there are no issues created from the strain on data centres, an effective network monitoring solution should be used.
By using the correct IT monitoring tool, data centres can achieve better performance and future-proof their systems without having to commit to a significant expenditure on hardware. All data centres, even those without extravagant budgets to invest in the latest technologies, will be able to future-proof themselves in this way to minimise the risks of upcoming challenges to their systems. Ultimately, future-proofing need not be expensive, radical or harmful to a business at any point in their operation.
IT monitoring is a sensible solution for companies looking to gain as much capacity from their data centres, or to offset potential future issues. These monitoring solutions will scan and diagnose common network issues, such as bottlenecks, preventing problems that can cause future issues, and potentially even network failures. Network monitoring can also check for underperforming devices, overloaded servers and other potential issues that can be catastrophic for businesses if left undiscovered.
IT monitoring also reduces downtime for businesses, optimising efficiency by detecting and diagnosing problems before they can cause such issues. It can also analyse bandwidth use and inform organisations on how they can maximise data usage. This makes IT monitoring a crucial tool when it comes to ensuring valuable information in the data centre is not lost or becomes unavailable when the customer wants to access it.
As well as diagnosing problems within the network, IT network monitoring can help guide how money is best attributed, and assess how effective the investment has been. Businesses demand and expect new technologies to work seamlessly within existing infrastructure, and to demonstrate how the investment is having a tangible benefit. However, it is often not as simple to discover how effective the new technology is without IT monitoring.
-iyl5wk.jpg)
IT teams usually hold sole responsibility to ensure new technologies work within the existing infrastructure. This complex task becomes easier with an IT monitoring tool by identifying the most effective way to integrate new devices into the network. Because of this, IT staff can be more confident of avoiding technical and teething issues.
Future technological developments will rely even more on the data centre, causing an increase in demand. Of all technological improvements, one of the most important to note is the Internet of Things (IoT). The possibilities of IoT are virtually limitless and have the potential to radically improve the way a business operates and how people live their lives. Although we can only speculate on the possibilities of IoT at this point, we must appreciate the realms of possibilities to ensure data centres are fully prepared for the potential strains on their operation systems.
The data passing through a data centre will expand exponentially as more and more technology joins the existing network structure. For example, any time a remotely controlled kettle or a connected device in a hospital is added to an existing network, it increases the burden data centre. Additionally, as increasing numbers of towns and cities aspire to become ‘Smart Cities’, a localised and regional approach to harnessing data centre power will be required.
Data flowing through the data centre must have the ability to be analysed and displayed in a meaningful way. The IT network will be the key to the interchange of all this data, so will need careful attention to ensure smooth running on a daily basis. Tools such as IT monitoring will prove invaluable in this situation.
Organisations and IT professionals must remain vigilant to ensure that their data centre withstands the pressures of an increasingly technological world. A network monitoring tool provides organisations with the knowledge that their businesses are secure and they can maintain the data centre well.
Although the abilities of future technological developments are still up in the air, it is almost guaranteed that they will substantially increase the demands from the data centre. An IT monitoring solution can be used as a tool to arm and prepare IT professionals for such a change in their network.
The next wave of data throughput growth is having a transformational effect on the data centre market. The IoT and IIoT (Industrial Internet of Things) is beginning to unleash billions of data points across the internet and this rapid expansion of content needs to be channelled, efficiently transported, analysed and stored alongside the current growing internet data merry-go-round.
By Michael Akinla, TSE Manager EMEA, Panduit.

IoT sensors and devices are expected to exceed mobile phones as the largest category of connected devices in 2018, growing at a 23% compound annual growth rate from 2015 to 2021. It is predicted that there will be a total of around 35 billion connected devices worldwide by 2021, with over 16billion of these being related to IoT. The total volume of data generated by IoT will reach 600ZB per year by 2020, dwarfing the projected traffic between data centers to end user devices (2.2ZB).
The data generated by these IoT deployments will need to be processed and analysed in real time, increasing the proportion of workloads of data centres and creating new security, capacity, throughput and analytics challenges. This massive step-change offers an opportunity to integrate across the organisation, providing increased market data, business efficiency and operational savings. However, it requires the data centre, enterprise and manufacturing plant to work towards greater convergence of systems.
