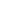I’m delighted that this issue of DCS contains several articles on the topic of data centre design. With the IT world moving so rapidly, and the promise of more disruption/innovation to come, it’s fair to say that data centre design has never been so important. Legacy facilities are already struggling to keep up with the demand of modern IT, and they’ll soon be swamped by the extra demands placed on them by wholescale digitalisation, unless they are updated and/or amended to be able to continue to play a useful part in the rapidly changing data centre landscape.
When Cloud first burst on to the scene, the theory was that everyone would move everything into the public cloud. Then there was something of a backlash, and the private cloud gained attention before, sensibly, the hybrid cloud – a mixture of private and public – became the preferred solution. It’s a similar story when it comes to data centres, where we’ve moved from private, to public, and now to a mixture of both, but we also have the added twist where everything was being centralised, and no it’s time (again) to start distributing data content – edge computing has arrived!
So, how and where your data centre(s) is/are located matters massively, depending on the focus of your business. And, while you might want to own as many of your data centre assets as possible, when it comes to keeping and processing data at a local level, it’s unlikely to make financial sense to build/own/operate your own facility. Much more likely that regional colos will be doing a roaring trade as more and more content is pushed closer to the consumer and more and more locally produced data is processed and consumed locally, without ever making it back to a big, centralised data centre facility.
Flexibility would seem to be key, once you’ve understood what it is you’re trying to achieve with your data centre real estate. And don’t leave it much longer before you do sit down and gain this understanding. IoT, Big Data and, no doubt, the next big thing, are rather like ‘time and tide’ – they wait for no man, or woman.

According to new research from International Data Corporation (IDC), cloud service providers are at risk of underestimating the impact of new data protection legislation on their business models. The General Data Protection Regulation (GDPR) applies from May 25, 2018, and introduces substantial changes in the way that personal data must be protected. As organizations move to the cloud they must assure themselves of their service providers' understanding of the new obligations. Equally, CSPs must understand the extent to which they now have liability under GDPR, and how they can construct workable and valid contractual agreements.
"CSPs must act immediately to consider their position under the GDPR, and review all systems and processes before the 2018 deadline," said Duncan Brown, associate vice president of security at IDC. "GDPR means increased risk and higher costs for CSPs dealing with personal data."
Most CSPs will be affected by GDPR because the definition of processing is broad and includes simply storing personal data. Similarly, personal data is also broadly defined and includes any data that relates to an identified or identifiable living human. "Many CSPs are unaware of these broad scoping definitions and are thus unprepared for their GDPR obligations," said Brown.
The IDC report — The Impact of GDPR on Cloud Service Providers — is divided into two parts. The first examines general considerations for contracts and liability, while the second focuses on security, international data transfers, and other considerations.
The report notes that CSPs not based in the EU will be impacted by GDPR if they are offering goods or services to EU-based individuals, either directly or via a customer organization such as a retailer or SaaS provider. Importantly, it does not matter if a CSP knows whether its customers are using its service to process personal data. "Ignorance is no defense," said Brown.
IDC recommends that CSPs understand the cloud supply chain, and conduct due diligence on subprocessors. Audits of subprocessors will be important, and CSPs may also begin auditing their customers to ensure that cloud services are used in a compliant manner.

Total worldwide enterprise storage systems factory revenue was down 0.5% year over year and reached $9.2 billion in the first quarter of 2017 (1Q17), according to the International Data Corporation (IDC) Worldwide Quarterly Enterprise Storage Systems Tracker. Total capacity shipments were up 41.4% year over year to 50.1 exabytes during the quarter. Revenue growth increased within the group of original design manufacturers (ODMs) that sell directly to hyperscale datacenters. This portion of the market was up 78.2% year over year to $1.2 billion. Sales of server-based storage were down 13.7% during the quarter and accounted for $2.7 billion in revenue. External storage systems remained the largest market segment, but the $5.2 billion in sales represented a modest decline of 2.8% year over year.
"The enterprise storage market closed out the first quarter relatively flat, yet adhered to a familiar pattern," said Liz Conner, research manager, Storage Systems. "Spending on traditional external arrays continues to slowly shrink while spending on all-flash deployments once again posted strong growth and helped to drive the overall market. Meanwhile the very nature of the hyperscale business leads to heavy fluctuations within the market segment, displaying solid growth in 1Q17."
1Q17 Total Enterprise Storage Systems Market Results, by Company
Dell Inc held the number 1 position within the total worldwide enterprise storage systems market, accounting for 21.5% of spending. HPE held the next position with a 20.3% share of revenue during the quarter. HPE's share and year-over-year growth rate includes revenues from the H3C joint venture in China that began in May of 2016; as a result, the reported HPE/New H3C Group combines storage revenue for both companies globally. NetApp finished third with 8.0% market share. Hitachi and IBM finished in a statistical tie* for the fourth position, each capturing 5.0% of global spending. As a single group, storage systems sales by original design manufacturers (ODMs) selling directly to hyperscale datacenter customers accounted for 13.2% of global spending during the quarter.
| Top 5 Vendor Groups, Worldwide Total Enterprise Storage Systems Market, First Quarter of 2017 (Revenues are in US$ millions) | |||||
| Company | 1Q17 Revenue | 1Q17 Market Share | 1Q16 Revenue | 1Q16 Market Share | 1Q17/1Q16 Revenue Growth |
| 1. Dell Inca | $1,968.5 | 21.5% | $2,304.2 | 25.0% | -14.6% |
| 2. HPE/New H3C Group b | $1,865.0 | 20.3% | $2,289.9 | 24.8% | -18.6% |
| 3. NetApp | $731.6 | 8.0% | $645.5 | 7.0% | 13.3% |
| T4. Hitachi* | $460.1 | 5.0% | $508.0 | 5.5% | -9.4% |
| T4. IBM* | $455.3 | 5.0% | $448.5 | 4.9% | 1.5% |
| ODM Direct | $1,212.9 | 13.2% | $680.5 | 7.4% | 78.2% |
| Others | $2,478.6 | 27.0% | $2,344.4 | 25.4% | 5.7% |
| All Vendors | $9,172.0 | 100.0% | $9,221.0 | 100.0% | -0.5% |
| Source: IDC Worldwide Quarterly Enterprise Storage Systems Tracker, June 8, 2017 | |||||
Notes:
* – IDC declares a statistical tie in the worldwide enterprise storage systems market when there is less than one percent difference in the revenue share of two or more vendors.
a – Dell Inc represents the combined revenues for Dell and EMC.
b – Due to the existing joint venture between HPE and the New H3C Group, IDC will be reporting external market share on a global level for HPE as "HPE/New H3C Group" starting from 2Q 2016 and going forward.
1Q17 External Enterprise Storage Systems Results, by Company
Dell Inc was the largest external enterprise storage systems supplier during the quarter, accounting for 27.2% of worldwide revenues. NetApp finished in the number 2 position and HPE in the number 3 position with 14.0% and 9.7% of market share, respectively. Hitachi and IBM rounded out the top 5 in a statistical tie* for the number 4 position with revenue shares of 8.6% and 8.4%, respectively.
| Top 5 Vendors Groups, Worldwide External Enterprise Storage Systems Market, First Quarter of 2017 (Revenues are in Millions) | |||||
| Company | 1Q17 Revenue | 1Q17 Market Share | 1Q16 Revenue | 1Q16 Market Share | 1Q17/1Q16 Revenue Growth |
| 1. Dell Inca | $1,424.6 | 27.2% | $1,696.7 | 31.5% | -16.0% |
| 2. NetApp | $731.6 | 14.0% | $645.5 | 12.0% | 13.3% |
| 3. HPE/New H3C Group b | $511.0 | 9.7% | $535.7 | 9.9% | -4.6% |
| T4. Hitachi* | $449.1 | 8.6% | $497.1 | 9.2% | -9.6% |
| T4. IBM* | $440.6 | 8.4% | $429.0 | 8.0% | 2.7% |
| Others | $1,684.9 | 32.1% | $1,589.5 | 29.5% | 6.0% |
| All Vendors | $5,241.9 | 100.0% | $5,393.6 | 100.0% | -2.8% |
| Source: IDC Worldwide Quarterly Enterprise Storage Systems Tracker, June 8, 2017 | |||||

Software-defined networking has reached the wide area network (WAN). Software-defined WANs (SD-WANs) will play a key role in network evolution as organizations try to cope with the accelerating requirements resulting from digital transformation. In a new report, International Data Corporation (IDC) foresees rapidly growing demand for SD-WAN solutions in Europe, the Middle East, and Africa (EMEA).
SD-WANs build on hybrid network architectures that have been rising in popularity for years, but add centralized software-based intelligence that monitors, analyzes, and controls the network, allowing end users to mix and match different forms of connectivity (like MPLS, internet, Ethernet, wireless) and services into a hybrid network that provides an optimal combination of cost and performance for every single location and application.
The momentum behind SD-WAN is strong, with many startup and established vendors and service providers jumping on the bandwagon. For end-user organizations the rationale for adoption is compelling, and IDC believes this will only increase as solutions mature and awareness and recognition of its benefits grow. The consequence will be a high growth opportunity, with revenues in EMEA expected to grow at an average pace of 92% per year to reach $2.1 billion by 2021.
"SD-WAN has emerged as one of the hottest topics in the WAN industry," said Jan Hein Bakkers, senior research manager at IDC. "It will become one of the key building blocks of network evolution, driving the flexibility, manageability, scalability, and cost effectiveness that organizations require in their balancing act between rapidly growing requirements and much flatter budgets."

According to the International Data Corporation (IDC) Worldwide Quarterly Converged Systems Tracker, the worldwide converged systems market revenues increased 4.6% year over year to $2.67 billion during the first quarter of 2017 (1Q17). The market consumed 1.48 exabytes of new storage capacity during the quarter, which was up only 7.1% compared to the same period a year ago.
"Converged systems have become an important source of innovation and growth for the data center infrastructure market," said Eric Sheppard, research director, Enterprise Storage & Converged Systems. “These solutions represent a conduit for the key technologies driving much needed data center modernization and efficiencies such as flash, software-defined infrastructure and private cloud platforms."
Converged Systems Segments
IDC's converged systems market view offers four segments: integrated infrastructure, certified reference systems, integrated platforms, and hyperconverged systems. Integrated infrastructure and certified reference systems are pre-integrated, vendor-certified systems containing server hardware, disk storage systems, networking equipment, and basic element/systems management software. Integrated Platforms are integrated systems that are sold with additional pre-integrated packaged software and customized system engineering optimized to enable such functions as application development software, databases, testing, and integration tools. Hyperconverged systems collapse core storage and compute functionality into a single, highly virtualized solution. A key characteristic of hyperconverged systems that differentiate these solutions from other integrated systems is their scale-out architecture and their ability to provide all compute and storage functions through the same x86 server-based resources.
During the first quarter of 2017, the combined integrated infrastructure and certified reference systems market generated revenues of $1.37 billion, which represented a year-over-year decrease of 3.3% and 51.3% of the total market. Dell Inc. was the largest supplier of this combined market segment with $647.8 million in sales, or 47.2% share of the market segment.
| Top 3 Vendors, Worldwide Integrated Infrastructure and Certified Reference Systems, First Quarter of 2017 (Revenues are in Millions) | |||||
| Vendor | 1Q17 Revenue | 1Q17 Market Share | 1Q16 Revenue | 1Q16 Market Share | 1Q17 /1Q16 Revenue Growth |
| 1. Dell Inc.* | $647.8 | 47.2% | $667.3 | 47.0% | -2.9% |
| 2. Cisco/NetApp | $395.6 | 28.8% | $313.7 | 22.1% | 26.1% |
| 3. HPE | $206.2 | 15.0% | $291.1 | 20.5% | -29.2% |
| All Others | $122.8 | 9.0% | $146.9 | 10.4% | -16.4% |
| Total | $1,372.5 | 100% | 1,419.1 | 100% | -3.3% |
| Source: IDC Worldwide Quarterly Converged Systems Tracker, June 22, 2017 | |||||
* Note: Dell Inc. represents the combined revenues for Dell and EMC sales for all quarters shown.
Integrated Platform sales declined 13.3% year over year during the first quarter of 2017, generating $635.9 million worth of sales. This amounted to 23.8% of the total market revenue. Oracle was the top-ranked supplier of Integrated Platforms during the quarter, generating revenues of $348.7 million and capturing a 54.8% share of the market segment.
| Top 3 Vendors, Worldwide Integrated Platforms, First Quarter of 2017 (Revenues are in Millions) | |||||
| Vendor | 1Q17 Revenue | 1Q17 Market Share | 1Q16 Revenue | 1Q17 Market Share | 1Q17 /1Q16 Revenue Growth |
| 1. Oracle | $348.7 | 54.8% | $379.6 | 51.8% | -8.1% |
| 2. HPE | $61.7 | 9.7% | $65.8 | 9.0% | -6.2% |
| T3* IBM | $19.9 | 3.1% | $26.6 | 3.6% | -25.1% |
| T3* Hitachi | $19.6 | 3.1% | $28.0 | 3.8% | -30.1% |
| All Others | $185.9 | 29.2% | $233.1 | 31.3% | -20.2% |
| Total | $635.9 | 100% | $733.1 | 100% | -13.3% |
| Source: IDC Worldwide Quarterly Converged Systems Tracker, June 22, 2017 | |||||
* Note: IDC declares a statistical tie in the worldwide converged systems market when there is a difference of one percent or less in the vendor revenue shares among two or more vendors.
Hyperconverged sales grew 64.7% year over year during the first quarter of 2017, generating $665.1 million worth of sales. This amounted to 24.9% of the total market value.

Gartner, Inc. has highlighted the top technologies for information security and their implications for security organizations in 2017.
"In 2017, the threat level to enterprise IT continues to be at very high levels, with daily accounts in the media of large breaches and attacks. As attackers improve their capabilities, enterprises must also improve their ability to protect access and protect from attacks," said Neil MacDonald, vice president, distinguished analyst and Gartner Fellow Emeritus. "Security and risk leaders must evaluate and engage with the latest technologies to protect against advanced attacks, better enable digital business transformation and embrace new computing styles such as cloud, mobile and DevOps."
The top technologies for information security are:
Cloud Workload Protection Platforms
Modern data centers support workloads that run in physical machines, virtual machines (VMs), containers, private cloud infrastructure and almost always include some workloads running in one or more public cloud infrastructure as a service (IaaS) providers. Hybrid cloud workload protection platforms (CWPP) provide information security leaders with an integrated way to protect these workloads using a single management console and a single way to express security policy, regardless of where the workload runs.
Remote Browser
Almost all successful attacks originate from the public internet, and browser-based attacks are the leading source of attacks on users. Information security architects can't stop attacks, but can contain damage by isolating end-user internet browsing sessions from enterprise endpoints and networks. By isolating the browsing function, malware is kept off of the end-user's system and the enterprise has significantly reduced the surface area for attack by shifting the risk of attack to the server sessions, which can be reset to a known good state on every new browsing session, tab opened or URL accessed.

