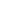The worldwide public cloud services market is projected to grow 18 percent in 2017 to total $246.8 billion, up from $209.2 billion in 2016, according to Gartner, Inc. The highest growth will come from cloud system infrastructure services (infrastructure as a service [IaaS]), which is projected to grow 36.8 percent in 2017 to reach $34.6 billion. Cloud application services (software as a service [SaaS]) is expected to grow 20.1 percent to reach $46.3 billion (see Table 1.)
"The overall global public cloud market is entering a period of stabilization, with its growth rate peaking at 18 percent in 2017 and then tapering off over the next few years," said Sid Nag, research director at Gartner. "While some organizations are still figuring out where cloud actually fits in their overall IT strategy, an effort to cost optimize and bring forth the path to transformation holds strong promise and results for IT outsourcing (ITO) buyers. Gartner predicts that through 2020, cloud adoption strategies will influence more than 50 percent of IT outsourcing deals."
Advertisement: Eltek

"Organizations are pursuing strategies because of the multidimensional value of cloud services, including values such as agility, scalability, cost benefits, innovation and business growth," said Mr. Nag. "While all external-sourcing decisions will not result in a virtually automatic move to the cloud, buyers are looking to the 'cloud first' in their decisions, in support of time-to-value impact via speed of implementation."
Table 1. Worldwide Public Cloud Services Forecast (Millions of Dollars)
| 2016 | 2017 | 2018 | 2019 | 2020 | |
| Cloud Business Process Services (BPaaS) | 40,812 | 43,772 | 47,556 | 51,652 | 56,176 |
| Cloud Application Infrastructure Services (PaaS) | 7,169 | 8,851 | 10,616 | 12,580 | 14,798 |
| Cloud Application Services (SaaS) | 38,567 | 46,331 | 55,143 | 64,870 | 75,734 |
| Cloud Management and Security Services | 7,150 | 8,768 | 10,427 | 12,159 | 14,004 |
| Cloud System Infrastructure Services (IaaS) | 25,290 | 34,603 | 45,559 | 57,897 | 71,552 |
| Cloud Advertising | 90,257 | 104,516 | 118,520 | 133,566 | 151,091 |
| Total Market | 209,244 | 246,841 | 287,820 | 332,723 | 383,355 |
Source: Gartner (February 2017)
The SaaS market is expected to see a slightly slower growth over the next few years with increasing maturity of SaaS offerings, namely human capital management (HCM) and customer relationship management (CRM) and the acceleration in the buying of financial applications. Nevertheless, SaaS will remain the second largest segment in the global cloud services market.
"As enterprise application buyers are moving toward a cloud-first mentality, we estimate that more than 50 percent of new 2017 large-enterprise North American application adoptions will be composed of SaaS or other forms of cloud-based solutions," said Mr. Nag. "Midmarket and small enterprises are even further along the adoption curve. By 2019, more than 30 percent of the 100 largest vendors' new software investments will have shifted from cloud-first to cloud-only."
Gartner predicts more cloud growth in the infrastructure compute service space as adoption becomes increasingly mainstream. Additional demand from the migration of infrastructure to the cloud and increased demand from increasingly compute-intensive workloads (such as artificial intelligence [AI], analytics and Internet of Things [IoT]) — both in the enterprise and startup spaces — are driving this growth. Furthermore, the growth of platform as a service (PaaS) is also driving the growth in adoption of IaaS.
From a regional perspective, China's IaaS cloud market forecast has been increased to account for anticipated higher buyer demand over the forecast period. In particular, the larger pure-play IaaS providers in China, as well as other telecom-related cloud providers driving this market, are reporting significant growth. While China's cloud service market is nascent and several years behind the U.S. and European markets, it is expected to maintain high levels of growth as digital transformation becomes more mainstream over the next five years.
There was a record 155MW of take-up across the four major European data centre markets of Frankfurt, London, Amsterdam and Paris during 2016 according to global real estate advisor, CBRE.
Amsterdam (54WM) became the first market in history to see more than 50MW of take-up in a single year, whilst London (49MW) and Frankfurt (34MW) recorded more take-up than any individual market had done in any year before 2016; the previous high was London with 29MW in 2010.
The Paris Market saw 17.6MW of take-up in the year, which is over seven times that of a particularly poor performance in 2015 (2.5MW). This was, in percentage terms, the largest increase from any market on the previous year.
Andrew Jay, Executive Director, Data Centre Solutions, at CBRE commented: “The record level of take-up in 2016 was totally unprecedented. Q4 alone saw almost as much activity as any other full year. Over the course of 2016 all four markets saw more take-up than they each did in the previous two years combined. The numbers are quite astounding.
“Cloud continues to dominate the landscape, with 70% of deals coming from this sector. These hyperscale cloud deals that once would have been unusual became the norm. We predict that cloud take-up will continue to increase in size as more hyperscale providers turn to large-scale build-to-suit facilities as an effective speed to-market option.”

Internet of Things (IoT) infrastructure spending is making inroads into enterprise IT budgets across a diverse set of industry verticals. IDC has just released the results of a U.S. survey, IoT IT Infrastructure Survey, which finds that improved business offerings, IoT data management, and new networking elements are key to a successful IoT initiative within an enterprise.
The new survey examines current and future plans of IT end users for IoT infrastructure and provides analysis on IT organizations' knowledge of IoT, their plans to deploy an IoT strategy in the next 24 months, and which vendors are best suited to influence end user IoT initiatives.
"Given the strong uptake in IoT based technology solutions, enterprise IT buyers are looking for vendors who can add IoT capabilities to the current networking and edge IT infrastructure," said Sathya Atreyam, research manager, Mobile and IoT Infrastructure. "Further, success of IoT initiatives will also depend on how IT buyers can effectively leverage newer frameworks of low power connectivity mechanisms, network virtualization, data analytics at the edge, and cloud-based platforms."
Advertisement: Vertiv

Additional findings from the survey include the following:
"The survey revealed that IoT will have significant impact on end users' decisions and strategies related to IT infrastructure across all three major technology domains: networking, software, and storage," said Natalya Yezhkova, research director, Storage. "Increase in budgets, broader adoption of public cloud, and open source solutions are the most anticipated results of IoT initiatives."
A new update to the Worldwide Digital Transformation Spending Guide from IDC forecasts worldwide spending on digital transformation (DX) technologies to be more than $1.2 trillion in 2017, an increase of 17.8% over 2016. IDC expects DX spending to maintain this pace with a compound annual growth rate (CAGR) of 17.9% over the 2015-2020 forecast period and reaching $2.0 trillion in 2020.
"Changing competitive landscapes and consumerism are disrupting businesses and creating an imperative to invest in digital transformation, unleashing the power of information across the enterprise and thereby improving the customer experience, operational efficiencies, and optimizing the workforce," said Eileen Smith, program director in IDC's Customer Insights & Analysis Group. "In 2017, global organizations will spend $1.2 trillion on digital transformation with discrete and process manufacturers contributing almost 30% of this spending, while the fastest growth will come from retail, healthcare providers, insurance, and banking."
The technology categories that will see the greatest amount of DX spending in 2017 are connectivity services, IT services, and application development & deployment (AD&D). Combined, these categories will account for nearly half of all DX spending this year. However, investments in these categories will vary considerably from industry to industry. The discrete and process manufacturing industries, for example, will invest roughly 20% of their DX budgets in AD&D and another 12-13% in IT services while the transportation industry will devote nearly half of its spending to connectivity services.
Advertisement: 8Solutions

The fastest growing technology categories associated with digital transformation over the five-year forecast are cloud infrastructure (29.4% CAGR), business services (22.0% CAGR), and applications (21.8% CAGR). And, despite a CAGR that is slower than the overall market (17.3%), AD&D spending will grow fast enough to overtake IT services as the second largest DX technology category by 2020.
More than half of all DX investments in 2017 will go toward technologies that support operating model innovations. These investments will focus on making business operations more responsive and effective by leveraging digitally-connected products/services, assets, people, and trading partners. Investments in operating model DX technologies help businesses redefine how work gets done by integrating external market connections with internal digital processes and projects. The second largest investment area will be technologies supporting omni-experience innovations that transform how customers, partners, employees, and things communicate with each other and the products and services created to meet unique and individualized demand.
On a geographic basis, Asia/Pacific (excluding Japan) will see the largest investments in DX technologies in 2017 with 37% of the worldwide total. DX spending in this region will be led by the discrete and process manufacturing industries as well as professional services firms. The United States will be the second largest region with 30% of the worldwide total, led by professional services, discrete manufacturing, and the transportation industries. Latin America and the Middle East and Africa will experience the fastest growth in DX spending with five-year CAGRs of 23.4% and 22.6%, respectively.
Worldwide revenues for information technology (IT) products and services are forecast to reach nearly $2.4 trillion in 2017, an increase of 3.5% over 2016. In a newly published update to the Worldwide Semiannual IT Spending Guide: Industry and Company Size , IDC estimates that global IT spending will grow to nearly $2.65 trillion in 2020. This represents a compound annual growth rate (CAGR) of 3.3% for the 2015-2020 forecast period.
Industry spending on IT products and services will continue to be led by financial services (banking, insurance, and securities and investment services) and manufacturing (discrete and process). Together, these industries will generate around 30% of all IT revenues throughout the forecast period as they invest in technology to advance their digital transformation efforts. The telecommunications and professional services industries and the federal/central government are also forecast to be among the largest purchasers of IT products and services. The industries that will see the fastest spending growth over the forecast period will be professional services, healthcare, and banking, which will overtake discrete manufacturing in 2018 to become the second largest industry in terms of overall spending.
Advertisement: Hillstone

How can datacentre owners and operators rapidly understand availability, capacity and efficiency of their facility?
This video showcases the available datacentre services including datahall CFD calibration & server simulator load banks. Further details can be found on our website, or by getting in touch.
Meanwhile, more than 20% of all technology revenues will come from consumer purchases, but consumer spending will be nearly flat throughout the forecast (0.3% CAGR) as priorities shift from devices to software for things such as security, content management, and file sharing.
"Consumer spending on mobile devices and PCs continues to drag on the overall IT industry, but enterprise and public sector spending has shown signs of improvement. Strong pockets of growth have emerged, such as investments by financial services firms and utilities in data analytics software, or IT services spending by telcos and banks. Government spending has stabilized, and shipments of notebooks including Chromebooks posted strong growth in the education market. Double-digit increases in commercial tablet spending will drive a return to growth for the overall tablet market this year, despite ongoing declines in consumer sales. These industry-driven opportunities for IT vendors will continue to emerge, even as the global economy remains volatile," said Stephen Minton, vice president, Customer Insights and Analysis at IDC.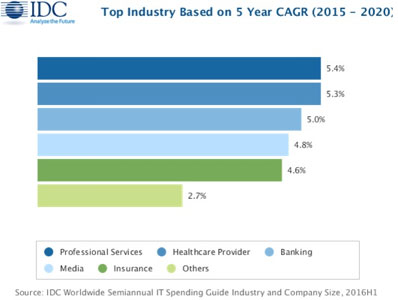
On a geographic basis, North America (the United States and Canada) will be the largest market for IT products and services, generating more than 40% of all revenues throughout the forecast. Elsewhere, Western Europe will account for slightly more than 20% of worldwide IT revenues followed by Asia/Pacific (excluding Japan) at slightly less than 20%. The fastest growing regions will be Latin America (5.3% CAGR) followed by Asia/Pacific (excluding Japan) and the United States (each with a 4.0% CAGR).
IT spending in the United States is forecast reach nearly $920 billion this year and top the $1 trillion mark in 2020. While IT services such as applications development and deployment and project-oriented services will be the largest category of spending in 2017 ($275 billion), software purchases will experience strong growth (7.9% CAGR) making it the largest category by 2020. Business services will also experience healthy growth over the forecast period (6.0% CAGR) while hardware purchases will be nearly flat (0.5% CAGR).
"While we are seeing a tempering in growth for U.S. healthcare provider IT spending as we enter the post-EHR era, the diverse and innovative professional services industry is expected to exhibit the fastest growth over the life of the forecast. Combine tech-savvy talent with an information-based business, and one can envision the multitude of possibilities for IT in this segment. IT investments will be used to achieve goals related to the differentiation of products and services, improving client satisfaction, and increasing revenue," said Jessica Goepfert, program director, Customer Insights and Analysis at IDC.
In terms of company size, more than 45% of all IT spending worldwide will come from very large businesses (more than 1,000 employees) while the small office category (businesses with 1-9 employees) will provide roughly one quarter of all IT spending throughout the forecast period. Spending growth will be evenly spread with the medium (100-499 employees), large (500-999 employees) and very large business categories each seeing a CAGR of 4.3%.
“Global SMB software spending will surpass that of hardware in 2018, upending traditional IT spending habits. More mature SMBs already recognize the value of linking software investments to business processes, and by the end of the forecast, we expect most midmarket firms will be on a path to embrace digital transformation," said Christopher Chute, vice president, Customer Insights and Analysis.
"Changing SMB attitudes regarding the importance of technology investment cut across company size and region categories. Small and midsize firms in developing geographies are just as interested in leveraging technology as those in developed regions. This sets the stage for spending growth everywhere, especially in midsize firms," added Ray mond Boggs, program vice president, SMB Research.
There are clear signs of maturity and still further evolution in the managed services market. Recent research continues to show high double digit growth in managed services for the next five years at least. The core reason for this is that it works, offering high effectiveness and performance, but to take full advantage, there is still a need for channels and MSPs themselves to keep up to speed on the latest developments, perhaps even more on the sales, management and development side than the technical aspects. The Managed Services and Hosting Summit 2017 (http://mshsummit.com/amsterdam) will focus on how the market has evolved and how the Managed Service Provider is helping organisations to succeed in this brave new digital world, but also on what MSPs need to know in 2017.
A 360Market research report in February 2017 - The Cloud-based Managed Services Market - predicts growth of 19.7% CAGR during the period 2016-2020. It says that the market drivers are the same as ever: the need to gain competitive edge, while the challenge to all players is the lack of integration expertise, both in customers’ organisations and the channels supplying them.