Chart 1. IoT Installed Base, Global Market.
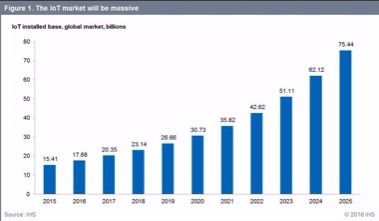
For decades, manufacturing operations technology (OT) and enterprise information technology (IT) have evolved into separate physical architectures. Today’s often closed manufacturing systems present a major challenge to transmitting OT generated data, to the right place and at the right time.
What is required is commitment to a common technology platform, allowing interconnected ecosystems with scalable platforms, providing affordable access to modelling and analytical technologies, for the manufacturing systems essential to the factory’s operation. A common network infrastructure built on standard Ethernet and Internet Protocol (IP), will enable a uniform data flow across the organisation.
This is a shift away from the constricted development of information and communication technology systems for specific sectors, towards a comprehensive and broad view of connectivity on a global scale. This new drive is increasing focus on integrating the new flows of data from machines and sensors with existing and evolving data sources, to produce new and actionable insights. IoT device access to the internet and the organisation’s compute environment is essential as people move away from the plant floor, increasing the need for non-physical monitoring and remote access to manage the factory.
Fundamentally important to the IoT model is the strategic activity of major ICT companies in developing IoT offerings. Leading vendors in the telecom, networking, industrial infrastructure, enterprise and cloud computing sectors are converging on the strategy of offering IoT platforms, providing validated network architecture design principles, and reference design guides which provide key considerations for a unified physical layer.
IoT is allowing organisations to create an entirely new business mining data from their stored and real time systems and using the analysis to provide valuable services and enhanced customer experience. Lufthansa is using its IoT strategy to gather data from its maintenance, repair and overhaul (MRO) operations and combining this with real time aircraft, airport and weather sensor data to improve on-time performance and optimise operations.
However, the integration of IT and Industrial Automation and Control Systems (IACS) and Operational Technology introduces the requirement for increased security, ease of use, rapid deployment and network managed support. Converged Plantwide Ethernet Architecture (CPwE) offers a collection of tested and validated architectures and provides the standard network services for control and information disciplines, devices and equipment found in IACS applications. Successful deployment of CPwE logical architecture depends on a robust physical infrastructure network design that addresses environmental, performance, and physical security requirements with best practices from operational technology and information technology. As over 60% of Ethernet link failures are related to physical infrastructure, it is important from the outset to design and build a resilient network that is architected to recover (converge) quickly from a failure condition.
As IT and OT continue down the path of convergence it is important to increase the resilience of an Industrial Ethernet network. To do this we need to identify the risks for underperforming networks and network disruptions, and define appropriate countermeasures to achieve high resilience. Consideration of challenging environmental factors, such as, long cable run distances, temperature extremes, humidity, shock and vibration, water and dirt ingress and electromagnetic interference need to be understood so as to design and implement a coherent infrastructure strategy.
ICT suppliers often allude to the ‘Demilitarised Zone’, the space between Manufacturing and the IT System, where converging protocols and automation processes co-exist with the IoT environment. This provides the flexible platform for future developments, while at the same time provides a safety partition maintaining a secure bridge between the two environments.
Resilient Design Considerations:
Integrating Manufacturing with Enterprise, Data Centre and Hybrid environments is increasing pressure on data bandwidth resource within the networks, and while the latest topologies (Leaf and Spine) reduced the latency overhead, higher data volumes and real-time analysis provide new challenges to the network designers and operators. The growth of East – West data activity has increased localised processing and storage. This is assisted by the introduction of higher speed and capacity structured cabling systems (based on the latest IEEE data rate standards), together with increased storage capacity benefiting from new storage technologies and Fibre Channel speed up to 128Gb and heading towards 256Gb. As fibre cabling is becoming increasing pervasive across the data centre and enterprise, the manufacturing environment can also benefit from the faster 10Gb up to 100Gb speeds across the longer cable runs that are now on the market.