Deception
Deception technologies are defined by the use of deceits, decoys and/or tricks designed to thwart, or throw off, an attacker's cognitive processes, disrupt an attacker's automation tools, delay an attacker's activities or detect an attack. By using deception technology behind the enterprise firewall, enterprises can better detect attackers that have penetrated their defenses with a high level of confidence in the events detected. Deception technology implementations now span multiple layers within the stack, including endpoint, network, application and data.
Endpoint Detection and Response
Endpoint detection and response (EDR) solutions augment traditional endpoint preventative controls such as an antivirus by monitoring endpoints for indications of unusual behavior and activities indicative of malicious intent. Gartner predicts that by 2020, 80 percent of large enterprises, 25 percent of midsize organizations and 10 percent of small organizations will have invested in EDR capabilities.
Network Traffic Analysis
Network traffic analysis (NTA) solutions monitor network traffic, flows, connections and objects for behaviors indicative of malicious intent. Enterprises looking for a network-based approach to identify advanced attacks that have bypassed perimeter security should consider NTA as a way to help identify, manage and triage these events.
Managed Detection and Response
Managed detection and response (MDR) providers deliver services for buyers looking to improve their threat detection, incident response and continuous-monitoring capabilities, but don't have the expertise or resources to do it on their own. Demand from the small or midsize business (SMB) and small-enterprise space has been particularly strong, as MDR services hit a "sweet spot" with these organizations, due to their lack of investment in threat detection capabilities.
Microsegmentation
Once attackers have gained a foothold in enterprise systems, they typically can move unimpeded laterally ("east/west") to other systems. Microsegmentation is the process of implementing isolation and segmentation for security purposes within the virtual data center. Like bulkheads in a submarine, microsegmentation helps to limit the damage from a breach when it occurs. Microsegmentation has been used to describe mostly the east-west or lateral communication between servers in the same tier or zone, but it has evolved to be used now for most of communication in virtual data centers.
Software-Defined Perimeters
A software-defined perimeter (SDP) defines a logical set of disparate, network-connected participants within a secure computing enclave. The resources are typically hidden from public discovery, and access is restricted via a trust broker to the specified participants of the enclave, removing the assets from public visibility and reducing the surface area for attack. Gartner predicts that through the end of 2017, at least 10 percent of enterprise organizations will leverage software-defined perimeter (SDP) technology to isolate sensitive environments.
Cloud Access Security Brokers
Cloud access security brokers (CASBs) address gaps in security resulting from the significant increase in cloud service and mobile usage. CASBs provide information security professionals with a single point of control over multiple cloud service concurrently, for any user or device. The continued and growing significance of SaaS, combined with persistent concerns about security, privacy and compliance, continues to increase the urgency for control and visibility of cloud services.
OSS Security Scanning and Software Composition Analysis for DevSecOps
Information security architects must be able to automatically incorporate security controls without manual configuration throughout a DevSecOps cycle in a way that is as transparent as possible to DevOps teams and doesn't impede DevOps agility, but fulfills legal and regulatory compliance requirements as well as manages risk. Security controls must be capable of automation within DevOps toolchains in order to enable this objective. Software composition analysis (SCA) tools specifically analyze the source code, modules, frameworks and libraries that a developer is using to identify and inventory OSS components and to identify any known security vulnerabilities or licensing issues before the application is released into production.
Container Security
Containers use a shared operating system (OS) model. An attack on a vulnerability in the host OS could lead to a compromise of all containers. Containers are not inherently unsecure, but they are being deployed in an unsecure manner by developers, with little or no involvement from security teams and little guidance from security architects. Traditional network and host-based security solutions are blind to containers. Container security solutions protect the entire life cycle of containers from creation into production and most of the container security solutions provide preproduction scanning combined with runtime monitoring and protection.

IT Europa and Angel Business Communications’ new event – the Managed Services Solutions Summit 2017 - is designed to help executives of enterprises, organisations and public sector bodies navigate the managed services maze and get the most out of managed services-based solutions. It builds on the seven-year history of highly successful UK and European Managed Services and Hosting Summit series of channel events.
The rapid growth in managed services and provision of IT as a service is changing the way customers wish to purchase, consume and pay for their IT solutions but evaluating and selecting which services are best suited to particular business needs creates its own challenges. The Managed Services Solutions Summit 2017 is an executive-level conference which will set out to demystify both the new technologies and the new delivery mechanisms and business models.
The event will feature conference session presentations by major industry speakers and a range of breakout sessions exploring in further detail some of the major issues impacting the development of managed services. The summit will also provide extensive networking time for delegates to meet with potential business partners. The unique mix of high-level presentations plus the ability to meet, discuss and debate the related business issues with sponsors and peers across the industry, will make this a must-attend event for any senior decision maker involved in buying information and communication technologies and services.

The Managed Services Solutions Summit 2017 will be staged in London on 22 November 201. The event is free to attend for qualifying delegates (senior managers and executives of businesses and public sector organisations). Those wishing to attend the event or IT hardware or software vendors, hosting providers, data centre co-location providers, ISVs and any other organisations involved in services delivered to end-users can find further information at: www.msssummit.co.uk
IT Europa (www.iteuropa.com) is the leading provider of strategic business intelligence, news and analysis on the European IT marketplace and the primary channels that serve it. In addition to its news services the company markets a range of database reports and organises European conferences and events for the IT and Telecoms sectors.
Angel Business Communications (www.angelbc.com) is an industry leading B2B publisher and conference and exhibition organiser. ABC has developed skills in various market sectors - including Semiconductor Manufacturing, IT - Storage Networking, Data Centres and Solar manufacturing. With offices in both Watford and Coventry, it has the infrastructure to develop a leadership role in the markets it serves by providing a multi-faceted approach to the business of providing business with the information it needs.

The 11th July 2017 sees the next in the highly successful series of Data Centre Transformation Manchester (DT Manchester) events, organised by Angel Business Communications, in association with Datacentre Solutions, the University of Leeds and the Data Centre Alliance.
The combination of such data centre knowledge and expertise ensures that DT Manchester is the premier data centre education event in the calendar, bringing together the data centre research and design community, the data centre vendor industry and, most importantly, enterprise end users, for a collaborative information interchange.
In 2017 DT Manchester will be running six Workshop sessions, covering a range of topics: Power including Power Management, Cooling, IT Energy & Availability, Business Needs & Management, Capability and Workforce Development. The workshops will be managed by independent industry specialists to ensure vendor neutrality. The workshops will ensure that delegates not only earn valuable CPD accreditation points but also have an open forum to speak with their peers, academics and leading vendors and suppliers.
The Workshops are complemented by Keynote presentations from major industry figures: John Kennedy, Senior Researcher at Intel and Tor Bjorn Munder, Head of Research Strategy at Ericsson & CEO SICS North Swedish ICT AB. Workshops and Keynotes, together with networking opportunities provide the perfect blend of educational and informative content and information exchange which is truly valued by the hundreds of delegates who attend.

2017 promises to be an exciting year for the data centre industry, as much of the received data centre design and operations ‘wisdom’ is being challenged not just by the maturing Cloud/managed services model, but by a host of new and emerging threats and opportunities: the Internet of Things, digitalisation, mobility, DevOps and micro data centres to name but a few. In simple terms, more and more intelligence is being brought in at all levels of both the facilities and IT aspects of the data centre – and by combining the information this provides, there are some huge efficiency and optimisation gains to be made by data centre owners and operators.
The Workshop sessions will address the fast moving technological evolution of data centres as mission critical facilities, this includes:
The overall objective of DT Manchester is to reflect the ongoing need for the facilities and IT functions to join together to ensure the optimum data centre environment that can best serve the enterprise’s business requirements. After all, data centres do not exist in isolation, but are the engines that drive the critical applications on which the enterprise relies.
For more information and to register visit: www.dtmanchester.com/register
As the next generation of digital infrastructure unfolds, there is a widespread expectation that a new tier of datacentres, or at least of compute and storage capacity, will need to be built to meet the latest demands of edge computing.
By Rhonda Ascierto Research Director, Datacenter Technologies & Eco-Efficient IT, 451 Research and Daniel Bizo Senior Analyst, Datacenter Technologies, 451 Research.


The Internet of Things (IoT), distributed cloud and other edge use cases will require computing, routing, caching and storage, localized analytics, and some automation and policy management close to where there are users and 'things.' Some suppliers, ranging from Schneider Electric and Vertiv to Dell, Ericsson Huawei and Nokia, expect that microdatacenters will play a leading role in meeting distributed edge demand.
Others such as Google are less convinced and are focused on building networks and capacity one step back from the edge – to the 'near edge.' Some say that edge datacentres will be relatively niche, citing the main use case as CDNs because of their high data volumes. In most other cases, they say, data volumes and latency needs will not need a 'dedicated' edge datacentre. They say the build out of new large and hyperscale datacentres, supported by reliable networks, will bring the edge much closer to users and 'things.'
Both arguments will likely bear out over time: the edge will almost certainly require many different datacentre types – and probably many of them. They will range from hyperscale cloud and large colocation facilities that are sited near or near enough to the point of use to support many applications, to new micro-modular datacentres at the edge, to smaller clusters of capacity that are not large or critical enough to even be described as datacentres.
The connectivity paths and datacentres required for different edge use cases will vary, although patterns of similar architectures are likely. Here at 451 Research we are bullish on the edge opportunity for micro-modular datacentres, including for integrated IT datacentre products via supplier partnerships (and with remote management services in the mix). At the same time, IoT gateways/systems are becoming increasingly sophisticated with more compute, storage and analytics.
At the near edge, colocation providers are dominating – their focus is on developing properties into connectivity-rich multi-MW datacentres with a 15-plus-year investment timeline. This may change for top-tier metro markets in the next 5-10 years (or sooner) if cloud giants follow through on a strategy of building additional capacity or shift existing capacity to their own datacentres (along with new investments in dark fibre). It is unclear how far the cloud giants will reach into the 'true' edge where telcos will become either key players or key partners.
Where is the edge?
The location of the edge is largely defined at the highest level by the application and workload function of the compute. It can include the physical or virtual location of the following:
Distributed datacentres at the edge
The volume of traffic in some distributed edge datacentres will be very high, and many data sets and applications may be involved. Failures or congestion in networks may cause serious problems in machines, devices and user experience – driving requirements for flexible, agile networking approaches, such as software-defined networking. Two-tier, leaf-and-spine architectures inside the datacentre will be ideal for optimized throughput and redundancy because of the vastly increased traffic between different services.
To understand the different types of datacentres required at the edge, it is useful to differentiate between edge and near edge.
Edge datacentre functions
The true edge is sometimes defined as where near-real-time response and action is needed, measured in sub-2 milliseconds (low or ultra-low latency). Ideally, there would be no – or very few – network paths or 'hops' and very little or no use of shared communications infrastructure between the user/data collection point and the true edge point of processing/aggregation. (When 451 Research has asked enterprise customers what they mean by edge, answers have varied: Some say at the device; others at the first point of aggregation; and others at the point where CIO control, in the form of performance or security, etc., and ownership begins.)
In some cases, telecom gateways such as 4G and 5G base stations and towers will require dedicated datacentre capacity to be collocated very close by, most likely in the form of micro-modular datacentres. These will meet the needs of east-west traffic at the edge where fibre is not an economic or otherwise practical option, such as, for example, between end-user devices and services near each other.
Some edge applications, including process manufacturing and the teleoperation of vehicles, generate data that requires rapid response and action. They need platforms that transform the data streams into formats that can be processed by applications that analyse and act on the data in real time. Wireless networks to support this with management software, protocols and processing/storage are known as ultra-reliable low-latency communications. In these environments, compute and storage capacity is required very close to the point of data generation – these are true edge computing functions.
This true edge processing capability is also referred to as 'fog computing,' which involves performing the required analysis and taking the resultant action as closely as possible to the data – or things of IoT. In other words, below the level of the centralised cloud.
To address this need, manufacturers such as Intel, HPE, Nokia, Dell EMC, Lenovo and Huawei, among others, sell local gateways that are essentially access routers with special interfaces (MODBUS, CANBUS, etc.) with varying degrees of compute and storage capability and that have the capability for VMs or containers to run applications. While this is a good and possibly the only viable solution for many environments, the scale of some potential IoT deployments will require hundreds or thousands of gateways, representing a considerable capital expense, in addition to the ongoing management and security of the gateways. In these cases, localized datacentre capacity will be needed that is one step back – the near edge.
Near-edge datacentre functions
The near edge can be broadly defined as the 'zone' where sub-millisecond latency, or low-single-digit latency, cannot (usually) be guaranteed across available networks, but performance and security has been architected to securely process, analyse, store and forward larger amounts of data – and possibly to connect to other applications and data sources – without going back to a centralized cloud service. Near-edge datacentres will likely be a mix of microdatacenters and much larger facilities, including enterprise, colocation and cloud datacentres that are sited deliberately or coincidentally near the user of the data.
Equinix, for example, positions its colocation and interconnection facilities as offering cost and management benefits over fully distributed edge environments (one or more aggregation points or devices at the interconnect versus hundreds or thousands of smaller devices to manage) and performance benefits over fully centralized cloud models. One of the notable moves by the company in this area is its Data Hub, which combines its interconnection and colocation service with tiered cloud-integrated storage to provide a potential aggregation layer for large amounts of IoT and other edge computing data. The service offers the opportunity for near-local storage, analysis and action of data, including data integration, as well as potential summarization of a large amount of data prior to backhaul to a centralized cloud.

Networking and datacentre topologies at the edge
Generally speaking, datacentre and network topologies to support low and medium latency and high traffic will vary. The deployment of 5G networks (likely to begin in 2019/2020 in pioneering countries such as South Korea and Japan) will reshape connectivity architectures for edge datacentres. In principle, 5G enables very good connectivity coverage from multiple gateways (cell towers) – if one gateway fails, the signal is picked up by another. With its 10Gbps design goal, one potential application of 5G is to replace the need for local high-bandwidth fibre to the edge, especially in some remote locations.
Ideally, 5G networking routes will be optimized, hopping intelligently between different 5G networks and cell towers. To optimize and utilize bandwidth more effectively, network management is increasingly being virtualized and separated from switches and devices. If visualized, these edge network and edge datacentre architectures may look something like the schema below, with true edge microdatacenters, and IoT and telecom gateways (at the very bottom) performing aggregation, control and analytics.
Potential Networking and Datacenter Topologies at the Edge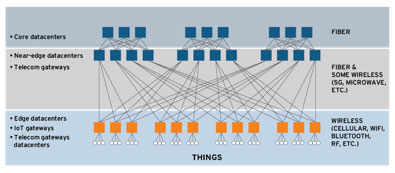
Source: 451 Research, Datacenters and Critical Infrastructure, 2017
Datacentres at the edge
Even within similar IoT use cases, there will be many different network architectures and datacentre types. It is likely that several IoT deployments will end up storing, integrating and moving data across a combination of public cloud and other commercial facilities, with both distributed micro and very large centralized datacentres playing a role. Some microdatacenters at the edge and near edge will incorporate software and network resiliency/capacity to enable failover to nearby similar facilities. This may mean that they will have relatively low physical resiliency/redundancy capabilities.
Key data and data needed by other applications and people will in some cases be made available at the near edge – including in large colocation and other metro datacentres. Cloud heavyweights are rapidly building hyperscale facilities with direct fibre links to leased colocation sites. These direct connects reduce latency and increase security and reliability, bringing hyperscale cloud capacity closer to the edge – effectively functioning as near-edge datacentre capacity.
Once consumed or integrated, data will then typically be moved or streamed into large or hyperscale, remote datacentres to be aggregated, analysed (including through integration with other data and applications) and archived. These large facilities represent the 'core layer.'
The figure below shows a broad schema of different types of datacentres and data paths for IoT and other types of edge computing, spanning the true and near edge and core layers.
Datacentres for IoT and Edge Computing
Source: 451 Research, Datacenters and Critical Infrastructure, 2017
Summary: Edge datacentre technologies
Although edge computing itself is not a specific technology, it will incorporate and attract a host of datacentre technologies and techniques that will make edge processing and storage a more effective deployment option. These include but are not limited to:
Suppliers are lining up behind the edge opportunity: there were 44 deals involving edge computing technologies in 2015 and 2016, according to 451 Research's M&A KnowledgeBase.

By Steve Hone, DCA CEO, Data Centre Trade Association
We always seem to get a great response from both members and academic partners for the summer edition of the DCA journal. It’s not surprising really when you consider the subject matter being discussed. It is a subject which will already be effecting most businesses as data demand continues to grow.
-nlhew5.jpg)
This month, the journal’s theme is “Education, Awareness, Skills and Training”. I consider all to be vitally important to the future health of our sector however I would like to focus this month on the one I feel is absolutely critical to our sectors future sustainability and that is ‘awareness’.
So, why do I put so much emphasis on ‘awareness’? Well, there are lots of reasons; one reason is that no one outside our little data centre fraternity seems truly aware that we exist or how instrumental the data centre sector is in supporting the global digital economy or the online services we all take for granted; (the recent issue with BA being a great example of this). It is for this very reason the Trade Association has a strong Public Affairs focus to help build bridges between DCA members, the sector and local Government.
The other reason is simply one of “supply and demand” - the demand is clear for all to see. It’s an undeniable fact that the demand for digital services is set for exponential growth over the next 10 years. That’s good and bad news. The good news is obvious, however the bad news is we seem unable to supply or find enough new talent to help swell our ranks to service this projected demand. The bottom line is it’s no good just concentrating on having great educational and training programmes if we can’t find ways to encourage fresh talent to enter the sector at ground level.
Funnily enough very few realise that household names such as Google, Amazon, eBay, Apple, WhatsApp, Snapchat and Uber all heavily rely on the data centre sector to deliver their services, and none of these organisations seem to have issues finding new talent, so what’s their secret?
Well, actually it’s not a secret at all - it’s because they’re not having to find new talent at all– they’re actually attracting it with relative ease. Like “bees to honey” the next generation of app-enabled (or in the case of my teenage son app-dependant), see these brands as sexy, cool and an integral part of their lives. These same teenagers just happen to also be the very consumers who are largely driving the data boom and remain blissfully unaware of what is going on behind the scenes to make these organisations shine. Like the proverbial iceberg they are only seeing what lies above the waterline.
There lies the challenge, it’s a problem we can only fix by pulling together and the trade association can only do this with your help. How do we make the next generation more aware of what the data centre sector is all about? Let’s face it not everyone can work for Google. Below the water line there are literally 1000’s of other career opportunities on offer and 10,000’s of jobs up for grabs in our sector. We just need to be doing a better job at helping the next generation see the bigger picture.
I would like to thank all those who contributed to this month’s DCA Journal and look forward to seeing you all at this year’s DCA Update Seminar and DTC Conference in Manchester on the 10th/11th in July, which is kindly organised for the DCA by Angel Communications (DCS).