The research highlights a key trend in how demand for mobility services is spreading across industry verticals – something which MSPs themselves have noted, and have geared up to provide across diverse industries for improved data security, productivity, and privacy.
Cloud-based managed services consist of a wide range of services that help organizations to monitor, regulate, and improve the IT infrastructure of an organization and all these aspects are important. These services offer the advantages of cost containment and reduced inventory, which are attractive to customers, but the managed services industry still needs to arm itself with a clear sales message and the ability to convey all the implications of managed services through its sales message. These are required by organisations to develop an economical cost structure and minimise expenditure and to provide a solid foundation to build on in the future.
Until recently services were still unknown and some organisations and institutions were both reluctant to make any changes and rather sceptical about the security and privacy systems in the cloud services. However, now that larger companies are comfortable with the concept of the cloud services and are looking to move more and more of their IT requirements to this model, the advantages are being seen by smaller business. At the same time, new models of data management and control through the use of IoT are now appearing on customers’ lists of requirements.
So this model is not all-pervasive - many small and medium businesses lack the technical expertise that is required to make the conversion to the cloud, and some channels are still primarily following the traditional break-fix model. So the process of change is still accelerating. Reaching the SMB and IoT sectors is expected to provide lucrative opportunities to managed services providers. The segment of managed mobility services is anticipated to surge at a considerably high CAGR during the next couple of years. With the growing use of tablets, smart phones, and other different mobile devices, the growth opportunities in the managed mobility services market have also surged.
The Managed Services and Hosting Summit will examine the role of managed services in a digital world - The sessions will focus initially on the evolution of the digital marketplace, how Managed Services need to evolve in this digital era and how governments and the European Community are driving this marketplace. The event then breaks into two streams. The first, ‘Behind the Service’, will be a series of talks focused on the latest technologies and practices around the infrastructure and services vital to delivering the managed service offering. The second stream, ‘Delivering the Service’, will address some of the key issues around delivering a first class user experience.
The keynote talks following this will focus on how Managed Services can help organisations secure their financial future by the exploitation of the era of the ‘Industrial Internet’ as well as secure their own and customers’ digital information against a background of mounting international fraud and cyber-attacks. Speakers and panellists will share their knowledge and insight into the opportunities and threats that organisations now face and what they can expect as digitalisation spreads throughout all facets of business operations. For full details of the agenda see http://mshsummit.com/amsterdam/agenda.php
[optional extra para] The network management services segment is likely to hold the largest market share in the IoT Managed Services Market, says research, and this is another aspect to be considered by supply channels and MSPs. Network management deals with the entire network chain of an organisation. It is essential to enhance the network for optimum utilization of the available resources. Network management services assist in analysing the amount of data transferring over a network and automatically routes it, to avoid congestion that can result in crash of the network. Opting for managed services can help organisations with reduced downtime, better network connectivity, safety, security, automatic device discovery, scalability, and seamless operation of the business process, but the MSP, integrator and other channels need to understand the management issues and layers of responsibility.

A one-day end-user
conference on flash and SSD storage technologies and their benefits for IT
infrastructure design and application performance.
1st June 2017 – Munich / 15th June 2017 - London
Since the very early days of flash storage the industry has gathered pace at an increasingly rapid rate with over 1,000 product introductions and today there is one SSD drive sold for every three HDD equivalents. According to Trendfocus over 60 million flash drives shipped in the first half of 2016 alone compared to just over 100 million in the whole of 2015.
FLASH FORWARD brings together leading independent commentators from the UK, Germany and the USA, experienced European end-users and most of the key vendors to examine the current technologies and their uses and most importantly their impact on application time-to-market and business competitiveness.
Divided into four areas of focus the conference will carry out a review of the technologies and the applications to which they are bringing new life together with examining who is deploying flash and where are the current sweet spots in your data centre architecture. The conference will also examine what are the best practices that can be shared amongst users to gain the most advantage and avoid the pitfalls that some may have experienced and finally will discuss the future directions for these storage technologies.

In London the keynote speakers and moderators are confirmed as Chris Mellor of The Register, Ken Male from TechTarget, Randy Kerns of Evaluator Group and the widely read blogger Chris Evans while in Munich we have respected analyst Dr. Carlo Velten, Jens Leischner from the user community, Bertie Hoermannsdorfer of speicherguide.de and André M. Braun representing SNIA Europe delivering the main conference content.
Sponsors include Dell/EMC, Fujitsu, IBM, Pure Systems, Seagate, Tintri, Toshiba, and Virtual Instruments and both events are fully endorsed by SNIA Europe.
Pre-register today at www.flashforward.io

By Steve Hone CEO, DCA Trade Association
This month’s theme is Service Availability and Resilience. It’s only natural that every data centre wants to ensure they are as resilient as possible.
Data centre owners spend hundreds of thousands on technology trying to achieve this goal and then tens of thousands to keep it maintained both from a support and power perspective. The other holy-grail that everyone seems to chase is the lowest PUE figure possible.

These two objectives are actually diametrically opposed to one another as the more resilience you build into your data centre the more inefficient it becomes as you need more energy to maintain the infrastructure you have running. This often has the perverse effect of sending your PUE up, not down. It is worth noting at this point that the “E” in PUE stands for “Effectiveness” NOT “Efficiency” which is a mistake often made and this yet again puts a different prospective on it.
On the subject of effectiveness, it is also worth noting that just because you think the facility you run or use is resilient on paper (e.g. N+ this and N+ that) please don’t automatically assume these measures will actually be “effective” in ensuring your service remains ‘Available’. Making sure you have fully tested processes and that a business continuity plan is in place is just as important, and some would argue more important, than the hardware itself. After all, when things go wrong, and they will, it is normally human error which is ultimately to blame.
Advertisement: Riello UPS

One very real example of this happened recently to one of the largest cloud providers to the insurance world, having suffered a major service outage at its third party colocation data centre despite boasting a 99.99999% uptime record, all eyes quickly turned to the data centre provider as the guilty party. I am sure there will be lessons learnt by the colocation provider, however I can’t help wondering if the ultimate reasonability for this outage actually lies with the managed service cloud provider for not asking the right questions and not planning more effectively for the worst.
Having a regularly tested business continuity strategy with your suppliers is critical, in fact it is often referred to as an insurance policy to help protect your business and your clients. The irony of this story is that it involved one of the largest providers of cloud based services to some of the top global insurance companies – who all failed to recognise the risk or value in investing in an insurance policy of their own.
It would be unfair to single out this one incident, provider or sector as I’m sorry to say this story is not uncommon, there are clear lessons to be learnt here for all clients seeking cloud based services and for all cloud providers seeking a hosting provider to deliver and underpin their offering.
Problems do occur irrespective of how resilient the provider says their service is and when it happens the SLA won’t save you. It is vital you do your due diligence, ignorance is no defence in the eyes of the law and no defence in the eyes of very unforgiving clients.
I would like to thank all those that contributed articles this month. Next edition is an opportunity for your customers to speak for you in the form of client case studies so if you would like to submit then please forward them to:
Kieranh@datacentrealliance.org
Deadline for submissions is the 15th March.
Finally, The DCA has an update seminar the afternoon before DCW 2017 at the Excel on the 14th March, if you are a DCA member or someone interested in finding out more about the Trade Association and the value it can deliver, you are more than welcome to register and attend. Full details are available on the DCA website:

By Prof Ian F Bitterlin, CEng FIET, Consulting Engineer & Visiting Professor, University of Leeds
We’ve all seen the claims for 99.999% uptime in data centre SLAs (service level agreements) and adverts for UPS, promising the holy-grail of ‘five-nines’ Availability. But what does it mean? By itself, without any explanation or supporting statements, any claim for any percentage is meaningless along similar lines to Sam Goldwyn’s ‘a verbal contract isn’t worth the paper it’s printed on’.

To understand why I claim it to be ‘meaningless’ we simply have to consider how we calculate the percentage Availability in the first place. It could not be easier; you need just two numbers and the ability to add, divide and multiply by 100. The two numbers are usually number of hours, the MTBF (mean time between failures) and the MDT (mean down time). If you divide MTBF by (MTBF+MDT) and multiply the answer by 100 you have the percentage uptime. Simply put, it’s the ratio of the time between failures divided by the total elapsed time. So, 1 hour MDT every 25,000h (with one year being 8760h) results in 99.996% Availability.
Unfortunately, so does a 4 hour MDT every 100,000h, or 15 minutes every 6250h. Now we see the trick because, let’s face it, we are more interested in having a system that doesn’t fail for 11 years, but when it does takes 4 hours to fix than in a system that fails nearly every 9 months but only takes 15 minutes to fix. The load, the ICT system, can often take several hours to reboot and in the process much transient data can have been lost forever. So ‘Availability’ isn’t a good, or an informative, metric. We are, clearly, much more interested in MTBF and, we have to presume, the person doing the Availability calculation has used an MTBF and MDT figure to create the percentage – rather than just guess it?
Let’s look at the two simple examples I opened with. First the data centre uptime SLA. Now 99.999% will result in a break of once per year of approximately 5 minutes (a very poor data centre by any standards) or, more attractively, a break of 52.5 minutes once every 10 years. If you consider that the power system can fail for 10ms (10 thousandths of a second) and the load can be lost then it is vital that that the 52.5 minutes is in one single failure event and not an accumulation of 315,000 very short events!
However, a promised 99.999% presents problems for the M&E systems. If we consider that the ‘availability’ of a data centre depends upon mainly human error (which you can’t model) but on the product of power, cooling, communication and fire suppression and inadvertent action of the EPO (Emergency Power Off) button, then each system will have to provide close to 99.99999% uptime – a very ambitious and expensive target.
Secondly let’s consider the frequent claims for modular UPS systems with 99.999% uptime. Firstly, that rarely includes the power distribution between the UPS and load but we should ignore that for now. The point is that most UPS are limited to the MTBF of their output circuit breaker which is in the order of 250,000h and when you model the whole UPS all systems, largely regardless of technology or architecture, tend to 80,000-100,000h MTBF.
The only way to get 99.999% is to assume, without telling anybody, that the modular UPS is fixed within 15 minutes. This means fixed by the client himself, assuming he can, assuming he has the spares on site and not waiting 4-8 hours for the service engineer – all highly unlikely. If you use 8 hours for the ‘fix’ then the same MTBF produces an Availability of 99.99%, four not five ‘nines’. Herein lies a perception problem – 99.99% doesn’t look much worse than 99.999% but the difference could be disastrous for a data centre manager.
So, what ‘should’ we do? Well, that is also easy. A ‘proper’ SLA would read ‘an Availability of 99.999%, measured over a period of 10 years and defined as one failure event’. You will notice that you can now see the MTBF (87,600h) and you can (now) calculate the assumed MDT as 52.5 minutes. Mind you it isn’t as attractive for the marketing department as ’99.999%’ is much punchier!

By Wendy Torell, Senior Research Analyst, Schneider Electric’s Data Centre, Science Centre
The migration of critical applications from traditional data centres to the cloud has garnered much attention from analysts, industry observers and data centre stakeholders. However, as the great cloud migration transforms the data centre industry, a smaller, less noticed revolution has been taking place around the non-cloud applications that have been left behind. These “edge” applications have remained on-premise and because of the nature of the cloud, the criticality of these applications has increased significantly.

The centralised cloud was conceived for applications where timing wasn’t absolutely crucial. As critical applications shifted to the cloud, it became apparent that latency, bandwidth limitations, security and other regulatory requirements were placing limits on what could be placed in the cloud. It was deemed, on a case-by-case basis, that certain existing applications (e.g. factory floor processing), and indeed some new emerging applications (like self-driving cars, smart traffic lights and other “Internet of Things” high bandwidth apps), were more suited for remaining on the edge.
Considering the nature of these rapid changes, it is easy for some data centre planners to misinterpret the cloud trend and equate the decreased footprint and capacity of the on-premise data centre with a lower criticality. In fact, the opposite is true. Because of the need for a greater level of control, adherence to regulatory requirements, low latency and connectivity, these new edge data centres need to be designed with criticality and high availability in mind.
The issue is that many downsized on-premise data centres are not properly designed to assume their new role as critical data outposts. Most are organised as one or two servers housed within a wiring closet. As such, these sites, as currently configured, are prone to system downtime and physical security risks and therefore, require some rethinking.
Systems redundancy is also an issue. With most of the applications living in the cloud, when that access point is down, employees cannot be productive. The edge systems, when kept up and running during these downtime scenarios, help to bolster business continuity.
Advertisement: Schneider Electric

In order to enhance critical edge application availability, several best practices are recommended:
Enhanced security – When you enter some of these server rooms and closets, you typically see unsecured entry doors and open racks (no doors). To enhance security, equipment should be moved to a locked room or placed within a locked enclosure. Biometric access control should be considered. For harsh environments, equipment should be secured in an enclosure that protects against dust, water, humidity, and vandalism. Deploy video surveillance and 24 x 7 environmental monitoring.
Dedicated cooling – Traditional small rooms and closets often rely on the building’s comfort cooling system. This may no longer be enough to keep systems up and running. Reassess cooling to determine whether proper cooling and humidification requires a passive airflow, active airflow, or a dedicated cooling approach.
DCIM management – These rooms are often left alone with no dedicated staff or software to manage the assets and to ensure downtime is avoided. Take inventory of the existing management methods and systems. Consolidate to a centralised monitoring platform for all assets across these remote sites. Deploy remote monitoring when human resources are constrained.
Rack management – Cable management within racks in these remote locations is often an after-thought, causing cable clutter, obstructions to airflow within the racks, and increased human error during adds/moves/changes. Modern racks, equipped with easy cable management options can lower unanticipated downtime risks.
Redundancy – Power (UPS, distribution) systems are often 1N in traditional environments which decreases availability and eliminates the ability to keep systems up and running when maintenance is performed. Consider redundant power paths for concurrent maintainability in critical sites. Ensure critical circuits are on emergency generator. Consider adding a second network provider for critical sites. Organise network cables with network management cable devices (raceways, routing systems, and ties). Label and colour-code network lines to avoid human error.
A systematic approach to evaluating small remote data centres is necessary to ensure greatest return on edge investments. Schneider Electric White Paper 256, “Why Cloud Computing is Requiring us to Rethink Resiliency at the Edge” provides a simple method for organising a scorecard that allows IT managers to evaluate the resiliency of their edge environments.
Wendy Torell is a Senior Research Analyst at Schneider Electric’s Data Center Science Center. In this role, she researches best practices in data center design and operation, publishes white papers & articles, and develops TradeOff Tools to help clients optimize the availability, efficiency, and cost of their data center environments. She also consults with clients on availability science approaches and design practices to help them meet their data center performance objectives. She received her bachelor’s of Mechanical Engineering degree from Union College in Schenectady, NY and her MBA from University of Rhode Island. Wendy is an ASQ Certified Reliability Engineer.
By Michelle Reid, Board Director, Telehouse Europe
The hyper-connected economy - where people, places, organisations and objects are linked together as never before, presents data centre providers with both opportunities and challenges. The market for new facilities is on a sustained upward trajectory, and predicted to be worth $32.3 billion by 2020(1). The popularity of mobile video services, the emergence of new business models based around the Internet of Things, and the widespread use of cloud services is underpinning strong demand for data storage and transmission, leading to the construction of a string of new data centres around the world. These new facilities are tasked with meeting an ever-growing requirement for connectivity, resilience and scalability, across diverse platforms and partners.