The latest developments in Cat 6A copper cabling have introduced industry standard compliant lighter, thinner cabling which can deliver 10Gb across 100m cable runs. This is an important development as it also extends the capability to deliver PoE (Power over Ethernet) whilst maintaining the cable’s robust data transmission characteristics. Developments such as this are providing intelligent access point ceilings across the data centre, enterprise and manufacturing facility.
The increase in data generation and real-time transport requires new thinking regarding fibre cabling in the manufacturing environment. The over used argument for the reluctance to deploying fibre in the factory is cost and that the systems require installation expertise. However, today fibre cabling systems have evolved to be simpler to deploy in factories and on plant floors and they offer new easy to use termination methods that any competent electrician can install. This now provides the infrastructure to securely transport the increased volumes of IoT data from the factory to the IT environment for processing and storage.
The latest industrial automation fibre optic cables are designed with harsh, device-level industrial installations in mind. Cost effective, large diameter, high strength GiPC (Graded Index Plastic Clad Fibre), is easy to prepare and terminate with hand-held tools and minimal training. These provide a flexible, hard wearing cabling system that is highly resistant to electrical and physical interference in the factory environment.
The convergence of IT and OT is benefiting manufacturing with resilient plant-wide network architecture which serves a crucial role in achieving higher overall plant uptime and productivity. The CPwE architecture provides standard network services to the applications, devices and equipment in IACS applications and integrates them in to the wider enterprise and cloud network environment. The latest developments in cable technology together with the latest WAN topologies is speeding data throughput within the data centre. New robust cabling systems are increasing up time and efficiency across the network. As the OT inevitably narrows the gap between its own technology and that of IT. The convergence will increasingly offer higher levels of return for the organisation that fully engage and invest in this ever-widening open environment.
In this article, Ciaran Flanagan from ABB Data Center will explore the rise of the digital datacenter and look at how the Internet of Things (IoT) can be leveraged to help datacenter managers and installers move towards maintenance 4.0 with early prediction, greater insight, increased uptime and proactive maintenance.

Today if you pick-up a newspaper to read about the Internet of Things (IoT) you may find that many headlines focus on how IoT is being used on smart devices, in mobile technology, across the automotive sector and in manufacturing.
As we become more digitally advanced in consumer and business to business worlds, demand on datacenter services is increasing dramatically with demand expected to grow 19% YoY from 2016 until 2021.* This means more computing capability, greater storage capacity and bigger, more robust network connections.
In this world of co-located services, un-scalable, converged networks, connected machines and devices, coupled with pressures on datacenter teams to do more with less, the balancing act between maintaining environmental and financial sustainability becomes ever more challenging.
The reality is that, over the next three years, there will be 400% growth in data center traffic**. Industrial digitalization is here to stay and the implementation of the Internet of Things (IoT) has been heralded as the next big challenge for industry and for datacenters as they look to adopt a new phase in industrial automation and maintenance 4.0.
So, how can IoT be utilised and implemented to add real value to the datacenter?
One of the key changes in sensor technology is the rapidly declining cost of sensors, integration and connectivity which increases the ability to analyse, process and store data. It enables machines to become more and more intelligent, with the ability to predict failures and undertake maintenance before they even happen.
IoT should be better described as ‘digital operations’ and the ability to control, interrogate and modify operational tasks in response to external signals. It’s about making IT operations more reliable, more cost effective and easier to maintain and execute.
In the quest to increase efficiency and drive down cost, many executives might be tempted to reduce the digital footprint and density, to reduce hardware spend which creates unnecessary pressure on the existing infrastructure.
Through IoT, datacenter managers can be empowered to implement an intelligent, data-driven solution to optimally balance workload and power resources, without looking towards CFOs and financial balance sheets to drive down costs.
As next generation datacenter professionals we must stop star gazing and trying to predict what will happen.
** http://annualreport2015.e.abb.com/business-overview/chairman-and-ceo-letter.html
We need to embrace that our industry is unpredictable and look to new solutions and business concepts that are elastic- shrinking and growing with demand.
To take advantage of these next generation ‘digital operations’, datacenter managers in the first instance need to balance the physical hardware structure in three simple steps:
1) Make sure any components and systems can be networked, including everything from your grid transformer to the humble low-voltage circuit breaker.