By Sarah Parks PgDip MCIM, Director of Marketing and Communications, CNet Training - An Academia Group Company
The importance of education within the data centre sector is often overlooked and sometimes forgotten when it comes to planning budgets. This is in addition to the usual organisational distractions where personal development is an easy ‘pick’ to push aside and put off to the future. Yet, there is a strong connection between having a team of professionally educated and competent staff and organisational risk.

For many years now the outage figures attributed to human error have remained static at around 70%, costing companies thousands of pounds per minute. This lack of change proves that this significant issue is not being addressed. However, it’s not just lack of skills and experience that pose a threat to a data centre facility, even those who may look like the perfect employee on paper can pose a risk. It’s how competent and confident people are at applying their knowledge on an on-going basis within mission critical environments that is the key to risk mitigation.
It’s a common situation that many data centre professionals have naturally evolved into their roles as technology has evolved around them. Meaning that they most likely learnt on the job and naturally adopt the approach of ‘well, it’s worked for years so why change things’.
Data suggests that continuing to do the things the same way time and time again is risky, particularly within mission critical environments. Liken it to passing your driving test, when you first pass you are tuned into the rules of the road and consciously aware of what is going on around you and know the potential dangers. Yet, after a number of years of driving, who refreshes themselves by re-reading the highway code? Who goes out of their way to understand the latest technics that are being taught to the new drivers? Most people are guilty of not refreshing their knowledge in this area. This scenario in a data centre could have dramatic and potentially costly consequences.
Research shows that 29%* of data centre technicians pose a risk to the organisation, they have misunderstanding and misplaced confidence, and 50% have knowledge gaps in some areas where they demonstrate a lack of understanding within subjects.
Unconscious incompetent. This is the most dangerous, or risky. Usually it is new staff who are unaware of what they don’t know. However, as an organisation you know who they are and where they are, so it can be managed.
Conscious incompetence. Individuals are aware that they have a lack of understanding. This is less risky, as these people will not carry out a task as they realise they do not know how to do it.
Conscious competence. These are good people. They are capable and know that they are capable, an example being those that have recently passed their driving test.
Unconscious competent. Individuals that do stuff intuitively, they have been doing it for a long time and do it every day so don’t even think about it.
This hierarchy follows a cyclical process. It is a fact that when people perform the same role for a period of time, initially they are highly confident and highly competent (the conscious competent) but over time they sway into the intuitive (unconscious competent) zone. Usually these are people that have been in the role or function for a very long time, they have surpassed the conscious competence stage and because they are doing things intuitively they present a risk.
Today there are new tools that measure individuals’ competence and confidence levels and on a very detailed scale. This allows gaps to be identified and intervention tools put in place to rectify the problems, plug the gaps and significantly reduce the risk.
Effective Intervention Tools
OK, so some may think this is the new phrase for education, and maybe it is in a distant way, however the most important concept to grasp is that education can come in many different guises and do not necessarily have to affect the bottom line. Here are some examples:
Internal Tools
External Tools
However, investment in education needs to be put into perspective. Millions of pounds are spent on data centre equipment and on some that may never be used – yet the people who work in a data centre every day are not considered in the same way. It’s important that organisations understand that investment in professional development is hugely positive and beneficial to the organisation and does actually provide an ROI. A competent and confident team reduces business risk, increases productivity (employee contribution), helps with staff retention and loyalty as staff know they are doing things right and therefore gain more satisfaction from their job, adds brand value (against the brand damage that occurs when there is an outage) and, with a reputation for ongoing staff development, it can actually attract new talent directly to your organisation, after all it’s a big pond out there and if your organisation can shine above the rest, you have greater chance of catching the good ones.
Just think about the cost of just one minute of data centre outage and how this could significantly reduce the risks within your mission critical facility.
Footnotes:
*Sources: Data Centre Technician Competent & Confidence Evaluation May 2016-March 2017. Cognisco
Author:
Sarah Parks – Director of Marketing, CNet Training
Sarah Parks is the director of marketing and communications at CNet Training. Sarah is a seasoned marketing professional with a real passion for marketing and 20 plus years' experience within the technology, FMCG, retail and other sectors.
A study by Geist

The technology sector is one of the most demanding but rewarding sectors to work in – from the latest innovations to the generous salaries on offer in this industry, there are plenty of opportunities to expand the IT skillset; which in turn, leads to promising promotions and pay rises. Yet with a plethora of different disciplines to choose from, how do you determine which role best suits your experience and interests?
With numerous academic institutions offering specialised degrees as well as businesses featuring internships, there are plenty of prospective career paths to take. From taking into account which route to follow (starting out as an intern then undertaking cross-departmental duties) to recognising the relevant qualifications for your chosen job, you’re not limited in your options – with plenty of support and resources available to help you find the right position that complements your background.
• Cloud computing
• Big data analytics
• Mobility
• Social Business
Additionally, by anticipating any trends, this gives you leverage – as you can build up your knowledge and therefore, place you ahead of your competition. With more and more people vying for coveted roles within the technology industry, this has meant many employers have had to make the hiring process much harder – from assigning complex assessments to conducting interviews over several stages.
As a result, prospective employees have had to widen their expertise – not only having an excellent academic and vocational record, but possessing unique qualities in order to differentiate them from other candidates. While anyone can learn from educational materials and historic events, going that extra mile to do your research and predict industry trends will place you in good stead – as not only can your specialised knowledge benefit the company when developing future products, but also shows your most important asset: that you see a future with the company, and how you intend to carve your career within the data centre industry.
You may be required to demonstrate both quantitative and qualitative qualities – so it’s important to have a broad spectrum of understanding data as well as being able to carry out extensive research. For example, a data centre technician’s job often encompasses a number of different responsibilities, providing vital support to a team. Certain tasks include troubleshooting any failures, ensuring equipment is configured correctly as well as maintaining best practice guidelines (which at times may require customer communications). However, due to the non-stop nature of the data centre, it’s not unheard of to do shift work – so ensure your schedule is flexible, as you may need to work nights. Additionally, emergencies can take place any time (such as data recovery) – so be prepared to be called out at unsociable hours!
Above all, you should possess excellent communication skills – as communicating any type of issue is imperative to ensure the smooth running of a data centre. Supporting various team members as well as being in direct contact with your supervisors contributes to an excellent support network, and given the various elements involved in a data centre environment, makes it crucial that you can step in and help out with a duty normally maintained by another member of the team.
Here are the most popular data centre certifications undertaken by those starting out:
• Certified Data Centre Management Professional (CDCMP). The training covers key matters such as data centre management as well as basic design issues) while the professional unit advises on management topics (facilities, procedures) and business strategies. Provided through global training firm, CNet Training, other certifications available include Certified Data Centre Design Professional (CDCDP) and Certified Data Centre Energy Professional (CDCEP) plus many more.
• Cisco Certified Network Professional (CCNP) Data Centre. Considered by many in the data centre industry to be the gold standard, acquiring a Cisco Certified Network Professional (CCNP) Data Centre credential is one of the most highly-coveted certifications going. As one of the most respected credentials across the board, this is aimed specifically at technology architects and solutions – developed for candidates with three to five years’ experience with Cisco technologies.
• VMware Certified Professional 5 – Data Centre Virtualization (VCP5-DCV). Highly recognized for both its traditional data centre networking and cloud management aspects, candidates studying for this certification must fully understand Domain Name System (DNS), as well as have the know-how to install, manage and scale VMware vSphere environments (it’s recommended to have at least six months’ experience with VMware infrastructure technologies prior to taking the VCP5-DCV assessment).
While there are numerous other certifications to take – such as the BICSI Data Centre Design Consultant (DCDC) – the three mentioned are the best-known, renowned for their world-class reputation. However, this is only a starting point; and is completely dependent on your experience and which specialist area you choose to work in.
Below is a selection of job roles in the data centre industry that you can progress into:
• Data Centre Test Engineer. Tasked with setting up environments in order to test PC and network solutions within the data centre, while also exposing any issues and identifying major contributing factors.
• Data Centre Environmental and Safety Technician. Offering support and monitoring the various environmental, health and safety activities within the data centres, it’s your responsibility to investigate any safety issues while conducting environmental training.
• Infrastructure Architects. Responsible for the design of the data centre, infrastructure architects typically take care of any supporting services such as cooling and power – while project managers ensure any major installations are well maintained.
• Data Centre Manager. Overseeing the general running of the facilities, it’s imperative that data centre managers have a wide range of knowledge of all things data centre-related – from understanding about network and operating systems to knowing the correct protocols and processes.
• Electrical Engineer, Data Centre R&D. Working in a team that helps design and build the software, hardware and networking technologies, your role as a hardware engineer sees you develop small scale projects right through to high volume manufacturing.
• Data Centre Maintenance Planner/Scheduler. As a data centre maintenance planner/scheduler, this involves communicating both internally as well as maintaining regular contact with clients. Planning requirements for customers and managing entire project lifecycles, you ensure efficient execution of the various planning and scheduling processes – additionally, providing equipment-related knowledge and technical expertise on improving preventive maintenance tasks.
• Data Centre Control Systems Staff Engineer. This role usually entails at least 10 years’ experience as well as a relevant degree, with experience in critical infrastructure such as industrial automation, SCADA systems and PLCs. Providing technical support to the engineering and operations teams, your responsibilities encompass resolving any critical electrical controls related matters along with handling any procurement and vendor management issues.
Whether you choose to be a DCIM Specialist due to your interests lying in infrastructure, or prefer to be an in-house dedicated programmer, there is a number of academic and vocational qualifications to help you achieve your desired career goal. Typically, staff are separated into two categories – one team consists of implementation managers (meeting new customer requirements) with the backing of engineers (who look after installation and cabling). The operational team are tasked with equipment configuration and maintaining it once installed, consisting of senior employees specialising in areas such as storage and backup, database management, as well as customer service representatives.
A day in the life of a data centre employee is never routine, and at times, can be stressful – yet the breadth of skills learnt can be acquired extremely quickly. This allows you to attain a senior level relatively swiftly whilst developing a good understanding of specialist areas; and as no two customers are ever the same, only serves as the perfect breeding ground for data centre employees looking to expand both professionally as well as personally. As a sector that continues to grow in popularity and size each day, it’s a sector that boasts one of the lowest unemployment rates – so if you’re looking for a secure and highly gratifying job, then working in the data centre industry is the ideal career for you.
By Dr. Rabih Bashroush, University of East London
Many people confuse these terms or understandably assume they mean the same thing, but while the data centre sector and the DCA moves to address its needs, it’s critical to understand that there are very clear differences. The terms of training, education and awareness are often mixed, and the terms used interchangeably. Although choosing the right training or education program doesn’t need to be a laborious process; there is a need to clearly understand the very fundamental differences between them and the benefits associated with each.

Training provides candidates with skills and knowledge that are associated with state-of-the-art technologies and best practices. Training usually focuses on the ‘how’, and is often acknowledged through certification. Professional certification proves that an individual has completed the learning process and achieved the stated objectives. It can provide post nominal letters to use after the delegates name. Certification is unique; it shows a commitment to life-long learning, as re-certification is often required every few years due to ever evolving technologies and best practices.
Benefits for the employer
Benefits for the employee
Education, on the other hand, provides candidates with insights and understanding of theoretical underpinnings behind most technologies. Education focuses on the ‘why’, and is often acknowledged through qualifications that are valid for life. They also differ from certifications in that they are tightly controlled by professional bodies and only accredited providers can award qualifications. They are mapped to the International Qualification Framework and therefore recognisable across the world.
Benefits for the employer
Benefits for the employee
Finally, awareness provides target audiences with information about a topic to help them recognise its importance (e.g. Energy Efficiency, health and safety, etc.). Awareness is usually about the ‘why’ and largely delivered through videos, newsletters, posters, seminars and other types of campaigns (e.g. printouts on shirts, mugs, etc.).
Together, training, education and awareness programmes can provide a very strong framework to up-skill and retain your work force, increase your organisation’s capabilities, and drive professionalism.

Dr Theresa Simpkin, Senior Lecturer, Leadership and Corporate Education, Lord Ashcroft International Business School, Anglia Ruskin University
It’s no secret that the Data Centre continues to suffer from a deeply entrenched skills and capability crisis. Traditional talent pipelines are more reminiscent of leaky funnels as a reduced graduate population filter off into other, better known, industries.

Lack of gender balance is contributing to a diminished pool of qualified recruits and other non-traditional sources of talent (people from low socio-economic backgrounds for example) remain largely untapped.
The capability landscape, despite an emerging groundswell of activity, will remain somewhat barren without looking to emerging opportunities to fill vacancies now and to develop a pool of potential talent for the future.
One of the most opportune mechanisms available for the domestic Data Centre is the role of apprenticeships. Used elsewhere in the world to develop vocationally focused individuals with robust academic qualifications, apprenticeships offer an alternative to waiting for the current crop of university graduates to pop out of universities and filter into various industries; all of which are clamouring for the best and brightest of a relatively small supply. There’s simply not enough of them to go ‘round.
At the recent Datacloud Europe event in Monte Carlo, Christian Belady of Microsoft and Infrastructure Masons recently suggested “Availability of competency is being outgrown. There is a shortage of nonlinear thinkers.”
On the other hand apprenticeships, particularly degree level apprenticeships, are a common sense alternative to the reliance on the traditional labour pool. Unlike the image of the 16 year old male mechanic or painter in overalls and steel capped boots, the new apprenticeship offers the opportunity to skill, upskill or reskill new and existing employees of almost any age in technical and academic based programmes.
It makes good economic sense too. As from April this year, employers with an annual payroll of £3 million or more will need to make a contribution to the apprenticeship levy aimed at funding a target of three million apprentices. This is an initiative that recognises that industry needs to develop practical skills and capabilities quickly. As a blend of on and off the job training, apprenticeships can create job ready individuals much more quickly than traditional forms of higher education.
Degree apprenticeships (those that offer a bona fide undergraduate or post graduate university degree) in particular will, over time, provide a framework for employers to develop internal capability with a capacity to better fit the needs of the industry. As much of the training is on the job the development of competencies happens in real time, paying dividends almost immediately. For the Data Centre sector this is imperative. Simply keeping up with organisational change and technical advances requires a more nimble and responsive approach. A well-designed apprenticeship curriculum and skill development programme can deliver this.
Smart organisations will see this not as a tax but as a means to leverage the levy for business and industry capability development. Even smarter organisations will recognise how such an initiative could replace traditional graduate programmes and create an almost bespoke learning and development agenda that delivers benefits to a range of stakeholders;
It would be a travesty if the levy is seen as a tax instead of a golden opportunity to reinvigorate the capability development agenda across the sector. Whilst it will take some effort to maximise benefits, the potential return on investment is profound.
Get wise. Find out how the levy works and think creatively about how it could deliver benefits to a more responsive learning and development initiative.
Get involved. Trailblazer initiatives give industry the power to determine what’s needed by way of curriculum and end capabilities. Having a say creates a more bespoke approach for greater levels of apprentice employability and lays the foundation for a return on investment for the sector as a whole. End point assessments associated with apprenticeships, too, offer industry a means of ensuring what’s taught and assessed is consistent with the needs of the sector.
Join the dots. The current dearth of talent making its way into the sector is indicative of a complex and long standing suite of factors. The apprenticeship agenda can chip away at the talent shortage, gender imbalance and demographic shifts if approached in a holistic and sensible sector-led manner.
Overall, while there are different apprenticeship initiatives in different countries, the new English model offers an alternative way of looking at how the sector can address long standing and potentially disastrous capability shortages.
Find out more at https://www.gov.uk/government/publications/apprenticeship-levy/apprenticeship-levy
There is an overarching fear that Artificial Intelligence (AI) and Machine Learning are going to take over people’s jobs, but there is a counter argument that their main purpose is to support humans as enabling technologies.
By David Trossell, CEO and CTO of Bridgeworks.