The architecture of today’s data centres needs to be specifically designed to meet customer demands for connectivity, guaranteeing an environment that is resilient, secure, and provisioned with low-latency links to a wide range of business partners.
The different architectural models meeting this demand come in two forms. Large cash-rich organisations such as Facebook, Amazon, Microsoft and Apple have invested in gigantic new facilities costing hundreds of millions of dollars.
The market for colocation centres, meanwhile, where equipment, space and bandwidth are available for rent to retail customers, continues to thrive. These two strands of data centre provision combine to make a flourishing sector where investment levels remain robust.
Indeed, the data explosion shows no signs of abating, driven by several key factors. These include: insatiable demand for mobile video services delivered through social media platforms and Over the Top (OTT) players; the emergence of new business models based around the Internet of Things; the shift from locally managed hardware to cloud computing and the adoption of more complex data privacy legislation across the European Union.
While demand for data storage is likely to remain buoyant, rapidly-evolving communication technologies are likely to require new thinking around data centre architectures. Predicted trends include the emergence of so-called ‘edge’ data centres, with the potential to provide enterprises that have a highly distributed customer base faster access to applications and even more processing power.
Advertisement: 8Solutions

The growth of mobile content, cloud services, and the emergence of IoT-enabled networks in both consumer and industrial sectors, means the ‘edge’ of data centres needs to be closer to users in order to reduce latency and increase the cost efficiencies of data transfer.
First and foremost, it’s about visual networking - where video streaming, high-speed networks, and interactivity come together to allow consumers to communicate, share or receive information over the Internet, when, where and how the user wants it. Visual networking has become one of the most dominant trends of modern times, transforming in a very short space of time video content from long-form movies and broadcast television programming to a database of segments or ‘clips’ and social network annotations.
These days, individuals and businesses are actively pursuing new combinations of video and social networking across a wide range of entertainment and communications. This is resulting in the creation of unprecedented amounts of data that need to flow across networks reliably, predictably and with low-latency.
A Visual Networking Index, produced by networking equipment specialist Cisco, tracks and forecasts the impact of visual networking applications, revealing the data challenge that lies ahead. The latest version of the Visual Networking Index (See Figure 1), produced earlier this year, predicts annual global IP traffic will pass the zettabyte (ZB), equivalent to 1,000 exabytes (EB) or 1 billion terabytes (TB), threshold by the end of 2016, and will reach 2.3 ZB per year by 2020.
Overall, IP traffic will grow at a compound annual growth rate of 22 per cent from 2015 to 2020, while monthly IP traffic will reach 25 GB per capita by 2020, up from 10 GB per capita in 2015. The growth of global cloud traffic has sky rocketed over the course of the past five years and Cisco predicts that cloud traffic will be responsible for 92% of all data centre traffic by 2020(2).
Cloud service providers need to offer a service that is ‘always on’ and is hosted in a secure environment that enables low latency access to enterprise customers in the most efficient manner possible.
Data centre providers have been tasked with meeting this buoyant demand, particularly through the provision of highly connected data centre facilities which offer an eco-system of business partners and organisations.
The above market shifts are key drivers of the hyper-connected economy and are placing huge pressure on data centre infrastructure, with companies racing to add extra capacity, scalable bandwidth, scalable high density power options and true redundancy. This activity is illustrated by KDDI-owned Telehouse Europe, which in 2016, launched the first phase of Telehouse North Two, its new data centre in London, deliver clients 24,000 sq. m of gross area across an 11-storey building located in Telehouse’s existing Docklands campus. This expansion takes its overall footprint in London to more than 73,000 sq. m. North Two is fully integrated within the Docklands campus, enabling established customers and new clients to make the most of connectivity across the wider site and cross its interconnected network of 48 data centres worldwide.
Connectivity and High Density/Future proof power is key to data centre performance
In conclusion, it’s clear that the hyper-connected economy is underpinning a vibrant data centre sector, with plenty of scope for global growth. The rapid pace of technological advancement in areas such as mobile video services, cloud computing and the emergence of the Internet of Things means that the requirement for resilient data storage and transmission is being propelled forward at an unprecedented rate.
The challenge, for data centre providers, is to ensure that they have the capacity and the flexibility to meet customers’ needs, increasing the requirement for connectivity – both in terms of access to application platforms and partners as well as high density power options to meet ever growing, power demanding, virtualisation and cloud based services. It’s only through the continued investment in modern, efficient data centre infrastructure that the hyper-connected economy will reach its full potential.
Further reading
http://www.marketsandmarkets.com/PressReleases/data-center-construction.asp
http://www.datacenterdynamics.com/content-tracks/colo-cloud/research-cloud-to-be-responsible-for-92-percent-of-data-center-traffic-by-2020/97297.article
By Giordano Albertazzi, President EMEA, Vertiv
In 2016, global macro trends significantly impacted the industry, with new cloud innovations and social responsibility taking the spotlight. As cloud computing has integrated even further into IT operations, the focus will move to improving underlying critical infrastructure as businesses look to manage new data volumes. Vertiv believe that 2017 will be the year that IT professionals will invest in future-proofing their data centre facilities to ensure that they remain nimble and flexible in the years to come.

Here are the key infrastructure trends we see shaping the data centre ecosystem in 2017:
However, while energy efficiency remains a core concern, water consumption and refrigerant use are important considerations in select geographies. Data centre operators are tailoring thermal management based on location and resource availability, and there has been a global increase in the use of evaporative and adiabatic cooling technologies which deliver highly efficient, reliable and economical thermal management. Where water availability or costs are an issue, waterless cooling systems such as pumped-refrigerant economisers have gained traction.
Advertisement: Riello UPS
While data breaches continue to garner the majority of security-related headlines, security has become a data centre availability issue as well. As more devices get connected to enable simpler management and eventual automation, threat vectors also increase. Data centre professionals are adding security to their growing list of priorities and beginning to seek solutions that help them identify vulnerabilities and improve response to attacks. Management gateways that consolidate data from multiple devices to support DCIM are emerging as a potential solution. With some modifications, they can identify unsecured ports across the critical infrastructure and provide early warning of denial of service attacks.
Technology integration has been increasing in the data centre space for the last several years as operators seek modular, integrated solutions that can be deployed quickly, scaled easily and operated efficiently. Now, this same philosophy is being applied to data centre development. Speed-to-market is one of the key drivers of the companies developing the bulk of data centre capacity today, and they’ve found the traditional silos between the engineering and construction phases cumbersome and unproductive. As a result, they are embracing a turnkey approach to data centre design and deployment that leverages integrated, modular designs, off-site construction and disciplined project management.
For businesses looking to stay competitive and seamlessly transition to new, cloud based technologies, the strength of their IT infrastructure continues to be the cornerstone of success. With data volumes rapidly rising, IT infrastructures will continue to evolve throughout 2017 to offer faster, more secure and more efficient services needed to meet these new demands. Investment in the right infrastructure – not just a new infrastructure – is essential. It’s therefore vital that a partner with a strong history of data centre operations is involved throughout the system upgrade – from planning and design, to project management and ongoing maintenance and optimisation.
By Amanda McFarlane, Marketing & PR Executive, The DCA
Data Centres North 14 – 15 February, Manchester
The DCA team spent a productive two days at Data Centre North, Emirates Old Trafford. The show comprised of an exhibition, a conference programme and networking event. Our CEO, Steve Hone, chaired sessions on ‘Broadening the Data Centre Offering’ by Mike Kelly from Datacentred, ‘What Brexit means to the Data Centre Sector’ by Emma Fryer from Tech UK and ‘Data Sovereignty Update’ by Mark Bailey from Charles Russell Speechlys, the sessions were well attended and provoked some great questions from the audience. The atmosphere was buzzing after a superbly organised evening dinner with
the networking continuing into the small hours!

The DCA – Data Centre Sector Update Seminar 14 March, London, Excel
The day before Data Centre World (DCW) on 14 March, The DCA Trade Association will be hosting an update seminar. Registration opens at 12.00pm, the programme comprises of four 45 min sessions finishing at 4.30pm.
Sessions include an update on Standards, EU Projects, Public Affairs and a dedicated focus on Workforce Development to help address the growing skills gap in the sector. The update is followed by networking at The Fox pub. Please visit the DCA website for details and to register.
Data Centre World
15 – 16 March, London, Excel
Approximately 10,000 Data Centre professionals attended this event in 2016 and its predicted to be even bigger this year. Once again it is being held at the Excel in London’s Docklands. Data Centre World is co-located with Cloud Expo Europe which this year are in separate halls. These two shows combined make DCW one of the largest and best attended technology events on the world.
One of the highlights this year is sure to be the DCW Live Green Data Centre which was first introduced last year and it promises to be even bigger this year.
DCS Awards - 11 May 2017, London
The DCS Awards are designed to reward the product designers, manufacturers, suppliers and providers operating in data centre arena.
The Awards recognise the achievements of the vendors and their business partners and this year encompass a wider range of project, facilities and information technology award categories designed to address all of the main areas of the datacentre market in Europe.
The editorial staff at Angel Business Communications validate entries and announce the final short list to be forwarded for voting by the readership of the Digitalisation World stable of publications during March and April. The winners will be announced at a gala evening on 11 May at London’s Grange St Paul’s Hotel. Nomination is free of charge and all entries must feature a comprehensive set of supporting material in order to be considered for the voting short-list.
Advertisement: The Data Centre Alliance

EDIE Live 2017
23 – 24 May, NEC, Birmingham
EDIE 2017 is an annual two-day exhibition and conference attracting thousands of energy, sustainability and resource efficiency professionals. The DCA are excited to be sponsoring and attending this event for this first time this year. Our objective is to meet with our members end users, to help promote members and the data centre sector as a whole.
Data Centre World
24 – 25 May 2017, Hong Kong
The DCA are confirmed as event partners for DCW Hong Kong. Our Ambassadors (based in Hong Kong) are Andrew Green and Barry Lewington of PTS Consulting. Andrew is planning to speak on Energy Efficiency case study and to also talk about the value PTS has gained from its collaboration with the DCA.
Data Centre Transformation
11 July 2017, Manchester
The DCA will again be partnering with Data Centre Solutions and Leeds University to organise and host the 2017 Data Centre Transformation Conference on the 11th July 2017. In 2016 we introduced a completely new workshop format which was refreshingly different from the more traditional conference format. This was such a great success that the format will be repeated again this year. Workshops will have a theme that is currently of importance to the industry, each being designed and moderated to ensure they are vendor neutral.
The sessions attended last year proved to be very educational with a high level of delegate interaction. Everyone the DCA spoke with felt they had a voice and
could contribute to the overall discussion. The conference format also allows ample time between the workshop sessions providing a great opportunity for delegates to follow up on the points raised in the sessions and speak to the experts. This year there will be six workshops throughout the day.
DCA Golf Tournament
14 September, Oxfordshire
The DCA Golf Tournament is scheduled to take place on the 14th September 2017 at Heythrop Park, Oxfordshire. It is the first time we have had the tournament at this course so it should be fun. This is a popular event allowing our members and partners to enter a team to play at this picturesque 18 hole course. Look out for our mailers and on our website for information on how to register.
Credentialing equates to lower risk – and lower insurance costs
There are multiple areas of potential risk in a data center environment that can cause incidents that would result in an insurance claim. Risks for a data center include accidents that damage the facility, potential for workplace injuries, and business risks from downtime events that impact the data center’s or its customers’ business continuity. By R. Lee Kirby, President of Uptime Institute and Stephen F. Douglas, Risk Control Director for CNA – Technology.


When insurers and underwriters evaluate a data center organization for coverage, they want to be certain that the risk profile of the facility is as low as possible. Considerations such as fire resistance are a component of assessing data center risk, but focusing only on facility risks leaves out the most important part of the picture.
It would be like insuring an automobile based solely on the quality of the vehicle design and manufacture, but failing to ascertain if a licensed driver is operating it.
In today’s global economy, data centers are critical. Organizations depend on 24 x 7 x 365 IT infrastructure availability to ensure that services to customers/end-users are available whenever they are needed. To provide and maintain this availability is not only a matter of designing and building the right facility infrastructure—it’s about how that facility is managed and operated on a day-to-day basis to safeguard the business-critical infrastructure.
Owners and operators must do what they can to ensure that the risk of incidents and downtime has been minimized, and prove this low risk profile to their insurers. Industry-recognized credentials can help validate that operating risks are being managed effectively.
Relying solely on the physical characteristics of the data center such as the construction, type of fire protection system, and proximity to flood and earthquake-prone areas; although important, leaves out very important considerations in evaluating the effectiveness of a service provider’s risk management program. Typically, the redundant infrastructure of engineered data centers does present a low frequency of loss when compared to other types of operations. However, there is a significant increase in reliance on these data centers by end users as more companies outsource to the cloud or house their primary or backup networks offsite. This increasing dependency of end users on a centralized, outsourced infrastructure presents opportunities for technology service providers to set themselves apart from the competition and manage risks by formally addressing operational controls.
In framing the risks that service providers are exposed to—and that insurers will be concerned with—it is important to view the operation in terms of what part of the “data supply chain” the service provider occupies or is responsible for. Infrastructure providers, such as a co-location provider, have a specific but related set of exposures as compared to a software as a service (SaaS) provider at the other end of supply chain. The various entities in these increasingly complex supply chains must make decisions about the viability of accepting, avoiding, mitigating or transferring these risks. The risks to the data supply chain include not only first party direct losses, but third party liability losses as well. Even the first party losses will differ based on the services provided. The primary risks to the data supply chain can be categorized as:
Regulations – regulations create compliance risks at all levels of the data supply chain. Regulatory impact is greatly dependent on the types of services offered, industries served, and the complex shared responsibilities of infrastructure and service providers and their clients. Just a few examples of regulatory frameworks that may have impact even down to the infrastructure level include U.S. regulations such as HIPAA, GLBA, FISMA; international regulations such as the EU Data Protection Directive and industry standards such as the PCI DSS. In these complex regulatory environments, regulatory enforcement actions are common and the impact of fines and penalties is growing.