2) Assess new communications platforms and protocols to ensure you are deploying the most effective network. A great example here is using IEC61850 to reduce physical cables and points of failure across your infrastructure.
3) Challenge your supplier to demonstrate that their solution and approach is elastic, that it can add and subtract capacity on demand and in response to other signals, and that it is future proofed.
Now you have the digital platform to make your operations smarter …what next?
You need to transform your operational tasks into software driven activity and combine operation technology with information technology.
ABB Ability™, our portfolio of connected and software-enabled solutions, included power management solutions that work in synergy with server technology to enable datacenters to extract operational data to identify power trends and failure modes, control energy costs and allow managers to transform how they implement their maintenance regime to reduce downtime.
Such solutions offer a whole new set of opportunities for large scale datacenters to gain greater insights and become more efficient with maintenance, energy consumption and even capacity planning- all in near real time.
By defining rules and configurations, this intuitive, automated platform can also help managers in peak and trough phases at a local and grid-wide level.
This could include switching workloads off a non-critical datacenter and moving to another datacenter with lower demand. It could even manage power costs and energy models enabling customers to choose the most cost-effective power sources and dynamically switch from grid to renewables, when rates are lower.
Ten years ago, the need for retrospective analysis to potentially cure issues in case they happened in the future was the only solution for datacenter managers. But today, intelligently connected IT reduces costs and optimizes datacenter maintenance.
IoT solutions bring together physical and digital worlds to work harmoniously as one, allowing datacenter managers to see everything and build an efficient and effective datacenter- for today and tomorrow.
Datacentres are increasingly able to elevate their operating temperatures which can lower the energy needed for cooling and humidification control, and has led many to shift their focus on maintaining an optimum indoor climate from cooling to heat removal. Matthew Philo, product manager CRAC at DencoHappel, explains what the difference is between the two, and how this change has enabled more energy-efficient technologies to be introduced.

The way we control the temperature in datacentres has changed significantly in recent years, and this is largely down to the way in which we understand the type of environments that need to be maintained in order for the servers to be able to operate effectively and efficiently.
When we look back at when data centres were first established, the machinery used required computer scientists working at their desks side by side with the machines. It was important to keep the machinery at a reasonable temperature, while ensuring that the room was suitable for these specialists to think clearly, too.
Meanwhile, these facilities had to ensure that any server rooms were suitable for the storage and use of paper, a key component in early computing. This meant the humidity of the room had to be controlled to ensure high quality paper operated through the machine and could be stored appropriately.
In order to provide a suitable environment for people and paper, the whole room was typically kept with a temperature around 21C and a relative humidity around 50%. That often required the cooling system to supply air at as low as 11C, to keep the whole room around the 21C target. This old notion of ideal temperature and humidity range has remained much longer than the technology inside a data centre itself.
Modern servers can in fact withstand temperatures beyond what people perceive. What’s more, datacentres nowadays do not have data scientists at their desks, so there less need to maintain a temperature which is comfortable for workers. With the development of aisle containment, it means that the cooling systems can now provide air at mid-20C temperatures, without affecting server performance.
There is also now a greater understanding of optimum datacentre layout to minimise hotspots, further negating the need to use industrial levels of cooling. These occur when air does not move through the space correctly, allowing warm air from the back of the server to recirculate and enter the front of the equipment, causing it to heat up. With the air leaving a server anywhere up to 10C higher than that entering it, the system can heat up very quickly. Adding more cooling units to the room does not address this recirculating airflow, and so does not solve the problem.
By carefully considering the layout of their facility, and ensuring that airflow is consistent and reliable, datacentre managers can provide a suitable environment for maximising the reliability and performance of IT hardware.
These changes in understanding have led to a shift from cooling the whole room with a flood of cold air, to heat removal, where hot air is taken away from the outlet of the server. By thinking in this manner, datacentres can reduce costs and increase energy efficiency, and reduce the facility’s Power Usage Effectiveness (PUE) rating.
If you appreciate that nearly all the electrical energy into a data centre will eventually become heat, which is a large amount, rather than making the white space a fridge to combat this, it is much more effective and energy efficient to view the hot air that is being generated as being required to be vented to the outdoor environment. In fact, because of this, your systems will often pay for themselves very quickly when compared with using more traditional cooling operating environments.