In their proponents’ viewpoint, they aren’t disabling anyone. However, organisations that don’t train up their staff now to learn new skills may find themselves left behind. This includes IT, which is of increasingly strategic importance to most organisations today. Both technologies are becoming a fundamental part of our lives, and with the advent of semi-autonomous and autonomous vehicles they will become more so – both in consumer and enterprise applications.
SD-WANs are very good at the branch office level, but as technology moves forward data volumes are going increase and the time to intelligence will need to shrink. Whilst SD-WANs are great for low bandwidth applications, with high bandwidth applications a different approach is needed to move ever larger amounts of data.
Humans make mistakes – that’s part of our nature, and by using AI and machine learning the risks associated with human intervention can be removed, which could include unexpected network downtime due to the poor manual configuring of a wide-area network (WAN). Thankfully, the concepts of AI and machine learning in IT networking are not science fiction. Rather than making us weaker, they can make us stronger and enable us to increase our performance. They are no Armageddon; they are an enabler that can permit organisations to do more with fewer resources.
The science fiction of autonomous networking, which is spoken about by David Hughes, Founder and CEO of Silver Peak Systems, in his sponsored article for Network World, is already here today in solutions such as PORTrockIT and WANrockIT. They can correctly mitigate the effects of latency without your organisation having to unnecessarily spend money on ever increasingly large bandwidths, WAN Optimisation, SD-WAN and WAN optimisation solutions. With AI and machine learning much can be achieved with what you’ve already got, and an ever larger pipe won’t defeat the laws of physics no matter how much you spend. The problems created by latency will still remain.
Hughes says that many enterprises are using SD-WAN solutions to connect employees consistently and securely to cloud and datacentre applications, but by themselves they do not provide any form of optimisation to enhance the flow of data. You have to add WAN optimisation, which many of the SD-WAN providers do. However, with security concerns requiring encrypted data and rich media being an increasing part of the data mix, they provide little or no performance improvement. He’s nevertheless right to explain that automation is playing a role in SD-WANs to eliminate many of the repetitive and mundane manual steps, which are required to configure and connect remote offices.
He believes it has limitations though: “Automation has its limitations…[it] is not sufficient to translate high-level business goals or intent into specific actions across the network, and automation is not good at dealing with the many unanticipated situations across production WAN deployments.” In his view these are areas where machine learning and artificial intelligence can play a role. With machine learning, WANs can be directed to adapt to changing environments without human intervention.

AI and machine learning techniques permit us to better manage and to cope with the ever-growing data volumes too. Clint Boulton, Senior Writer at CIO magazine, talks about freight forwarding company JAS Global in his 12th May 2017 article, ‘How logistics firm leverages SD-WAN for competitive advantage’, and refers to it taking a gamble on an unknown technology.
The firm is using an SD-WAN to run cloud applications, but hopes to use it as the backbone of a predictive analytics strategy to grow its business. The claim is that JAS Global managed to cut millions of dollars from its bandwidth costs. That’s good.
Boulton also explains: “SD-WANs allow companies to set up and manage networking functionality, including VPNs, WAN optimisation, VoIP and firewalls, using software to program traffic routing typically conducted by routers and switches. Just as virtualisation software disrupted the server market, SD-WANs are shaking up the networking equipment market.”
He will, as many before him have found out once you start down the big data path, find that the volumes of data start to increase exponentially. The need to gather data from further afield at an increasing rate SD-WANs limitations start to bite. There will also be a a need to invest in larger bandwidth capabilities and data acceleration techniques. What’s certain is that data acceleration makes big data and predictive analytics increasingly viable. Machine learning can be used to help us humans to understand what story the data is telling us. Latency on the other hand can lead to inaccurate data analysis.
To me this just sounds like hype – particularly as WAN optimisation won’t necessarily increases WAN performance like it should do. On the other hand, data acceleration solutions can create performance increases. Your datacentres and disaster recovery sites don’t need to be situated within the same circles of disruption. Boosted by machine learning they can be placed thousands of miles apart, and as the transmitted data is encrypted it is very secure. The analysis of the network’s performance happens in real-time too, eliminating the risks of being reactive as opposed to being proactive.
Managing network performance, protecting your data, mitigating latency and reducing packet loss needn’t be the gamble that Boulton writes about. Mark Baker, CIO of JAS Global, felt he had to embrace SD-WANs because his company was already supporting global applications and email with MPLS networks and VPNs. The costs of running an enterprise resource planning (ERP) system over them worried him though. The ERP software required a sub-150 millisecond of latency. “Setting up and provisioning an MPLS system also takes several months”, says Boulton. Baker was therefore drawn to SD-WANs from Aryaka.
This is fine, but organisations should also look beyond SD-WAN to a data acceleration solution as it can do more for less. Many of Baker’s goals would probably have been achieved more quickly and more simply with one of them to address the latency challenge of having a global company “go from Atlanta to L.A. to London and Paris”. He adds: “But when you start talking about going across the pond or [to the northern and [southern] hemispheres there is a huge latency challenge to overcome when you’re lacking a traditional MPLS network”. With AI and machine learning, such a challenge is minimised - and that’s simply because machines can support humans effectively and sometimes outperform them. With machine learning behind data acceleration, you’ll always be a step ahead too.
Cloud computing is levelling the playing field for large and small businesses.
Netmetix’s Managing Director, Paul Blore outlines why.

Phil Simon’s 2010 book, The New Small, foretold the story of how an emerging breed of small businesses were poised to take on the big boys by harnessing the power of disruptive technology. Its central proposition has proved highly prophetic. Seven years later and we’ve all seen the PowerPoint; the world’s biggest cab company owns no taxis, the largest phone companies have no telecoms infrastructure and the biggest movie house on the planet doesn’t own a single cinema. You get the picture. Ambitious start-ups have, with the help of now-familiar technology, unseated the giants and established a new normal. David has slain Goliath, with the cloud rather than the catapult providing the metaphorical knock-out blow.
But you don’t have to aspire to be the next Netflix to exploit the value of technology. It’s there for all of us – and it’s changing the game. Traditionally, evaluating the technology infrastructures of large and small businesses was generally akin to comparing apple with pear. Now, thanks to cloud computing, every SME can compare with Apple. Independent research has found that almost half of SMEs believe technology ‘levels the playing field’ between small businesses and large corporations. Furthermore, the study suggests that the agility that comes with being smaller often gives SMEs the edge, enabling them to take advantage of digital innovation more quickly. The dynamic of modern business is changing. Small is becoming the new big – and cloud computing is helping to put it there.
However, despite the undoubted benefits, some SMEs are yet to move to the cloud. Many persist with legacy systems, or rely on server upgrades to solve their needs. Too often, technology is viewed as a tactical consideration rather than a strategic enabler. It’s a missed opportunity that’s holding companies back. Cloud computing is the transformative technology of our time. Fundamentally, it gives even the smallest businesses access to enterprise-grade IT infrastructure – the very same infrastructure, in fact, that the world’s biggest conglomerates are themselves deploying. It’s this transition that levels the playing field, giving SMEs a platform to future proof their businesses and flexibly align for growth.

The benefits of cloud computing are many but the most resonant boil down to advantages in four key components of the drive for digital transformation; flexibility, resilience, security and the development of the digital workplace. Primarily, the cloud gives small businesses the ability to scale their IT platforms based on the needs of their business today, rather than having to invest in infrastructure based on estimates of where it might be tomorrow. Instead of forking out significant up-front capital investment for functionality they may not need, the cloud allows companies to pay for services as and when they need them. IT becomes a utility – you simply turn the tap on when you need a little more, and turn it off when you don’t. This gives SMEs flexible access to transformative technologies such as Internet of Things, machine learning and artificial intelligence, as well as powerful tools and software that may have previously been out of reach. The ‘utility’ approach breeds an operational agility that helps small companies evolve infrastructure in line with business needs.
Another major consideration in the digital transformation journey is the need to maintain business continuity. Resilience is imperative. Typically, smaller businesses have relied on RAID storage, using multiple drives to protect their data in the event of hardware failure. The best cloud systems are more robust; data is stored not on drives but in industrial-strength data centres. In the rare event that an entire centre fails, businesses continue to function via remote data centres. This provides a level of resilience that’s unparalleled in most large organisations, let alone SMEs.
Perhaps the first question that’s asked about cloud computing is around security: how safe is my data? It’s a perceived barrier that often prevents businesses from considering it. But security is not a barrier to the cloud – it’s a reason to move there. Without doubt, a cloud deployment is more secure than any on-premise system – both physically and digitally.
Physically, most on-premise systems are ‘secured’ behind a locked door or in an alarm-protected room. Data centre environments are typically protected by CCTV, perimeter fencing and biometric access controls. Similarly, digital security for on-premise systems is often just a firewall. The major cloud providers invest hundreds of millions in data security each year – and their users reap the benefits simply by using their platforms. This means that small businesses can enjoy the same resilience as global giants like BP. Moreover, with a cloud deployment, organisations always benefits from the latest operating system, security updates and patches – further minimising risks. In an era where ransomware and data protection breaches present significant threats, companies need to do all they can to reduce vulnerability. The cloud, underpinned by good governance and good practice from a trusted IT partner, helps take care of it.
Across all industries, there’s much focus on the need to create a digital workplace that meets the needs of the modern workforce – providing mobility and connectivity and supporting collaboration. Cloud computing not only enables this, it can also unlock efficiency gains and help SMEs align for growth. For example, start-ups can facilitate remote working or open regional offices without the need for expensive infrastructure; with the cloud, everyone works off the same system and has access to the same tools and data. The benefits can be practical too. For instance, in companies that have migrated to the cloud, the removal of unnecessary hardware can free up office space and reduce the costs of outsourcing IT.
There’s little doubt that a move to the cloud can transform SMEs. It’s no surprise that many are making the journey. But it’s important to exercise caution: not all clouds are equal. Some ‘cloud providers’ offer little more than storage space on locally hosted servers. This provides no resilience and few of the scalable benefits associated with fully-managed services. It’s therefore essential you ask the right questions. Where will your data be hosted? Is it a credible data centre? What’s the physical and digital security of that facility? Where will data be replicated to if there’s an incident at the primary site? Can you actually operate from that back-up site, or will you need to restore your systems elsewhere to get up and running again? These are just the base considerations. The most effective partners will understand your business requirements and work with you to develop the best strategy.
In the era of digital transformation, having a flexible, robust and secure IT system is a clear business advantage. If you haven’t got the right infrastructure, whether that’s on-premise or cloud, you won’t be able to run your business effectively in the modern world. In truth, that world is marching relentlessly down a one-way street towards the cloud. Those that wait will get left behind.
The journey doesn’t need to be difficult. With the right IT partner, ideally a specialist in cloud deployment, it’s possible to manage a seamless transition that will have a transformative effect on your business. What’s more, it will give you all the benefits the big boys get, whilst retaining all the advantages of being small and nimble.
Cloud computing has levelled the playing field. It’s time to think big.
Jon Healy, Associate Director at Keysource discusses their market observations, new services and success of the business over the last year.

1. For those that don’t know please can you describe Keysource and your role in summary?
Keysource is an international provider of solutions for business critical environments, including data centres. We have 35 years’ experience partnering with our customers to provide solutions and services that enable their technology requirements.
Our work spans the full lifecycle of the critical environment providing an ability to leverage a wide range of capability within the business.
As an Associate Director, and a member of the senior management team, my team and I are responsible for existing and new customer engagements, understanding the best way we can help customers and how our capabilities are best utilised.
Our passion is in understanding our customers’ businesses and how they use technology in order to deliver their objectives and drive benefits, often taking some innovative thinking to get there.
2. 35 years? Congratulations! Let’s not go back that far but what have Keysource been up to recently?
As technology changes so do the demands of the market and our customers’ requirements. We’ve continued to adopt a fresh strategy year-on-year to be able to continue meeting this.
The most significant change to the business in the last 18 months has been the development of our consultancy and professional services offering.
This approach allows us to work with our customers to better understand their data centre needs, including how they use and deliver these services, whether this be internally, externally or both.
In our view, having an understanding of how data centres fit within wider business objectives is now vital. And as customers’ adoption of virtualisation, cloud and other platforms continues, our role is becoming increasingly critical.
We’re very much of the view that given the normally significant investment and the long term nature of these solutions, they need to meet the customer’s needs both now and in the future. Working back from the application layer and infrastructure selection, where possible, enables a more informed and strategic process when it comes to both specifying the build of a data centre and assessing its future operation requirements.
Building on our critical facilities management offering, our additional service lines that support IT and network services have organically grown through long-term customer partnerships. We’ve seen these provide benefits akin to a managed service while also giving customers operational benefits including better efficiency and higher availability.
We also joined the Styles&Wood Group towards the end of last year. This has allowed us to offer a much wider range of property services to our customers while also providing critical environment expertise to new and existing customers from across the Group.
3. And who have been the key personnel involved in this transformation?
As Keysource continues to grow we’ve made a number of strategic appointments to retain our position in the market and build on continued success.
The has included the expansion of our leadership team through the appointment of our new managing director, Stephen Whatling, last year and a new operational management team, that brings together key individuals responsible for the performance of the business.
The people at Keysource are our number one asset. We’re proud of the highly-skilled teams we’ve developed that have become a real driver in delivering high quality customer service.
This commitment to our people and innovative approach to delivering solutions for customers was recognised by our recent DCS Award for our contribution to our industry.
4. You’ve touched on the new consultancy led approach and Keysource have a well-known D&B service so, in a nutshell, what is Keysource’s offering?
We have structured our business to support our customers throughout the critical environment lifecycle.
Our consultants and professional services teams support strategy development, auditing, discovery exercises, and assessment of operational environments. We also advise clients during design-stages with a range of pre-construction services including business cases, permission and approvals, design development and tender creation.
Keysource’s project teams deliver critical projects from small works to major data centre builds with a range of flexible services. These include project management, turnkey construction, operational upgrades, and transformation as well as a full range of end-of-life services.
To complement this Keysource provide a full range of critical environment operational services through our facilities management specialism. From security, maintenance planning and management, to reactive on-site support, monitoring and optimisation. These are often tailored services to meet specific needs of the customer or operation.
5. Do you have an example of where these new front end services have provided real benefits for your customers?
For a recent contract, we were appointed right at the beginning of a client project. This meant we were involved in, and had an appreciation of, the broader business objectives and establishing the strategic need for the data centre.
Often these business objectives have a cost, time and risk implication. By discussing these openly with the customer and working with their in-house team to develop the brief and key deliverables, we were able to advise on a range of potential models with the client and ultimately arrive at the best approach to meet their needs.
Our consultants provide a wide range of services from market advice, strategy development, assessment services, transformation planning and design development.
The great thing about having a platform which brings together Keysources’ specialist consultants with client IT and facility teams is that decisions are so much more informed. As a result, the collective output quality is extremely high and clients can typically achieve better delivery while minimising cost and risk.
6. It sounds like it’s been an exciting 18 months! How about this year? What have been the major milestones and/or contract wins so far?
So far in 2017 we’ve built on our already strong portfolio of customers within the higher education sector and secured new contracts with institutions including the University of Southampton, University of Exeter and University of Bristol. These have seen us deliver a range of projects across our strategic consultancy, design development and operational service lines.
We’ve also secured a flagship project to construct two major data centre hubs for specialist insurance broker firm Willis Towers Watson.
Our aims to grow our services overseas have also continued through an appointment to provide the design and construction management services for a leading Nordic data centre provider – supporting retail and wholesale IT colocation. In addition, we are also delivering professional services in the US and China to support new data centre development and construction projects for our global customers.
7. You mentioned you launched a managed service offering, I know that this is something that you are delivering for the Met Police but am I right to understand that this is also within a SIAMs/multi-supplier environment?
Yes, that is correct. Following a strategic decision to establish new services, Keysource successfully secured a long term contract with the Metropolitan Police Service as part of the organisation’s IT transformation programme.
The Met operates a Service Integration and Management (SIAM) model for its IT infrastructure suppliers. The Keysource service therefore had to be designed to work as part of a SIAM environment and the team worked with supplier relationship boards and within collaboration workshops on a regular basis to help de-risk the more stringent demands of this model.
Following the success of the contract, including an award won for Public Services Digital Delivery in EMEA, Keysource has continued to grow this service area. This has led to us becoming more and more involved in our customers critical environment operations. It also provides more opportunity to influence decisions on customers’ ongoing data centre strategy.
8. Keysource is now part of the Styles&Wood Group. Can you tell us a little bit about them?
Styles&Wood are a national integrated property services provider. They provide a full range of specialist services to the built environment. Over the past 35 years, they have delivered projects for some of the UK’s premier brands and leading blue chip organisations.
Some of the projects include commercial office fit-outs and refurbishment, multi-location retail frameworks, intelligent estate management services using data management tools, and large-scale redevelopment projects in the education, healthcare and banking sectors.
Considering the broader work is typically undertaken by separate contractors, the Group structure means that it can offer service lines complimenting a project to clients as a single specialist.
9. And how do you see Keysource developing under the Styles&Wood umbrella?
As part of the Styles&Wood Group we have an excellent platform to continue to build on our success and grow the business.
We have already seen a number of opportunities to deliver complementary services that take in elements of the Group’s different business units and Keysource’s specialisms in delivering critical environments. Styles&Wood, like Keysource, is an expert in working in built environments and there are a wealth of opportunities for different skills to be shared between teams and delivered on client projects.
We also see real benefits for our teams, as we now have even greater access to initiatives to support our people, including training programmes and flexible benefits packages. This is allowing us to continue to attract and retain the best talent within the sector, which has become even more critical to our long-term strategy given the ongoing skills shortage in the industry.
10. You spoke at the beginning about the rapid changes in technology changing our approach to data centres. More generally, how do you see the approach to data centre design/build/operations developing over the coming years?
Development in the sector is as interesting as ever and there are a few different themes that will influence a change in how data centres are approached in the coming years.
Firstly, the ever growing cloud offering, facilitated by hyperscale data centre players, are evolving to better tailor their services and the way they are delivered, with need for data centre availability not necessarily always being a priority. Instead we expect to see more customers focus on flexibility to better accommodate an ever evolving IT-infrastructure layer and the ability to drive commercial efficiencies while maintaining service levels.
Questions around how the sector can provide the infrastructure for the Internet of Things (IoT), and the emergence of industries such as smart buildings, self-driving transport and consumer automation are also going to play a huge role in driving change. We expect growth in ‘Edge’ data centres and therefore identifying a need for regional presence will become prominent over the next 12 – 18 months. Professional data centre operators are already considering their strategies with this in mind and we expect this to continue.
Meanwhile legislation and regulations will continue to influence the market and the likes of the General Data Protection regulation (GDPR), information security and Brexit will continue to be factors in the decision making process.
There is also an ongoing focus on resilience at the application layer, and the way this is enabled can now take many different forms. As a result, the hybrid-approach that many have already adopted is set to continue as businesses look to respond to challenges in both the data centre market and their own industries.
One thing is for sure with no silver bullet in sight for customers. Navigating the endless options and aligning these with wider business strategies will be crucial in the success of any project requiring data centre services.
11. And how do you see Keysource developing to help address these trends?
Keysource is always looking ahead to understand how we can better support our customers with foreseen trends and the challenges that emerge alongside.
Strategy and approach are key to what physical assets and service are procured in order to deliver on customers’ requirements. And, support from trusted partners will continue to be needed.
One thing is for certain, our need to continue to innovate is key in order to provide the different ways of thinking and agility to a situation or problem.
12. Keeping it simple(!), what are some of the issues that need to be considered by organisations looking at either a data centre build or refresh project?
Something that we pride ourselves on is the ability to understand the business objectives of the customer, their market, and the role that technology and their critical environments play within this. Clients will increasingly need to involve industry partners earlier in the process to have frank conversations to meet forthcoming challenges.
For our enterprise clients we’re already doing this. It sees us proactively challenge the need for data centre builds or refreshes during the early project stages. This consultative approach typically leads to a broader discussion around varying levels of IT services and operational needs to help the business meet wider aims.
As technology changes and our customers’ services expand, the delivery model is constantly being tested. This presents a fantastic opportunity to take stock of what services are in place, how critical they are to the business and the operational models needed to support this.
For our hyperscale and professional data centre operator customers, different market drivers often lead to a different set of considerations.
A couple of interesting observations. The first is that the delivery models of these organisations are changing. As they continue to battle for market share, effective and efficient systems to support their aims are now key to wider success. This presents opportunities to leverage different models, which can potentially realise huge reward.
Secondly, finding the right skilled and experienced individuals has become more and more difficult as demand continues to boom. This creates challenges for fast-paced programmes that customers will need to work with the industry to plan in at the start of new projects.
13. And are there any obvious places to start/quick wins in this process?
For enterprise customers, a common theme often used to provoke constructive conversation is the classification given to an IT service and the definitions given to the levels of service.
Take availability, for example, where this is most common. Clients need to assess how many services a new facility will support, and then assess what options in the market are available to support different levels of IT service.
Similar to their IT architecture, where various solutions are adopted, decentralising data centres can – in many cases help drive real benefits.
However, there’s no catch-all. Often the best place to start is stepping back and asking fundamental questions – for example, why do we need to increase availability, and what systems have become less critical over the last decade.
14. Any other thoughts or comments?
It’s an exciting time for Keysource and our customers. Market trends and the critical role technology is playing in business is reinforcing the need for robust data centres strategies. Changes to critical environments and systems to enhance IT environments are driving the need for the industry to act as a partner to customers, not a supplier.