From 20 years of collecting incident data, Uptime Institute has determined that human error (i.e., bad operations) is responsible for approximately 70% of all data center incidents. Compared to this, the threat of “fire” (for example) as a root cause is dwarfed: data shows only 0.14% of data center losses are due to fire. In other words, bad operations practices are 500 times more likely to negatively impact a data center than fire. An outage at a mission critical facility can result in hundreds of thousands of dollars or more in losses for everything from equipment damage and worker injuries to lost business and penalties for failure to maintain contractual Service Level Agreements.
For both data center operators and insurers, there are some key questions to ask:
As discussed above, increased outsourcing, flexible cloud architecture, and resilient network infrastructures are creating increasing dependency on third party providers at all levels of the data supply chain. This increased dependency is creating greater liability risk for service providers.
Managing liability risks starts with contracts. A clear scope of work and allocation of risk between the contracting parties is essential. Clauses such as service level agreements, limitation of liability, force majeure, wavier of subrogation and indemnification wording reinforce the intended allocation of risk. Complex multiparty contract disputes are common particularly when significant losses are incurred. Claims of negligence are non-contractual, so even well executed contracts may not mitigate significant liability losses.
Data center operations credentials are another means of mitigating liability risks. In addition to reducing the probability of loss, clearly defined repeatable procedures and processes demonstrate adhering to a duty of care that is foundational to most standards of care. As with any human endeavor, residual risk will remain regardless of mitigation efforts. Insurance provides a means of risk transfer particularly effective on high severity risks.
Uptime Institute has provided data center expertise for more than 20 years to mission-critical and high-reliability data centers. It has identified a comprehensive set of evidence-based methods, processes, and procedures at both the management and operations level that have been proven to dramatically reduce data center risk, as outlined in the Tier Standard: Operational Sustainability.
Organizations that apply and maintain the Standard are taking the most effective actions available to protect their investment in infrastructure and systems and reduce the risk of costly incidents and downtime. The elements outlined in the Standard have been developed based on the industry’s most comprehensive database of information about real-world data center incidents, errors, and failures: Uptime Institutes’ Abnormal Incident Reporting System (AIRS). Many of the key Standards elements are based on analysis of 20 years of AIRS data collected on thousands of data center incidents, pinpointing causes and contributing factors.
To assess and validate whether a data center organization is meeting this operating Standard, Uptime Institute administers the industry’s leading operations certifications. These independent, third-party credentials signify that a data center is managed and operated in a manner that will reduce risk and support availability. There are two types of operations credentials: Tier Certification of Operational Sustainability (TCOS) and The Management & Operations (M&O) Stamp of Approval.
Both credentials are based on the same rigorous Standards for data center operations management, with detailed behaviors and factors that have been shown to impact availability and performance. The Standards encompass all aspects of data center planning, policies and procedures, staffing and organization, training, maintenance, operating conditions, and disaster preparedness.
The data center environment is never static; continuous review of performance metrics and vigilant attention to changing operating conditions is vital. The data center environment is so dynamic that if policies, procedures, and practices are not revisited on a regular basis, they can quickly become obsolete. Even the best procedures implemented by solid teams are subject to erosion. Staff may become complacent, or bad habits begin to creep in.
There is tremendous value for organizations that hold themselves to a consistent set of standards over time, evaluating, fine tuning, and retraining on a routine basis. This discipline creates resiliency, ensuring that maintenance and operations procedures are appropriate and effective, and that teams are prepared to respond to contingencies, prevent errors, and keep small issues from becoming large problems.
Insurance is priced competitively based on the insurers assessment of the exposure presented. Data center operations credentials provide the consistent benchmarking of an unbiased third party review that can be used by service providers at all levels of the data supply chain to demonstrate the quality of the organization’s risk management efforts. This demonstration of risk quality allows infrastructure and service providers to obtain more competitive terms and pricing across their insurance programs.
When data centers obtain the relevant Uptime Institute credential, it results in a level of expert scrutiny unmatched in the industry, giving insurance companies the risk management proof they need. Insurers can validate risk level to a consistent set of reliable Standards. As a result, facilities with good operations, as validated by TCOS or M&O Stamp of Approval, can benefit from reduced insurance costs.

Experience all the key technologies for the digital transformation in one place – at CeBIT in Hannover!
What was pure science fiction just a few years ago has become reality today and limitless business opportunities lie ahead.
CeBIT is the world’s foremost event on the wave of digitalization revolutionizing every aspect of business, government and society. Every year, the show features a lineup of around 3,000 exhibitors and attracts some 200,000 visitors to its home base in Hannover, Germany. The spotlight is on all the latest advances in fields such as artificial intelligence, autonomous systems, virtual and augmented reality, humanoid robots and drones.
Thanks to a rich array of application scenarios, CeBIT makes digitalization tangible in the truest sense of the word. “d!conomy – no limits”, the chosen lead theme for 2017, underscores the show’s emphasis on revealing the wealth of opportunities arising from the digital transformation. As a multifaceted exhibition/conference/networking event, CeBIT is a perennial must for everyone involved in the digital economy. The startup scene is also right at home at CeBIT and its dedicated SCALE 11 showcase, which sports more than 400 aspiring young enterprises.
The next CeBIT will be staged next month from 20 to 24 March 2017, with Japan as its official Partner Country and, on 19 March, Shinzo Abe, the Prime Minister of this year’s Partner Country, Japan, and German Chancellor Angela Merkel will officially open CeBIT 2017 in the presence of more than 2,000 VIP guests at the Welcome Night ceremony in Hall 9 of the Hannover Exhibition Center. The Partner Country, alone, is fielding around 120 companies to appear in every segment of the show.
Artificial intelligence, humanoid robots, virtual reality: new technologies are constantly pushing the boundaries of what is possible. What does this mean for society, the economy and concretely for your company? What new business models bring the most value? Dive into the fascinating digital future – at the world's biggest digitization showcase and experience all the big digital trends and highlights:
The integration of a trade show with a complementary conference program not only creates the ideal setting for generating new business, but also facilitates effective networking and a cross-industry knowledge transfer and dialogue between experts.
We have secured a limited number of complimentary exhibition tickets - Click here to get yours! (link: http://www.cebit.de/promo?qgpew
The CeBIT Global Conferences
#cgc17 will revolve around the slogan "Explore the Digital World!". The five day conference will delve deep into the realms of artificial intelligence, cyborgs & biohacking, robots, virtual worlds, the Darknet and cybercrime. The conferences in hall 8 bring together IT suppliers and users, Internet firms and investors, as well as creative and future-oriented thinkers.
This year’s conferences boast a truly stellar line-up of speakers. Among the big names are Google engineer and futurist Ray Kurzweil, the famed roboticist Hiroshi Ishiguro, and Stanford professor and social researcher Michal Kosinski. An expert in psychometrics, Kosinski has developed a mathematical method that analyzes Facebook likes and other publicly available data to determine people’s personality traits. The speaker list also includes someone who is arguably the world’s most famous whistleblower – Ed Snowden. Snowden will be joining the proceedings via live stream from Moscow.
Purchase your ticket to the CeBIT Global Conference http://www.cebit.de/en/conferences-events/cebit-global-conferences/cgc-tickets/
For more information visit www.cebit.de
However, there is something of a mystique surrounding these different data center components, as many people don’t realize just how they’re used and why. In this pod of the “Too Proud To Ask” series, we’re going to be demystifying this very important aspect of data center storage. You’ll learn:•What are buffers, caches, and queues, and why you should care about the differences?
•What’s the difference between a read cache and a write cache?
•What does “queue depth” mean?
•What’s a buffer, a ring buffer, and host memory buffer, and why does it matter?
•What happens when things go wrong?
These are just some of the topics we’ll be covering, and while it won’t be exhaustive look at buffers, caches and queues, you can be sure that you’ll get insight into this very important, and yet often overlooked, part of storage design.
Recorded Feb 14 2017 64 mins
Presented by: John Kim & Rob Davis, Mellanox, Mark Rogov, Dell EMC, Dave Minturn, Intel, Alex McDonald, NetApp

Advertisement: Cloud Expo Europe

Converged Infrastructure (CI), Hyperconverged Infrastructure (HCI) along with Cluster or Cloud In Box (CIB) are popular trend topics that have gained both industry and customer adoption. As part of data infrastructures, CI, CIB and HCI enable simplified deployment of resources (servers, storage, I/O networking, hardware, software) across different environments.
However, what do these approaches mean for a hyperconverged storage environment? What are the key concerns and considerations related specifically to storage? Most importantly, how do you know that you’re asking the right questions in order to get to the right answers?
Find out in this live SNIA-ESF webcast where expert Greg Schulz, founder and analyst of Server StorageIO, will move beyond the hype to discuss:
· What are the storage considerations for CI, CIB and HCI
· Fast applications and fast servers need fast server storage I/O
· Networking and server storage I/O considerations
· How to avoid aggravation-causing aggregation (bottlenecks)
· Aggregated vs. disaggregated vs. hybrid converged
· Planning, comparing, benchmarking and decision-making
· Data protection, management and east-west I/O traffic
· Application and server I/O north-south traffic
Live online Mar 15 10:00 am United States - Los Angeles or after on demand 75 mins
Presented by: Greg Schulz, founder and analyst of Server StorageIO, John Kim, SNIA-ESF Chair, Mellanox

The demand for digital data preservation has increased drastically in recent years. Maintaining a large amount of data for long periods of time (months, years, decades, or even forever) becomes even more important given government regulations such as HIPAA, Sarbanes-Oxley, OSHA, and many others that define specific preservation periods for critical records.
While the move from paper to digital information over the past decades has greatly improved information access, it complicates information preservation. This is due to many factors including digital format changes, media obsolescence, media failure, and loss of contextual metadata. The Self-contained Information Retention Format (SIRF) was created by SNIA to facilitate long-term data storage and preservation. SIRF can be used with disk, tape, and cloud based storage containers, and is extensible to any new storage technologies.
It provides an effective and efficient way to preserve and secure digital information for many decades, even with the ever-changing technology landscape.
Join this webcast to learn:
•Key challenges of long-term data retention
•How the SIRF format works and its key elements
•How SIRF supports different storage containers - disks, tapes, CDMI and the cloud
•Availability of Open SIRFSNIA experts that developed the SIRF standard will be on hand to answer your questions.
Recorded Feb 16 10:00 am United States - Los Angeles or after on demand 75 mins
Simona Rabinovici-Cohen, IBM, Phillip Viana, IBM, Sam Fineberg

SMB Direct makes use of RDMA networking, creates block transport system and provides reliable transport to zetabytes of unstructured data, worldwide. SMB3 forms the basis of hyper-converged and scale-out systems for virtualization and SQL Server. It is available for a variety of hardware devices, from printers, network-attached storage appliances, to Storage Area Networks (SANs). It is often the most prevalent protocol on a network, with high-performance data transfers as well as efficient end-user access over wide-area connections.
In this SNIA-ESF Webcast, Microsoft’s Ned Pyle, program manager of the SMB protocol, will discuss the current state of SMB, including:
•Brief background on SMB
•An overview of the SMB 3.x family, first released with Windows 8, Windows Server 2012, MacOS 10.10, Samba 4.1, and Linux CIFS 3.12
•What changed in SMB 3.1.1
•Understanding SMB security, scenarios, and workloads•The deprecation and removal of the legacy SMB1 protocol
•How SMB3 supports hyperconverged and scale-out storage
Live online Apr 5 10:00 am United States - Los Angeles or after on demand 75 mins
Ned Pyle, SMB Program Manager, Microsoft, John Kim, SNIA-ESF Chair, Mellanox, Alex McDonald, SNIA-ESF Vice Chair, NetApp

•Why latency is important in accessing solid state storage
•How to determine the appropriate use of networking in the context of a latency budget
•Do’s and don’ts for Load/Store access
Live online Apr 19 10:00 am United States - Los Angeles or after on demand 75 mins
Doug Voigt, Chair SNIA NVM Programming Model, HPE, J Metz, SNIA Board of Directors, Cisco


It had to come one day. After the initial and growing adoption of 10G Fibre Channel over Ethernet (FCoE) since the end of 2008, it was just a matter of time before the market introduction of the next speed level would materialize.
By Fausto Vaninetti, SNIA Europe Board Member.

The first switch capable of 40G FCoE appeared in the middle of 2013 but during 2016 a wider portfolio of 40G FCoE capable devices was brought to commercial fruition by some vendors. At first sight, 40G FCoE may seem just a speed bump as compared to its predecessor but a closer look shows a different story.
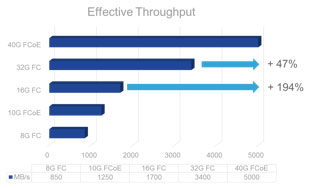
The original idea behind FCoE was network convergence and that is why FCoE technology started with 10G and not 1G bit rate. Having a single adapter, a single cable, a single switch for both LAN and SAN traffic seemed a good idea in terms of lowering cost and reducing administrative burden. When FCoE was first introduced, 8G Fibre Channel (FC) technology was already available but majority of deployments were still only using 4G FC. As a result, a 10G pipe offered a nice consolidation opportunity by bringing together native Ethernet traffic with Ethernet-encapsulated Fibre Channel traffic.
A few years after the availability of 10G FCoE capable adapters and switches, 16G FC became available. The convergence benefit provided by FCoE technology was still there, but the bandwidth advantage that FCoE could offer on top of 8G FC was now lost in favor of 16G FC. As a result, 10G FCoE saw a slowdown in adoption and remained confined to the place where it still makes a lot of sense: the access network. As a proof point of this, many blade chassis are nowadays sold with some type of embedded FCoE connectivity. This choice appears convenient since it reduces network adapter’s footprint on blade servers, minimizes cabling and shaves out overall cost. Rack mount servers, instead, are mostly sold with separate Ethernet and Fibre Channel adapters. As of now, market research indicates Fibre Channel traffic out of servers is using converged network adapters in approximately 30% of cases, leaving the rest to native FC host bus adapters.
Advertisement: Vertiv
The tangible savings when adopting FCoE are mostly coming from consolidation in the access, where server nodes connect to the network edge, but when you need to interconnect switches or connect to disk arrays, or simply when there is no interest in network convergence, 16G FC has won the majority of deployments. This is not to say 10G FCoE cannot be used for end-to-end multi-hop solutions, but not many organizations have embraced that deployment option.
The introduction of 40G FCoE could change the scenario again. In fact, 40G FCoE is supported by both switches and modular platforms and could fit organizations of different sizes. It also offers three times the bandwidth of 16G FC for approximately twice the price, so that it captures attention in terms of cost/Gbps ratio. All in all, when cabling simplification is accounted for, the total cost of ownership of 40G FCoE becomes even more interesting.
This means the window of opportunity for 40G FCoE is not going to reach an end when 32G FC will grow in popularity and both protocols are expected to be seen in use within datacenters.
With the continuous increase in processing power within compute nodes, bandwidth needs on servers keeps growing. Between 2015 and 2017, cloud service providers are expected to double their virtual machine density per host in order to improve their profitability. At the same time, new applications within enterprises will leverage the newly available processing power to push network needs beyond 10G. When consolidation is a priority, 40G adapters are more than adequate for transporting modern Data Center traffic and can be a valid alternative to deploying separate 16/32G FC HBAs and 10/40G NICs. As a result, since their commercial introduction in 2015, 40G FCoE converged network adapters have experienced a slowly growing market penetration.
With the continuous increase in processing power within compute nodes, bandwidth needs on servers keeps growing. Between 2015 and 2017, cloud service providers are expected to double their virtual machine density per host in order to improve their profitability.
At the same time, new applications within enterprises will leverage the newly available processing power to push network needs beyond 10G. When consolidation is a priority, 40G adapters are more than adequate for transporting modern Data Center traffic and can be a valid alternative to deploying separate 16/32G FC HBAs and 10/40G NICs. As a result, since their commercial introduction in 2015, 40G FCoE converged network adapters have experienced a slowly growing market penetration.
However, the future is a bit uncertain. The combined effect of an increased price pressure, real aggregate bandwidth needs out of servers and newly introduced network speeds are possibly casting a shadow on 40G adoption. In fact, chances are that 25G will be the next speed on servers after 10G becomes insufficient. The consequence of this explains why the sweet spot for 40G FCoE seems to be as a technology to interconnect network devices more than anything else. If 10G FCoE became notorious for convergence in the access network, 40G FCoE could become popular to interconnect the edge of networks to the core, leveraging the high bandwidth it can deliver. This approach seems very reasonable for IT departments that already embraced FCoE in the access but could be viable also for organizations that are relying on a native FC access network.
As bit rate increases, the complexity of circuitry, modulated light transmitters and receivers will grow and consequently another important aspect will influence decisions: the cost of the transceiver itself as compared to the cost of a network port on a switch. A multimode transceiver at 16G FC can be approximately 20-40% of the cost of a 16G FC port on a switch. These pricing considerations will have an impact on the speed of adoption for 32G FC transceivers on both servers and switches, but for sure they will not impede their use on inter switch links even during the initial ramp up phase for the higher bit rate. Moreover, 32G FC is expected to enjoy a growing success on the storage side as well. In many cases, network devices and disk arrays are not refreshed at the same time and there is a need for the newly purchased equipment to be able to work with the existing installed base. From this point of view, the main feature that will drive 32G FC adoption in place of the 40G FCoE approach will be its backward compatibility with 8G and 16G FC ports.
It is never easy to make predictions, but do not be surprised if during 2017 the situation for new deployments will see 10G FCoE remaining popular in the access and 40G FCoE and 32G FC both gaining traction for networking devices interconnection and trending up elsewhere. Rather than competing solutions, they seem to be the two faces of the same coin, clear representation of reliable, scalable, deterministic storage networking options.