Take DencoHappel’s indirect evaporative cooling system, Adia-DENCO® for example. This principle exploits the temperature difference between the indoor and outdoor environment, by passing the indoor and outdoor air through a plate heat exchanger. When outdoor temperatures are higher, it can utilise adiabatic humidification to recreate this temperature difference for heat rejection.
Also the Multi-DENCO® F-Version exploits free cooling by using a water circuit as a go-between when the outdoor air is colder than the indoor conditions. With higher indoor temperatures, it extends its mix-mode, where both the free cooling and the direct expansion operate simultaneously. The system benefits from the ‘cube root’ principle, where if the free cool circuit can provide 20% of what is required, then this is 20% less for the direct expansion circuit, saving near 50% in energy consumption.
Removing heat from the datacentre, then, can prove to be more effective and cheaper mind-set than a cool at all costs methodology. This is why it is becoming a more popular way of managing the datacentre environment. Fuelled by the rise of technologies such adiabatic evaporation and free cooling, this mind-set is set to continue progress over the coming years.

As the world embarks on a potential fourth Industrial Revolution, 30 to 50 billion connected devices are set to spur an unprecedented growth in bandwidth. The next few years are critical to building the networks that will meet the demand and, in anticipation of this need, data centres as we have come to know them are changing. Under pressure from increasing demands of trends such as wearable technology and big data for greater bandwidth, faster data speeds, and lower latency, there has been a shift in how organisations are viewing, planning and building their data centres.
By Koen ter Linde, head of enterprise, CommScope Europe.

As the ways in which technology is used and valued by enterprises continue to evolve, so we’re likely to see a number of changes in the data centre space.
Facing a data deluge, for example, many organisations are migrating new data centres to leased co-location facilities and public cloud, while those choosing to build their own data centres are having to ensure their facilities are more efficient, and able to achieve higher density.
Previous generations of data centres tended to focus primarily on the storage of information and disaster recovery. Geographic diversity was required for backup, and data would be retrieved on a periodic basis.
Now, however, the focus has shifted to analysing and processing data for on-demand access, with the rise in mobility and wearable technology creating requirements for reduced latency never before seen.
Consumers and businesses alike now share an expectation for being able to access on-demand data from the cloud and enjoying the same user experience as if accessing data residing on a device. The most efficient way for businesses to achieve such low levels of latency through the use of cloud computing, is for data centres to be far more distributed than ever before.
The latest breed of datacentres will, as mentioned, need to be more efficient and achieve higher density than their predecessors, and a growth in the provision of distributed computing will be required to cater for the needs of service providers and the increase in co-location.
The most significant growth, however, will be in the number of point-of-presence (PoP) data centres needed to support content delivery networks for service providers, as well as promoting increasingly popular network virtualisation and software-defined networks.
An outcome of the combination of this growth in PoP data centres and in the trend for co-location will be an increase in the need for more interconnecting, or peering, between service providers.
Most importantly, businesses will need to know exactly where their data is at any given moment, and how their data centres are being used and powered. Data centre infrastructure management (DCIM) will be key to keeping these data centres running smoothly, and avoiding any potentially costly inefficiencies.
One of the biggest changes to data centre design is being brought about by the desire from service providers to push as much computing resource as possible to the edge of the network. The aim of this is to reduce latency by cutting down the number of ‘hops’ taken by data in order to reach the end user.
Ten years ago, a user would pull up a programme on their laptop and, after it had taken some time to load, they would look at it for long periods, a couple of times a day. Now though, we’ve shifted towards an app-driven world in which we look at data hundreds of times a day for shorter durations. As a result, users increasingly expect data to be predictive, instantly serving up information from the cloud.
By way of illustration, consider the launch of social networks at the beginning of the 21st century. Their growth during these first few years was limited somewhat by the need to increase the number of servers available. Nowadays, however, cloud services mean that a new social network can have instant access to virtually unlimited compute resources across every continent.
With such capabilities providing start-ups and tech companies with instant scalability, it’s little surprise that small and medium-sized businesses are now following suit.