Flexibility and scalability are important concerns for any data centre, regardless of its size. Changing business requirements make it inevitable that capacity has to be added or removed at frequent intervals. The ability to do so quickly and reliably—minimising downtime and maximising efficient use of resources—is essential in today’s world. Not only must IT equipment itself be designed to ensure easy scalability up or down, according to need; so too must supporting infrastructure such as power and cooling.
By Patrick Donovan, Sr. Research Analyst Data Center Science Center IT Division, Schneider Electric.

Standardisation of components and sub assemblies helps to simplify the task of managing scalability. In the early days of data centres, lack of familiarity with quickly changing IT requirements and ad hoc additions of equipment often led to stranded capacity and inefficient use of resources. Not only was space ineffectively used but great variations in rack densities led to poor use of power and cooling infrastructure and incurred unnecessary costs.
For small and medium sized facilities, the rack or IT enclosure is typically the standard building-block implement of computing capacity, on which designers can base their calculations to estimate the requirements of a facility. Knowing the average and peak rack density, and the number of racks, not only allows for efficient facility sizing, but also determines the branch power circuit ratings and airflow needed for each rack.
The rack standard itself also creates a simple framework or unit of organisation for deploying IT and making efficient use of white space. Other advantages include containing electrical faults, which can be traced to a specific rack; simplifying moves, adds and changes through understanding of a rack’s location and which IT equipment, both physical elements and virtual machines, are contained within it; and easy identification of power and cooling resource dependencies.
For larger data centres, especially up to and including the newer hyperscale facilities, there is a need to use larger increments of computing resource to respond to changing demands in capacity. Unfortunately there is not, as yet, a similar industry standard or ‘black box’ method to scale up such large facilities with appropriate increments of computing resource in a timely manner.
This has not stopped many data centre operators from developing their own internal standards around the use of IT Pods, a larger unit of infrastructure comprising a group of IT racks in a row, or more typically a pair of rows, that share some common infrastructure elements such as a Power Distribution Unit (PDU), network router, containment system, air handlers and security.
Carefully designed IT Pods represent a useful building block, coming in size and capacity between an individual rack and an IT room, for scaling up large data centre resources efficiently. As well as the advantage of having a larger scaled building block to help with capacity management, a Pod can also serve as a logical grouping of business applications or be assigned to a specific client or line of business. It can be advantageous to deploy varying infrastructure technologies, architectures and operational procedures at Pod level, rather than individual rack level, for larger facilities.
In terms of power and cooling distribution, using Pods as a unit can make it easier to vary the support infrastructure within the same IT facility to meet specific business needs. Servers hosting highly critical applications requiring dual power feeds can be grouped together in a Pod and kept separate from less critical loads that do not need to incur the additional expense. Likewise, Pods hosting critical applications requiring higher levels of management with regard to emergency operating procedures can be kept separate from those containing less critical equipment.
The flexibility of adding a high-density Pod requiring row-based coolers or a rear-door heat exchanger that is not needed elsewhere in the room makes scaling up to new equipment easier. So too does the opportunity of deploying a Pod designed to deliver water cooling for future servers in a facility otherwise designed around an air-cooled architecture.
Furthermore, organising hardware at the Pod level makes it easier to host equipment using different architectures and technology, for example Open Compute Project (OCP) server racks and traditional servers could be hosted on different Pods but in the same IT room or data centre.
When deciding on a Pod architecture there are three principal factors to consider: choice of electrical feed; the physical space available for a Pod, ie the number of racks; and the average rack density required.
Considering the power feed first: in traditional data centres bulk power is usually brought to PDUs or Remote Power Panels (RRPs) either placed against the wall or located throughout the floor for larger rooms. As the data centre fills up with equipment, each PDU is allocated a physical area and delivers final power to individual racks through local distribution feeds. As the amount of equipment in the data centre approaches capacity and upper limits on breaker panel space or transformer loading is reached, it is not unusual to “borrow” breaker space from a PDU located far away from the newest rack additions. This makes operations complicated and increases both maintenance requirements and the risk of downtime.
Pods have dedicated electrical feeds. For the purpose of simplicity two basic categories of Pods, low power and high power can be specified with the former delivering an available power of 150kW through breakers rated at 250A and the latter delivering 250kW through breakers rated at 400A. Narrowing choices in this way can simplify and clarify what would otherwise be a very complex menu of design alternatives. Standardising on a small number of options accelerates design and deployment while reducing error.
A Pod’s footprint is its total width by its length. The length can theoretically be as short as one rack and as long as the length of the entire room but there are of course other limitations. Too long, and rows can violate local exit requirements; too short, and space may not be used efficiently.
The longer the Pod size, the more racks can be placed into a given space. To make the best use of space, a Pod should be designed to be as long as is practical to fit the room. But to increase scalability options, smaller Pods should also be considered, the exact size of which will depend on the business requirements. There are also always factors specific to the building space to take into account, including room shape, building columns, cooling architecture and ducting and security requirements, among others.
Average rack density within a Pod is a simple calculation of the available kW of power divided by the number of racks. However, it is important to consider the cost tradeoffs when balancing infrastructure capacity with space. In most cases, designers and operators should under estimate expected rack density. If the installed racks operate at a higher density, you use up your more expensive resource, namely power and cooling, before the floor space. In other words, it is much costlier to deploy IT below the data centre design density than to deploy above the design density.
In conclusion, when implementing best practices for designing and specifying IT Pods it is recommended that one should:
90% of the world’s data was created in the last two years. This percentage, and indeed the rate of data creation and consumption is only set to grow. The proliferation of IoT devices, increasing cloudification, advancements in machine learning and artificial intelligence - not to mention ever-increasingly connected and locationally fragmented workforces - means the capacity and resilience of data centres has never been more important.
By Jon Leppard, Director at Future Facilities.
.jpg-fxtwsl.jpg)
In other words, the demand for data centres is not just growing, it is skyrocketing. Look at colocation provider Colt Data Centres for example. The firm recently announced an expansion of its flagship London site by 6.4MW, simply due to increasing demand, and this is illustrative of a far wider industry trend. Suddenly, the common industry consensus on a five year data centre lifecycle is beginning to seem outdated and unsustainable.
Some organisations may be able to deliver the extra capacity by managing the increase in density, but what about those facilities that are unable to cope with those power requirements? For some data centre managers, the demand for capacity forces them into a guessing game - which brings with it increased risk and potential for failure. They may not have the data required to safely operate at higher temperatures, with inadequate mapping of their cooling and no real capability to deal with potential hotspots.
The simple answer here is that data centre managers need to be able to optimise the space available to them, in order to suit particular business goals; chasing that extra MW of capacity for instance. After all, simply expanding the estate through land acquisition can be prohibitively expensive, or even impossible in crowded inner-city locations.
This is a trend that we at Future Facilities see frequently, within the UK but also across the globe. And this challenge is not a criticism of data centre managers. The reality is that there are a huge number of pressures in the management of the data centre which has often led to them becoming over-provisioned and underutilised. Erratic and difficult-to-predict external business trends mean that IT teams have often (understandably) prioritised the safe delivery of compute power, to make sure that mission critical applications and services don’t fall over.
On an operational level, an efficient data centre is one where power and cooling supplied by the facility balances the IT demand. In commercial terms, the data centre must also have the ability to maintain this balance while being completely flexible to the needs of the business, such as an increased demand for capacity. This means changing things often, and with no risk of downtime.
In the current model of the data centre optimisation, where five year infrastructure replacements are the norm, the adaptation process is no longer fast enough to keep pace with demand. This is Primarily because of a decision-making gap between IT and facilities.
The issue lies in the fact that both are currently operating independently. Many organisations have deployed DCIM technology with a goal of crossing the data and process gaps that are found within any data centre. This is a positive step, but it does not cover all bases. In fact, the majority of IT implementations today are managed whereby the operator makes decisions without any clear insight into the engineering impact they may have on the other side of the gap. In other words, IT doesn’t know how it will affect facilities, and vice versa. In a mission critical facility that is defined by the physics within it, there is an engineering gap between the two key stakeholders.
This engineering gap exacerbates the stresses faced by data centre managers, and it exists in almost any facility that isn’t being fully simulated and modelled. It is exposing organisations to significant risk: a loss of hardware availability that is detrimental to business performance; wasted CapEx when new facilities are deployed prematurely; unnecessary increases in OpEx due to losses in cooling efficiency and ultimately; and ultimately increased costs in delivering the required compute.
However, the leading organisations have overcome these issues by closing the engineering gap. While all the complex processes at play in the data centre cannot be mapped on a single sheet of paper, in the head of a single facilities manager, or even in a traditional DCIM tool, they can be predicted using an engineering simulation. Through engineering simulation it is possible to create a fully mapped 3D model of a data centre, simulate power systems, changes in temperature, changes in infrastructure layout and then run computational fluid dynamics modelling to predict how the facility needs to be cooled. Through the creation of this virtual facility, you can an accurate decision making engine that’s based on physics but aligned to business performance.
This process of engineering simulation gives data centre managers an incredible amount of foresight into how their actions will affect infrastructure. It gives them a safe, offline environment in which they can explore and test the changes required within the data centre. So when the demands of the business come flooding in, resulting in huge variation in the workloads being handled, the data centre can perform with absolute resilience. Change will no longer be the enemy — refurbishment cycles will be delayed — and there is the assurance there that every megawatt drawn into the facility is of strategic business importance.
Future-proof designs need to take a modular approach incorporating scalable physical architecture, management software and a structured fibre backbone to accommodate the bandwidth and data speed requirements of the IOT era.
By Michael Adams. VP Strategic Business, Global Accounts at Panduit Global.