DW talks to Paul Smethurst, Managing Director of Hillstone Products, to understand the research and subsequent development work that has led to the recent launch of the new GENSET_loadbank range, a permanent load bank solution, – helping to reduce energy costs and increase reliability in the data centre.

Q: Please can you give us some background on Hillstone’s involvement in the data centre industry/with load banks over the past few years?
A: I can pin point four important events fundamental to establishing Hillstone at the forefront of load banks that are used today worldwide in the datacentre industry.
The first dates back ten years to 2007 when we were approached by British Telecom who wanted to rent a number of rack mounted server simulator load banks. We found a clean sheet of paper and a pencil to design the 3RM, a 3kW Rack Mounted load bank.
The second significant development was in 2009 with a request from Telecity to purchase a total of 2000kW of rack load banks for testing a new large empty white space data hall. Our design team created the 6RM, a single phase and three phase server simulator with granular heat dissipation and adjustable delta T from 5oC to 20oC. Then, to overcome not having any available cabinets, we designed the 20kW mini-tower
In 2010 when the BBC’s new home at Media City in Salford needed load banks for IST commissioning, Hillstone were ideally placed 20 minutes down the road to heat load the studios and datacentre. The project was delivered with support from our datacentre testing team to Bovis Lend Lease & NG Baileys.
The fourth was also down to being ideally placed, but this time overseas in Dubai, where the previous 12 years in Middle East sales travel resulted in establishing Hillstone Middle East in 2012. Our appointment by Blackberry and regional telecom operators Etisalat, DU, Mobily & STC for IST services allowed datacentres in Dubai and Saudi Arabia to also obtain Uptime Certification.
Q: And what prompted the recent research into why a datacentre needs a permanent load bank?
A: I shared a power workshop with Ian Bitterlin at the Datacentre Transformed Conference in Manchester July 2016 and it was his matter of fact statement that every datacentre needs a load bank which prompted my questioning of “why?“ and also how can this increase my sales of load banks?
Q: And what did the research reveal?
A: Of course, Ian was correct! and the research has increased sales, but the most significant findings are that datacentres’ can reduce energy costs and improve reliability by installing a load bank, alongside our wider understanding of fuel being the single point of failure and the impact of running on a low IT load.
Q: And this research has led to the creation of the GENSET_loadbank range?
A: From a commercial point of view the research has allowed the re-branding of our load bank ranges with a focus to application specific branding. Therefore the GENSET_loadbank range is for permanently installed load banks used with generator systems.
The important features within the GENSET_loadbank range are the ability to allow auto-regulation of load when the genset is running and also to allow manual control during planned maintenance, which are both very important datacentre requirements.
Q: This range is designed to prevent breaches in Service Level Agreements (SLAs) and warranty conditions?
A: There is nothing new in warranty conditions for running a generator and it is not specific to datacentres to require the genset to run at load of at least 40%. So unless the datacentre has a permanent load bank running on a genset to compensate for low IT load the facility will either breach the SLA or include a high premium for additional maintenance and servicing which in turns reduces reliability and uptime.

Q: And to overcome fuel being the singular point of failure in the data centre?
A: This was a great find of the research and really it is a very simple concept in so much that with a permanently installed load bank the genset will burn fuel from both the day tanks and the belly tank every time it is running.
So if the Standard Operating Procedure ( SOP ) is for a weekly test to make sure the genset battery will start, the genset, then the load bank, will pull fuel though the fuel system and the generator be exercised under load.
This will therefore cycle the fuel and prevent bad fuel materialising with or without a fuel polishing system.
Q: And this is achieved by maintaining best practice expected in mission critical data centre infrastructure?
A: Yes. Because datacentres are the factories for tomorrow’s world they have been designed with the importance of mission critical power systems which must require the implementation of best practice for operation and maintenance procedures. So, with a genset having a basic requirement of running on a load of at least 40%, and today’s datacentres having low IT load, the only best practice we can implement is to install a permanent load bank on the generator system.
Q: And this therefore prevents the costs of wet stacking?
A: Wet stacking is the expensive mistake of running the genset on low load, so with less than 40% load the engine will not reach the optimum (or design ) running temperature. This results in un-burnt fuel deposits and carbon build up in the engines cylinders. Whilst normal genset users may solve this problem during annual load bank maintenance, the datacentre genset cannot chance the risk of failure or the extra costs of downtime for extended servicing, such as engine strip down
Q: And how does the GENSET_loadbank range help to increase load bank reliability?
A: Reliability is a function of uptime which is obviously the inverse of downtime. If the weekly ‘genset start STOP’ validates the fuel supply and the genset is running as per warranty and SLA conditions and if the maintenance downtime on the genset is reduced all by installing a load bank on generator system, then the datacentre increases its reliability.
Q: And how does it help reduce energy costs?
A: Having a permanently installed load bank allows energy efficiencies in the mechanical cooling systems to be implemented effectively and responsively to low IT load. Therefore, the reliance of using the full mechanical load to contribute to the loading on the genset is no longer needed and the annual savings in power usage will be reflected against the datacentre PUE.
Q: And what is the typical ROI?
A: To measure the ROI on the load bank could be presented in hours or days rather than months or years because if the genset fails so does the datacentre. An alternative view point could be in the reduction of the required maintenance or the ability to remove SLA penalty breaches or an overall reduction in SLA costs.
In monetary terms, a load bank for a 2500kVA datacentre genset system should cost less than £10,000, so a reduction of £5000 per year in load bank rental costs, maintenance service visit costs and energy saving costs will easily give an ROI of less than 1 year.
Finally, the GENSET_loadbank range works by delivering dual automatic and manual operation, and features open software that integrates with both BMS and DCIM?
The ability to integrate the load bank easily and without cost implication to the BMS or DCIM is another user focused feature of the GENSET_loadbank range. As responsible engineers, Hillstone want to lead the industry forward with low cost flexible load bank software integration that is based on simple open source principles and development for tomorrow’s modern datacentre.
DW talks to Maeve Fox, Global ITD Channel Strategy Manager, IT
Channel, IT Division APC by Schneider Electric about the new APC by
Schneider Power and Cooling Services MSP initiative, focusing on the benefits
it provides for both MSPs and their customers, with integration being a key
differentiator.

1. What’s the thinking behind the new APC by Schneider Power and Cooling Services MSP offering and, in general terms, what does this initiative offer MSPs?
Over the past several years, managed services as a business model has moved past being a niche and is now becoming the predominant model for partners in many markets in the world.
For many MSPs, buy/resell still account for much of their revenue but the main area of growth is now in attached to the more profitable managed services which many end customers require now.;
The challenge that many MSPs are facing is that the core Managed Service offerings are starting to become commoditised. So much so that we see many partners are now looking for ways in which they can further diversify both their businesses and service portfolio to create a competitive advantage and improve their opportunity for growth. This is where APC can add significant value. We have found that while almost all partners are selling power, most aren’t monetizing it in their managed services practice. Our new MSP initiative will help rectify that and prevent our partners from leaving money on the table
Schneider Electric’s MSP programme focuses primarily on the area of power and cooling services and is driven by the realisation that the managed services provision is no longer a niche activity for a number of its channel partners.
This is especially important when considering that the surrounding critical infrastructure is becoming an increasingly important element of the managed services offer, and one where channel partners can now increase the lifetime value of an uninterruptible power supply (UPS) by up to three and a half times simply by including it in a managed service contract.
2. And can you tell us a little bit about the rest of the MSP package – education, financials etc.?
Additional support offered by Schneider Electric includes a new and specific certification aimed at creating managed services around power. It certifies that company personnel have been trained in best practices on how to tailor services around UPS and power systems for the benefit of end users and best practices on how to integrate these into a broad managed services platform. There are also financial incentives available through the rewards offered via the Select Level of the programme, which is the current accreditation level for managed services partners.
Our ultimate goal is to allow partners to manage all of its connected products as part of their managed services portfolio. With an installed base world wide of some 8m units, including UPS, power distribution units (PDUs), cooling systems and NetBotz physical security systems, that provides ample opportunity for new service based revenue streams.
Advertising: DT Manchester

3. And what benefit will this MSP offering bring to the end user?
From the point of view of end users, the increasing availability of managed services covering all IT and related infrastructure products offers a number of benefits. For small and medium-sized companies, who would typically not have a dedicated IT staff in-house, managed services provide the peace of mind and convenience of knowing that all of their physical infrastructure is being monitored to maximise system availability. Typically, a company starts to build out its own IT staff when it reaches about 100-150 employees; managed services are allowing SMEs to postpone that decision until later in their maturity cycle.
The programme effectively provides the MSP customer base with a partner that’s proficient in services surrounding the entire IT stack, especially where power is concerned. As we know power is critical to all of todays businesses, therefore having one vendor that specialises in the complete solution becomes important for customers from the perspective of reliability, continuity and 24*7 availability.
In addition, larger organisations may of course have their own dedicated IT teams but they may also have a greater number of sites, some of which may be unmanned. In such cases, the traditional warning from a UPS alarm mechanism alerting management to the fact that the battery is close to expiry is of little use.
On the other hand, a network-connected UPS linked directly to a NOC and supervised by a managed service provider will provide adequate warning of a battery’s impending death, allowing timely replacement and preventing the damaging downtime that can be caused in the event of a UPS failure. Companies of all sizes can benefit, too, from the 24*7 supervision offered by a managed services contract.
4. And how does this MSP initiative compare with any being offered by other power/cooling vendors?
By far the biggest difference between our industry competitors and ourselves is through the integration piece. Many competitors are asking customers to use their software directly. However, we’re integrating our network-connected solutions into the monitoring tools our partners are using already. This saves them the onerous task of building our physical infrastructure software into their NOCs, which would require them both to purchase extra software and then train their personnel how to use it.
By minimising disruption to their current operations and following the path on which they are already travelling, we are assisting our partners to broaden their services portfolio throughout the entire IT stack.
5. Jason Covitz has been appointed as Global Director of Managed Services – this suggests that Schneider is taking this MSP initiative very seriously?
Absolutely. Between managed services and by extension Cloud services are by far the biggest shift in our partners’ business models in a very long time. Five years ago only the most progressive partners were doing managed services; now the majority are offering such services. We are supporting partners throughout this transition by aligning our business needs better to theirs.
So as more partners begin to utilise our Remote Monitoring and Management (RMM) platform, we are empowering them to monetise parts of the IT stack, such as UPS, that they were previously unable to exploit using services. Partners can now earn revenues throughout the working life of all network-connected products.
In addition the appointment of Andy Connor as the new Channel Director for the UK puts us in a great position as we continue to focus our sites on the Channel and Managed Service Providers.
6. What has been the success of the MSP programme to date and how would you like to see it develop, in terms of numbers of participants, regions covered over time?
Since the MSP programme started nine months ago we have seen a strong take up from our existing partner base. Our commitment to the programme is reflected by the fact that the launch of every new connected product now carries a focus on how we can help our partners to monetise such products as part of an on-going managed-services contract. Currently the MSP programme is active in the US, UK, Germany and Australia with plans in place to expand it into other countries, especially in Europe, throughout the year.
From what we’ve seen there were very few Managed Service Providers that are offering a complete Managed Service around Power, therefore all of our offers and opportunities for growth will be new to them and our vision is that we will continue to help our partner businesses to grow, without question.
7. Finally, Schneider has already marked itself out as a thought leader when it comes to IoT. Is this Power and Cooling Services service part of the company’s IoT focus, or viewed very much as a data centre initiative?
We very much consider it to be part of both the data centre and the IoT initiatives. As new market trends have shown, they are very much aligned. A big driver for the growth of managed services will come from the emerging market for the Internet of Things (IoT). Given the rapid growth in data centre capacity expected to attend this new trend the opportunity for additional managed services in this area is likely to be considerable.
In addition, we’re perfectly placed to help our partners solve customer challenges due to our unique connection to the Internet of Things (IoT). Not only do we have the technology to assist MSPs, but partnership with Schneider Electric will directly enable them to engage with customers outside of the IT realm.
I think it’s also important to add that partners have always been a fundamental part of our business and they will continue to be. Power is essential in today’s business and partners play a critical role in its delivery. Because of this, the partner landscape is becoming more competitive so it's now more important than ever for MSPs to build and develop the right vendor partnerships, ensuring they deliver on that promise of 24*7 availability.
According to a recent Osterman Research report, spear-phishing and ransomware attacks on businesses are on the up, with the majority of organisations – including SMBs – being victimised in the past 12 months. Unlike traditional phishing attacks, which typically broadcast spam to thousands of people, spear-phishing is a carefully crafted and highly targeted attack designed to lure recipients into downloading a malicious attachment, or clicking a link.
By Wieland Alge, VP & GM EMEA at Barracuda Networks.