The growth in adoption of streaming music and video services which, by necessity, need to be uninterruptable and low latency, combined with the scale of demand from consumers shopping online, has led to many organisations moving some of their operations to the cloud in hyperscale data centres. By doing so, they are able to flex into a cloud capability when their networks become stressed, and hold their data across multiple locations in order to provide static information without latency.
Finally, and perhaps the most important issue, is speed. The more data consumers and network users need, the more services they expect, and the more critical speed becomes. We are quickly moving from 10Gb/s and 40Gb/s to 100Gb/s, 400Gb/s and beyond. High-speed migration services are, therefore, now critical in providing a bridge between current and future demand, helping data centre managers to accelerate the growth of their capacity, and supporting higher speeds and emerging applications while avoiding the need to rip and replace.
As a result of the growing popularity of data-hungry trends such as streaming services and wearable technology, we’ve recently seen major technology companies moving away from managing their own data centres and completely into the cloud.
It’s exciting to consider how the data centre space will continue to grow and change over the coming years, as more businesses expand via cloud and co-location at the same time as computing power expands throughout the network and around the world.
The need for increased governance, security, regulation, IP protection and minimal latency has all led to an increasing percentage of computing capabilities moving towards the edge. This is true for the latest wave of driverless cars, drones and Internet of Things (IoT) devices in particular. At the same time, there is the theory that cloud computing is merely a temporary way point on the evolutionary path of IT, and that it will be overtaken by better processing and storage at the edge.
By Stuart Nielsen-Marsh, Director — Microsoft Cloud Strategy, Pulsant.

While this may well be the case, traditional networks and edge computing will likely coexist for some time to come.
One of the most obvious problems that is solved by moving datacentres towards the edge is that of latency. It is easy to imagine the problems that latency could cause with a form of artificial intelligence (AI) that requires real-time action and response in order to operate effectively.
Think about the issues that latency could cause if we reach a point where AI is being used to support medical surgery, or if robotics becomes a critical part of vehicle navigation. These scenarios require real-time action and response — something that is prevented through latency.
When talking among peers, it is clear that edge computing and networks will not be disappearing any time soon, and that the balance sought will depend on individual use cases and business scenarios.
Moving to the edge does not signal the end for core datacentres though. It’s about an appropriate use of edge and public cloud based on specific business requirements, rather than one being better than the other. The answer here lies in hybrid solutions.
People have been talking about hybrid for a little while now, but the evolution of services and architectures that support this model has yet to catch up with requirements. Yet that is about to change. Microsoft will later this year release Azure Stack, a solution that is very much focused towards putting services and capabilities at the edge, while ensuring that the benefits of hyper-scale computing and services in the (public) cloud are available when required.
The idea of buying a private version of Azure — with all its inherent services and capabilities — and putting this at the edge to deal with latency, governance, IOT, security and other edge requirements (and doing so in essentially the same ecosystem), is one that will prove to be a game changer.
It is likely that businesses will continue to just test the water for the time being and won’t move everything previously kept at the core towards the edge — instead they will rather pick and choose depending on circumstances. We have lived through a period where public cloud has been seen as the bright new shiny toy, capable of solving all the ills of corporate IT. As the public cloud matures and evolves, people are naturally starting to see use cases where the edge has distinct advantages over centralised cloud scenarios.
It’s about an appropriate use of these two models based on need rather than one being better than the other – the answer here is about hybrid solutions and building true end-to-end hybrid ecosystems that allow you to get the best of both worlds.
The nature of what is defined as an edge or regional datacentre may well soon change. Microsoft’s soon-to-be-released Azure Stack solution is a great example of how a previously mothballed regional datacentre might be repurposed.
Rather than an edge datacentre being all about building your own private cloud or a traditional colocation process, it could instead become a secure facility for hosting private Azure appliances. This is certainly what Microsoft hopes.
Today, the company has 38 core datacentre sites around the world, but if you look at the distribution it’s easy to find a few blackspots. What it hopes is that local and global hosting providers will take up Azure Stack and put these private cloud environments into local and regional datacentres. This would then light up Azure edge services in geographic regions where large-scale core datacentre investment is not practical for political, geographical or economic reasons.