In a global environment where customers are dictating the rate of transformation operators must decide on an approach that facilitates change. Select the right type of netcomms architecture and build in efficiency. In this fashion operators can continue to manage capacity for reduced OpEx, whilst retaining operational integrity.
Any data centre design requires a comprehensive and reliable infrastructure framework that bridges the gap between the traditional Facility and IT stacks to ensure a seamless physical to logical convergence. Given the enormous expense of operating data centres, organisations must design and deploy an architecture that is adaptable to meet future needs and scalable to meet changing business demands and optimise IT investments. We all must continue to deliver value throughout the data centre lifecycle. Data centre management tools, consultancy and products that accelerate the design cycle, simplify implementation and enhance operations are essential to improve total cost of ownership (TCO).
Fig 1. The Physical Infrastructure must be easily enhanced and upgraded
Interoperability and speed of deployment are part of a successful data centre deployment. When physical infrastructure components are brought together from numerous manufacturers, elements such as long lead time components and system inconsistency can quickly extend the time needed for live system functionality. Provision of a preconfigured solution mitigates this potential obstacle by assuring that elements ranging from base enclosures to intelligent monitoring systems arrive complete and are 100 percent tested prior to deployment.
Security and access control, whether at the physical or application level, is another challenge that aligns well with integrated infrastructure. By taking that same preconfigured model and utilising HID card or keypad access control as part of the solution, traditionally less secure colocation deployments are immediately protected right out of the box.
The major pain points that are often encountered are downtime and saving money via energy use reduction. Although not immediately apparent, these considerations often have a knock-on impact on costs in terms of installation and moves, adds and changes (MAC) expenditure.
The physical layer represents around 5 percent of data centre project spend and accounts for 59 percent of downtime once operational. These numbers indicate that numerous installations have been found wanting as infrastructure performance requirements have increased. If we consider that 76 percent of data centre traffic is east to west – machine to machine - then infrastructure rationalisation is imperative, whether as an upgrade path or new build site. These problems are especially prevalent in colocation facilities, where these two issues are top of mind and flow directly to the bottom line of the business.
At the same time, the increasing speed of the network has driven an increased focus on the architecture of the network. When the speed of the network increases, for example from 10G Ethernet to 50G Ethernet, the distance that can be spanned with the cabling links is reduced. Additionally, one needs to consider the number of connectors in the link and what impact this has on the data speed across the network.
High Density Fiber Solutions are allowing customers to maximise and transform their data centre space to accommodate next generation technologies and evolve within IoT (Internet of things) and beyond to IoE (Internet of Everything).
Image – High Speed Server Shipments will transform the need for Fibre Infrastructure
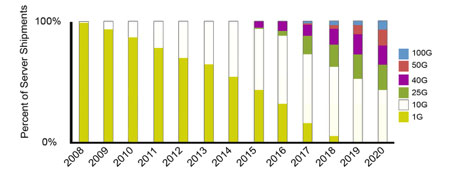
A key challenge for the date centre operator is understanding what type of fibre to install; single-mode or multimode and if multimode, which Category: OM3, OM4, SignatureCore or OM5. Selecting a fibre type depends on cost, future data rate needs, and maximum channel reach.
Single-mode fibre (SMF) will support all future data rates and channel reaches, but the performance comes at a cost premium in the order of 3 to 5 times that of multimode channels.
For the latest technologies such as, SWDM, wide band fibre such as SignatureCore or OM5 will be required to guarantee performance over the specified channel reaches with a high confidence level. The range of options appears broad, however the operator must have an infrastructure development strategy in order to optimise the investment and reduce the requirement to repeatedly install new cabling moving forward.
As a cohesive set of products cabling can help solve in tandem: network performance, system reliability, energy efficiencies, seamless integration, space and savings, installation and uptime, as well as data transfer speed and speed migration to future demands.
By far, the largest proportion of the data centre operations budgets is spent on cooling. Energy efficiency being the greatest opportunity for cost savings, increasing numbers of data centre operators are installing turn-key wireless monitoring and cooling control solutions that utilise intelligent software, leading edge wireless nodes, and professional services to gain real-time visibility into current data centre operating conditions.
Frequently operators cite many reasons for needing to control energy utilization, including being green, PUE compliance, good corporate citizenship, and operations leadership in their industry. Often the key benefit is saving money without putting the data centre at risk. That being the case, one can’t manage what one doesn’t measure. Therefore it is essential to incorporate an effective process: Assess, Instrument, Optimise, and Control. This process enables the customer to address two key pain points – energy savings and risk management.
Image – SmartZone Stack
Understanding this balance and how to maintain it provides the basis for enhanced operator return on investment (ROI). Over-provisioning (or over-sizing), has always been a belt and braces response to the need for data centre resilience. However, it permits waste into the system and results in unnecessary expenditure. Too little capacity can increase the risk of unplanned downtime and reduce the resilience, so crucial in the modern data centre. However, Data Centre Infrastructure Management (DCIM) providers have been guilty of delivering only broad and ill-defined solutions, often lacking a structured development path. This has to some extent tainted the DCIM message, which if delivered and implemented successfully can provide clear and defined benefits to the operator and customers.
Designed and configured correctly DCIM power solutions enable comprehensive energy and physical infrastructure efficiency across data centres, facilities and enterprise estates. These focus visibility of power, capacity and environmental information that is accurate and actionable for operational optimisation. The goal is to quickly provide IT and facility professionals with a transparent view of actual consumption and capacity. These diagnostics will help elevate operational efficiencies, reduce operational expenses (OpEx) and increase the resilience of facilities in support of Service Level Agreements (SLAs).
The cost of operating large data centres requires DCIM to become an integral element in the data centre operation. As part of the total solutions approach customer and suppliers work together through comprehensive DCIM consulting and implementation services. In this way they become focused on achieving manageable, measurable and cost effective DCIM strategies.
Today the data centre operations discussion is framed around increased bandwidth, reduced latency, and energy concerns including; lower power usage and reduced heat generated by the system. Clear understanding of the data centre infrastructure and how this bridge technology enhances the development and sustainability of the site will create more efficient data centres. Taking a holistic view of the entire build, its projected purpose and future needs enables operators to conceive future-proof facilities that have the capability to generate consistent return on investment.
The design and construction of a data centre is not a simple process. The wide range and number of stakeholders, and the far-reaching effects of the decisions made during the design and construction phase, provides multiple interpretations of what is the optimal solution for a particular business.
By Zac Potts, associate Director, Sudlows.

Providing an auditable chain of checks and balances for any project is important, but within data centres, when the technologies and processes are changing so rapidly, the reasons behind decisions and the information upon which these decisions were made is critical.
When a project is delivered well, the due diligence and stringent project control will often be invisible to the wider business. When a project fails however, the processes and history often come under scrutiny. In our experience of data centre construction, it is internationally understood that getting the right people involved and at the right time is fundamental to the design and coordination of the project. When you appreciate that every individual engineer has an area of expertise, the benefits to all parties of collaborating with both external and internal stakeholders becomes apparent.
The result is a well-documented and understood decision-making process and improved engineering based on multiple points of view and personal experiences.Professional synergy is working together to deliver a better outcome rather than approaching a project alone, and it is the key to every stage of a well-developed and successful data centre delivery model.
Most projects can trace their roots to an initial business case and assessment of feasibility, the importance of which lies within ensuring the right decisions have been made for the business as a whole, accounting for the various business drivers and stakeholder interests, and incorporating the reasons and contributing factors that have led to their final recommendations. A Feasibility Study needs to be developed by someone unbiased, but also requires thorough discussion and collaboration with the major stakeholders to ensure underlying concerns are addressed and anticipated options explored. To achieve this, it is often best developed outside of the end user organisation.
Increasingly, the scope of our Feasibility Studies include broader assessments against ethical, environmental or sustainability goals. Also, as data centres provide an extensive scope for improvements to energy consumption, this can be a strong incentive for the wider business to appreciate the benefits of an overdue upgrade.
However, energy efficiency is not the only factor: the practicality of a new facility or upgrade, the associated time and cost, and the viability of alternatives must be considered . On many of the Feasibility Studies that Sudlows have developed, simply comparing the proposed to the existing would, often, have misjudged the situation. Instead, we have always sought to consider not only existing and proposed solutions, but also a range of alternatives.
Ultimately, things change, and this is one of the most important reasons why we suggest Feasibility Studies are incorporated into the working project file and referred to as the project progresses. Today’s data centre industry is a dynamic and fast-paced environment, and maintaining access to the original Feasibility Study enables new people joining the project to understand the history of the decisions made. If there has been a change in the underlying reasoning then it can be reviewed and addressed rather than assuming that the historical basis for a decision still applies.
Considering the rapid developments within the industry, data centre Engineering requires a large investment in time and resource for a business such as Sudlows to remain at the forefront of the innovations and technology. Our collaborative approach to peer review, and working closely with consultants and engineers, helps to manage project risk, and balance the demand for innovation with the critical nature of data centre infrastructure projects.
We’re enthusiastic supporters of knowledge sharing, and operating on either side of a peer review process allows for a mutually beneficial exchange of experiences and understanding between all stakeholders.
Technology is a key area where an understanding of a system’s strengths and weaknesses is gained from no better source than experience. Similarly, our engineers repeatedly feedback that the level of appreciation of specific certification gained from involvement in a project is irreplaceable. Actually working towards Uptime Institute Design and Construction Certification, to BS EN 50600 Data Centre Class Standards, or to other similar standards, provides a level of understanding which cannot be gained by just reading the documents alone.
Peer review is often seen as an obstacle to design but, although there will often be disagreements and debates, these should not be looked upon as a burden. Conversely, when correctly implemented within a collaborative working culture, it’s a major opportunity for the engineering teams to work together and incorporate into a design the sum total of everyone’s experience - resulting in a stronger project team and better engineered results. Importantly, Peer review is not always about finding problems: it’s about offering experiences and solutions, and about listening to and learning from others.

Identifying problems and issues at design stage or earlier is ideal. Once a critical facility is constructed however, final proving and testing provides one last opportunity to find faults before going live. For most critical facilities, it’s an opportunity which will never be presented again.
Once more, incorporating the experience of others allows the outputs of the systems acceptance testing and integrated systems testing to be substantially improved.
A separate commissioning and testing team is essential to be able to offer expertise and experience in testing and proving systems independently from the design stages. However, maintaining independence does not mean working entirely alone. During the final phases of a project, understanding the design requirements of the systems, and anticipating difficult scenarios will allow the benefits of testing to be maximised, and this cannot be delivered without close co-ordination and discussion with the wider design and installation teams. Demand from both End Users and Owner Operators for truly independent testing and verification has increased in recent years, with more projects employing specialist data centre testing and verification experts to either oversee or deliver these final stages.
The scope of an independent testing specialist can range from simply assisting with the planning and management of the testing, to being a client’s representative during testing, to undertaking separate testing and delivering a turnkey testing package.
In addition to specialist knowledge, testing a data centre properly requires specialist tools. Speaking from experience, the Sudlows A:LIST system of IT load emulators was developed exclusively to meet the complex needs of simulating dual-fed IT equipment with both a reasonable temperature rise and a realistic air flow rate. Without this system, our commissioning and testing team would not be able to offer the level of flexibility, accuracy and control as they do.
The attitudes to independent testing are changing, and rather than being approached as a final exam with a hard-faced invigilator, the final testing phases are understood as an opportunity for a wide range of stakeholders to learn more about the systems involved and the design topologies implemented. Though it is not ideal to identify a shortfall in design during the testing process of the project lifecycle, it is preferable to a defect presenting itself during live operation.
Ultimately, although we test systems which we expect to pass, we test them thoroughly because there is a chance – albeit small – that they may fail. In the end, once the project has been delivered and is live and operational, this record of testing is the comfort which data centre owners and operators want to be sure that when the redundancy and resiliency of the data centre is needed, it is able to deliver.
Data centres are a unique engineering challenge, combining multiple specialist systems, a fast-paced industry, and an unforgiving need for resilience. Creating synergy from a diverse delivery team and project structure requires the sharing of experiences and knowledge, offering solutions instead of just problems, and welcoming opportunities for enhancements. Incorporating the right people at the right time in a project enhances the outcome, be that early in the feasibility stages, during peer review or during testing and commissioning. Not everyone can offer all levels of the service needed and not everyone has the in-house resource and experience to deliver it alone but working together ultimately allows everyone to achieve more.
Reducing unplanned downtime and increasing asset utilisation are the single biggest opportunities for financial improvement in production operations. It’s a $20 billion problem for the process industries. Millions are being spent on new maintenance solutions, but is that even addressing the problem? Here we assess the effectiveness of these approaches and consider an alternative strategy based around analytics and asset performance management.
By Robert Golightly, product marketing, AspenTech.

In the past 50 years, maintenance as a practice has evolved to better serve the manufacturing sector in the areas of reliability and availability. However, this is now starting to change. The current approaches, such as run-to-failure, calendar, usage-based, condition-based and reliability centered maintenance (RCM), are less than ideal.
There are two key challenges. First, despite the increasing complexity of these maintenance initiatives, the precise science of when to conduct inspections and service the machines is less than scientific. Second, the current slew of maintenance methodologies focuses on wear and tear as the root cause of failure. This literally sidesteps the fact that 80% of degradation and failure in mechanical equipment is process driven.
This view is further reinforced by Boeing, a company at the cradle of RCM and the aircraft industry. Boeing basically acknowledges that up to 85% of all equipment failures happen on a time-random basis, no matter how much you inspect and service. ARC analyst, Peter Reynolds, gives a useful indication of what works by saying: “A useful prognostics solution is implemented when there is sound knowledge of the failure mechanisms that are likely to cause the degradations leading to eventual failures in the system.”
However, the industry reality today is that in order to maximise profitability, processes tend to be operated as close to key limits as possible. This can be detrimental, as process excursions quickly place an asset in an undesirable operating point, where damage or excessive wear and tear to the asset occurs. This means maintenance decisions need to be further mitigated by better understanding the impact on asset and process. A new generation of analytical capabilities is required to provide deeper insights into the asset, process and interaction between them. While operators need predictive solutions to red flag impending trouble, the software needs to be able to guide them away from trouble with prescriptive guidance. This requires the preferred solution provider to have deep domain and process expertise with the ability to extract data from design, production and maintenance systems.
In the broader scheme of things, McKinsey & Co has observed: “…entirely new and more affordable manufacturing analytics methods and solutions – which provide easier access to data from multiple data sources, along with advanced modelling algorithms and easy-to-use visualisation approaches – could finally give manufacturers new ways to control and optimise all processes throughout their entire operations.”
ARC Research Group further crystallises this view by saying: “With a good APM strategy, operations and maintenance groups become more collaborative, exchanging information to manage critical issues and operational constraints, while improving overall operating performance. Combining the information from traditionally separate operations and maintenance solutions improves the effectiveness of both areas, and offers new opportunities for managing risk and optimising performance.”
In taking a step into the future of manufacturing, APM 2.0 incorporates the advanced analytics that predict issues and prescribe operator actions. With a holistic view of the process and asset, Aspen APM software suite combines asset analytics, reliability modelling and machine learning to analyse, understand and guide. Principles of data analytics and data science enable the reliability strategy, which includes machine learning. A dominant predictive analytics technology in information technology today, machine learning on manufacturing assets requires domain specific knowledge of chemical processes, mechanical assets and maintenance practices, for example.
For industrial prowess, machine learning needs to interpret and manage complex, problematic sensor and maintenance event data. Eventually, it can determine the operating conditions and patterns that can have a deleterious impact on the asset by capturing the patterns of process operation and merging them with failure information.
While predictive analytics can reduce downtime, disruption seldom happens in isolation. Instead, dozens of reliability, process and asset issues happen simultaneously. This presents a systemic problem for RCM, a current maintenance approach that conducts static assessments, by delaying the decision-making process.
As such, dynamic assessment is required, as new warnings need to be evaluated alongside other active conditions to prioritise and allocate resources. However, we cannot address everything at once. A system of success is mandatory to address problems and prioritise them, according to the level of risk they represent.
With Aspen APM software, each new alarm triggers a recalculation of risk profiles to guarantee that the most current financial and risk probability assessment is used.
However, to be thoroughly successful, companies need to adopt a holistic approach in implementation. First, they need to communicate their goals clearly. This helps in effective problem solving. Second, it is necessary for companies to genuinely embrace a data-driven world. Third, they need to differentiate between lagging and leading indicators, as well as how to respond accordingly. Fourth, the right mix of people, technology, strategy and solution is essential – along with the use of relevant case studies. Fifth, companies need to invest time and master the technology well. Sixth, the adopted analytics program needs to be well aligned with business goals. Seventh, companies need to deploy the appropriate software and hardware to solve problems. Eighth, companies need to execute well and with a keen sense of urgency. With operational excellence and profitability at stake, it is imperative that organizations are successful in developing the best asset performance strategy.
Indeed, failure is not an option – in creating a world that doesn’t break down!
Mark Hickman, Chief Operating Officer at WinMagic, helps you focus on the key elements of GDPR preparation.

On May 25th 2018 the EU General Data Protection Regulation (GDPR) will come into force meaning that if your company trades with EU citizens or holds data on them, then you are bound to adhere by the regulations. Compliance is not just a matter of avoiding fines; consumers care deeply about the abuse and loss of their data. The reputational damage from non-compliance can far outweigh the €20 million or 4% of global revenue fine that a company could receive from the EU.
Recent research has shown the UK companies are struggling to get ready for the new rules in key areas such as the management of personally identifiable information and data breaches. For example, only 40% of companies check on every occasion whether a customer has given permission for records to move between data processors, and only 21% claim to have processes that allow them to remove data without delay from live systems and backups as required under articles 16 and 17 of GDPR.
The survey which was conducted by Vanson Bourne across 500 IT Decision Makers for WinMagic, also found when looking specifically at data breaches that only 37% of UK companies are completely confident that they can report data breaches within 72 hours of discovery to the authorities. Companies also admitted they cannot easily identify the data obtained in a breach. As few as a quarter (27%) are completely confident that they could precisely identify the data that had been exposed in a breach.
With this in mind and only a little time left for you to prepare for GDPR, here are our tips to help ensure you consider some key areas of compliance with GDPR.
Assess what, where and how EU resident personal data is stored, processed and transferred within and outside your organisation’s structure. Check every department from marketing to HR, legal and IT. Personal data includes “any information relating to an identified or identifiable natural person”. That means names, passwords, ID numbers, location data, online identifiers or any data relating to physical, physiological, genetic, mental, economic, cultural or social identity. It is essential to examine everything as ‘personal data’ covers a very wide area of what might be stored and processed on your systems.