The cost of opening an email that appears to be from a known individual or organisation is high. This year a report by the Federation of Small Businesses estimates cyber attacks cost the UK economy around £5.26 billion, with 37% of small firms reporting they were victims of spear-phishing scams and 29% reporting malware attacks. With limited resources, time and expertise to deal with digital attacks, small businesses appear to be bearing the brunt of this form of cyber crime.
By scouring online sources like LinkedIn and the corporate website, or phoning switchboards to ask for contact names and details, criminals will undertake research in a bid to identify specific details that will help convince targets the spoof email they receive is legitimate.
The aim of the game is to impersonate known personnel and lure recipients into verifying details or passwords via a malicious link, or opening an infected file. Worryingly, criminals are proving adept at exploiting the ‘fast response’ behaviours of employees – especially when working on the move or using instant messaging platforms.
Scammers are also using their social engineering insights to target CEOs and finance teams with ‘whaling’ scams – emails purporting to be from a supplier, overseas subsidiary or other known contact which request the immediate transfer of funds. In other cases, senior managers may receive an email designed to look like it’s been issued by a government agency in relation to unpaid taxes, fines or a customer complaint.
Advertisement: Eltek
When it comes to accessing enterprise networks, criminals will focus on finding a ‘path of least resistance’ back door entry point. This is achieved by targeting spear-phishing campaigns at smaller suppliers and contractors, whose cyber security may be less advanced, to acquire the valid access credentials needed to silently enter the network and launch an attack – stealing data, defacing websites, installing ransomware or unleashing advanced persistent threats.
There are a number of best practices organisations can employ to protect themselves against spear-phishing and ransomware.
1. Educate users
Today’s attackers target the easiest point of network vulnerability – users. Email represents a primary threat vector for many attacks, yet many users suffer information overload and are less likely to scrutinise for phishing.
Security awareness training is a key area for improving protection levels and the findings from Osterman Research confirm that organisations with well-trained employees are less likely to succumb to a spear-phishing attack. Training needs to be conducted on a regular basis, highlighting how to deal with fraud or email compromise, good email behaviours and safe practices when surfing the web.
2. Monitor and prevent
Deploy systems to detect and eliminate phishing and ransomware attempts. Monitoring software should deliver full visibility, enabling IT teams to scan email inboxes regularly and pinpoint threats to a specific device. Preventative measures – including scanning for web app vulnerabilities and existing spyware and advanced threat detection tools – should also be undertaken. Finally, to ensure a rigorous damage limitation strategy is in place, review backup procedures to ensure data across all platforms is recoverable.
3. Secure your cloud
Adopting solutions designed to work in the Cloud ensures businesses are better able to protect their users, data and assets when using cloud-based productivity suites or other hosted services. These include heuristic scanning tools that seek out commands that might indicate malicious activity, and cloud-based system emulators that open and examine files in a sandbox to prevent systems from the risk of malicious attachments.
4. Keep systems up-to-date
Every application and operating system should be regularly inspected for vulnerabilities and brought up-to-date using the latest patches from vendors. Last year, Edgescan discovered that 63% of all security vulnerabilities could have been eradicated by simply applying security updates. Without the latest update, your data is simply not protected.
5. Implement robust policies
Detail thorough policies for the email, web, collaboration, social media and other tools deployed by the IT department, ensuring these include the legal and regulatory obligations to encrypt emails and other content if these contain sensitive data. Control or manage the use of personal devices that access corporate systems, ensuring that employees are aware of the tools and applications they should use when accessing corporate resources.
No organisation can afford to ignore the growing threat of targeted cyber attacks. The multi-vector nature of these threats means putting an end-to-end strategy in place is crucial to addressing spear-phishing and ransomware threats and reducing the chances of infection.
In today’s information intensive economy, bandwidth is a critical requirement - an essential commodity, in the same category as power and water. It must be delivered where it’s needed and when it’s needed on a high quality, constant and reliable infrastructure.
By Peter Coppens, Director of Ethernet & IP Portfolio, Colt.

The network is the critical link to achieving a business’s key objectives, but international expansion, mergers, acquisitions, cloud adoption and wide-ranging integration all require network capacity that scales with the business.
You need to be able to flex up the bandwidth when you add those 20 employees and perhaps reduce it when they are moved elsewhere. You don’t need that extra bandwidth in six weeks’ time, you need it on day one and you don’t want a penalty from your supplier when the requirement is throttled back.
Data centre to data centre connectivity is a significant consideration. Many companies have multiple data centre sites nationally or internationally. This makes high bandwidth connections between data centres critical. Data centre colocation is also important in sectors such as capital markets, where everyone wants to be physically close to the exchange and requires high speed, low latency connections out of the data centre.
One challenge facing data centre operators is the rapid deployment of data centre to data centre connectivity to meet unpredictable demand from cloud applications, and the ability to quickly flex up/down the bandwidth.
Advertisement: Vertiv
This allows businesses to intelligently meet short term additional demands for high-bandwidth applications, such as disaster recovery or data backup. While public cloud services can be tuned up and down in a matter of minutes, traditional network delivery processes can take weeks to deliver connectivity between data centres.
Businesses need a liquid infrastructure to be able to flex their bandwidth accordingly between sites. From a technology side, Software Defined Networks (SDN) and Network Functions Virtualisation (NFV), combined with a professional services provider can deliver this flexible consumption model.
NFV describes the process of virtualising the network functions that are traditionally carried out by proprietary, dedicated hardware (like a router appliance, a load balancer appliance, a firewall appliance), and implementing the network functions as software applications on a general purpose server. NFV decreases the amount of proprietary hardware that's needed to launch and operate network services and therefore further reduces the costs.
Meanwhile flexibility, policy management and programmability are the hallmarks of SDN solutions. Using SDN enabled network service provider platforms, data centre managers can fully automate the delivery or flexing of inter-data centre connectivity. SDN also reduces the level of expertise required to configure the connectivity.
Combining SDN and NFV technologies, and driven by self-service portals, allow the instant provisioning of network connections between data centres, expansion of connectivity into new data centre locations, and the scaling of bandwidth in real time – a step improvement compared to the several weeks of traditional networking! SDN-based network management is the key to this flexibility.
This allows an organisation to dynamically self-provision Wide Area Networking according to real time business requirements, which themselves are increasingly driven by user expectations and demands.
This on-demand flexibility also extends to pricing, giving customers the option to choose per-hour pricing plans, as well as more traditional fixed term contracts.
After decades where most advances in networking were focused on delivering ever higher bandwidths, we’re now entering a time were Wide Area Networking becomes just as flexible to deliver and flex as the cloud computing it provides connectivity to.
A one cloud approach may not be enough in today’s complex business world.
By Rob Lamb, Cloud Business Director & CTO UK&I, Dell EMC.

The rapid acceleration of digital transformation in business has led to a huge increase in the investment in and use of cloud and data storage technologies to let companies look after, manage, secure and analyse their data. However, after an initial rush to public cloud, some of the complexities are coming to the fore; for example, how do we manage data protection and security policies in a public cloud environment whilst ensuring we remain compliant with data sovereignty requirements that vary from country to country (look at what happened to LinkedIn in Russia, for example)?
Many organisations are also beginning to ask themselves: how do we ensure performance across a widely distributed geographic footprint; how do we conduct analytics; with redundancy in place, is public cloud a cost-effective option?
In addition, with the rise of these technologies, and a continuing surge in data, organisations won’t always be able to store all their data on premise in their private cloud infrastructure. The more widely connected devices and IoT technologies are adopted, the greater the need for low cost cloud archive resources or ‘burst’ resources for particularly busy periods.
As such, many organisations are evaluating a hybrid cloud approach, figuring out which workloads are suited to which environments, and how to manage the mobility of data from one resource to another, something which can be extremely complex. I believe that many organisations will evolve their strategies to be hybrid or multi-cloud rather than simply putting all their data in the public cloud. Key to this will be the deployment of software defined data centres (SDDC), which allow businesses to more easily build, operate and manage hybrid cloud environments, whilst ensuring data is secure.
Advertisement: DT Manchester

So how can a SDDC environment help organisations with their digital transformation journey to the hybrid cloud? Below I outline the key benefits of how the SDDC helps to pave the way and how virtualisation helps to address the increasing demands on IT infrastructure.
Inevitably, I think all organisations will move to a multi-cloud model. One size doesn’t fit all and different application workloads will be suited to different cloud platforms – this needs to be factored into the strategy, but don’t try to run before you can walk. A hybrid environment brokering to a single public cloud environment is the right way to start to reduce the risk of losing control. At the same time, you don’t have to software-define your entire infrastructure all at once. It’s important to test and look for problems before you roll out your solutions. And finally, SDDC is a fundamental shift that requires both business and IT to be on board. It’s important that both parties are in sync to accelerate the organisation’s digital transformation journey.
Eltek expert Mat Heneghan comments on the way forward for data centers and their power systems.

Strong growth - no compromises. As the amount of data keeps on growing, so must data centers – in terms of capacity, reliability and efficiency. That’s the opportunity and challenge for data center owners. The answer is partly revolution, mostly evolution. The revolution lies in introducing modularity, the evolution in gradually migrating from AC to DC.
Modularity enables quicker and easier maintenance, resulting in the ability to replace a faulty part in minutes, and with no effect on the load capability. Today, a traditional repair cycle time can be days, including either reduced load capability or reduced resilience.
A further benefit of modularity is flexible upgrade paths. A modular power system can evolve as the load equipment evolves, while still keep the core power infrastructure.
The main arguments for DC technology in data centers are reliability and power availability (downtime in data centers is very costly and AC UPS’s one of the most frequent culprits). In addition, DC UPS’s are generally smaller, have a better efficiency compared to AC UPS’s in online mode. Off-line, or “eco-mode”, often does not provide isolation between AC input and output, and therefore transients, ripple and noise pass through, which can potentially damage the IT equipment. DC UPS’s are also simpler to service and are more cost effective.
Advertisement: Eltek
However, to enjoy the full advantage of DC technology, all the IT equipment and mechanical loads have to accept DC input. This is happening, and many of the key server manufacturers have DC input options. Still it will take some time before pure DC data centers will be the standard. In the transition period, both AC and DC will be common place.
A smart way to start using DC power is for cooling and other auxiliary systems in the data center. This is a way to start saving and start getting experience with DC. The challenges of replacing old with new…
The building itself may be a significant challenge. It may have been designed and built around a traditional UPS power system infrastructure, resulting in inefficient use of space, with many separated or isolated rooms for switchgear, switchboards, UPS’s, etc. With a Converged Power Solution, there can be a reduction in the electrical infrastructure equipment and the power system can evolve alongside the evolution of the IT equipment, creating more cost effective use of building space. Data centers and the environment... Obviously, increased data traffic and storage will lead to higher energy consumption. However, modern DC technology will minimize the environmental effects by: reducing losses in energy transmission; intelligent cooling techniques and reuse of waste heat; high efficiency power conversion; reduced need for space, smaller buildings; efficient processing and intelligent evaluation of active traffic and load management. This has always been Eltek’s way: to have the highest levels of conversion efficiency for lowest use of electricity; the highest reliability for longer service life and less frequent replacement; to package maximum power into a minimum of space, and to integrate renewable energy generation directly into our power solutions.
It’s good for the environment, good for you and good for us.
Companies have data. Lots of data. As they accrue more and more, we’re seeing a change in infrastructure preferences. Consumers like to use apps – there are more than 2 million available on the Apple app store – and apps need data. The two things are getting closer and closer together in a very literal, geographical way and we’re starting to see the development of data centre campuses.
Dale Green, Marketing Director, Digital Realty.

In a virtual and connected world, it could seem counter-intuitive for physical proximity to be so important for modern infrastructures. However, companies need to have rapid, real-time access to their stored data. They also need simplified processes for using that data.
There are teams that need to process data in real time and understand its impact immediately so that they can put it into action. For instance, marketing agencies may need to adjust advertising campaigns based on the performance of specific creatives, especially when they’re focused around specific events. Or online retailers need to understand the performance of their platforms at peak buying times to ensure maximum conversions. The list of uses goes on.
With so much of a business’s success or failure hinging on the effective application of data, getting hold of valuable information quickly starts to have a premium. Like the ‘speed races’ amongst high frequency traders of the 2000s, proximity is becoming the key thing. Speed is increased when distance is reduced. It’s a very basic principle of physics.
Advertisement: Data Centre World

So how is that speed actually achieved in practice? The birth of data centre campuses solves the proximity problem. By being part of a geographically defined space, within which all data is stored and processed, companies can get themselves an edge.
Campuses that unite colocation, scale and hybrid data centres mean that businesses can continue with the same hybrid cloud infrastructures, but in a way that benefits their strategic outcomes. You can get high demand networking, storage and low-latency all in one space.
Proximity is also important when you peek under the bonnet of the data centres themselves. Most of the services that are consumed by businesses and individuals are mash-ups of multiple feeds or services themselves. The infrastructure that supports these services isn’t always ‘mashed up’ in the same way.
Interconnection to establish an ecosystem of apps and data seems a simple idea, but in practice relies not only on knocking down siloes, but also the proximity that we’ve been talking about. Companies with multiple cloud instances and a diversified infrastructure don’t always have their data and apps in the same locations.
However, peering exchanges make it possible to bring all of this together at an affordable rate. By buying and procuring transit of data within an integrated campus environment, the costs can be managed, but also the campus becomes highly scalable. For webscale businesses, the growth from one cabinet to a whole data centre can happen at break-neck speeds. So having a blueprint for interconnecting different databases in a scalable way that optimises the analysis of data is crucial for building successful businesses.
Connected data centre campuses allow companies to take part in a diverse ecosystem that consists of a culmination of services and assets. They provide agility to support dynamic workloads, flexibility to scale when needed and private and secure access to cloud services in under 1.5 milliseconds.
The disintegration of traditional network systems in favour of layered network infrastructure and the continued move towards automation is not driven by technology but by the business imperatives of scalable and resilient infrastructures.
By Marcio Saito, CTO, Opengear.