Bringing private cloud capability back to the edge is one of the biggest game changers we will see in the next 12 months. Azure is the very first viable edge option to be introduced in the marketplace, and currently the only one available to businesses. If other providers want to remain relevant to the edge then they will also have to evolve true hybrid strategies, and this could happen in the near future. However, in today’s landscape, it is Microsoft that has the edge!
Over the last year, the total global traffic handled by Data Centres reached five petabytes. To put that into perspective: one zettabyte is equal to about a trillion gigabytes or the content of 250 billion DVDs. Over the next three years, network consolidation, automation, the further rise of IoT and cloud applications. These developments have several consequences for Data Centres design and operation.
By Andreas Rüsseler, CMO, R&M.

Devices connected to the Internet of Things are constantly transmitting data. Predictions claim there will be up to 30 billion online ‘things’ by 2020, from surveillance cameras and industrial robots to living room thermostats and health monitoring devices. Most IoT data will end up in Data Centres, which means they need to enhance their infrastructures and provide permanently available networks. Cloud Data Centres are responsible for 70% of IT work around the world. Recent studies show that around 91% of internet data traffic is related to video transmissions. The vast takeup of action cameras, dashcams and high resolution mobile phones, will continue to contribute to this.
Infrastructure in and outside the data centre has to be reliable, flexible and scalable to accommodate the demands of current and future applications. The largest possible port density needs to be realised in the smallest possible space. For edge networks, which move content such as HDTV programmes closer to the end user, high density of more than 100 ports per rack unit is essential. After all, these systems may have to support several consecutive generations of hardware and bandwidth standards. Traditional 72 ports per unit UHD solutions won’t do the job.
Current high-density fibre solutions for data centres generally offer up to 72 LC duplex ports per rack unit. However, this can introduce management difficulties.
When developing a high density solution, various factors, such as physical properties need to be taken into account. For example, higher density infrastructure requires more energy and produces more heat and racks can be be significantly heavier. Consolidating POP servers in a single rack unit leaves more space for switches and routers. Software Defined Network (SDN) architectures can be planned more sensibly. High density makes it possible to free up space for additional racks and switches and minimize the meet-me-room area.
High Density solutions can, in many cases, offer a lower cost per port than existing platforms, and provide a flexible upgrade path to accommodate needs for many years to come. What’s more you can increase port density and improve organization of ports and cabling. Adhering to structured cabling standards such as TIA-942 also becomes easier, as do MACs and maintenance – if you think ahead when specifying and implementing a HD solution.
Increased density can often result in unmanageable cabling. Fault-finding, Moves, Adds and Changes and cable tracking may be severely hindered. Troubleshooting or making decisions regarding infrastructural changes based on incorrect, out-of-date or unreliable documentation is like walking a tightrope without a safety net. An integrated hardware and software system can automatically detect when cords are inserted or removed. The entire infrastructure is represented in a consistent, up to date database, offering precise, real-time information on the current state and future requirements of the data centre. Cabling infrastructure, including connected equipment, can be documented on an ongoing basis and monitored and administrated from a common software tool.
Such automated tracing and monitoring of all changes to a physical network, including switches, servers and patch panels improves operational efficiency and facilitates passive infrastructure management. A solution which offers functions for mapping, managing, analysing and planning cabling and cabinets adds to that even further. These systems may also be used to take care of asset management, planned and unplanned changes and alarms.
Organising trays and cable management in a way that respects fibre cables’ bend radius avoids performance limitations, damage and downtime. Cables should have a very high fibre count, be easy to terminate and it should be possible to handle them in the same way as smaller cables. Bad cable management can result in inter-symbol interference, damage and failure, resulting in data transmission errors, performance issues and downtime. We recommend double-checking measurements and the quality of terminations, testing wherever necessary, labelling and colour coding, avoiding tight conduits and ensuring no cables or bundles resting upon others.
Vast data traffic increases and new applications are driving Data Centres to look at higher performance network architectures. Data-hungry technology solutions might expand at amazing speeds; however, the backbone can’t simply be replaced every few years. Data centres will soon need far more bandwidth than current infrastructure can provide. If specified and employed properly, high density solutions can play an important role in accommodating this growth.