In the age of Big Data, it is important to adopt the “less is more” principle when it comes to personal information. The GDPR states that “Personal data shall be adequate, relevant and not excessive in relation to the purpose or purposes for which they are processed.” Adopting an ongoing data minimisation approach is not only best practice, it’s GDPR-mandated. That also includes techniques such as pseudonymisation and anonymisation, as well as implementing foundational security measures like encryption which together, can dramatically reduce risk.
The era of assumption is over when it comes to citizens’ consent for data use and disclosure. Evaluate all your current consent forms and processes to ensure that consent is both voluntary and explicit with regard to the scope and consequences of data processing. You need to obtain or empower “a statement or a clear affirmative action” and essentially ensure that consent can be withdrawn as easily as it is given – something many companies fall down on.
EU residents will have a greatly expanded set of rights, post EU GDPR. You need to honestly assess your ability to respond to requests within one month, with a maximum extension of two months. These reinforced rights include: the right to access data, to rectify or erase data, to restrict data processing, to data portability and to object to data processing. This will require a rethink across processes, staff training, technology and an intelligent approach to backup and disaster recovery, ensuring that personal data wherever it is stored can be identified and accessed relatively quickly.
72 hours is the upper time limit for notifying your Supervisory Authority of a personal data breach. If the breach presents a risk to the rights and freedoms of EU residents, you also need to notify all affected individuals. However, if your data in encrypted and rendered “unintelligible to any person who is not authorised to access it,” then your organisation is not required to inform all affected individuals. Often organisations use encryption to protect data such as credit card details, or passwords, but stop there. All organisations should take the attitude that if they hold data that is either commercially sensitive or falls under the category of personally identifiable information (as defined by EU GDPR), and they don’t want it getting into the public domain, then it should be encrypted when ‘at rest’. It is the last line of defence against a data breach.
Just being compliant isn’t enough; you need to prove it. That means establishing a clear framework for accountability and compliance. Do your core activities include large scale data processing? If so, you’ll need to have a designated Data Protection Officer on board too, both monitoring compliance and being a single point of contact for the Supervisory Authority in your country, for example the Information Commissioners Office in the UK. As part of the this process it would be prudent to periodically conduct a Data Protection Impact Assessment, determining the impact of data processing operations on data privacy.
You’re required to put in place “appropriate technical and organisational measures” to safeguard personal data and minimise data collection, processing, and storage. Whilst the wording may be intentionally imprecise, it does come with very definite risk, given the fines for non-compliance. You must place yourself in the mind of the regulator and question whether they could deem your security measures as falling short of their interpretation of “appropriate”? Do this proactively, hunting out the gaps, or weaker process areas, so that they can be improved.
You may find that you are better prepared to deal with GDPR than you think, but don’t delay the assessment of your processes and systems. Regardless of your company’s size, if you hold data on EU citizens or intend to trade with them then you will be affected. Don’t be fooled into thinking Brexit makes a difference either, you will need to be compliant and can be hit by the full force of the regulation’s fines regardless.
With digital transformation looming large on most companies’ agendas, how to transfer systems efficiently to the cloud has become a central concern.
Steve Denby, Head of Solution Sales, Node4, outlines why enlisting the help of an MCSP will usually benefit such projects.

In recent years there has been an enormous upswing in digital transformation projects. Cloud adoption tends to be playing a large part within such projects, (alongside other strands such as mobile migration, social elements and analytics). So how can businesses best-ensure their movement to the cloud, as part of such projects, is a success?
Projects to move systems to the cloud (as part of a wider digital transformation project) tend to have one major thing in common; they fail frequently. Why? Largely because they tend to be far more complicated, difficult and expensive than most companies initially realise. Such projects involve a huge number of moving parts, and require a broad skill base in order to be completed successfully. It’s therefore not uncommon to find such projects being abandoned halfway, when companies realise they don’t have the money, or access to the right kinds of staff. Engaging with an MCSP can be the best route to avoiding this common trap.
Generally-speaking most people’s reasons for moving systems to the cloud tend to be similar: Cloud offers almost limitless scalability, allowing your systems to expand and contract according to demand. Cloud systems can be highly responsive and highly automated.
That said, even if you have the technical ability to implement cloud projects successfully, you have to ensure that the business case has been sufficiently analysed. After all, there’s no guarantee that your shiny new cloud systems will automatically be more cost-efficient or effective than your old systems. Overall these projects need to be approached from the top-down with an impartial, holistic, business-oriented view. You need to involve a party that is completely platform-agnostic, and who will ask the business questions before the IT questions. After all, from a business perspective, the correct answer may be simply ‘don’t do it’. MCSPs will be used to undertaking such analysis on a daily basis for their broad range of customers.
On top of these considerations, you have the various business-risk elements to consider. What’s the risk that this project could lead you to overpay for services? Could it result in loss of business or data? Also will it risk putting you in breach of the law including emerging leglisaltion such as GDPR?
Technically-speaking, a business needs to understand the suite of applications that will be affected, how business-critical these applications are, availability requirements, traffic profiles, etc., as well as questions related to costs, time required for development. For example, if your company moved from two local application servers to twelve load balanced cloud-based servers, how would the associated applications deal with that? Would the associated applications require re-engineering for your new cloud environment? The question is always ‘what will break, and how do we fix it?’ Do you have the skills in-house to analyse and correct for that?
You’ll find that the skills base required to provide cloud migration services such as these is incredibly broad and rarely do businesses have this in-house. For example, as an MCSP and IT integrator that handles a lot of digital transformation projects; Node4 is required to employ dedicated developers, windows admins/sysadmins, database experts of various hues, experts in Micro Services, Linux, Hyperscale Services such as AWS or Azure as well as a number of other highly specialist individuals that tie all this together as a solution. These people, again, need to be platform-and technology-agnostic, and possess a real breadth of skills. Frankly it’s just not practical (or affordable) for most companies to employ this diversity of people for a single project, far less to employ the long-term, and keep them occupied and retained. As a rule, the more highly-skilled the individual, the more easily they become bored, and unless they’re kept occupied and stimulated with interesting work, they’ll quickly be lured away by the promise of higher wages and more interesting work.
A top consideration in the mind of most businesses now is ‘how will this new system affect my security exposure’. The number of threat vectors in the marketplace are expanding in number and increasing in sophistication every day, and include everything from DDoS attacks to cryptographic ransomware. Capable security expertise is becoming concomitantly hard to source.
Ultimately a business needs to manage security and remain in-line with the latest regulations, as well as providing encryption where required. Such concerns are occasionally viewed as a reason not to adopt public cloud services – but they needn’t be. An MCSP that assists with cloud-based DigiTran projects should have the requisite in-house expertise to walk you through your infosec requirements.
Overall an MCSP should already have all of the skills in-house to allow you to make a success of cloud-based digital transformation projects. They’ll be out-and-out cloud experts, and, importantly, will bring an outsider’s perspective to your business issues. If you’ve already established this then you’ll be likely to require cloud services, an MCSP should be able to offer you significant economies of scale, (both in terms of the cost of hosting systems and of managing them on an ongoing basis), and should be able to cross-sell services at a discount.
When engaging with an MCSP look for a company that not only has a solid customer base, but also a history of comparable projects. Look, too, for a company that has its hands in many different platforms and technologies, and no particular investment in or bias towards one or other. Ideally, you’d engage with a company that can make money out of straightforward consulting and integration work, without the need to necessarily host your systems. They should be proficient in BiModal concepts and the demands of Digital Transformation your own IT Department. After all, you need a partner you can trust to tell you if cloud isn’t the answer to your requirements. It frequently won’t be.
further success for Mavin
Recent £1.4m investment has allowed for significant expansion of space and facilities at Mavin's Data Centre build facility in South Wales, including the implementation of cutting edge technologies designed to make the Data Centre build process run with increased efficiency and speed.
By Russell Bartley – Director at Mavin Global.
Established in 2005, Mavin provides cohesion between its operating brands, Mavin Global and Mavin Powercube. Each is widely recognisable within their specific areas of expertise and have become renowned for achieving high levels of professional excellence through technology, innovation, bespoke delivery models and proactive customer relations.
Through the Powercube brand, Mavin provides no-nonsense desktop to data centre services and solutions. Specialising in the design and build of bespoke, scalable low ->medium ->high power, fit-for-purpose, modular, containerised and traditional build data centres, as well as data storage containers, specialised UPS and Switchgear containers and NOC type operations containers.
Launched by Mavin in 2005 the *M-CMDC* Containerised Modular Data Centre is an award winning, British designed and built solution. With construction taking place at our recently upgraded facility in South Wales, we collaborate openly with our clients to deliver a 100% bespoke solution, meeting specific operational requirements, with in-built flexibility to support future growth as well as cooling and power technology advancements. We offer a full turn-key engagement including full environment preparation, power and data presentation, with full professional project management support from start to finish.
Immediately raising interest as a tangible and more flexible alternative to the more traditional data centre designs of yesteryear, the M-CMDC delivers an innovative, effective and re-deployable solution to the inherent challenges faced by today's businesses moving forward into the future.
Innovation is delivered not only through the physical bespoke and scalable nature of the M-CMDC, but also via its capacity to provide client organisations with the ability to manage their capital expenditure more effectively and efficiently. This is achieved by providing a ‘plug ‘n’ play’ – ‘pay-as-you-go’ architecture that enables tangible, real-time capacity planning.
Mavin has various design concepts incorporating a calculated balance between traditional, current and next generation ideologies. All concepts are designed to maximise efficiency, space requirement and provide scalable, fit-for-purpose environments for individual user requirements.

The M-CMDC can be used as primary critical data centre, secondary DR facilities or scalable and secure hubs for wider and remote data centre. Available in single or multiple formats; the options are almost limitless. Current projects scale from a micro 2 rack single container to 38 rack single containers and 350 rack multi-container environments.
We also apply similar concepts to more traditional building based data centre design and build solutions. See here for more detail.
With a complete CMDC built and delivered within 8-16 weeks from final design sign-off, the M-CMDC may be deployed externally as a stand-alone structure or internally within a host building. The cost of an M-CMDC is economical compared to a traditional design and build. Plus, being modular and therefore movable, should an organisation wish to relocate they have the capability to migrate their entire Data Centre set-up, relatively quickly and economically.
With a highly skilled workforce, Mavin is UK based with commercial and IT technical teams operating nationwide and our design and engineering teams based at our Warwickshire and South Wales facilities.
Aimed at the private, public and defence sectors, Mavin undertake client projects using experienced, structured teams including commercial, technical, design and engineering plus the crucial project management.
Many clients choose to encompass combined services, solutions and skill sets from across the Group. Mavin’s ability to work closely with clients as a single team, supporting the same important core values and proactive, efficient nature throughout, transcends the more common and inflexible engagement models often associated with complex ICT infrastructure projects. We offer a more co-operative approach.
The Group’s strategic objective of leveraging a key differential by ‘raising the bar’ for deliverable standards within the business-to-business market place has seen record growth within the commercial, defence and public sectors.

Proud to be noted for their commitment to excellence, Mavin is an innovative organisation, offering a flexible, proactive approach and valuing open, consistent communication with clients.
Mavin has delivered high profile modular data centre solutions, including UK airports, Telco, multiple MoD, NHS and Education deployments. All fully reference able to prospective clients. Our commitment to innovation has been recognised by various data centre design official bodies, including an ICT Excellence Award for Best Value Added Service and most recently as a finalist in the prestigious industry awards held by DCS.
Mavin has enjoyed steady growth since being established, predominately through referral due to the growing reputation for delivering 1st class service and solutions. Looking to the future, Mavin expect more steady growth thanks to exciting developments with strategic partnerships in the UK and internationally.
There's an old adage that could be applied to almost every industry, whether you're cooking burgers or handling complex infrastructures: “keep it simple, stupid.” This is proving more and more difficult for IT professionals as today’s networks are becoming increasingly complex.
By Destiny Bertucci, Head Geek™, at SolarWinds.

But before we look forward, let's take a big step back—all the way back to when humans were cave dwellers. How did they communicate? Cave paintings. Now move forward, 30,000 years or so, to the early Egyptians, who used hieroglyphs to record events.
Leap forward again, and we come across the ancient Greeks, who named the constellations and mapped the skies, striving to find our place among the stars through the use of imagery. And we haven’t even touched upon the ancient Sumerians, who attempted the same thing 5,000 years ago.
Now, you may question what all this has to do with network visualisation, but bear with me. We are a visual species. Throughout time, we have relied upon diagrams, blueprints, paintings, and more to help us decipher and understand complex ideas. Why, then, should this not also apply to the network?
We already have at our disposal means to create and view diagrams that allow us to see the multiple pathways that underpin today's networks, but this is no longer enough. We need to find a way to bring everything to life visually, from network devices to traffic if we are to improve both our understanding of the network, and how we monitor and manage it.
You may think I'm overreacting, but consider device setups. When establishing a switch stack, you should have a completed ring of pairing partners when properly set up. What often happens, however, is the network administrator makes the assumption that the pairing partners are working correctly without carrying out the due diligence.
They are switched on, cabled together, and configured with nothing more than a passing concern about what will happen to these devices as people add or move cables.
So, if the chain is broken, or if the wrong cable is removed, what would happen? Well, the worst-case scenario is no redundancy, which results in unexpected downtime—an excruciating blow for an organisation. Matters are made even worse if the device is situated remotely, where the IT professionals can't even physically check if it remains configured and plugged in correctly.
Think, too, about Border Gateway Protocol networks. Traditional approaches to diagramming such networks often result in an impenetrable web of connections. Network visualisation offers the chance to see how the pathways link from one device to another, and shows how path traffic is travelling from point A to B. This allows you to remove assumption from the equation, making it clear just how the network is performing.
There are other examples, too, including software-defined devices like unified computing systems, which creates one system by bunching different networking components together. Each of these components still need to be monitored; however, a visual representation of the system can help do just that, and saves a great deal of time when troubleshooting the device.
Too many network administrators are happy to overlook the fact that many network monitoring tools don't offer visual insight into whether network devices are configured correctly. This, I find baffling. You should be able to know if a device is connected and configured correctly in seconds, rather than having to trawl through old, outdated network diagrams.
Is it really too much to ask for IT professionals to be able to open a page and immediately see whether our switch stacks are in a perfect circle, or if the pathways are all connected and running as expected? It certainly shouldn't be.
There's no doubt that network environments are only becoming more complex, and devices with software-driven protocols and back-end designs have ensured that network visualisation is no longer a luxury, but a necessity.
The amount of time that can be saved by having a tool that paints you a clear picture of an environment, rather than one steeped in confusion, is enormous. Just imagine how much easier bringing new devices online would be if you can see on your screen that you're ready to start moving cables, rather than having to physically do it yourself.
Indeed, a picture can say a thousand words, and in the case of a network environment, save you thousands of minutes.
The buzz around Big Data has risen into an audible crescendo over the past twelve months, as businesses everywhere have begun to realise its potential to make them more competitive in the digital business economy. As proven use-cases have started to emerge, we’ve moved beyond the early days of hype.
By Kalyan Kumar, EVP and Chief Technology Officer, HCL Technologies.