Software-Defined Networking (SDN) is a term used to describe a new approach to design, provision, manage and operate a network, going beyond the mere adoption of new technology.
Traditionally, network infrastructure has been built as vertically integrated systems including the physical network interfaces, the switching fabric or packet forwarding engines, the compute resources to run the network protocols, and the software to configure and manage how the system works. Those proprietary systems were built and sold by a small number of large networking vendors (such as Cisco, Juniper) as self-contained boxes, providing limited latitude for network engineers to optimise the system to their specific needs.
SDN proposes to break that vertical integration, decoupling the dependencies between the underlying network-specific hardware and software (implementing what is called the “data plane” in SDN terminology) from the higher-level network intelligence software (the “control plane”). This is accomplished by adopting and enforcing a standard interface between data and control planes. In the early days of SDN, Openflow was the proposed protocol to address that, although new variants have emerged since.
The move from monolithic systems to a layered infrastructure offers the following advantages:
Network reliability is a paramount requirement for any modern business. That has made enterprise networking a relatively conservative environment, with a natural resistance to any disruptive change.
Advertisement: MSH Summit UK

The network is reliable, so why do we need to change how things are done? Network engineers have spent years learning how to configure and manage the proprietary systems (with all the certifications to prove it). Why force them to learn new protocols and fundamentally change how they work? Isn’t SDN just technology for the sake of technology?
That’s a fair question. However, SDN adoption is an unstoppable trend that will disrupt and change how networks are provisioned, configured, and managed in the future. We can say that with some confidence, because the SDN revolution mirrors transformations that have already happened in other areas of IT.
Let’s take a look at computing, the infrastructure built on servers providing power to run applications. Going back a decade, servers were also built as vertically integrated systems. The business application, such as a CRM system, was designed to run on top of a specific Operating System (say, UNIX), which was customised to run on a specific piece of hardware (perhaps an HP server), using a specific processor architecture (say, Intel x86). A few large system integrators (Sun, Dell, HP, and others) dominated the market for computer servers.
A consequence of that one-to-one-to-one relationship between layers in the compute stack was that any failure (for example, faulty memory chip on a server motherboard) would bring down the machine, its operating system and the application running on top of it, directly affecting services to users. So server architects and sysadmins focused on getting more reliable platforms to maximise application availability.
Virtualisation technologies (e.g. vmware, Linux KVM) allowed the initial decoupling of traditional applications from the underlying compute infrastructure. Today, most business applications are designed to be natively distributed and virtualised on a cloud infrastructure so that, for example, a hardware failure in a Google data centre is not felt by Gmail users. Software now just moves around to run anywhere on a resilient and distributed infrastructure.
So, the adoption of SDN is not driven by availability of technology, but by the same demands that drove the shift from monolithic servers to cloud computing. The always increasing need for reliable and scalable IT services.
A server system administrator in a traditional Enterprise data centre in the late 2000’s could manage, perhaps, 10 physical servers. With today’s cloud service providers, it is not uncommon to see ratios of 2,500 servers per system administrator. The drive towards automation is another component of infrastructure evolution.
Today, we do not expect or accept outages in our business applications, but we do still fear and occasionally experience outages in network connectivity. SDN is an inevitable response to the new challenges faced by network engineers.
A shift from vertically integrated systems to a layered infrastructure represents a significant impact for individual network engineers, requires organisational changes in IT, favours certain technologies over others, and deeply affect the relationship between IT vendors and customers.
Here are some action items related to the progression of SDN in the next years:
And while SDN is a disruption in the long term, every major change starts with small steps. If you are a network engineer running a traditional network, here are a few things to consider acting on today:
SDN technology is not new, but its adoption is still in its infancy. The reasons for the slow adoption when compared to other areas of IT can be attributed to both organisational reasons (network engineers are trained to favour stability over disruption) and technical causes (networking is intrinsically closer to physical infrastructures than business applications). But the business drivers and the increasing maturity of technology will eventually take its course.
Data centers are now a critical part of our infrastructure, housing vital digital information that is pivotal to a company’s success. Their reliability has a huge impact on businesses and organizations, affecting how they operate and how they grow. They now represent such enormous business value that if one goes offline it can cost an average of over seven thousand dollars per minute. Ensuring their reliability and security is, therefore, a fundamental part of their design.
By Andreas Haas, Product Portfolio Manager Extinguishing, Siemens Building Technologies Division.

Data center infrastructure management (DCIM) systems need to manage the complex data center environment effectively and efficiently. Personnel, assets and data all need to be protected from fire risks, physical threats and intrusions. However, these systems also need to offer flexibility of scale so that a business can grow as needed as well as handling rapidly increasing volumes of data traffic while ensuring systems do not overheat.
The amount of data storage and power demand in a data center can fluctuate widely from moment to moment. The complexity of variation in demands combined with wider authorized access to the facility requires a good DCIM system to maintain the integrity of operations. It needs to balance the needs of a business to be flexible in the services it provides while optimizing IT performance. This takes particular expertise and understanding of all aspects of processes and data management.
The availability and operational efficiency of an integrated data center solution will impact an organization’s ability to compete and respond to customer demands. As well as security of data, buildings and assets, the performance of the data center also needs to be assessed in terms of energy efficiency and carbon footprint. Accurate data and reporting tools are essential to creating an energy efficient data center infrastructure. Specialist services such as energy auditing and remote energy monitoring can help optimize energy usage in data centers, resulting in a lower environmental impact and reduced operating overheads.
Any power outage is catastrophic for a data center. Effective power monitoring can help operators understand power consumption in real time, enabling dynamic strategies to control energy use and rapid identification of any potential issues that require corrective action. This more detailed understanding of the power demands within a data center will help to create greater resilience to power outages.
A substantial part of the total energy required by a data center is used by operation-critical HVAC and cooling systems that keep environmental conditions constant. The DCIM system needs to effectively optimize energy use of these systems while ensuring consistent, reliable environmental control. Should any problems arise with these systems, the DCIM system needs to provide rapid alarming and clear visualization so operators can react before system availability is compromised.
Advertisement: MSH Summit Amsterdam

So, a data center needs to have consistent environmental conditions, robust power distribution as well as integrating the demands of IT with effective facility management. It also needs protection against possibly the greatest risk it faces: fire.
Data centers contain vast quantities of diverse electrical systems and power hungry computer racks that generate a lot of heat. Any faults in electrical installation or the HVAC systems that protect racks from overheating may lead to fire. Early, accurate detection of fire as soon as it develops is vital to enable rapid response of fire suppression systems and to prevent wide-spread damage.
When specifying a fire extinguishing system, consideration also needs to be given to whether the extinguishing system itself can cause any further damage to computer systems. For large data centers, inert gas extinguishing systems are usually selected as the gases they use do not harm sensitive technology. However, in 2009 Siemens recognized that there was an unusual amount of hard disk drive (HDD) failures following a discharge of these systems and began an investigation into why this was occurring.
A large amount of gas needs to be released quickly when fire is detected. This causes a number of effects in the data center environment. These include a small drop in temperature, an overpressure in the room and high noise levels, which can exceed 140dB, as the gas is forced through the discharge nozzles.
The drop in temperature is only slight and is a transient effect. It does not impact HDD performance. Tests on several types of HDDs further showed that even unrealistic levels of pressure and pressure gradients did not affect their performance. Investigations into the effect of noise levels, however, showed different results with varying levels of performance degradation of the HDDs.

Excessive noise levels cause vibrations which can affect the alignment of the head to the disk in the HDD. The first signs of trouble start with occurrences of incorrect reading and writing of information on the disk surface, resulting in performance degradation of the HDD. If there is an ongoing high error rate seen by the error correcting code (ECC), the self-diagnostic system will finally shut down the HDD. As noise levels and vibrations increase, however, this may cause the head to come into contact with the disk surface. This can scratch the magnetic layer of the disk and cause permanent damage. This contact damage may also release particles that are the cause of further crashes and ultimately total abrasion of the disk surface.
The effect of noise on the HDDs was tested using a loud speaker system. The speaker was set at different noise levels and frequency ranges and the performance of the HDDs monitored. This showed that performance systematically deteriorate at around 120 dB with some drive technology at certain frequencies even degrading at around 100 dB. Noise in the frequency range of 500 Hz to 8 kHz was shown to have the greatest impact on the disk drives. However, noise below 500 Hz and above 12.5 kHz did not disturb operation of the drives. The extreme noise (>140 dB) that is generated by a direct discharge jet of a standard nozzle that has been historically used in fire extinguishing systems showed the potential to cause permanent damage to the HDDs’ micro-mechanical systems.
When further tests were carried out using actual extinguish system discharges rather than noise from speakers, some degradation of performance was seen but no permanent damage or data loss occurred. The noise from fire extinguishing systems has, however, been attributed to the costly outage of data centers with damage to HDDs even as recently as 2016. Silent extinguishing systems, which significantly lower the noise level when the inert gas is discharged, were developed in response to the investigations that showed the damage noise can cause.
When designing an extinguishing system that lowers the noise generated at the point of gas discharge, care needs to be taken to ensure the performance and response of the system is not compromised. This is achieved through a noise aware design.
The lower pressure drop created by the use of a two-stage gas flow expansion means extinguishing gas can be discharged more quietly. The Sinorix Silent Nozzle developed by Siemens has an internal orifice which provides the first stage of pressure reduction while keeping the noise generated inside the nozzle. Rather than using large jets, the release of the gas into the data center room is then achieved using more numerous, smaller jets. Combined with the lower pressure drop of this second-stage expansion, the configuration of the system provides smoother, quieter release of gas with higher frequency noise – making it is less likely to cause any issues with HDD operation.
The noise of a fire extinguishing system can be further reduced by controlling the flow of gas into the room using Constant discharge technology (CDT). This eliminates the initial noise spike created by the first peak discharge of gas when the extinguishing system is initiated and, instead, provides a constant mass flow of gas over the discharge period. Without the higher initial gas flow, the use of CDT further means overpressure flaps can be reduced by up to 70%. Still greater noise reduction can be achieved if a longer discharge time (up to 120 seconds) is acceptable for the application, room acoustics are optimized, and nozzle placement and flow patterns avoid direct discharge towards equipment. This holistic design of the fire-extinguishing system results in efficient fire protection that safeguards HDD performance from noise impact.
DCIM systems need to integrate efficient building and environmental management with the needs of the IT systems. This includes providing the flexibility and agility a business needs to remain competitive. They should be tailored to specific business requirements with careful consideration to safety, security, integrity and efficiency. The value data centers now represent to a business or organization means that investing in a good, integrated DCIM system will help protect against potentially devastating failures.
When it comes to fire safety, having a system designed to help better protect both equipment and personnel is also a wise investment. The impact of the noise and vibration generated by a discharge of the fire extinguishing system is now much better understood, yet incidents still occur where systems are damaged resulting in costly downtime. The experience that suppliers such as Siemens offer gives the peace of mind that all aspects of data center needs will be considered in the design of a data center management solution for new and existing installations. Selecting a partner that fully understands data center processes and infrastructures will help to keep operations running smoothly – a decision that not only protects but may well save a business’ future.
The merger of SMS and Curvature creates an independent, global leader providing customers with best-in-class IT services, products and solutions. DCS talks to Jeremy Beavis - UK General Manager, SMS.

Please can you provide some background on SMS Systems Maintenance Services – a brief history to date and the company’s technology focus?
Founded in 1981, SMS is one of the worlds’ foremost global providers of multivendor IT asset lifecycle service solutions. We regard ourselves as ‘locally global’, in which we mean that all of our operational processes and procedure are globally standardised but designed to be locally flexible to meet the ever changing demands of our customers needs.
We offer an adaptive suite of IT data centre asset lifecycle support services developed to meet any requirements of an organisations’ evolving IT infrastructure, providing cost effective IT hardware maintenance and support tailored to our customer business demands by;-
Please can you provide some background on Curvature – a brief history to date and the company’s technology focus? And what’s the thinking in joining up a company that focuses on IT data centre lifecycle services and one that focuses on new and pre-owned network hardware and IT infrastructure services?
Curvature initially gained wide acclaim providing used Cisco equipment and a third party service alternative to OEM service contracts, called NetSure. Under NetSure maintenance provision, Curvature provides data centres with a highly affordable alternative to Cisco OEM maintenance. With SMS’ complementary offerings including hardware maintenance; smart hands; data migrations; asset management; product deployment; data centre relocation; data erasure and IT asset recycling across the data centre, combined, we are now able to deliver unparalleled products and services for our customers.
As to the merger. This is fantastic news for our collective customers, as together, the SMS and Curvature alliance forms a formidable team with a shared collective vision, complementary offerings and a unified commitment to deliver unparalleled products and services. We are now uniquely positioned to transform how we manage, run and expand the entire IT infrastructure for our customers.
Advertisement: Hillstone
How can datacentre owners and operators rapidly understand availability, capacity and efficiency of their facility?
This video showcases the available datacentre services including datahall CFD calibration & server simulator load banks. Further details can be found on our website, or by getting in touch.
We align perfectly with one another, with very little overlap across the organisations which allows us to drive real customer value and address the complete IT business demands that our customers face each and every day.
Less than a year ago, both SMS and Curvature were separately listed as ‘Top Performers’ in Gartner’s Competitive Landscape Report: “Leveraging Third-Party Maintenance Providers for Data Centre and Network Maintenance Cost Optimization, North America”. Collectively, with the combined strengths we are uniquely able to drive real value to our customers by increasing end to end services, driving down costs and wastage, whilst dramatically increasing efficiencies.
With our combined strengths surpassing $540 million in revenue and over 2,000 employees worldwide, together we have now become the undisputed independent global leader in IT services, products and solutions.
A key element that is often overlooked in any merger is the combined strength of the people. It’s no co-incidence that SMS and Curvature demonstrate very similar cultures that mean that we are big enough to make a difference and small enough to be flexible to respond to our customers’ ever changing needs. So unlike some of our rival organisations, the merged organisation will continue to operate as a global player, but with the dynamic soul of a start-up - ready to think outside the box and move fast to help our customers meet the most pressing IT asset lifecycle demands.
Curvature’s expertise covers IT infrastructure cost optimisation?
For the past 30 years, Curvature has based its entire focus on helping customers reduce the cost of buying and maintaining their IT infrastructure. From a CAPEX perspective, Curvature offers customers a range of both new and pre-owned products at significant discounts. Customers can expect to receive discounts between 60% and 90% off list price, depending on generation of equipment. Curvature maintains a global inventory of over $250 million worth of product (OEM list) that is available for overnight delivery and offers a true lifetime best efforts warranty on sold products. With NetSure, our third-party maintenance alternative, we allow customers to keep previous generation models in their network that have gone past their end-of-life date. That means no unnecessary or premature upgrades and significant reduction in CAPEX. We protect those working devices with our support & maintenance service at a fraction of the cost.
Networking/infrastructure technology?
Curvature is the largest independent provider of new and pre-owned networking equipment. For example in 2016, Curvature delivered over 250,000 serialised chassis and in excess of one million total devices/components to clients around the world. Curvature’s global engineering teams test and configure thousands of devices every day which gives them a valuable combination of theoretical and practical experience with in-depth knowledge of how current and past generation equipment work together. Because Curvature remains independent from the manufacturer, we are not required to help them drive new product upgrades. This allows Curvature to uniquely assist companies with building a technology road map that maximises customer return of their current investment.
Data centre and IT asset management?
Curvature supports IT assets throughout the lifecycle. Whether supporting complex network configurations or individual equipment replacement, Curvature’s 24x7 certified technical engineering teams based in the U.S., the Netherlands and Singapore offer a rare industry balance of hands-on experience and helpful customer service. With our hardware maintenance and support offering and our lifetime warranty, Curvature offers comprehensive, reliable coverage.
Maintenance, service and support?
Curvature provides an alternative to OEM maintenance based on a programme called NetSure. NetSure provides customers with 24x7x365 TAC support and guaranteed product replacement. NetSure costs significantly less than OEM support and comes with no OEM mandated “end of support” date. This allows customers to take a thoughtful approach to why and when they choose to upgrade equipment on their network. By delaying unnecessary CAPEX, customers can use their budgets to greater effect by prioritising high impact projects. Together with SMS, Curvature provides maintenance to Customer locations in over 65 countries including India and China and it is available in any of the standard SLA’s (NBD/4HR, with or without field engineering).
And both new and pre-owned equipment?
Indeed, Curvature is the largest independent provider of new and pre-owned networking equipment. In 2016, Curvature delivered over 250,000 serialised chassis and in excess of one million total devices/components to clients around the world. Curvature’s global engineering teams test and configure thousands of devices every day giving an in depth knowledge of how current and past generation equipment work together. Because we are independent from the manufacturer, we are not required to help them drive new product upgrades. This allows us to uniquely assist companies with building a technology road map that maximises the return of their current investment.
Meanwhile, SMS offers data centre migration services?
SMS is expert at providing data centre migration services, assisting organisations with both the hardware relocation and the migration of data on their equipment. Together with Curvature’s logistic and asset recovery services, the combined SMS | Curvature organisation is set to provide the market with a truly differentiated offering.
And relocation services?
Together, SMS | Curvature are capable of offering customers relocation services in over 60 countries and is an area of long standing expertise for both hardware and data relocation depending on requirements. With over 2,000 employees worldwide and a robust partner network, reach is strong and demand is growing for supported relocation assistance.
And has a ‘remote hands’ offering?
The SMS ‘Remote Hands’ service can help customers when and where needed, regardless of geographic location or facility type (data centres, remote offices and/or distribution centres). As the service name implies, SMS’ technical resources can quickly be deployed to accommodate most any need including Installs, Moves, Adds, Changes, De-Installs (IMACD) of IT equipment, as well as general IT support assistance, allowing the customer’s staff to remain focused on business initiatives.
And offers a lifecycle focus, looking at kit and IT asset disposition?
This is especially relevant for customers that relocate frequently, to facilitate proper equipment disposal completing the entire equipment lifecycle. SMS | Curvature provides an extensive buy-back scheme for excess hardware and/or can properly dispose in a secure and environmentally certified manner.
And how will the strengths of the two organisation be increased under one roof?
By joining forces, SMS | Curvature are able to offer customers seamless access to a wider suite of services. This increase in services allows total end-to-end design, procurement, maintenance and service of IT infrastructures in the most cost-effective manner possible. Importantly, customers will receive world class support along the way. The combined companies show very little overlap in customer base but their existing clients share similar perspective on effectively managing their IT spend.
And how do you see the new organisation developing, both in terms of integrating the two companies’ areas of expertise, and in bringing new products and services to the market?
SMS and Curvature’s overall aim is to simplify and to maximise value along the entire IT supply chain thereby deepening relationships with new and existing customers and increasing value along the way.
In other words, what can we expect from the new organisation over the next 12-18 months?
Short-term, SMS | Curvature will be active in communicating the combined value proposition to shared customers. Combined, the organisation will position itself as being dominant global leader in the emerging TPM marketplace increasing global footprint. The TPM (third party maintenance) marketplace is nearing an important tipping point. Today, IT analyst firms like Gartner, Forrester, Accenture and IDC are educating customers about the inherent value that TPM provides leading to both greater awareness and acceptance. SMS Curvature will work to meet the increased demand.
And how would you position the merged organisation when compared to similar companies operating in the data centre/IT infrastructure space?
SMS and Curvature have both been recognized by leading analysts as having best-in-class capabilities with highly complementary product and service offerings. This merger positions us as the independent global leader providing customers with best-in-class IT services, products and solutions.
How will the new organisation help end users address issues surrounding the Cloud?
For customers considering, or have already embarked, into their journey to the Cloud, the new SMS | Curvature organisation will bring increased flexibility, choice and a wide range of expertise. When implementing a Cloud strategy, it is important to recognise that customers face a wide variety of challenges developing, implementing and evolving a long-term Cloud strategy. Considerations include which applications should move? Which applications should stay? Is the security plan complete? Are the right personnel in place to assist with the transition? Frequently, after due diligence, it’s recognised that some business critical applications and systems are better off in a hybrid on premise model.
And, more generally, data centre/IT infrastructure evolution/revolution? For example, networking developments such as SDN and NFV?
There is little doubt that SDN will have a major impact on the industry but accurately envisaging when it becomes a reality remains uncertain. We advise customers to consider where SDN will be in 2-3 years’ time. This view changes depending which manufacturer you talk to. Traditional OEM’s have different views on what SDN should look like compared to start-up manufacturers. The battle to influence the market continues. For some of the largest Telco’s and customer networks, SDN planning and lab development is well underway. For most customers however, how to tackle SDN remains a huge grey area. Companies know that SDN has the potential for greater network control and cost savings but they are not yet ready or comfortable enough to move away from their current network design. This provides a challenge to CIO’s and CTO’s who have OEM’s knocking on their door asking them to move forward with another major global network upgrade. With so many questions unanswered, the smart CIOs are putting off the significant spends in upgrades while the market establishes what SDN will become. When such a pragmatic approach to hold back $$ sign off until the SDN market matures is adopted SMS | Curvature couples to provide ongoing infrastructure support -even when it has passed the OEM stipulated “end of life” date.
And the apparent move towards the deployment of more and more open systems?
The future also looks increasingly interesting when watching how OEM’s themselves treat maintenance of their own equipment as the push towards more open, integrated systems continues. SMS | Curvature look likely to achieve additional opportunities as increasingly, some of these OEM’s elect to outsource their own maintenance programme, given this route frequently offers better service options and a more realistic price tag for the customer.
Big Data, High Performance Computing, Internet of Things – are these issues with which the new company can help end users?
With the advent of IoT, Gartner is anticipating a significant increase in “Micro Data Centres” that are regionally distributed and sit outside of the major data centres. To the extent that this is true, these micro data centres require both hardware and engineering support. This is the same with the emergence of Hyper-Converged. SMS | Curvature bridges this gap extending IT staff into previously unsupported branches.
Data centre monitoring services have been around for over 10 years. Over that period of time, many of these systems have not been updated to reflect changing data centre technologies. As a result, the lives of systems administrators have become more complex and maintaining data centre uptime has become more of a challenge.
By Victor Avelar, Director and Senior Research Analyst, Schneider Electric Data Center Science Center.

When compared to the systems of 10 years ago, modern data centre power and cooling infrastructure has become more intelligent. With more built-in data points, these systems produce, on average, 300% more alarm notifications than they did in the past. Therefore, data centre staffs have to deal with much more alarm support “busy work”.
The whole point of monitoring data centres is to reduce the risk of downtime by identifying and addressing a state change before an uptime-threatening incident occurs. This becomes a challenge when alarm fatigue overwhelms the staff, when no unified monitoring platform exists (i.e., individual power and cooling devices have their own native management solution), and when administrators find themselves having to contact various vendor customer support lines for help.
Traditional remote monitoring is not an online service and therefore it cannot provide real-time monitoring. Instead these older systems produce intermittent status updates, oftentimes via email. New digital remote monitoring systems are connected to a data centre, usually through a gateway. Therefore, these new systems can employ IT services such as cloud storage and data analytics to help system administrators cope with the vast increase of equipment performance data.
New on-line monitoring systems simplify system administrator work because they employ big data analytics and machine learning techniques. Big data analytics are supported by software tools, which process the monitoring system data so that decisions can be made on which actions to take. Big data analytics are required when data volumes increase, when data becomes unstructured (i.e. data variety like emails, free-form text fields, or trouble tickets) and when data is processed in real-time.
Advertisement: Vertiv
Machine learning is related to data analytics in that it uses data to make predictions. However, it also improves the overall support model by factoring in results from previous learning. That means the monitoring system gets smarter over time.
These tools also streamline how data centre operators manage systems uptime. In the case of a data centre remote monitoring service, event processing and prioritization of alarms can be much more efficiently managed. Network Operation Centre (NOC) experts can notify and guide systems operators during an event that triggers multiple alarms. Alarm consolidation can convert multiple alarms from the same device into a single incident. Since so many data centre operators now use mobile devices as a common interface into systems, automatic trouble ticket generation can be provided through a mobile app which can track incidents via live chats and instant messages. Contextual alarms can provide administrators with useful information like the origin of the problem (e.g. data centre X, data hall Y, rack 15C), who’s involved, the number of alarms generated, and what to check first.
Event correlation and root cause analysis can be performed which evaluates multiple alarms, deduces possible causes, and proposes possible solutions. This correlation process, performed by domain experts in a NOC, can be combined with machine learning so that future downtime incidences can be avoided.
Data centres are on a path to become more reliable and efficient through the use digital remote monitoring. However, this can only happen with platforms that interpret and leverage the data generated by the physical infrastructure in a data centre. For more information, download Schneider Electric White Paper 237 “Digital Remote Monitoring and How It Changes Data Center Operations and Maintenance”.
A central hub room in the Telehouse North data centre required a new cable management solution that would provide flexible and future-ready, intrabuilding connectivity to each of the five floors and customer colocation suites.
Telehouse North is Europe’s first purpose-built, carrier-neutral colocation data centre. One of four Telehouse data centres located at the Docklands campus in London, it is the primary home of the London Internet Exchange (LINX) and one of the most connected data centres in Europe. It provides end-to-end information and communications technology (ICT) solutions including managed services, integrated communications services, virtualisation services, content management and system security services, as well as disaster recovery services.
Telehouse’s cabling infrastructure required an update in order to maximise capacity in its 9,717 square metre, highly secure colocation centre, which consists of 32 suites over multiple floors. A central hub room required a new cable management solution that would provide flexible and future-ready, intrabuilding connectivity to each of the five floors and customer colocation suites.
Most importantly, the new central hub had to be ready for operations within three months. From an infrastructure perspective, the design had to meet a number of objectives:
To meet this challenge, Corning enlisted the help of Kinetic IT, one of their preferred installers, to work closely with Telehouse on the design. The proposal was for a future-ready, passive cabling infrastructure solution, including planning and installation. In addition, Corning provided the consultation and training required to accelerate knowledge transfer and operational readiness to meet the strict deadlines for a complete turnkey solution.
Telehouse required a resilient solution with flexibility to meet future growth and change. Key to the design was the addition of a central hub with 100 percent diverse routing of fibre connectivity to each floor and a customer colocation suite with enough capacity to meet future demand.
Corning was invited to tender for this project along with two other connectivity infrastructure suppliers. Telehouse informed Corning that they selected their solution because it offered the most value while also meeting all of the project requirements, including:
Corning proposed an infrastructure solution designed around its proven Centrix™ system. The innovative design of the Centrix system enables an ultra-high-density deployment in a compact footprint and provides a scalable fibre management solution for cross-connect applications in the data centre’s central hub. The Centrix system supports up to 4,320 LC connector ports per 2200 mm frame with a 900 mm wide, 300 mm deep footprint. The highest density of 17,280 optical fibre ports in one square metre is possible in a quad configuration.
The frame design provides optimized routing paths for jumpers, reducing the risk of entanglement, while the operations staff can install or remove a single patch cable in less than two minutes regardless of the cable route.
The foundation of Centrix is a modular cassette that can be tailored in a variety of ways to provide flexibility and functionality without sacrificing density. Each cassette contains fibre guides and a splice section and can hold 24 or 36 LC connector adapters. Telehouse personnel can easily access the fibre ports as the cassettes have a sliding mechanism with drop-down handle.
Corning indoor/outdoor cables, typically 96 fibre, were terminated on cassettes within the Centrix frame and installed along diverse routes to each of the customer suites. These cables utilise low-loss SMF-28® Ultra optical fibre, which provides a solid foundation of high-performance for the newly upgraded infrastructure. SMF-28 Ultra optical fibre offers industry-leading specifications for attenuation and macrobend loss. Low attenuation enables extended reach of network connectivity between locations, while 33 percent better macrobend performance helps improve existing duct utilisation and the support of smaller enclosures.
Advertisement: 8Solutions
The project, which began in late December 2015, involved the initial termination of over 16,000 fibre ports on the Centrix as well as the installation of cables to each suite. Completed in March 2016, within a 12-week timeframe, the installed system has the capacity to allow for expansion up to 130,000 ports with the use of additional cabinets.
Steve Gentle, Telehouse senior customer installations manager, commented, “We are very pleased with the level of technical assistance and support we received from Corning and their partner Kinetic for our fibre infrastructure project at Telehouse North. Corning offered excellent technology and product knowledge and Kinetic supplied a high level of practical design and installation expertise. Both organisations were easy to work with and surpassed our expectations – working with the combined team was a very positive experience.”
The Centrix system combines extreme flexibility and simplicity with the ultimate in density. With superior jumper management and an innovative fibre routing system, the Centrix system is a cross-functional system that meets the requirements of multiple application spaces.
Telehouse was pleased with the installation, as it met all requirements and was delivered on time and within budget. Consultancy services and advice were provided to Telehouse throughout the project process to ensure its success. Project handover training was provided to the Telehouse operations team with further consultation and installation support being offered on an ongoing basis. Telehouse is now able to provide fast and flexible provisioning of connectivity to suites and respond quickly to the changing business needs of its business customers.
A successful execution and implementation of this installation will create the basis for future project stages, including the infrastructure in a new Telehouse building scheduled for completion later in the year.
“Kinetic IT was delighted to be selected to partner with Corning for the Telehouse project. By working closely with Steve Gentle and his team at Telehouse, we were able to understand how they would best utilise the infrastructure and take into account both their current and future capacity requirements. Close collaboration with Corning’s design team and the quality Centrix product set ensured that this was achievable, making for a seamless installation that went without a hitch.” Tom Cella, Managing Director at Kinetic IT