Businesses are now investing heavily in practical applications of Big Data to improve processes and provide better support for their customers. Google is a prime example of a company putting Big Data into action, with its Maps now using real-time mobile data to help users avoid traffic-jams. Illustrating the likely scale of this progress, IDC recently forecast that the Big Data technology and services market will grow at a compound annual growth rate of 23.1% from 2014 to 2019, with annual spending reaching $48.6 billion by 2019. Clearly, Big Data is set to get bigger and bigger.
However, using a data lake also removes the siloes that separate data sets in relational database environments. This enables businesses to create a vast reservoir where data can truly become Big Data, generating far richer insights by identifying patterns and contextualising the relationships between different data sets. As an added benefit, it is much easier to get data into a data lake in comparison to relational database environments, as there is no need to prepare or remodel the data before it can be inputted.
Once the storage platform has been built, businesses will need to ensure they have the right people on board to make their Big Data journey a success. As well as the IT team, it’s important to have digitalisation specialists and managers from every level of the business involved to identify how analytics can be integrated seamlessly with the processes it’s intended to support. It’s also vital to have people with the skills needed to implement and use Big Data tools and manage their operation effectively. However, this can often be a major stumbling block, as the relative newness of Big Data means there is a scarcity of ‘data scientists’ with these skillsets available. Whilst many universities are now offering courses to address this shortage, this younger generation of workers is new to the business world and lacks the experience of their more senior counterparts.
As such, rather than trying to navigate uncharted territories alone, many are bringing on board technology partners who already have the skills and experience of implementing Big Data projects. As well as removing the barrier created by the shortage of available skills internally, this enables businesses to learn from the experiences of others that have already completed a Big Data journey. Many partners that have managed similar projects elsewhere have also been able to build accelerators to reduce the time needed to get a Big Data initiative off the ground. For example, frameworks for completing major milestone tasks such as data integration can provide a series of modular building-blocks that can reduce much of the complexity and enable businesses to move more rapidly on their journey to Big Data.Wherever they are on their journey, there’s a very strong chance that Big Data will remain fixed on the radar of every business. However, it’s important not to get caught up in the hype. Having a fully defined roadmap, a clear destination and the right balance of internal skills and external expertise will be imperative to success. Those that are able to achieve this level of forward-thinking will surely reap the biggest rewards as their business enters a new, data-driven future.
A world without data centers seems impossible today. Every area of our life and every industry depend on data-based IT infrastructures, which have to be stored in huge data centers. To keep both data and infrastructure protected and available, operators need to prevent corrosion damage by running their data centers under stable temperature and pressure conditions. What is often thought to be a problem confined to smog-polluted cities in Asia or humid regions in Latin America has also become a common challenge in European countries. However, there is a simple solution to providing pure air and avoiding corrosion – a new filtration solution in the shape of honeycombs.
The number of data centers has grown constantly in recent years – not only in Europe and Northern America, but also in many other regions around the globe. Thanks to digital transformation and intensified data use, the traffic and storage of data are set to increase even further. According to network supplier Cisco, total data center storage capacity will increase almost five-fold from 2015 to 2020[1]. Furthermore, an increasing number of today’s data centers are located in the heart or immediate proximity of cities such as Shanghai or Beijing, which have to cope with unexpected levels of corrosive noxious gases in the air.
Sulphur-bearing gases, such as sulphur dioxide (SO2) and hydrogen sulphide (H2S), are the most common gases causing corrosion of electronic equipment. Along with various nitrogen oxides, they are released during the combustion of fossil fuels, especially in areas with large volumes of road traffic or heating systems. This type of pollution directly affects data center operators as the infiltration of gaseous contaminants leads to electronic corrosion.
In the major conurbations of China and the U.S., experts are generally aware of dangerous corrosive gases in data centers. However, air pollution and consequently the risk of corrosion for electronic components is just as high in many European urban agglomerations. In London alone, 75 centers are operated in close proximity to the city.
So how can corrosive gases affect sensitive data? Due to cost issues, data centers are not usually hermetically sealed and air is drawn in, cooled if necessary and recirculated. Facilities are usually not operated under cleanroom conditions and operators are regularly entering via normal doors, so corrosive gases have easy access to the electronic components. To make things worse, these electronic parts have become even more sensitive over the last decade: with the introduction of the European RoHS guidelines in 2006, the use of certain hazardous substances in electrical devices has been restricted, which in turn has led to changes in the compounds used for electrical parts. Unfortunately, the new substances react far more readily with noxious gases, and consequently corrosion levels have increased.
The reduction in the size of circuit board features and the miniaturization of components necessary to improve hardware performance also make the hardware more prone to attacks by corrosive particles and gases in the environment. In addition, temperature has a significant influence on the level of corrosion. Today, data centers are frequently operated at higher room air temperatures to save energy costs – while in the past operating temperatures were between 20 and 24°C, the average temperature in many data centers is now as high as 27°C. Although this may not sound alarming, we must keep in mind that a temperature increase of 10°C doubles the corrosion rate. Consequently, data centers are now more likely to be affected by corrosion, which can cause faults or equipment disturbances, reduce productivity or increase downtime and eventually lead to data loss.
Running IT systems nonstop is crucial for most organizational operations. Hence, the main concern of data center hosts is business continuity. If a system becomes unavailable, company operations may be impaired or stopped completely. Therefore, it is essential to provide a reliable infrastructure for IT operations, which will minimize the chance of disruption. A first step to preventing hardware failures in data centers is to proactively measure the air quality. In order to find a suitable preventive solution, it is necessary to assess and monitor the temperature, humidity, dust and gaseous contamination.
A simple approach to monitoring air quality is to expose copper and silver foil discs to the air for a couple of weeks, and then analyse the thickness of the resulting corrosion layer. Based on the test results, it is possible to classify the environment into one of four corrosion severity levels: G1 – mild, G2 – moderate, G3 – harsh, GX – severe. Corrosion of the sensitive electronic parts already occurs in G1 environments. Their lifespan is considerably shortened in G2 environments, while in level G3 and GX it is highly probable that corrosion will lead to damages.
Experts recommend that data center equipment should be protected from corrosion by keeping the relative humidity below 60 percent, and by limiting the particulate and gaseous contamination concentration to levels at which the copper corrosion rate is less than 300 ångström per month and silver corrosion rate is less than 200 ångström per month. Gas-phase filtration air-cleaning systems are a valuable corrective step, removing corrosive gases through the process of chemisorption or adsorption.
A common solution to eliminate acidic pollutant gases from intake and recirculated air is to use air-filtrating pellets. However, using pellets in data centers has one major disadvantage: they produce dust that will cling to the surface of the electrical parts. An additional dust filter is needed – resulting in extra costs and higher energy consumption. Freudenberg Filtration Technologies supports customers around the globe with its Vildeon system solutions for industrial filtration. As an alternative to pellets, Freudenberg offers a revolutionary, honeycomb-shaped filter technology based on activated carbon. This new technology can remove contaminant and odorous gases as well as volatile organic compounds from the air supply stream more efficiently, and is capable of neutralizing even ultra-low concentrations of gaseous contaminants.
The new Viledon Honeycomb modules are based on Freudenberg’s Versacomb technology, which works with parallel square channels through which the air passes. The channels are separated by walls made of activated carbon powder, which are less than a millimetre thick. They are held in shape by ceramic binders to prevent any dust production and to provide stability. The honeycomb structure reduces the maximum distance between the carbon and the bulk flow of the process air, allowing highly efficient interaction between carbon and air during operation at high flow velocities.
Existing systems can be easily upgraded or retrofitted with the new technology. If a data center is already equipped with an air-conditioning system, the Honeycomb modules can be installed before the air intake since they have a low air resistance. Pressure loss is only one-third that of pellet-based solutions, which means that the new solution is able to work with existing air-conditioning systems, while pellets would require a larger and more expensive air-conditioning solution due to pressure loss. Depending on the size of the data center, honeycomb modules can be flexibly combined according to the density and composition of the corrosive gases.
Once the modules are installed, no further maintenance is needed. Honeycomb filters will run for between four and five years before they have to be changed – depending on the contamination level. To monitor the corrosivity of the air in a room, an online system based on copper and silver sensors – as described before – can easily be set up. ChemWatch by Freudenberg collects the data on the corrosion status and visualises the information about the current G classification graphically. All data can be transferred to a computer, control station or smartphone, providing operators with a constant overview of the air quality. Thanks to the sensors’ corrosivity measurement, operators are able to foresee when the filter’s capacity is coming to an end and needs to be replaced.
Freudenberg also provides a comprehensive filter management package, comprising not only innovative filter solutions, but also service support and warranties. Viledon filterCair is based on specialist expertise for diverse industry sectors combined with top-quality filter solutions for any requirements. Companies like Pacific Insurance and Alibaba in Asia, already rely on Freudenberg’s Viledon Honeycomb filter solutions. Thanks to this highly efficient and reliable gas-phase filtration system, customers have been able to significantly improve the air quality in their data centers, helping ensure that their systems remain up and running without the fear of data loss due to corrosion. Based on this experience, several European data center hosts are also considering the implementation of the Honeycomb technology. Since the risk of pollution is expected to increase in European cities over the next years, a reliable filtration solution is paramount to protecting data and introducing purest air into data centers.
[1] “Cisco Global Cloud Index: Forecast and Methodology, 2015–2020”, source: http://www.cisco.com/c/dam/en/us/solutions/collateral/service-provider/global-cloud-index-gci/white-paper-c11-738085.pdf
Do it once – do it right
Digitalisation as a game changer for fibre networks.
By Tobias Münzer, Market Manager Public Networks, R&M.

Human progress has always been closely linked to technological development. After the Stone Age, Bronze Age and Iron Age, between 2 million BC and 1,200 BC, the next major development was harnessing natural power. The 18th century saw the water wheel, the 19th century was characterised by steam. The 20th century saw the advent of electrical engineering and ICT.
In recent years, we’ve witnessed the rise of the WWW and PDAs, 4G mobile computing and the advent of Artificial Intelligence and 5G. These advances have enabled a shift from individual interaction and learning to connected learning, IoT and digital enterprise. In the most recent years, we’ve seen a merging of platforms and technologies on a vast scale. A convergence of networks with mobile computing and connectivity, along with the arrival of cloud-based technologies has brought new possibilities, from the Internet of Things to, Digital Infrastructure management, Digital commerce and finance, and is currently on it’s way to creating ‘Digital Enterprises’. As Artificial Intelligence and Virtual Reality become more widespread, we’ll be seeing application that haven’t even been considered yet, but may prove extremely valuable. Based on developments over the past decades, we may assume that the digital revolution will continue to make our lives more comfortable and our work more efficient and bring us new opportunities and prospects.
Today, many industries are facing serious challenges and business models are changing as communication infrastructures need to boost availability, latency, capacity and data throughput. Fibre optics can enormously improve high-speed internet connectivity and the resulting improved digital infrastructure has a marked effect on many aspects of business and society. This ranges from HD video streaming to healthcare innovations, autonomous vehicles and new payment methods based on blockchain technology. Completely new business opportunities will continue to arise and the way we live and behave will change.
One interesting observation: the speed at which innovations and developments follow each other has been increasing over the centuries. This process will, without a doubt, only accelerate further. Obviously, that makes planning ahead in terms of infrastructure increasingly difficult. However, a few points can be made. In addition to today’s Human-to-Human and Human-to-Machine communication, we will witness a tremendous increase in Machine-to-Machine and Device-to-Device communication, which are essential to a number of fast-moving developments. Examples of these developments include smart cities (traffic management, video surveillance, mobility on demand), smart homes (energy management, automating, increased security), augmented and virtual reality, wearables, implanted technologies (health sector) and V2X communication.
The growth momentum of fixed networks and especially mobile communication will continue and these platforms will play a vital role. However, less than one year ago, the IFO (Institute for Economic Research) stated that fibre deployment wouldn’t be required for the time being, as higher data rates would be based on mobile anyway. However, far more mobile communication cell sites are needed to cover demand for increasing bit rates and low latency - these must all be connected to core networks. This is the only way in which the increasing demand for broadband & latency can be covered.
A solid, reliable fibre optic infrastructure is the key to the playground of digitalisation and a requirement to stay there! However, the world is still lagging when it comes to fibre optic coverage. We don’t only have to roll out fast – have to get it right first time! However: what is the ‘right’ way to organise coverage? To answer this, we need to take a few things into account. The infrastructure we’re designing faces several key challenges. It needs to provide a continuous bit rate while bandwidth demand increases. Furthermore latency needs to be as low as possible and downtime is out of the question, as more mission-critical systems than ever depend on functioning networks. In addition, the networks needs to offer enough flexibility to accommodate future upgrades and network quality and reliability
As end-user and device-to-device data grow, network quality, reliability and flexibility are key factors for current and future success. This requires precise specifications, in line with local needs and requirements, and an eye for detail in the execution and maintenance phases. A very precise requirement specification, adapted to regional and local circumstances is absolutely key! The checklists below list a number of items that need to be covered by the specification.
Generic characteristics of a good specification:
Minimum must-haves for passive Infrastructure specification:
Any installation that is designed, rolled out, maintained and upgraded with these principles in mind will support consecutive generations of network technology, protocols and the applications that run upon them. By designing networks with the right kind of flexibility and reliability in mind, and making smart technology choices today, potential bottlenecks can be solved, supporting the requirements of innovations such as the Internet of Things today and in the future.
It’s a huge decision for any company. Let’s take out infrastructure, the IT heartbeat of our organisation and house it in a custom built data centre beside some of our competitors. Or indeed let’s outsource the provision of our infrastructure and put it in a data centre beside some of our competitors. Why would you do that?
By Doug More, CEO, Assure APM.

Security, reliability, best practice, failure, and financial considerations could all be cited to make a business case. Also, better your mission critical business systems and data information is housed in a state of the art custom built data centre rather than crammed into a makeshift cupboard or storeroom, as is the case in some organisations.
Complying with industry recognised standards such as ISO 22301:2012 for Business Continuity and ISO 27001:2013 for Security sometimes comes at a prohibitive price for some organisations. This means that promises from data Centre providers to give you the very best of breed and highly expensive to build and maintain location for the IT nerve centre of your organisation is a compelling proposition. Offering access anywhere in the UK in less than 20 milliseconds, state of the art, purpose built, Tier III+ facilities with multiple failsafe power sources, fire prevention and optimum physical security certified for Azure hybrid cloud can underpin the business case.
However, a lack of real control and visibility can be an insurmountable issue for some organisations. Here’s where APM comes in. Advanced Performance Management (APM) technology automates many of the tasks associated traditionally with IT support people. It provides a round-the-clock automatic watchdog monitoring all aspects of an IT environment: the application, infrastructure, networks, virtual environments and cloud environments. The technology monitors all this from the perspective of ‘end user performance’ ensuring that the optimum is maintained and if there are any issues, rapidly reporting where the problem is to support staff, usually before there is any impact on the business or the user population.
These performance metrics can be displayed anywhere and tailored to any audience. So if you are the COO you can see at a glance that all is well. Or if you are the CIO you can tell with one look that there is trouble on the horizon unless you do something. IT support can pinpoint where the problem lies and can call specialists to resolve issues without any ambiguity. So, your organisation now has visibility and control of outsourced infrastructure and network performance allowing you to confidently outsource core business functions like data centre and infrastructure to a specialist whilst at the same time retaining visibility. It allows support staff to get on with rectifying issues and delivering system enhancements within the security of a top tier data centre environment to operate in.
Trust is at the root of all successful partnerships. Without trust between all parties, commercial relationships can break down. And it is prohibitively expensive to move infrastructure between data centre providers if trust and the contract relationship has broken down. For the data centre provider, there is reputational damage and the onerous expense of getting new business in the door.
So how can trust be built and maintained by data centre and infrastructure outsource providers? The answer is Advance Performance Management.
In recent times, there has been a move to hybrid IT environments spanning both mainframe and legacy systems, private clouds and hyperscale cloud providers such as Amazon, Google and Microsoft. These are complicated environments. Organisations providing outsource facilities need to be able to provide complex skill sets, processes and tools that are essential to manage this kind of infrastructure consistently and at scale. If this can’t be delivered it can lead to serious problems for the customer and impact the overall relationship.
This shift in IT expectation has resulted in the client demanding more transparency, control and visibility. To provide this level of service, most traditional business models would require a root and branch upheaval. But thanks to the advent of APM, which incorporates Infrastructure and Network Performance Management with Applications Performance Management, it is possible to build a level of trust.
These are two technologies which are industry recognised and complementary, but currently they are diverse. In my experience the best solution for complete oversight is a combination of the two with bells on. I refer to it as advanced performance management (APM), a much more holistic approach using just one tool, providing ultimate visibility and control.
Using this APM technology it is possible for true transparency to be automated and delivered round the clock. Implementation of monitoring technology in data centres allows for reporting to all stakeholders, giving a true understanding of exactly what is happening and so building trust.
The performance management technology does this by building up a picture of what ‘normal state’ is. Once integrated into a system the software will run and monitor the activity on the network for a period. It will observe the peaks and troughs of activity, where users are accessing files and when. Having captured this normal state, alerts can then be set up to flag unusual activity, whether this is people accessing certain files or anything else that is deemed to be outside the norm. APM’s auto discovery and proactive problem identification capability makes for far more efficient use of the human resource and lowers the cost of the service delivery overhead.
This automated oversight helps with system transparency in many ways. It can aid the detection of security threats from both inside and outside the network. It can pre-emptively detect problems across the network, for example it could see unusual activity affecting the DBA team or the network team, allowing the incident management team to pinpoint this and ask the relevant people to investigate before a major problem occurs.
Currently, finding exactly what is causing problems in a network is time consuming – up to 30 percent of total time spent on IT support is fault-finding. This obviously adds to the length of resolution time and to the frustration of end users. Advanced Performance Management technology can virtually eradicate this and helps to create a transparent, optimised and efficient environment. Good news for everyone.
There are other added benefits beyond trust in deploying this tech. Thanks to understanding what ‘normal state’ looks like, monitoring software can predict and detect where future issues may arise. This allows incident management teams to proactively target areas that might cause system slowdowns or outages before they happen. The technology also enables modelling and testing prior to the roll-out of new technology and applications.
As well as building trust via transparency, APM can be updated and calibrated as the underlying system changes over time and to keep up with innovations in the marketplace. This means that an expensive and time-consuming overhaul won’t be required as the software can keep pace with current requirements.
The development of a trust based, transparent business model that generates longer-term contracts based on real working partnerships is valuable to both data centre provider and client. It reduces cost, provides resource continuity and increases general productivity. Building trust through transparency saves money and ultimately delivers enhanced services. Finally, it provides the answer to the datacentre conundrum - how do I maintain security, visibility and control of my IT all in one package without investing in a massive non-core business asset like a datacentre?